cherche
2.2.1
ค้นหาประสาท

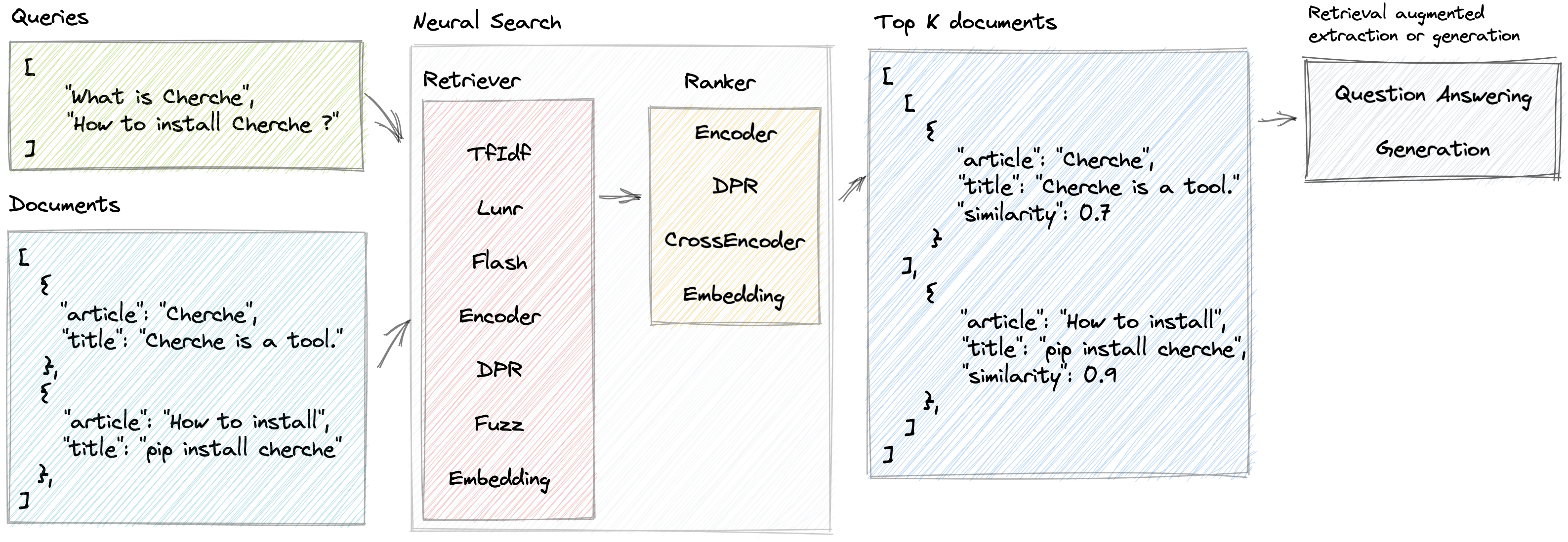
Cherche ช่วยให้สามารถพัฒนาไปป์ไลน์การค้นหาแบบนิวรัลที่ใช้รีทรีฟเวอร์และโมเดลภาษาที่ได้รับการฝึกอบรมล่วงหน้าทั้งในฐานะรีทรีฟเวอร์และจัดอันดับ ข้อได้เปรียบหลักของ Cherche อยู่ที่ความสามารถในการสร้างท่อส่งแบบครบวงจร นอกจากนี้ Cherche ยังเหมาะอย่างยิ่งสำหรับการค้นหาความหมายแบบออฟไลน์เนื่องจากเข้ากันได้กับการคำนวณแบบแบตช์
นี่คือคุณสมบัติบางส่วนที่ Cherche นำเสนอ:
การสาธิตสดของเครื่องมือค้นหา NLP ที่ขับเคลื่อนโดย Cherche
หากต้องการติดตั้ง Cherche เพื่อใช้กับรีทรีฟเวอร์แบบธรรมดาบน CPU เช่น TfIdf, Flash, Lunr, Fuzz ให้ใช้คำสั่งต่อไปนี้:
pip install chercheหากต้องการติดตั้ง Cherche เพื่อใช้กับรีทรีฟเวอร์หรือตัวจัดอันดับเชิงความหมายบน CPU ให้ใช้คำสั่งต่อไปนี้:
pip install " cherche[cpu] "สุดท้ายนี้ หากคุณวางแผนที่จะใช้รีทรีฟเวอร์หรือตัวจัดอันดับเชิงความหมายบน GPU ให้ใช้คำสั่งต่อไปนี้:
pip install " cherche[gpu] "เมื่อปฏิบัติตามคำแนะนำในการติดตั้งเหล่านี้ คุณจะสามารถใช้ Cherche ได้ตามข้อกำหนดที่เหมาะสมกับความต้องการของคุณ
เอกสารมีอยู่ที่นี่ โดยให้รายละเอียดเกี่ยวกับผู้ดึงข้อมูล อันดับ อันดับ ไปป์ไลน์ และตัวอย่าง
Cherche อนุญาตให้ค้นหาเอกสารที่ถูกต้องภายในรายการวัตถุ นี่คือตัวอย่างของคลังข้อมูล
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]นี่คือตัวอย่างของไปป์ไลน์การค้นหาแบบนิวรอลที่ประกอบด้วย TF-IDF ที่จะดึงเอกสารอย่างรวดเร็ว ตามด้วยโมเดลการจัดอันดับ โมเดลการจัดอันดับจะจัดเรียงเอกสารที่รีทรีฟเวอร์สร้างขึ้นตามความคล้ายคลึงทางความหมายระหว่างข้อความค้นหาและเอกสาร เราสามารถเรียกไปป์ไลน์โดยใช้รายการการสืบค้นและรับเอกสารที่เกี่ยวข้องสำหรับการสืบค้นแต่ละครั้ง
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]เราสามารถแมปดัชนีกับเอกสารเพื่อเข้าถึงเนื้อหาโดยใช้ไปป์ไลน์:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche จัดเตรียมตัวดึงข้อมูลที่กรองเอกสารอินพุตตามแบบสอบถาม
Cherche จัดให้มีผู้จัดอันดับที่กรองเอกสารในผลลัพธ์ของผู้ดึงข้อมูล
อันดับ Cherche เข้ากันได้กับโมเดล SentenceTransformers ซึ่งมีอยู่ในฮับ Hugging Face
Cherche มีโมดูลสำหรับการตอบคำถามโดยเฉพาะ โมดูลเหล่านี้เข้ากันได้กับโมเดลที่ได้รับการฝึกล่วงหน้าของ Hugging Face และบูรณาการเข้ากับไปป์ไลน์การค้นหาด้วยระบบประสาทอย่างสมบูรณ์
Cherche ถูกสร้างขึ้นสำหรับ/โดย Renault และขณะนี้ทุกคนสามารถใช้ได้แล้ว เรายินดีรับทุกการมีส่วนร่วม

Lunr สุนัขจำพวกหนึ่งเป็นเสื้อคลุมรอบ Lunr.py Flash Retever เป็นโปรแกรมห่อรอบ FlashText ตัวจัดอันดับ DPR, Encode และ CrossEncoder เป็น wrappers ที่ทุ่มเทให้กับการใช้โมเดล SentenceTransformers ที่ผ่านการฝึกอบรมมาแล้วในไปป์ไลน์การค้นหาแบบนิวรัล
หากคุณใช้ cherche เพื่อสร้างผลลัพธ์สำหรับการตีพิมพ์ทางวิทยาศาสตร์ของคุณ โปรดดูเอกสาร SIGIR ของเรา:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}ทีมผู้พัฒนา Cherche ประกอบด้วย Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero, Jose G Moreno -


