3DDFA
1.0.0
โดย เจี้ยนจู้ กัว.

[อัพเดท]
2022.5.14 : แนะนำให้ใช้ Python ในการทำโปรไฟล์ใบหน้า: face_pose_augmentation2020.8.30 : โมเดลและรหัสที่ได้รับการฝึกล่วงหน้าของ ECCV-20 ได้รับการเผยแพร่สู่สาธารณะบน 3DDFA_V2 ลิขสิทธิ์ได้รับการอธิบายโดย Jianzhu Guo และกลุ่ม CBSR2020.8.2 : อัปเดต พอร์ต c++ แบบง่าย ของโปรเจ็กต์นี้2020.7.3 : การขยายงาน ไปสู่การจัดตำแหน่งใบหน้าหนาแน่น 3 มิติที่รวดเร็ว แม่นยำ และเสถียร ได้รับการยอมรับโดย ECCV 2020 ดูหน้าของฉันสำหรับรายละเอียดเพิ่มเติม2019.9.15 : การอัปเดตบางอย่าง โปรดดูรายละเอียดที่คอมมิต2019.6.17 : เพิ่มวิดีโอสาธิตโดย zjjMaiMai2019.5.2 : การประเมินความเร็วการอนุมานบน CPU ด้วย PyTorch v1.1.0 ดูที่นี่ และ speed_cpu.py2019.4.27 : ไปป์ไลน์การเรนเดอร์แบบธรรมดาที่ทำงานที่ ~25ms/frame (720p) โปรดดูรายละเอียดเพิ่มเติมที่ rendering.py2019.4.24 : ให้บริการอาคารสาธิตของ obama โปรดดูรายละเอียดเพิ่มเติมที่ demo@obama/readme.md2019.3.28 : อัปเดตบางส่วน2018.12.23 : เพิ่มคุณสมบัติหลายประการ: การประมาณความลึกของภาพ, PNCC, คุณสมบัติ PAF