textgenrnn
T
ฝึกฝนโครงข่ายประสาทเทียมที่สร้างข้อความของคุณเองทุกขนาดและซับซ้อนบนชุดข้อมูลข้อความใดๆ ได้อย่างง่ายดายด้วยโค้ดเพียงไม่กี่บรรทัด หรือฝึกฝนข้อความอย่างรวดเร็วโดยใช้โมเดลที่ผ่านการฝึกอบรมมาแล้ว
textgenrnn เป็นโมดูล Python 3 ที่อยู่ด้านบนของ Keras/TensorFlow สำหรับสร้าง char-rnns พร้อมฟีเจอร์เจ๋งๆ มากมาย:
คุณสามารถเล่นกับ textgenrnn และฝึกไฟล์ข้อความด้วย GPU ได้ฟรี ใน Colaboratory Notebook นี้! อ่านโพสต์บนบล็อกนี้หรือดูวิดีโอนี้สำหรับข้อมูลเพิ่มเติม!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
โมเดลที่รวมไว้สามารถฝึกฝนข้อความใหม่ได้อย่างง่ายดาย และสามารถสร้างข้อความที่เหมาะสมได้ แม้จะผ่านข้อมูลที่ป้อนเพียงครั้งเดียวก็ตาม
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
น้ำหนักของโมเดลมีขนาดค่อนข้างเล็ก (2 MB บนดิสก์) และสามารถบันทึกและโหลดลงในอินสแตนซ์ textgenrnn ใหม่ได้อย่างง่ายดาย เป็นผลให้คุณสามารถเล่นกับโมเดลที่ได้รับการฝึกฝนเกี่ยวกับการส่งผ่านข้อมูลหลายร้อยครั้ง (อันที่จริง textgenrnn เรียนรู้ ได้ดี จนคุณต้องเพิ่มอุณหภูมิอย่างมากสำหรับผลงานสร้างสรรค์!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
คุณยังสามารถฝึกฝนโมเดลใหม่ได้ โดยรองรับการฝังระดับคำและเลเยอร์ RNN แบบสองทิศทางโดยการเพิ่ม new_model=True ให้กับฟังก์ชันการฝึกใดๆ
นอกจากนี้ยังเป็นไปได้ที่จะเข้าไปมีส่วนร่วมในวิธีที่ผลลัพธ์ออกมาทีละขั้นตอน โหมดโต้ตอบจะแนะนำตัวเลือก N อันดับแรก สำหรับอักขระ/คำถัดไป และให้คุณเลือกได้
เมื่อรัน textgenrnn ในเทอร์มินัล ให้ส่งผ่าน interactive=True และ top=N เพื่อ generate N มีค่าเริ่มต้นเป็น 3
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
สิ่งนี้สามารถเพิ่ม สัมผัสของมนุษย์ ให้กับเอาต์พุต รู้สึกเหมือนคุณเป็นนักเขียน! (อ้างอิง)
textgenrnn สามารถติดตั้งได้จาก pypi ผ่าน pip :
