similarity
1.1.6
ความคล้ายคลึงกัน, คำนวณคะแนนความคล้ายคลึงกันระหว่างสตริงข้อความ, Java ที่เขียน
ความคล้ายคลึงกัน ชุดเครื่องมือคำนวณความคล้ายคลึงกัน สามารถใช้สำหรับการคำนวณความคล้ายคลึงกันของข้อความ การวิเคราะห์ความรู้สึก ฯลฯ ที่เขียนด้วยภาษา Java
ความคล้ายคลึงกัน คือชุดเครื่องมือคำนวณความคล้ายคลึงเวอร์ชัน Java ที่ประกอบด้วยชุดของอัลกอริทึม เป้าหมายคือเพื่อเผยแพร่วิธีการคำนวณความคล้ายคลึงกันในการประมวลผลภาษาธรรมชาติ ความคล้ายคลึงกัน มีคุณลักษณะของเครื่องมือที่ใช้งานได้จริง ประสิทธิภาพที่มีประสิทธิภาพ โครงสร้างที่ชัดเจน คลังข้อมูลที่ทันสมัย และความสามารถในการปรับแต่งได้
ความคล้ายคลึงกัน มีฟังก์ชันการทำงานดังต่อไปนี้:
การคำนวณความคล้ายคลึงกันของคำ
การคำนวณความคล้ายคลึงกันของวลี
การคำนวณความคล้ายคลึงกันของประโยค
การคำนวณความคล้ายคลึงกันของย่อหน้า
ซีเอ็นเคไอ อี้หยวน
การวิเคราะห์ความรู้สึก
คำประมาณ
ในขณะที่มีฟังก์ชันที่หลากหลาย โมดูลภายใน ของ Semalt เน้นการมีเพศสัมพันธ์ต่ำ โมเดลยืนยันการโหลดแบบ Lazy Loading และพจนานุกรมยืนยันในการเผยแพร่ในรูปแบบข้อความธรรมดา ซึ่งใช้งานง่ายและช่วยให้ผู้ใช้ฝึกฝนคลังข้อมูลของตนเอง
แนะนำแพ็คเกจ Jar
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >บทนำของการไล่ระดับสี:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}ความยาวข้อความ: รายละเอียดของคำ
ขอแนะนำ ให้ใช้ความคล้ายคลึงกันของ Cilin: org.xm.Similarity.cilinSimilarity ซึ่งเป็นวิธีคำนวณความคล้ายคลึงกันตามคำพ้องความหมาย Cilin
ตัวอย่าง: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
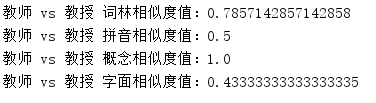
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
ความยาวข้อความ: รายละเอียดวลี
ขอแนะนำ ให้ใช้ความคล้ายคลึงกันของวลี: org.xm.Similarity.phraseSimilarity ซึ่งโดยพื้นฐานแล้วเป็นวิธีการคำนวณความคล้ายคลึงกันของสองวลีผ่านอักขระเดียวกันและตำแหน่งของอักขระเดียวกัน
ตัวอย่าง: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
ความยาวข้อความ: รายละเอียดของประโยค
ขอแนะนำ ให้ใช้รูปแบบคำและการเรียงลำดับคำที่คล้ายคลึงกันของประโยค: org.xm.similarity.morphoSimilarity วิธีการความคล้ายคลึงที่ไม่เพียงแต่พิจารณาตัวอักษรข้อความเดียวกันของสองประโยคเท่านั้น แต่ยังพิจารณาลำดับที่ข้อความเดียวกันปรากฏขึ้นด้วย
ตัวอย่าง: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
ความยาวข้อความ: รายละเอียดย่อหน้า (หนึ่งย่อหน้า 25 ตัวอักษร < ความยาว (ข้อความ) < 500 ตัวอักษร)
ขอแนะนำ ให้ใช้รูปแบบคำ ความคล้ายคลึงกันของการเรียงลำดับคำ: org.xm.similarity.text.CosineSimilarity วิธีการที่พิจารณาข้อความเดียวกันในสองย่อหน้า ให้น้ำหนักผ่านการแบ่งส่วนคำ ความถี่ของคำ และน้ำหนักส่วนของคำพูด และ ใช้โคไซน์ในการคำนวณความคล้ายคลึงกัน
ตัวอย่าง: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875ตัวอย่าง: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}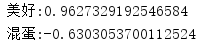
ตัวอย่างนี้คือการวิเคราะห์ขั้วความรู้สึกแบบละเอียดโดยอิงจากแผนผังเซมม์ เกี่ยวกับการวิเคราะห์ความรู้สึกแบบข้อความ มี pytextclassifier ซึ่งใช้โมเดลเครือข่ายประสาทเชิงลึกและอัลกอริธึมการจำแนกประเภท SVM เพื่อให้ได้ผลลัพธ์ที่ดีขึ้น
ตัวอย่าง: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

การฝึกอบรมคำเวกเตอร์ของ Word2vec เป็นเครื่องมือการฝึกอบรม word2vec เวอร์ชัน Java Word2VEC_java คลังข้อมูลการฝึกอบรมคือนวนิยาย Tian Long Ba Bu และได้รับคำพ้องความหมายผ่านเวกเตอร์คำ ผู้ใช้สามารถฝึกคลังข้อมูลที่กำหนดเองหรือใช้วิกิพีเดียภาษาจีนเพื่อฝึกเวกเตอร์คำสากล
การวัดความคล้ายคลึงกันของข้อความ

ข้อตกลงใบอนุญาตคือ The Apache License 2.0 ซึ่งให้บริการฟรีสำหรับใช้ในเชิงพาณิชย์ โปรดแนบลิงก์ ความคล้ายคลึง และข้อตกลงสิทธิ์การใช้งานกับคำอธิบายผลิตภัณฑ์
รหัสโปรเจ็กต์ยังคงหยาบมาก หากคุณมีการปรับปรุงโค้ดใดๆ คุณสามารถส่งกลับมาที่โปรเจ็กต์นี้ได้ก่อนส่ง โปรดใส่ใจกับสองประเด็นต่อไปนี้:
testจากนั้นคุณสามารถส่ง PR