และการทำให้เป็นอนุกรม obj ดูตัวเลือก dump_depth , dump_pncc , dump_paf , dump_obj สำหรับรายละเอียดเพิ่มเติม2018.12.2 : รองรับการครอบตัดใบหน้าแบบไม่มีจุดสังเกต ดูตัวเลือก dlib_landmark2018.12.1 : ปรับแต่งโค้ดและเพิ่มฟีเจอร์การประมาณค่า ดูรายละเอียดเพิ่มเติมที่ utils/estimate_pose.py2018.11.17 : ปรับแต่งโค้ดและแมปจุดยอด 3 มิติกับพื้นที่รูปภาพดั้งเดิม2018.11.11 : อัปเดตไปป์ไลน์การอนุมานจากต้นทางถึงปลายทาง: อนุมาน/ทำให้รูปร่างใบหน้า 3 มิติเป็นอนุกรม และจุดสังเกต 68 จุดด้วยรูปภาพที่กำหนดเองหนึ่งภาพ โปรดดูรายละเอียดเพิ่มเติมที่ readme.md ด้านล่าง2018.10.4 : เพิ่มการสาธิตการเรนเดอร์ Matlab face mesh ในการแสดงภาพ2018.9.9 : เพิ่มการประมวลผลล่วงหน้าของการครอบตัดใบหน้าในเกณฑ์มาตรฐาน[สิ่งที่ต้องทำ]
การซื้อคืนนี้ถือเป็นเวอร์ชันปรับปรุงของ pytorch ของกระดาษ: การจัดตำแหน่งใบหน้าในช่วงท่าทางเต็ม: โซลูชันทั้งหมด 3 มิติ มีการเพิ่มผลงานหลายชิ้นนอกเหนือจากเอกสารต้นฉบับ รวมถึงการฝึกอบรมแบบเรียลไทม์ กลยุทธ์การฝึกอบรม ดังนั้น repo นี้จึงเป็นเวอร์ชันปรับปรุงของงานต้นฉบับ จนถึงตอนนี้ repo