cleanrl
v1.0.0 CleanRL Release ?
CleanRL เป็นไลบรารี Deep Reinforcement Learning ที่ให้การใช้งานไฟล์เดียวคุณภาพสูงพร้อมฟีเจอร์ที่เป็นมิตรกับการวิจัย การใช้งานนั้นสะอาดและเรียบง่าย แต่เราสามารถปรับขนาดเพื่อทำการทดลองนับพันครั้งโดยใช้ AWS Batch คุณสมบัติเด่นของ CleanRL คือ:
ppo_atari.py ของเรามีโค้ดเพียง 340 บรรทัด แต่มีรายละเอียดการใช้งานทั้งหมดเกี่ยวกับวิธีการทำงานของ PPO กับเกม Atari ดังนั้นจึงเป็นการใช้งานอ้างอิงที่ดีเยี่ยมในการอ่านสำหรับผู้ที่ไม่ต้องการอ่านไลบรารีแบบโมดูลาร์ทั้งหมดคุณสามารถอ่านเพิ่มเติมเกี่ยวกับ CleanRL ได้ในรายงานและเอกสารประกอบของ JMLR ของเรา
โครงการที่เกี่ยวข้องกับ CleanRL ที่โดดเด่น:
การสนับสนุนสำหรับโรงยิม : Farama-Foundation/Gymnasium เป็น
openai/gymรุ่นต่อไปที่จะยังคงได้รับการบำรุงรักษาและแนะนำคุณสมบัติใหม่ๆ โปรดดูประกาศของพวกเขาสำหรับรายละเอียดเพิ่มเติม เรากำลังย้ายไปgymnasiumและสามารถติดตามความคืบหน้าได้ใน vwxyzjn/cleanrl#277
หมายเหตุ : CleanRL ไม่ใช่ ไลบรารีแบบโมดูลาร์ ดังนั้นจึงไม่ได้มีไว้สำหรับนำเข้า เราทำให้รายละเอียดการใช้งานทั้งหมดของตัวแปรอัลกอริทึม DRL ง่ายต่อการเข้าใจ โดยต้องเสียโค้ดที่ซ้ำกัน ดังนั้น CleanRL จึงมาพร้อมกับข้อดีและข้อเสียในตัวมันเอง คุณควรพิจารณาใช้ CleanRL หากคุณต้องการ 1) ทำความเข้าใจรายละเอียดการใช้งานทั้งหมดของตัวแปรของอัลกอริทึม หรือ 2) คุณสมบัติขั้นสูงต้นแบบที่ไลบรารี DRL แบบโมดูลาร์อื่นๆ ไม่รองรับ (CleanRL มีบรรทัดโค้ดน้อยที่สุด ดังนั้นจึงให้ประสบการณ์การแก้ไขข้อบกพร่องที่ยอดเยี่ยมและคุณก็ไม่ต้อง ไม่มีคลาสย่อยมากมายเหมือนบางครั้งในไลบรารี DRL แบบแยกส่วน)
