context search engine
1.0.0

วัตถุประสงค์หลักของโครงการนี้คือเพื่อแสดงความสามารถในการค้นหาเวกเตอร์โดยจัดให้มีอินเทอร์เฟซที่เป็นมิตรต่อผู้ใช้ซึ่งช่วยให้ผู้ใช้สามารถค้นหาตามบริบทในคลังข้อมูลของเอกสารข้อความได้ ด้วยการใช้ประโยชน์จากพลังของ BERT ของ Hugging Face และ FAISS ของ Facebook เราจะส่งคืนข้อความที่มีความเกี่ยวข้องสูงโดยพิจารณาจากความหมายเชิงความหมายของข้อความค้นหาของผู้ใช้ แทนที่จะเป็นเพียงการจับคู่คำหลักเท่านั้น โครงการนี้ทำหน้าที่เป็นจุดเริ่มต้นสำหรับนักพัฒนา นักวิจัย และผู้ที่ชื่นชอบที่ต้องการเจาะลึกเข้าไปในโลกแห่งการค้นหาข้อความตามบริบท และปรับปรุงแอปพลิเคชันด้วยเทคนิค NLP ที่ล้ำสมัย
เป้าหมายของฉันคือเพื่อให้แน่ใจว่าเราเข้าใจฐานข้อมูลเวกเตอร์เบื้องหลังตั้งแต่เริ่มต้น
ภาพหน้าจอของแอปพลิเคชัน:
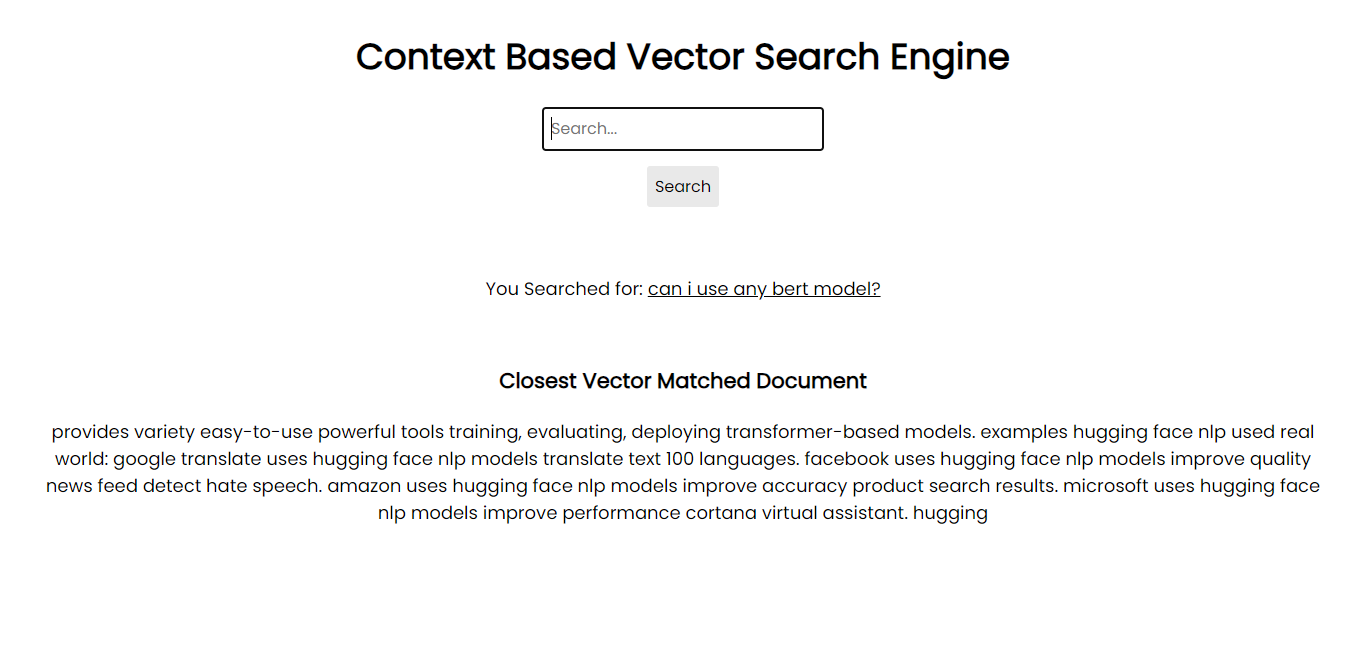
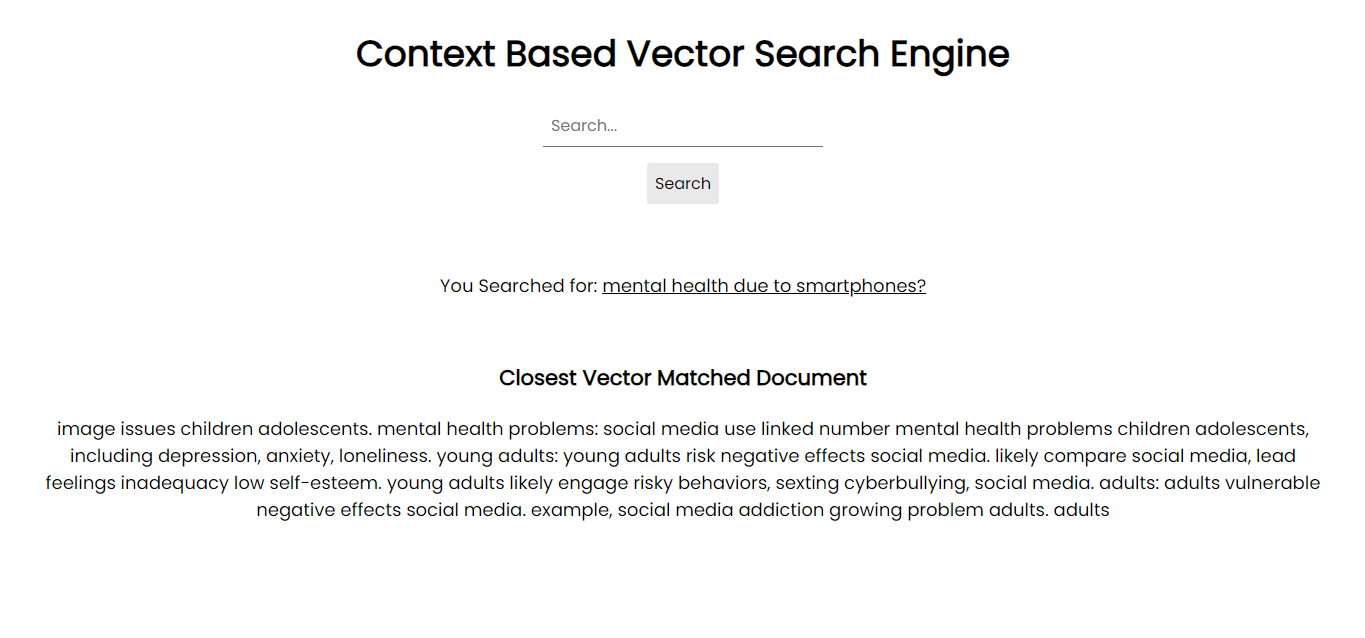
เพื่อที่จะทำงานบนระบบของคุณ คุณสามารถติดตั้งแพ็คเกจที่จำเป็นทั้งหมดผ่าน pip โดยใช้ไฟล์ข้อกำหนด:
pip install -r requirements.txtสำหรับข้อมูลของคุณ ฉันใช้ Python 3.10.1
อย่างไรก็ตาม หากคุณมี GPU คุณจะต้องติดตั้ง FAISS GPU เพื่อการผสานรวมฐานข้อมูลที่รวดเร็วและใหญ่ขึ้น
เวอร์ชันปัจจุบันของโครงการนี้ประกอบด้วย:
แม้ว่าโครงการนี้จะนำเสนอระบบการค้นหาตามบริบทที่ใช้งานได้ แต่ก็ได้รับการออกแบบให้เป็นโมดูลาร์ เพื่อให้สามารถขยายและรวมเข้ากับระบบหรือแอปพลิเคชันที่ใหญ่ขึ้นได้
รากฐานของโครงการนี้อยู่ที่ความเชื่อที่ว่าเทคนิค NLP สมัยใหม่สามารถให้ผลการค้นหาที่แม่นยำและมีความเกี่ยวข้องตามบริบทมากกว่ามาก เมื่อเปรียบเทียบกับวิธีการที่ใช้คำหลักแบบดั้งเดิม ต่อไปนี้คือรายละเอียดแนวทางของเรา:
จากแนวทางดังกล่าว ผมได้แบ่งโครงการออกเป็น 2 ส่วน คือ
ส่วนที่ 1: การสร้างข้อมูลเวกเตอร์ที่สามารถค้นหาได้
ในส่วนนี้ ขั้นแรกเราจะอ่านอินพุตจากเอกสาร แบ่งมันออกเป็นชิ้นเล็กๆ สร้างเวกเตอร์โดยใช้โมเดลแบบ BERT จากนั้นจัดเก็บอย่างมีประสิทธิภาพโดยใช้ FAISS นี่คือแผนภาพการไหลที่แสดงให้เห็นสิ่งเดียวกัน
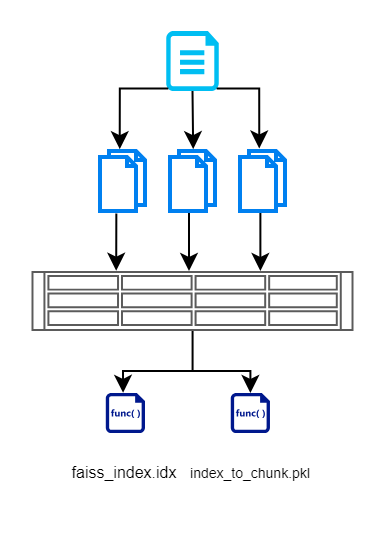
เราสร้างไฟล์ FAISS Index ซึ่งมีการแสดงเวกเตอร์ของเอกสารที่แยกเป็นชิ้น เรายังจัดเก็บดัชนีของแต่ละก้อนด้วย ซึ่งจะคงไว้เพื่อที่เราจะได้ไม่ต้องสืบค้นฐานข้อมูล/เอกสารอีกครั้ง สิ่งนี้ช่วยเราในการลบการดำเนินการอ่านที่ซ้ำซ้อน
เราทำส่วนนี้โดยใช้ create_index.py มันจะสร้างไฟล์ 2 ไฟล์ข้างต้น หากต้องการใช้รุ่นอื่นก็เปิดให้ทำจากฮับ HuggingFace ?