นี้เผยแพร่โมเดล pytorch ขั้นแรกที่ได้รับการฝึกอบรมล่วงหน้าของโครงสร้าง MobileNet-V1 ซึ่งเป็นชุดข้อมูลการฝึกอบรมและการทดสอบที่ประมวลผลล่วงหน้า และฐานโค้ด โปรดทราบว่าเวลาในการอนุมานประมาณ 0.27 มิลลิวินาทีต่อภาพ (ชุดอินพุตที่มี 128 ภาพเป็นชุดอินพุต) บน GeForce GTX TITAN X
Repo นี้จะอัปเดตต่อไปในเวลาว่าง และยินดีรับฟังปัญหาที่สำคัญและการประชาสัมพันธ์
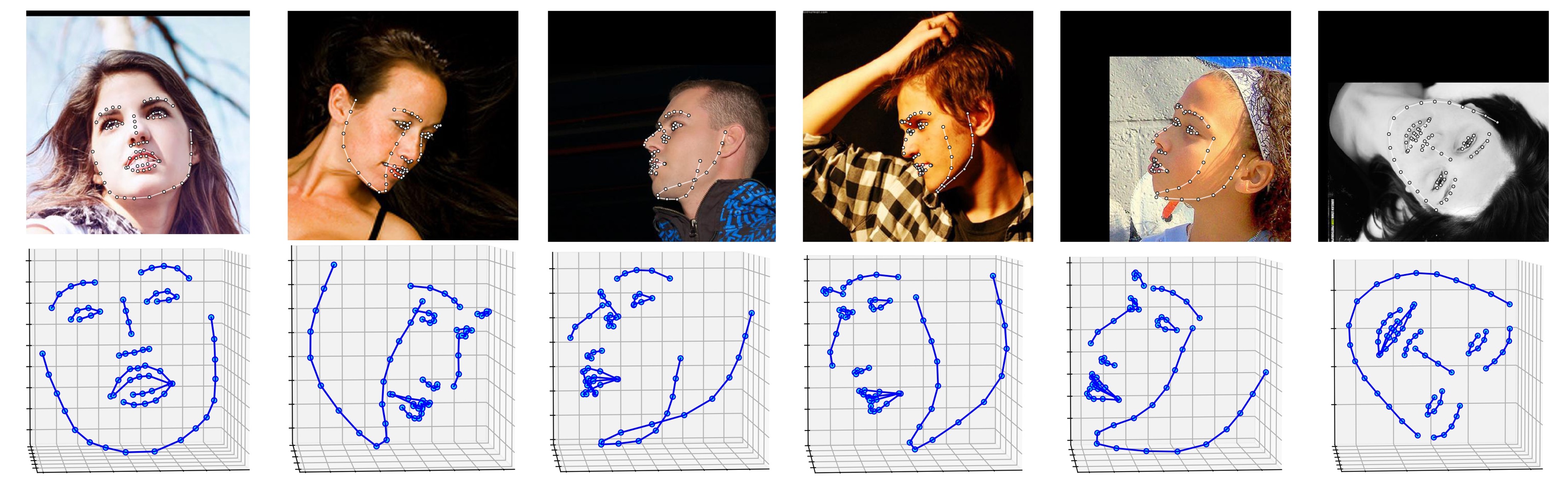
ผลลัพธ์หลายรายการในชุดข้อมูล ALFW-2000 (อนุมานจากโมเดล Phase1_wpdc_vdc.pth.tar ) แสดงอยู่ด้านล่าง





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
นอกจากนี้ ฉันขอแนะนำอย่างยิ่งให้ใช้ Python3.6+ แทนเวอร์ชันเก่าเพื่อการออกแบบที่ดีขึ้น
โคลน repo นี้ (อาจใช้เวลาสักครู่เนื่องจากมีขนาดใหญ่เล็กน้อย)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
จากนั้น ดาวน์โหลดโมเดลก่อนการฝึกอบรมสถานที่สำคัญของ dlib ใน Google Drive หรือ Baidu Yun และใส่ลงในไดเร็กทอรี models (เพื่อลดขนาด repo นี้ ฉันจะลบไฟล์ไบนารีขนาดใหญ่บางไฟล์รวมถึงโมเดลนี้ด้วย ดังนั้นคุณควรดาวน์โหลดมัน : ) )