pip3 install textgenrnnสำหรับ textgenrnn ล่าสุด คุณต้องมี TensorFlow เวอร์ชัน 2.1.0 ขั้นต่ำ
คุณสามารถดูการสาธิตคุณสมบัติทั่วไปและตัวเลือกการกำหนดค่ารุ่นได้ใน Jupyter Notebook นี้
/datasets มีชุดข้อมูลตัวอย่างที่ใช้ข้อมูล Hacker News/Reddit สำหรับการฝึก textgenrnn
/weights มีโมเดลที่ได้รับการฝึกอบรมเพิ่มเติมในชุดข้อมูลที่กล่าวมาข้างต้น ซึ่งสามารถโหลดลงใน textgenrnn ได้
/outputs มีตัวอย่างข้อความที่สร้างจากโมเดลที่ได้รับการฝึกอบรมข้างต้น
textgenrnn มีพื้นฐานมาจากโปรเจ็กต์ char-rnn โดย Andrej Karpathy พร้อมการปรับปรุงสมัยใหม่บางอย่าง เช่น ความสามารถในการทำงานกับลำดับข้อความที่เล็กมาก
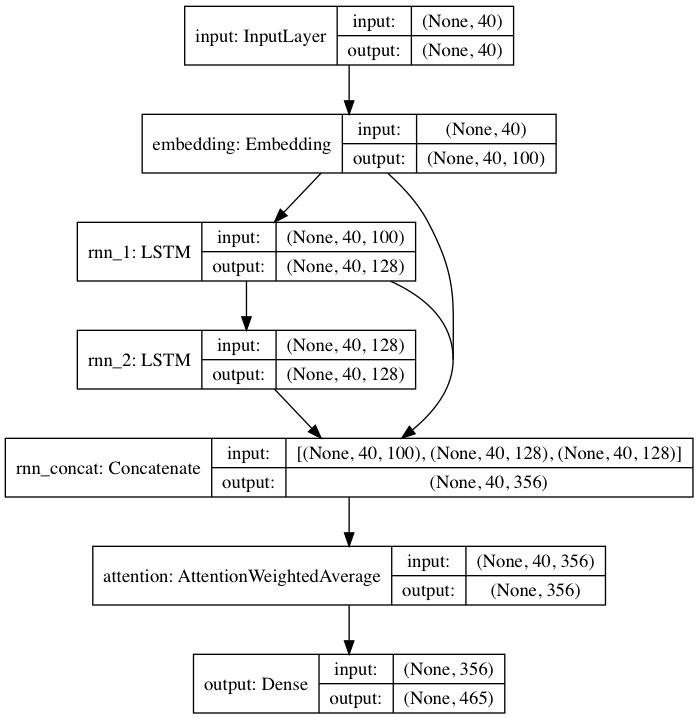
โมเดลที่ได้รับการฝึกล่วงหน้าที่รวมมานั้นเป็นไปตามสถาปัตยกรรมโครงข่ายประสาทเทียมที่ได้รับแรงบันดาลใจจาก DeepMoji สำหรับโมเดลเริ่มต้น textgenrnn รับอินพุตสูงสุด 40 อักขระ แปลงอักขระแต่ละตัวเป็นเวกเตอร์ที่ฝังอักขระ 100-D และป้อนอักขระเหล่านั้นลงในเลเยอร์ที่เกิดซ้ำของหน่วยความจำระยะสั้นระยะยาว (LSTM) ขนาด 128 เซลล์ จากนั้นเอาต์พุตเหล่านั้นจะถูกป้อนเข้าไปใน LSTM ขนาด 128 เซลล์ อีกอัน จากนั้นทั้งสามเลเยอร์จะถูกป้อนเข้าไปในเลเยอร์ Attention เพื่อชั่งน้ำหนักคุณลักษณะชั่วคราวที่สำคัญที่สุดและเฉลี่ยพวกมันเข้าด้วยกัน (และเนื่องจากการฝัง + LSTM ที่ 1 นั้นเชื่อมต่อแบบข้ามไปยังเลเยอร์ Attention การอัปเดตโมเดลจึงสามารถเผยแพร่กลับได้ง่ายขึ้นและป้องกันการหายไป การไล่ระดับสี) เอาต์พุตนั้นแมปกับความน่าจะเป็นสำหรับอักขระที่แตกต่างกันสูงสุด 394 ตัวซึ่งเป็นอักขระถัดไปในลำดับ รวมถึงอักขระตัวพิมพ์ใหญ่ ตัวพิมพ์เล็ก เครื่องหมายวรรคตอน และอีโมจิ (หากฝึกโมเดลใหม่บนชุดข้อมูลใหม่ ก็สามารถกำหนดค่าพารามิเตอร์ตัวเลขด้านบนทั้งหมดได้)
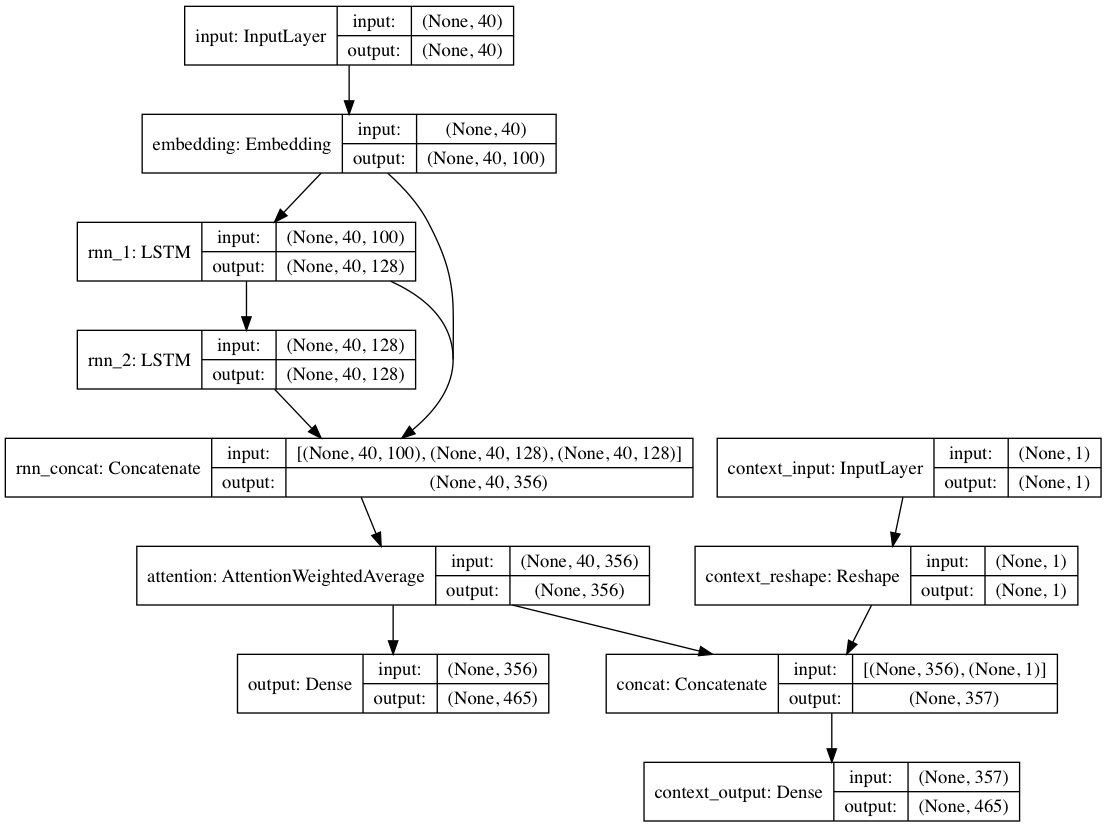