หมายเหตุ: หากคุณพบปัญหาในการตั้งค่าไฮเปอร์พารามิเตอร์สำหรับมิติ ให้ตรวจสอบไฟล์ config.json ของโมเดลเพื่อดูรายละเอียดเกี่ยวกับมิติของโมเดลที่คุณกำลังพยายามใช้
ส่วนที่ 2: การสร้างอินเทอร์เฟซแอปพลิเคชันที่ค้นหาได้
ในส่วนนี้ เป้าหมายของฉันคือการสร้างอินเทอร์เฟซที่ช่วยให้ผู้ใช้โต้ตอบกับเอกสารได้ ฉันให้ความสำคัญกับการออกแบบที่เรียบง่ายโดยไม่ทำให้เกิดอุปสรรคเพิ่มเติม
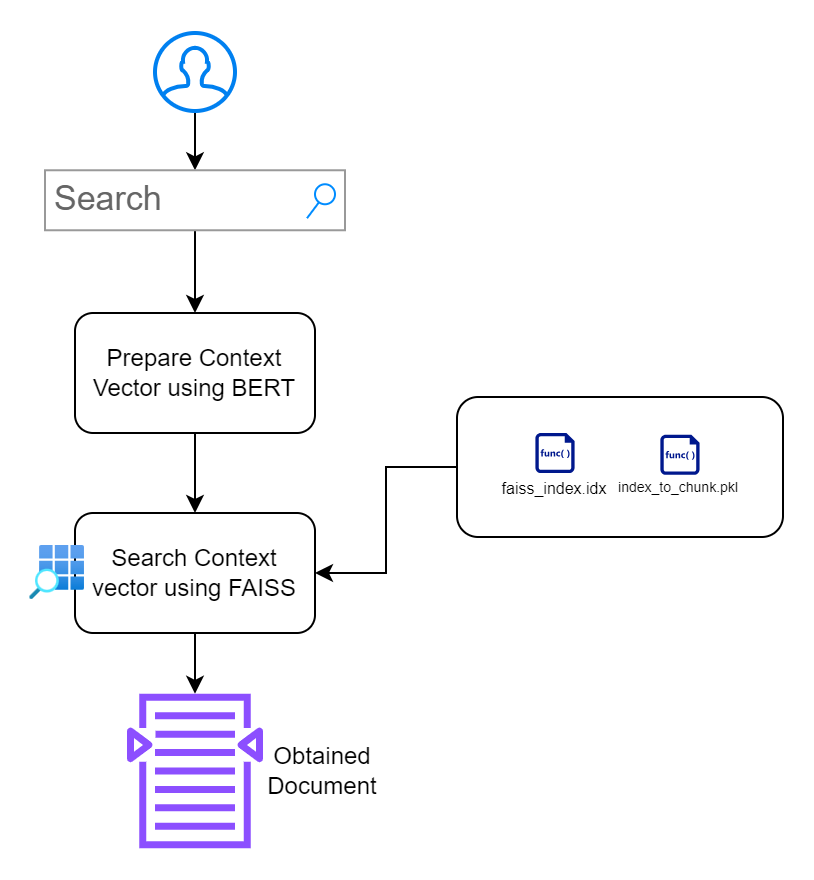
index.html : หน้า HTML ส่วนหน้าสำหรับป้อนคำค้นหาapp.py : แอปพลิเคชัน Flask ที่ให้บริการส่วนหน้าและจัดการคำค้นหาsearch_engine.py : ประกอบด้วยตรรกะสำหรับการสร้างการฝัง การค้นหา FAISS และการเน้นคำหลัก /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) และการแมปประกอบจากดัชนีหนึ่งไปยังอีกกลุ่มข้อความ ( index_to_chunk.pkl ) python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000มีพื้นที่สำหรับการปรับปรุงอยู่เสมอ ต่อไปนี้เป็นการปรับปรุงที่เป็นไปได้และคุณลักษณะเพิ่มเติมที่สามารถบูรณาการได้:
โครงการนี้อยู่ภายใต้ใบอนุญาต MIT รู้สึกอิสระที่จะใช้โดยการอ้างอิง ปรับเปลี่ยน แจกจ่าย และมีส่วนร่วม อ่านเพิ่มเติม
หากคุณสนใจที่จะปรับปรุงโครงการนี้ เรายินดีรับฟังความคิดเห็นของคุณ! โปรดเปิดคำขอดึงหรือปัญหาบนพื้นที่เก็บข้อมูลนี้ ฉันกำลังจัดลำดับความสำคัญของสิ่งต่าง ๆ ข้างต้นเพื่อทำการปรับปรุงเป็นหลัก คำขอดึงอื่นๆ จะได้รับการพิจารณาเช่นกันแต่จะมีลำดับความสำคัญน้อยกว่า
ขอขอบคุณล่วงหน้าสำหรับความสนใจของคุณ :มีความสุข: .