สร้างโมดูล Cython (เพียงบรรทัดเดียวสำหรับการสร้าง)
cd utils/cython
python3 setup.py build_ext -i
นี่เป็นการเร่งการประมาณความลึกและการเรนเดอร์ PNCC เนื่องจาก Python ช้าเกินไปในการวนซ้ำ
เรียกใช้ main.py โดยมีรูปภาพที่กำหนดเองเป็นอินพุต
python3 main.py -f samples/test1.jpg
หากคุณเห็นบันทึกเอาต์พุตเหล่านี้ในเทอร์มินัล แสดงว่าคุณเรียกใช้งานได้สำเร็จ
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
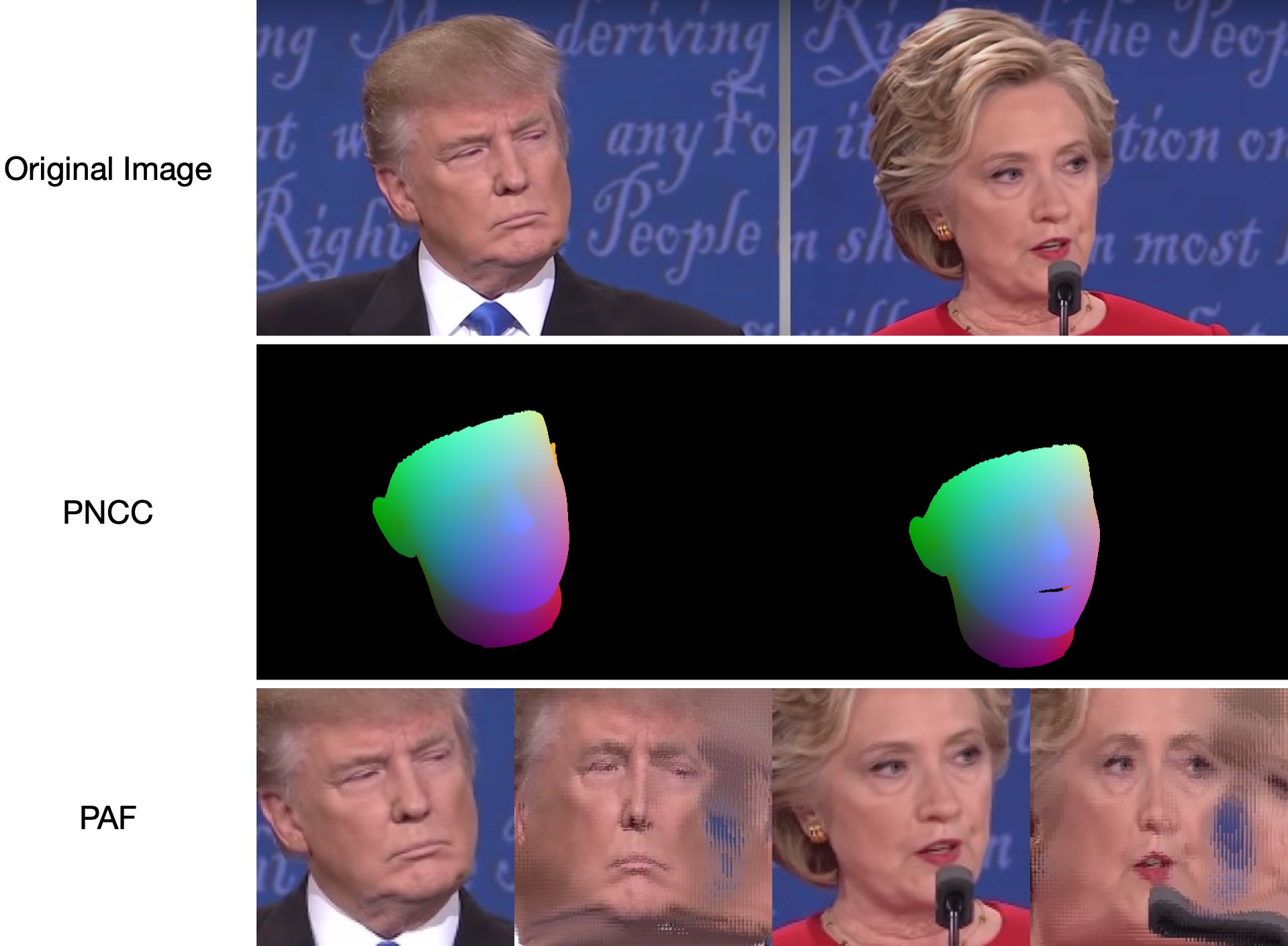
เนื่องจาก test1.jpg มีสองหน้า จึงมีไฟล์ .ply และ .obj สองไฟล์ (สามารถเรนเดอร์ได้โดย Meshlab หรือ Microsoft 3D Builder) การประมาณความลึก, PNCC, PAF และการประมาณท่าทางล้วนตั้งค่าเป็นจริงตามค่าเริ่มต้น โปรดเรียกใช้ python3 main.py -h หรือตรวจสอบโค้ดเพื่อดูรายละเอียดเพิ่มเติม
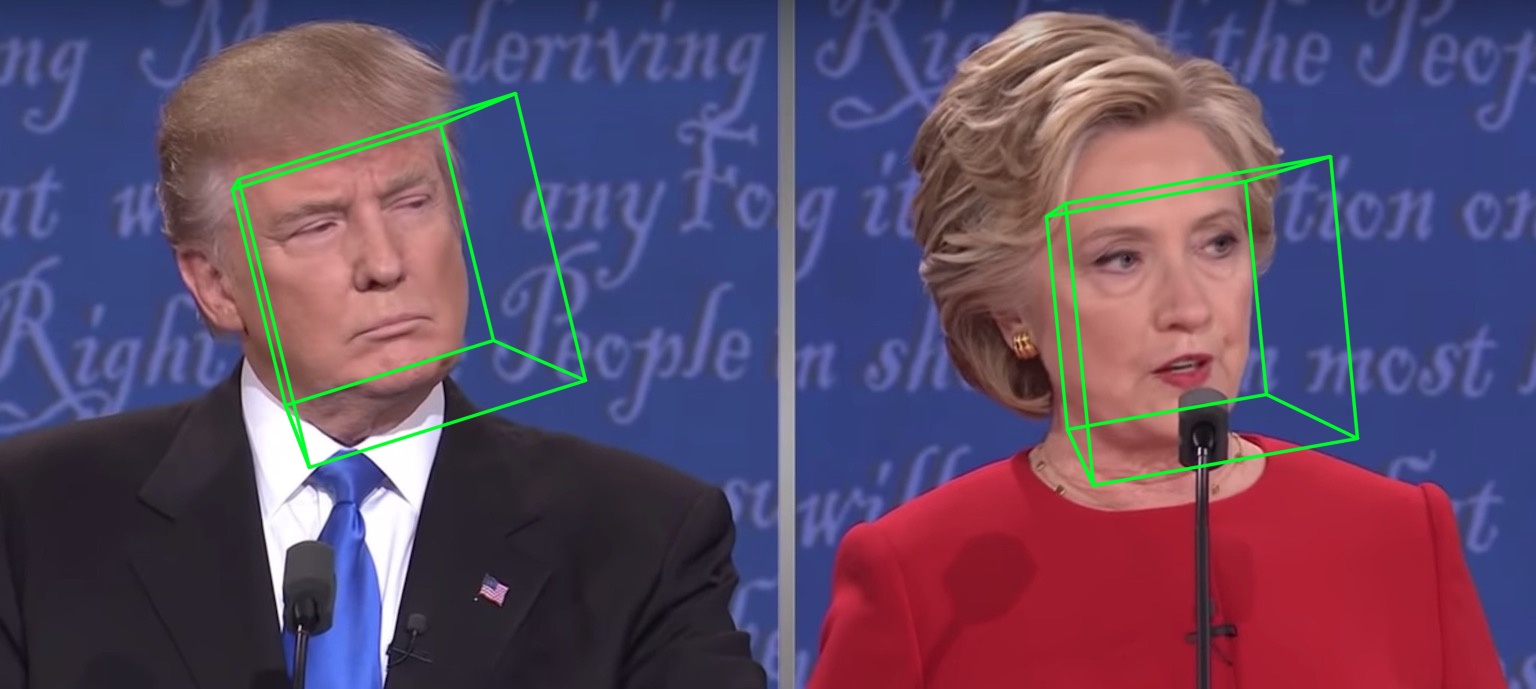
samples/test1_3DDFA.jpg และ samples/test1_pose.jpg แสดงอยู่ด้านล่าง:

ตัวอย่างเพิ่มเติม
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
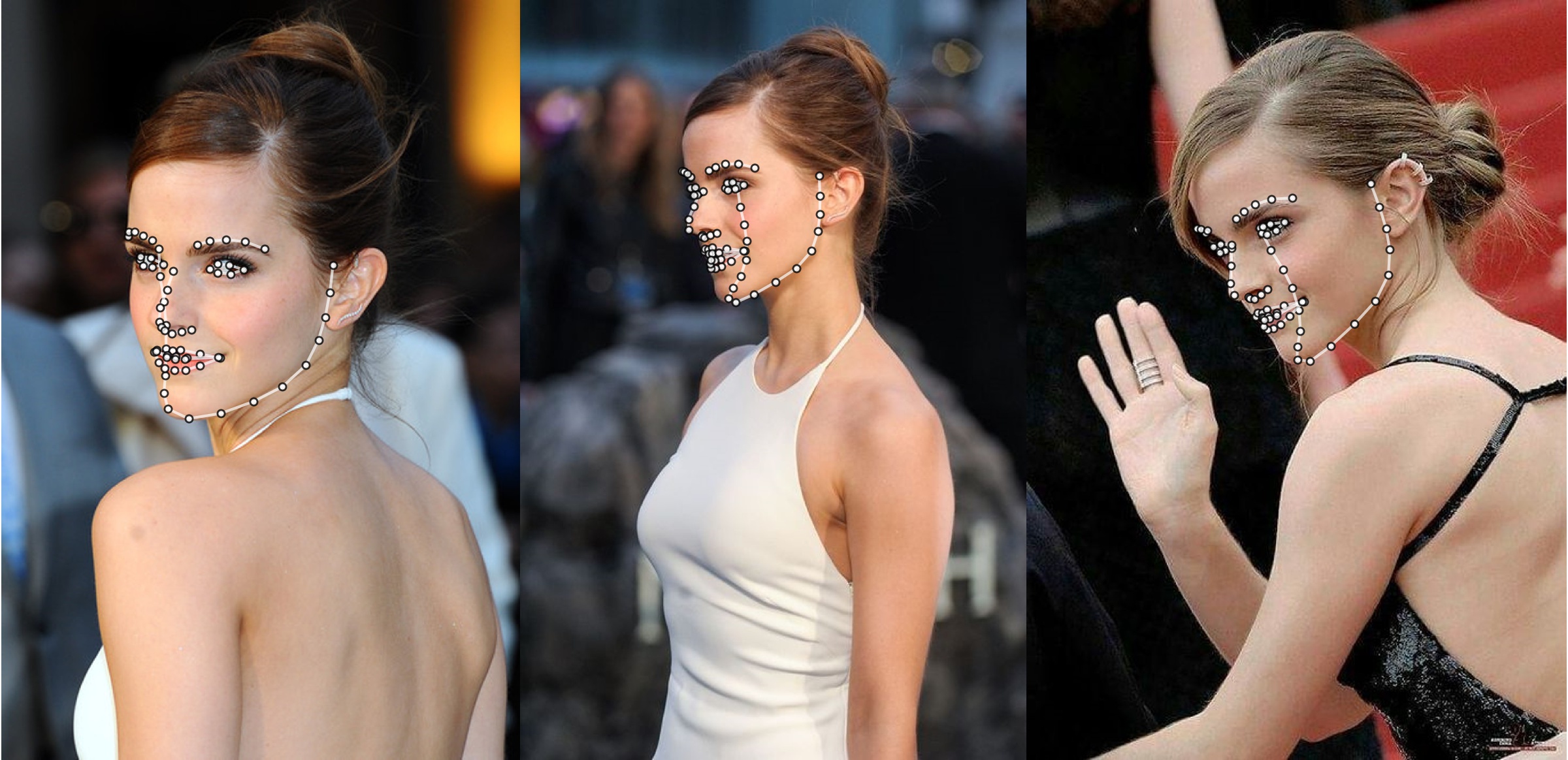
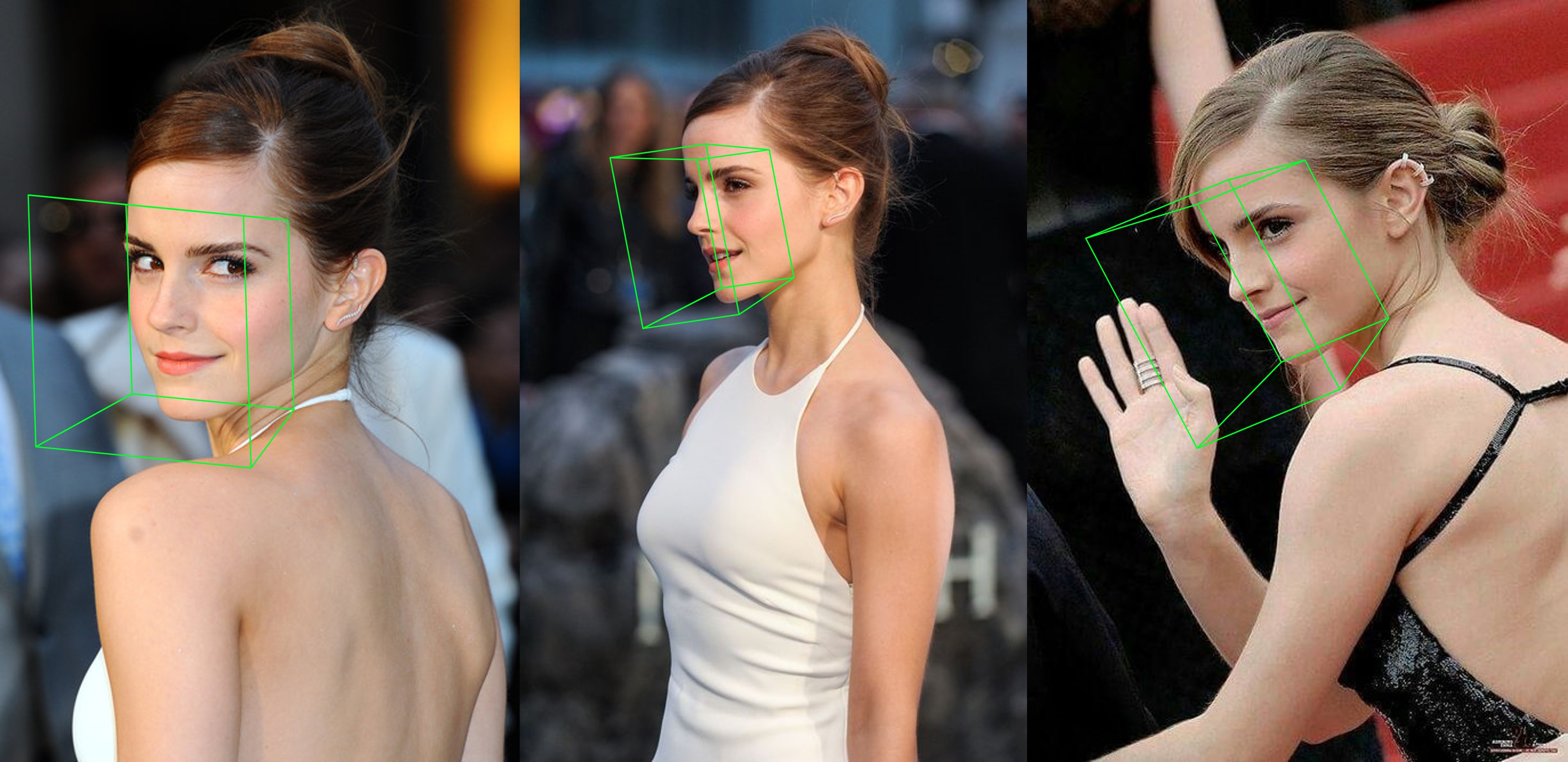