อีกทางหนึ่ง หากมีการระบุป้ายกำกับบริบทให้กับเอกสารข้อความแต่ละฉบับ โมเดลสามารถฝึกได้ในโหมดบริบท โดยที่โมเดลจะเรียนรู้ข้อความ ที่กำหนดบริบท ดังนั้นเลเยอร์ที่เกิดซ้ำจะเรียนรู้ภาษา ที่ไม่มีบริบท เส้นทางแบบข้อความเท่านั้นสามารถดึงกลับออกจากเลเยอร์ที่ไม่มีบริบทได้ โดยรวมแล้ว ส่งผลให้การฝึกอบรมเร็วขึ้นมากและประสิทธิภาพของโมเดลเชิงปริมาณและคุณภาพดีกว่าการฝึกโมเดลโดยใช้ข้อความเพียงอย่างเดียว
ตุ้มน้ำหนักโมเดลที่รวมอยู่ในแพ็คเกจได้รับการฝึกฝนกับเอกสารข้อความนับแสนจากการส่ง Reddit (ผ่าน BigQuery) จาก subreddits ที่หลากหลาย มาก เครือข่ายยังได้รับการฝึกอบรมโดยใช้แนวทาง decontextual ที่ระบุไว้ข้างต้น เพื่อปรับปรุงประสิทธิภาพการฝึกอบรมและลดอคติด้านเผด็จการ
เมื่อปรับแต่งโมเดลอย่างละเอียดบนชุดข้อมูลใหม่ของข้อความโดยใช้ textgenrnn เลเยอร์ทั้งหมดจะได้รับการฝึกใหม่ อย่างไรก็ตาม เนื่องจากเครือข่ายที่ได้รับการฝึกล่วงหน้าแบบเดิมมี "ความรู้" ที่แข็งแกร่งกว่ามากในตอนแรก textgenrnn ใหม่จะฝึกได้เร็วขึ้นและแม่นยำยิ่งขึ้นในท้ายที่สุด และอาจเรียนรู้ความสัมพันธ์ใหม่ที่ไม่มีอยู่ในชุดข้อมูลดั้งเดิม (เช่น การฝังอักขระที่ฝึกไว้ล่วงหน้าจะรวมถึงบริบทด้วย สำหรับอักขระสำหรับไวยากรณ์อินเทอร์เน็ตสมัยใหม่ทุกประเภทที่เป็นไปได้)
นอกจากนี้ การฝึกขึ้นใหม่เสร็จสิ้นด้วยเครื่องมือเพิ่มประสิทธิภาพตามโมเมนตัมและอัตราการเรียนรู้ที่ลดลงเป็นเส้นตรง ซึ่งทั้งสองอย่างนี้ป้องกันการระเบิดของการไล่ระดับสี และทำให้มีโอกาสน้อยลงมากที่แบบจำลองจะแตกต่างออกไปหลังจากการฝึกฝนมาเป็นเวลานาน
คุณจะไม่ได้รับข้อความที่สร้างขึ้นอย่างมีคุณภาพ 100% แม้ว่าจะมีโครงข่ายประสาทเทียมที่ได้รับการฝึกมาอย่างดีก็ตาม นั่นคือเหตุผลหลักที่โพสต์บล็อกแบบไวรัล/ทวีต Twitter ที่ใช้การสร้างข้อความ NN มักจะสร้างข้อความจำนวนมากและดูแลจัดการ/แก้ไขข้อความที่ดีที่สุดในภายหลัง
