T5Elasticsearch
1.0.0
ด้านล่างนี้เป็นตัวอย่างการค้นหางาน:
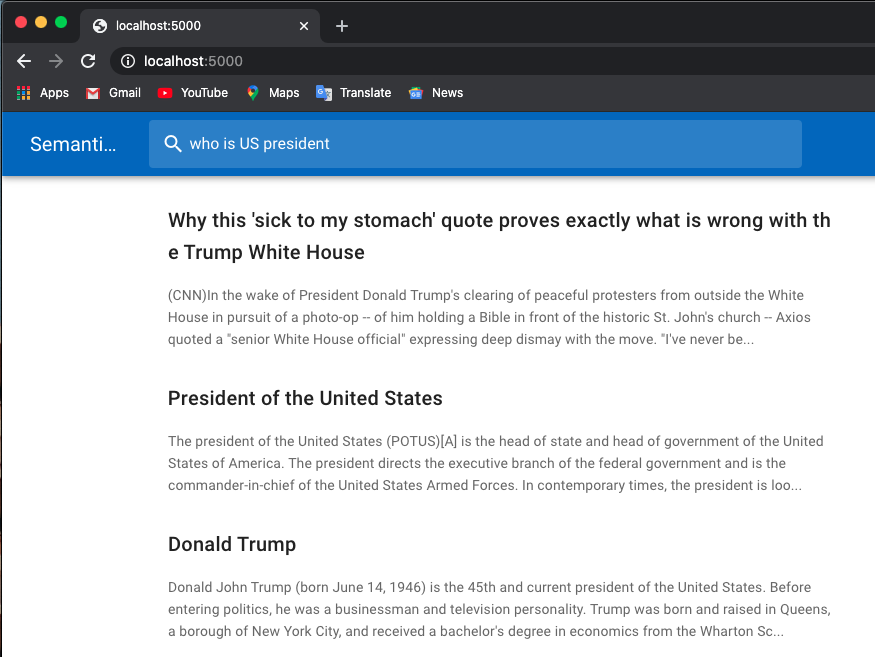
ฉันใช้โมเดลที่ได้รับการฝึกมาจากหม้อแปลงฮักกิ้งเฟซ
ดาวน์โหลดโทเค็นไนเซอร์ที่ได้รับการฝึกล่วงหน้าและโมเดล t5/bert ลงในไดเร็กทอรีในเครื่องด้วยตนเอง คุณสามารถตรวจสอบโมเดลได้ที่นี่
ฉันใช้โมเดล 't5-small' ตรวจสอบที่นี่ และคลิก List all files in model เพื่อดาวน์โหลดไฟล์ 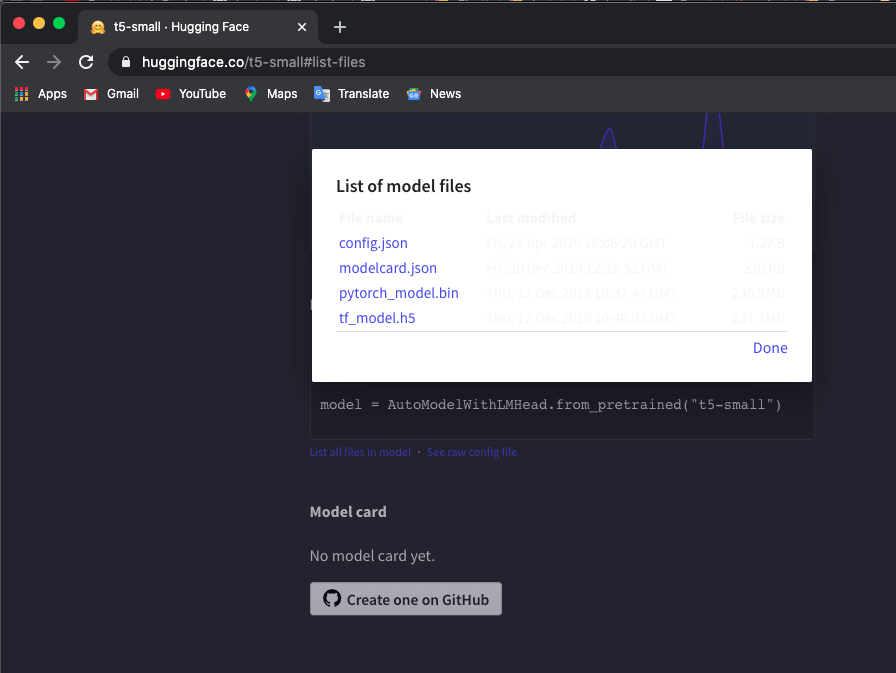
สังเกตโครงสร้างไดเร็กทอรีไฟล์ที่ดาวน์โหลดด้วยตนเอง
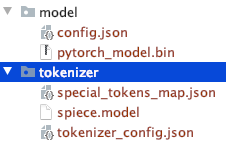
คุณสามารถใช้ T5 หรือ Bert รุ่นอื่นได้
หากคุณดาวน์โหลดรุ่นอื่น ให้ตรวจสอบรายการรุ่น pretraied ของ Hugaface Transformers เพื่อตรวจสอบชื่อรุ่น
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build ฉันยังใช้ docker system prune เพื่อลบคอนเทนเนอร์ เครือข่าย และรูปภาพที่ไม่ได้ใช้ทั้งหมดเพื่อเพิ่มหน่วยความจำ เพิ่มหน่วยความจำนักเทียบท่าของคุณ (ฉันใช้ 8GB ) หากคุณพบ Container exits with non-zero exit code 137
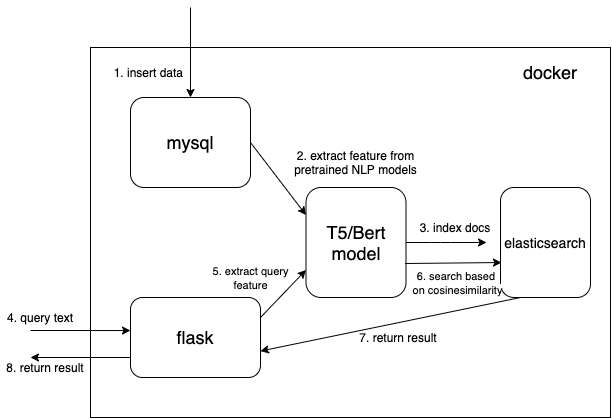