แค่วิ่ง
python3 speed_cpu.py
บน MBP ของฉัน (i5-8259U CPU @ 2.30GHz บน MacBook Pro ขนาด 13 นิ้ว) ที่ใช้ PyTorch v1.1.0 โดยมีอินพุตเดียวเอาต์พุตที่ทำงานอยู่คือ:
Inference speed: 14.50±0.11 ms
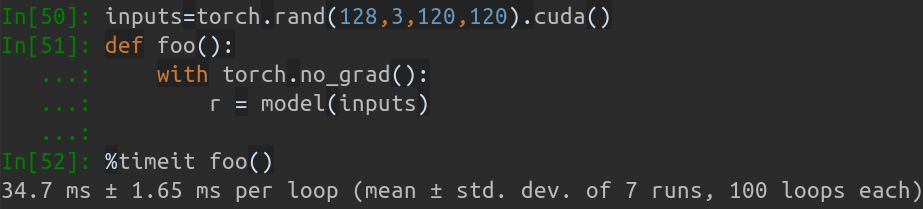
เมื่อขนาดแบตช์อินพุตคือ 128 เวลาอนุมานรวมของ MobileNet-V1 จะใช้เวลาประมาณ 34.7 มิลลิวินาที ความเร็วเฉลี่ยอยู่ที่ประมาณ 0.27ms/pic
สคริปต์การฝึกอบรมอยู่ในไดเร็กทอรี training ทรัพยากรที่เกี่ยวข้องอยู่ในตารางด้านล่าง
| ข้อมูล | ลิงค์ดาวน์โหลด | คำอธิบาย |
|---|---|---|
| รถไฟ.configs | BaiduYun หรือ Google Drive, 217M | ไดเร็กทอรีที่มีพารามิเตอร์ 3DMM และรายการไฟล์ของชุดข้อมูลการฝึกอบรม |
| train_aug_120x120.zip | BaiduYun หรือ Google Drive, 2.15G | รูปภาพที่ครอบตัดของชุดข้อมูลการฝึกอบรมการเสริม |
| test.data.zip | BaiduYun หรือ Google Drive, 151M | ภาพที่ครอบตัดของชุดทดสอบ AFLW และ ALFW-2000-3D |
