lark
1.2.2 - Bugfix for 1.2.1 (Earley issues with ambiguity)
Lark เป็นชุดเครื่องมือแยกวิเคราะห์สำหรับ Python ที่สร้างขึ้นโดยเน้นไปที่หลักสรีรศาสตร์ ประสิทธิภาพ และความเป็นโมดูล
Lark สามารถแยกวิเคราะห์ภาษาที่ไม่มีบริบททั้งหมดได้ พูดง่ายๆ ก็คือ มันสามารถแยกวิเคราะห์ภาษาการเขียนโปรแกรมได้เกือบทุกภาษา และในภาษาธรรมชาติส่วนใหญ่ในระดับหนึ่งด้วย
มันมีไว้สำหรับใคร?
ผู้เริ่มต้น : Lark เป็นมิตรมากสำหรับการทดลอง มันสามารถแยกวิเคราะห์ไวยากรณ์ใดๆ ที่คุณพูดถึง ไม่ว่าจะซับซ้อนหรือคลุมเครือแค่ไหน และทำได้อย่างมีประสิทธิภาพ นอกจากนี้ยังสร้างแผนผังการแยกวิเคราะห์ที่มีคำอธิบายประกอบให้กับคุณ โดยใช้เพียงไวยากรณ์และอินพุต และให้เครื่องมือที่สะดวกและยืดหยุ่นแก่คุณในการประมวลผลแผนผังการแยกวิเคราะห์นั้น
ผู้เชี่ยวชาญ : Lark ใช้ทั้ง Earley(SPPF) และ LALR(1) และ lexers ต่างๆ มากมาย เพื่อให้คุณสามารถแลกพลังงานและความเร็วได้ ตามความต้องการของคุณ นอกจากนี้ยังมีคุณสมบัติและยูทิลิตี้ที่ซับซ้อนมากมาย
มันทำอะไรได้บ้าง?
และคุณสมบัติอื่น ๆ อีกมากมาย อ่านล่วงหน้าและค้นหา!
สิ่งสำคัญที่สุดคือ Lark จะช่วยคุณประหยัดเวลาและป้องกันไม่ให้คุณปวดหัวในการแยกวิเคราะห์
$ pip install lark --upgrade
Lark ไม่มีการพึ่งพา
Lark จัดให้มีการเน้นไวยากรณ์สำหรับไฟล์ไวยากรณ์ (*.lark):
สิ่งเหล่านี้คือการใช้งาน Lark ในภาษาอื่น พวกเขายอมรับไวยากรณ์ของ Lark และจัดเตรียมยูทิลิตี้ที่คล้ายกัน
นี่คือโปรแกรมเล็กๆ สำหรับแยกวิเคราะห์ "Hello, World!" (หรือวลีอื่นที่คล้ายคลึงกัน):
from lark import Lark
l = Lark ( '''start: WORD "," WORD "!"
%import common.WORD // imports from terminal library
%ignore " " // Disregard spaces in text
''' )
print ( l . parse ( "Hello, World!" ) )และผลลัพธ์คือ:
Tree ( start , [ Token ( WORD , 'Hello' ), Token ( WORD , 'World' )])สังเกตเครื่องหมายวรรคตอนไม่ปรากฏในแผนภูมิผลลัพธ์ จะถูกกรองออกไปโดยอัตโนมัติโดย Lark