ข้อกำหนดเบื้องต้น:
หากต้องการดำเนินการทดสอบในเครื่อง ให้ลองทำสิ่งต่อไปนี้:
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runsหากต้องการใช้การติดตามการทดลองด้วย wandb ให้เรียกใช้
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest หากคุณไม่ได้ใช้ poetry คุณสามารถติดตั้ง CleanRL ด้วย requirements.txt :
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txtหากต้องการรันสคริปต์การฝึกในเกมอื่น:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
คุณยังอาจใช้สภาพแวดล้อมการพัฒนาที่สร้างไว้ล่วงหน้าซึ่งโฮสต์ใน Gitpod ได้:
| อัลกอริทึม | ตัวแปรที่นำไปใช้ |
|---|---|
| ✅ การไล่ระดับนโยบายใกล้เคียง (PPO) | ppo.py เอกสาร |
ppo_atari.py เอกสาร | |
ppo_continuous_action.py เอกสาร | |
ppo_atari_lstm.py , เอกสาร | |
ppo_atari_envpool.py , เอกสาร | |
ppo_atari_envpool_xla_jax.py , เอกสาร | |
ppo_atari_envpool_xla_jax_scan.py เอกสาร) | |
ppo_procgen.py เอกสาร | |
ppo_atari_multigpu.py , เอกสาร | |
ppo_pettingzoo_ma_atari.py , เอกสาร | |
ppo_continuous_action_isaacgym.py , เอกสาร | |
ppo_trxl.py , เอกสาร | |
| ✅ การเรียนรู้เชิงลึก (DQN) | dqn.py เอกสาร |
dqn_atari.py เอกสาร | |
dqn_jax.py เอกสาร | |
dqn_atari_jax.py เอกสาร | |
| ✅ หมวดหมู่ DQN (C51) | c51.py เอกสาร |
c51_atari.py เอกสาร | |
c51_jax.py เอกสาร | |
c51_atari_jax.py , เอกสาร | |
| ✅ ซอฟท์นักแสดง-นักวิจารณ์ (SAC) | sac_continuous_action.py เอกสาร |
sac_atari.py เอกสาร | |
| ✅ การไล่ระดับนโยบายเชิงกำหนดเชิงลึก (DDPG) | ddpg_continuous_action.py , เอกสาร |