หลังจากเตรียมชุดข้อมูลการฝึกอบรมและไฟล์การกำหนดค่าแล้ว ให้ไปที่ไดเร็กทอรี training และเรียกใช้สคริปต์ bash เพื่อฝึกอบรม train_wpdc.sh , train_vdc.sh และ train_pdc.sh เป็นตัวอย่างของสคริปต์การฝึกอบรม หลังจากกำหนดค่าชุดการฝึกอบรมและการทดสอบแล้ว ให้เรียกใช้ชุดการฝึกอบรมเหล่านั้น ใช้ train_wpdc.sh เช่นด้านล่าง:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
พารามิเตอร์การฝึกอบรมเฉพาะทั้งหมดจะแสดงเป็นสคริปต์ทุบตี รวมถึงอัตราการเรียนรู้ ขนาดชุดย่อย ยุค และอื่นๆ
ขั้นแรก คุณควรดาวน์โหลดชุดทดสอบที่ครอบตัด ALFW และ ALFW-2000-3D ใน test.data.zip จากนั้นแตกไฟล์และวางไว้ในไดเร็กทอรีราก จากนั้น รันโค้ดการวัดประสิทธิภาพโดยระบุพาธโมเดลที่ผ่านการฝึกอบรม ฉันได้จัดเตรียมโมเดลที่ได้รับการฝึกล่วงหน้ามาแล้วห้าโมเดลในไดเร็กทอรี models (ดูในตารางด้านล่าง) โมเดลเหล่านี้ได้รับการฝึกฝนโดยใช้การสูญเสียที่แตกต่างกันในระยะแรก ขนาดโมเดลประมาณ 13M เนื่องจากประสิทธิภาพสูงของโครงสร้าง MobileNet-V1
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
ประสิทธิภาพของโมเดลที่ได้รับการฝึกล่วงหน้ามีดังต่อไปนี้ ในระยะแรก ประสิทธิผลของการสูญเสียที่แตกต่างกันจะเป็นไปตามลำดับ: WPDC > VDC > PDC ขณะที่กลยุทธ์การใช้ VDC เพื่อปรับแต่ง WPDC ก็ได้ผลลัพธ์ที่ดีที่สุด