Lark เก่งในการจัดการกับความคลุมเครือ นี่คือผลลัพธ์ของการแยกวิเคราะห์วลี "แมลงวันผลไม้เหมือนกล้วย":
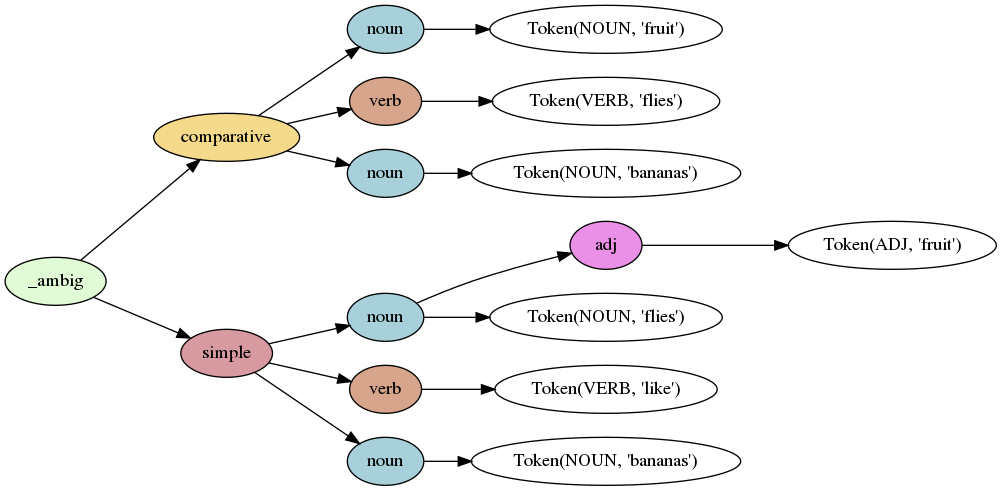
อ่านโค้ดที่นี่ และดูตัวอย่างเพิ่มเติมได้ที่นี่
ดูรายการคุณสมบัติทั้งหมดได้ที่นี่
ความสนุกสนานนั้นเร็วและเบา (ต่ำกว่าดีกว่า)
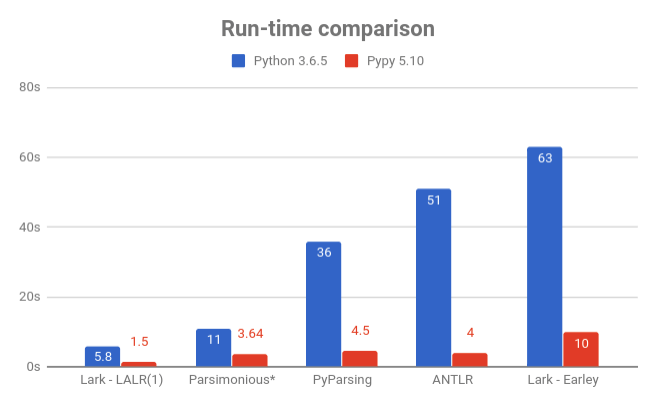
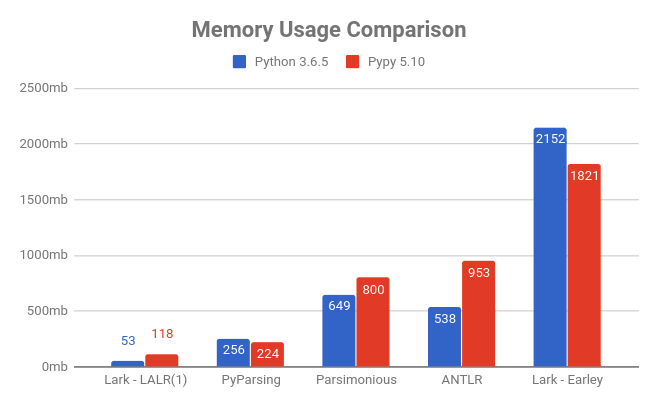
ดูบทช่วยสอน JSON เพื่อดูรายละเอียดเพิ่มเติมเกี่ยวกับวิธีการเปรียบเทียบ
หากต้องการการวัดประสิทธิภาพจากบุคคลที่สามอย่างละเอียด โปรดดูที่ Python Parsing Benchmarks repo
| ห้องสมุด | อัลกอริทึม | ไวยากรณ์ | สร้างต้นไม้? | รองรับความคลุมเครือ? | สามารถจัดการทุก CFG ได้หรือไม่? | การติดตามบรรทัด/คอลัมน์ | สร้างแบบสแตนด์อโลน |
|---|---|---|---|---|---|---|---|
| สนุกสนาน | เออร์ลีย์/LALR(1) | อีบีเอ็นเอฟ | ใช่! | ใช่! | ใช่! | ใช่! | ใช่! (LALR เท่านั้น) |
| ชั้น | ลาอาร์(1) | บีเอ็นเอฟ | เลขที่ | เลขที่ | เลขที่ | เลขที่ | เลขที่ |
| PyParsing | ตรึง | เครื่องผสมผสาน | เลขที่ | เลขที่ | เลขที่* | เลขที่ | เลขที่ |
| ผักชีฝรั่ง | ตรึง | อีบีเอ็นเอฟ | เลขที่ | เลขที่ | เลขที่* | เลขที่ | เลขที่ |
| ใจดี | ตรึง | อีบีเอ็นเอฟ | ใช่ | เลขที่ | เลขที่* | เลขที่ | เลขที่ |
| แอนทีอาร์ | LL(*) | อีบีเอ็นเอฟ | ใช่ | เลขที่ | ใช่? | ใช่ | เลขที่ |
(* PEG ไม่สามารถจัดการไวยากรณ์ที่ไม่ได้กำหนดไว้ได้ นอกจากนี้ตาม Wikipedia ยังไม่ได้รับคำตอบว่า PEG สามารถแยกวิเคราะห์ CFG ที่กำหนดทั้งหมดได้จริงหรือไม่ )
รายการเต็ม
Lark ใช้ใบอนุญาต MIT
(เครื่องมือแบบสแตนด์อโลนอยู่ภายใต้ MPL2)
Lark ยอมรับคำขอแบบดึง ดูวิธีพัฒนา Lark
ขอบคุณมากสำหรับทุกคนที่มีส่วนร่วมจนถึงตอนนี้:
หากคุณชอบ Lark และอยากเห็นเราเติบโต โปรดพิจารณาสนับสนุนเรา!
คำถามเกี่ยวกับโค้ดควรถามใน Gitter หรือในประเด็นต่างๆ
สำหรับสิ่งอื่นใด ฉันสามารถติดต่อได้ทางอีเมลที่ erezshin ที่ gmail com
-- เอเรซ