ผลลัพธ์จะแตกต่างกันอย่างมากระหว่างชุดข้อมูล เนื่องจากโครงข่ายประสาทเทียมที่ได้รับการฝึกไว้มีขนาดค่อนข้างเล็ก จึงไม่สามารถจัดเก็บข้อมูลได้มากเท่ากับที่ RNN มักอวดอ้างในบล็อกโพสต์ เพื่อผลลัพธ์ที่ดีที่สุด ให้ใช้ชุดข้อมูลที่มีเอกสารอย่างน้อย 2,000-5,000 รายการ หากชุดข้อมูลมีขนาดเล็ก คุณจะต้องฝึกให้นานขึ้นโดยตั้ง num_epochs ให้สูงขึ้นเมื่อเรียกใช้วิธีการฝึกและ/หรือฝึกโมเดลใหม่ตั้งแต่เริ่มต้น ถึงกระนั้น ในปัจจุบันยังไม่มีการศึกษาสำนึกที่ดีในการกำหนดโมเดลที่ "ดี"
ไม่จำเป็นต้องใช้ GPU ในการฝึก textgenrnn อีกครั้ง แต่จะใช้เวลานานกว่ามากในการฝึก CPU หากคุณใช้ GPU ฉันแนะนำให้เพิ่มพารามิเตอร์ batch_size เพื่อการใช้งานฮาร์ดแวร์ที่ดีขึ้น
เอกสารที่เป็นทางการมากขึ้น
การใช้งานบนเว็บโดยใช้ tensorflow.js (ทำงานได้ดีเป็นพิเศษเนื่องจากขนาดเครือข่ายที่เล็ก)
วิธีแสดงภาพผลลัพธ์ของชั้นความสนใจเพื่อดูว่าเครือข่าย "เรียนรู้" อย่างไร
โหมดที่อนุญาตให้ใช้สถาปัตยกรรมโมเดลสำหรับการสนทนาแชทบอท (อาจเผยแพร่เป็นโปรเจ็กต์แยกต่างหาก)
เจาะลึกบริบทมากขึ้น (บริบทเชิงตำแหน่ง + อนุญาตให้มีป้ายกำกับบริบทหลายรายการ)
เครือข่ายที่ได้รับการฝึกอบรมล่วงหน้าขนาดใหญ่ขึ้น ซึ่งสามารถรองรับลำดับอักขระที่ยาวขึ้นและความเข้าใจภาษาที่ลึกซึ้งยิ่งขึ้น ทำให้เกิดการสร้างประโยคที่ดีขึ้น
การเปิดใช้งาน softmax แบบลำดับชั้นสำหรับโมเดลระดับคำ (เมื่อ Keras ได้รับการสนับสนุนอย่างดี)
FP16 สำหรับการฝึกอบรมที่รวดเร็วเป็นพิเศษเกี่ยวกับ Volta/TPU (เมื่อ Keras ได้รับการรองรับเป็นอย่างดี)
แม็กซ์ วูล์ฟ (@minimaxir)
โปรเจ็กต์โอเพ่นซอร์สของ Max ได้รับการสนับสนุนจาก Patreon ของเขา หากคุณพบว่าโครงการนี้มีประโยชน์ เราจะยินดีอย่างยิ่งที่จะบริจาคเงินให้กับ Patreon และจะนำไปใช้อย่างสร้างสรรค์
Andrej Karpathy สำหรับข้อเสนอดั้งเดิมของ char-rnn ผ่านทางโพสต์บล็อก ประสิทธิผลที่ไม่สมเหตุสมผลของโครงข่ายประสาทเทียมที่เกิดซ้ำ
Daniel Grijalva สำหรับการสนับสนุนโหมดโต้ตอบ
เอ็มไอที
รหัสชั้นความสนใจที่ใช้จาก DeepMoji (ได้รับใบอนุญาตจาก MIT)