| แบบอย่าง | แอฟแอลดับบลิว (21 แต้ม) | แอฟแอลดับเบิลยู 2000-3D (68 แต้ม) | ลิงค์ดาวน์โหลด |
|---|---|---|---|
| เฟส1_pdc.pth.tar | 6.956±0.981 | 5.644±1.323 | ไป่ตู้ หยุน หรือ Google Drive |
| เฟส1_vdc.pth.tar | 6.717±0.924 | 5.030±1.044 | ไป่ตู้ หยุน หรือ Google Drive |
| เฟส1_wpdc.pth.tar | 6.348±0.929 | 4.759±0.996 | ไป่ตู้ หยุน หรือ Google Drive |
| เฟส1_wpdc_vdc.pth.tar | 5.401±0.754 | 4.252±0.976 | ในการซื้อคืนครั้งนี้ |
เชื่อฉันเถอะว่ากรอบการทำงานของ repo นี้สามารถบรรลุประสิทธิภาพที่ดีกว่า PRNet โดยไม่ต้องเพิ่มงบประมาณการคำนวณใดๆ งานที่เกี่ยวข้องอยู่ระหว่างการตรวจสอบ และโค้ดจะออกเมื่อได้รับการยอมรับ
การเริ่มต้นกล่องขอบเขตใบหน้า
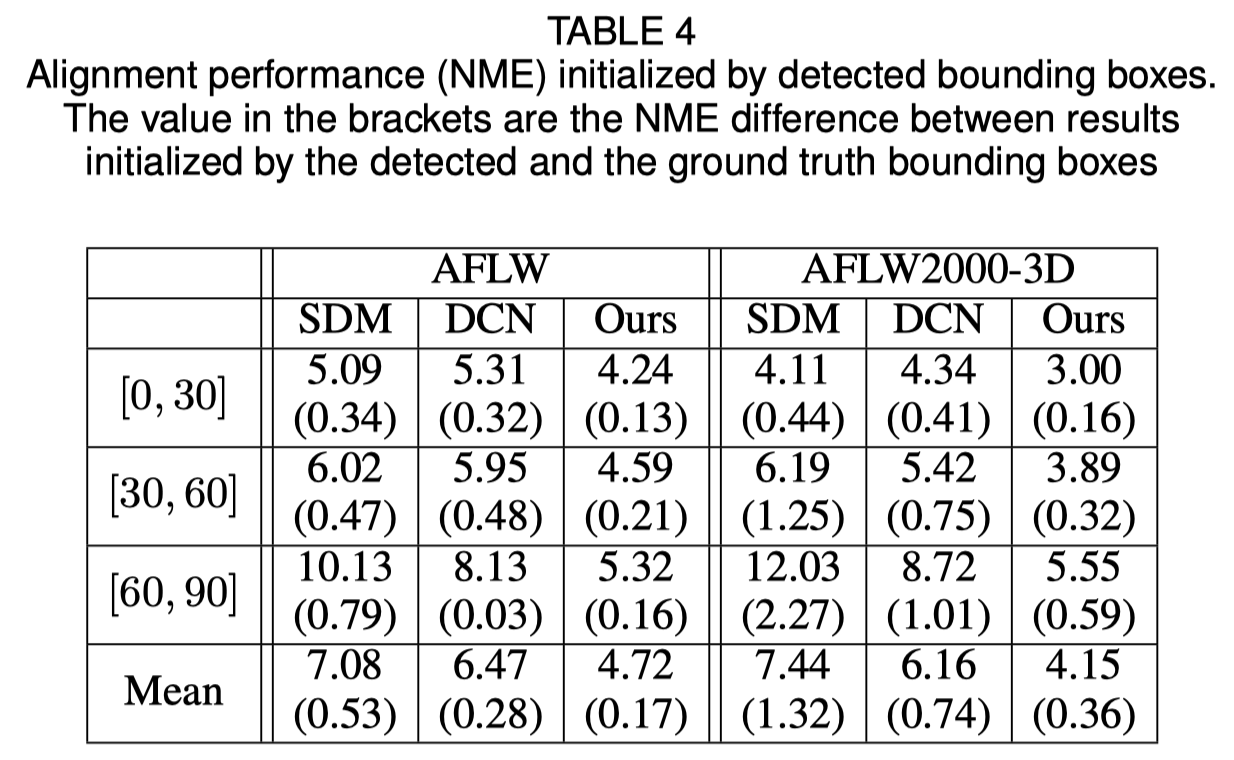
บทความต้นฉบับแสดงให้เห็นว่าการใช้กล่องขอบเขตที่ตรวจพบแทนกล่องความจริงภาคพื้นดินจะทำให้ประสิทธิภาพลดลงเล็กน้อย ดังนั้นวิธีการครอบตัดใบหน้าในปัจจุบันจึงมีความแข็งแกร่งที่สุด ผลลัพธ์เชิงปริมาณแสดงอยู่ในตารางด้านล่าง
การสร้างใบหน้าใหม่