เราใช้ประเภทข้อมูลเวกเตอร์หนาแน่นเพื่อบันทึกคุณสมบัติที่แยกมาจากโมเดล NLP ที่ได้รับการฝึกล่วงหน้า (t5 หรือ bert ที่นี่ แต่คุณสามารถเพิ่มโมเดลที่ได้รับการฝึกไว้ล่วงหน้าที่คุณสนใจได้ด้วยตัวเอง)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} ขนาด dims:512 ใช้สำหรับรุ่น T5 เปลี่ยน dims เป็น 768 หากคุณใช้รุ่น Bert
อ่านเอกสารจาก mysql และแปลงเอกสารเป็นรูปแบบ json ที่ถูกต้องเพื่อรวมเป็น elasticsearch
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'ไปที่ http://127.0.0.1:5000
รหัสสำคัญสำหรับการใช้โมเดลที่ได้รับการฝึกล่วงหน้าเพื่อแยกคุณสมบัติคือฟังก์ชัน get_emb ในไฟล์ ./index_files/indexing_files.py และ ./web/app.py
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()คุณสามารถเปลี่ยนรหัสและใช้โมเดลที่ได้รับการฝึกอบรมที่คุณชื่นชอบได้ ตัวอย่างเช่น คุณสามารถใช้รุ่น GPT2 ได้
คุณยังสามารถปรับแต่ง elasticsearch ของคุณได้โดยใช้ฟังก์ชันคะแนนของคุณเองแทน cosineSimilarity ใน .webapp.py
ตัวแทนนี้ได้รับการแก้ไขตาม Hironsan/bertsearch ซึ่งใช้แพ็คเกจ bert-serving เพื่อแยกคุณสมบัติ bert จำกัดไว้ที่ TF1.x