ddpg_continuous_action_jax.py , เอกสาร | |
| ✅ การไล่ระดับนโยบายกำหนดลึกแบบล่าช้าแบบคู่ (TD3) | td3_continuous_action.py เอกสาร |
td3_continuous_action_jax.py เอกสาร | |
| ✅ การไล่ระดับนโยบายระยะสุดท้าย (PPG) | ppg_procgen.py , เอกสาร |
| ✅ การกลั่นแบบเครือข่ายแบบสุ่ม (RND) | ppo_rnd_envpool.py , เอกสาร |
| ✅ คิวแด็กเกอร์ | qdagger_dqn_atari_impalacnn.py , เอกสาร |
qdagger_dqn_atari_jax_impalacnn.py , เอกสาร |
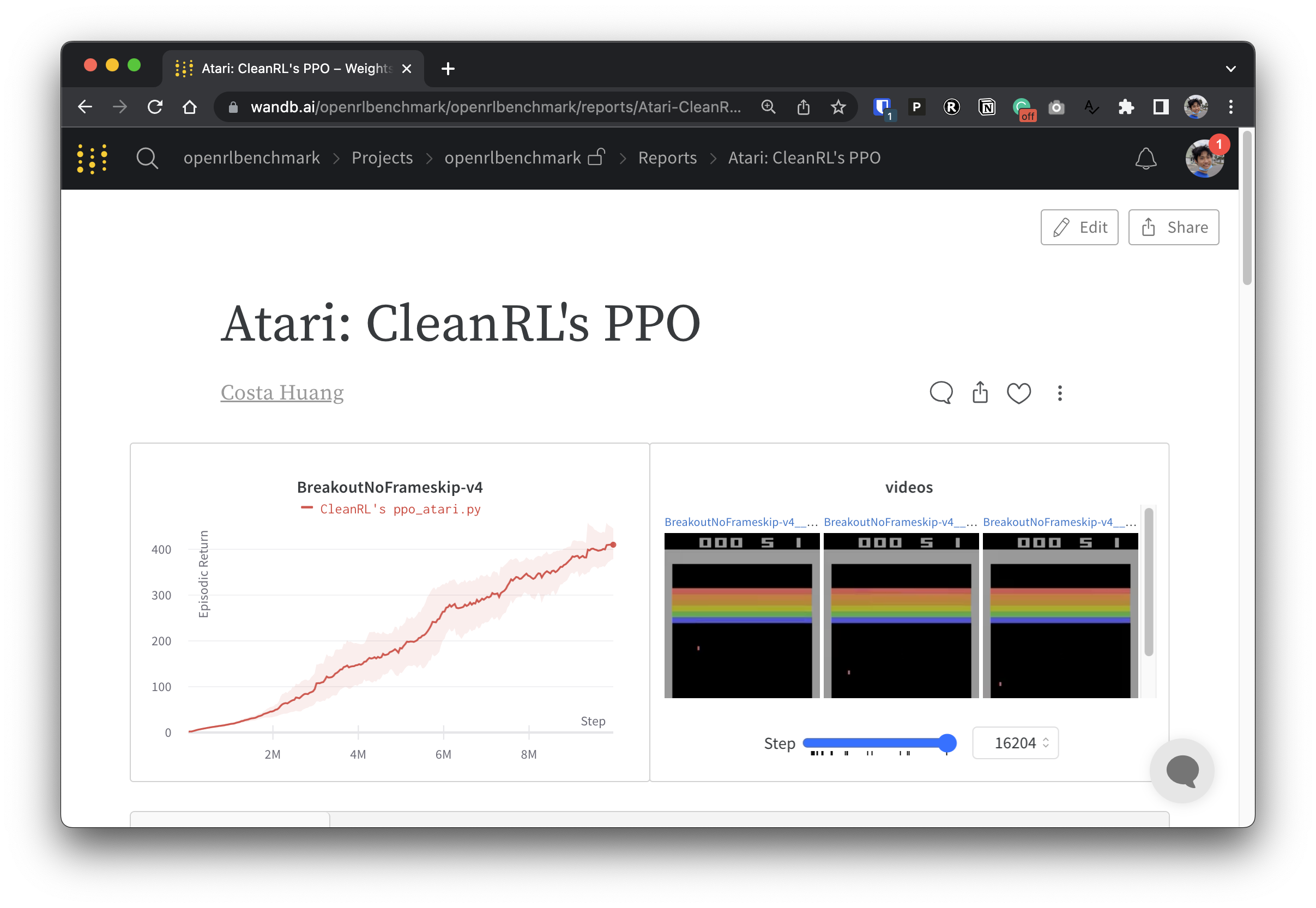
เพื่อให้ข้อมูลการทดลองของเราโปร่งใส CleanRL เข้าร่วมในโครงการที่เกี่ยวข้องที่เรียกว่า Open RL Benchmark ซึ่งประกอบด้วยการทดลองที่ติดตามจากไลบรารี DRL ยอดนิยม เช่น Stable-baselines3, openai/baselines, jaxrl และอื่นๆ ของเรา
ไปที่ https://benchmark.cleanrl.dev/ เพื่อดูคอลเลกชั่นรายงานน้ำหนักและอคติที่แสดงการทดลอง DRL ที่ติดตาม รายงานเป็นแบบอินเทอร์แอคทีฟ และนักวิจัยสามารถสืบค้นข้อมูล เช่น การใช้งาน GPU และวิดีโอการเล่นเกมของตัวแทนซึ่งปกติแล้วจะหาได้ยากในการวัดประสิทธิภาพ RL อื่นๆ ในอนาคต Open RL Benchmark มีแนวโน้มที่จะจัดเตรียมชุดข้อมูล API เพื่อให้นักวิจัยเข้าถึงข้อมูลได้อย่างง่ายดาย (ดู repo)
เรามีชุมชน Discord สำหรับการสนับสนุน อย่าลังเลที่จะถามคำถาม ยินดีต้อนรับการโพสต์ในประเด็น Github และ PR นอกจากนี้ วิดีโอที่บันทึกไว้ในอดีตของเรายังมีอยู่ใน YouTube
หากคุณใช้ CleanRL ในงานของคุณ โปรดอ้างอิงเอกสารทางเทคนิคของเรา:
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL เป็นชุมชนที่ขับเคลื่อนโดยโครงการ และผู้มีส่วนร่วมของเราทำการทดลองกับฮาร์ดแวร์ที่หลากหลาย