พื้นผิวของบริเวณที่มองไม่เห็นนั้นบิดเบี้ยวเนื่องจากการบดบังตัวเอง ดังนั้นบริเวณใบหน้าที่มองไม่เห็นอาจดูแปลกตา (น่ากลัวเล็กน้อย)
เกี่ยวกับการตัดพารามิเตอร์รูปร่างและการแสดงออก
การตัดพารามิเตอร์จะช่วยเร่งการฝึกอบรมและการสร้างใหม่ แต่จะลดความแม่นยำลง โดยเฉพาะรายละเอียด เช่น การหลับตา ด้านล่างนี้เป็นรูปภาพซึ่งมีขนาดพารามิเตอร์ 40+10, 60+29 และ 199+29 (ขนาดเดิม) เมื่อเปรียบเทียบกับรูปร่างแล้ว การตัดการแสดงออกจะส่งผลต่อความแม่นยำในการประกอบใหม่มากกว่าเมื่อมีอารมณ์เข้ามาเกี่ยวข้อง ดังนั้น คุณจึงสามารถเลือกการแลกเปลี่ยนระหว่างความเร็ว/ขนาดพารามิเตอร์และความแม่นยำได้ คำแนะนำในการตัดทอนการแลกเปลี่ยนคือ 60+29

ขอขอบคุณที่สนใจ repo นี้ หากงานหรือการวิจัยของคุณได้รับประโยชน์จากการซื้อคืนนี้ ให้ติดดาวไว้ ?
ยินดีต้อนรับสู่งานที่เกี่ยวข้องกับใบหน้า 3 มิติของฉัน: MeGlass และ Face Anti-Spoofing
หากงานของคุณได้รับประโยชน์จากการซื้อคืนนี้ โปรดอ้างอิงผ้ากันเปื้อนสามรายการด้านล่างนี้
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [หน้าแรก, Google Scholar]: [email protected] หรือ [email protected]


