genai_robotics
1.0.0
พื้นที่เก็บข้อมูลนี้มีการตั้งค่าเชิงทดลองและคำนึงถึงความเป็นส่วนตัว เพื่อใช้ประโยชน์จากวิธีการ AI เชิงสร้างสรรค์ในการควบคุมหุ่นยนต์ ด้วยโซลูชันที่นำเสนอในที่นี้ ผู้ใช้สามารถกำหนดการกระทำได้อย่างอิสระด้วยเสียงซึ่งแปลเป็นแผนการที่หุ่นยนต์ดูดฝุ่นสามารถทำได้ในสภาพแวดล้อมแบบโลกเปิดที่กล้องสังเกตได้
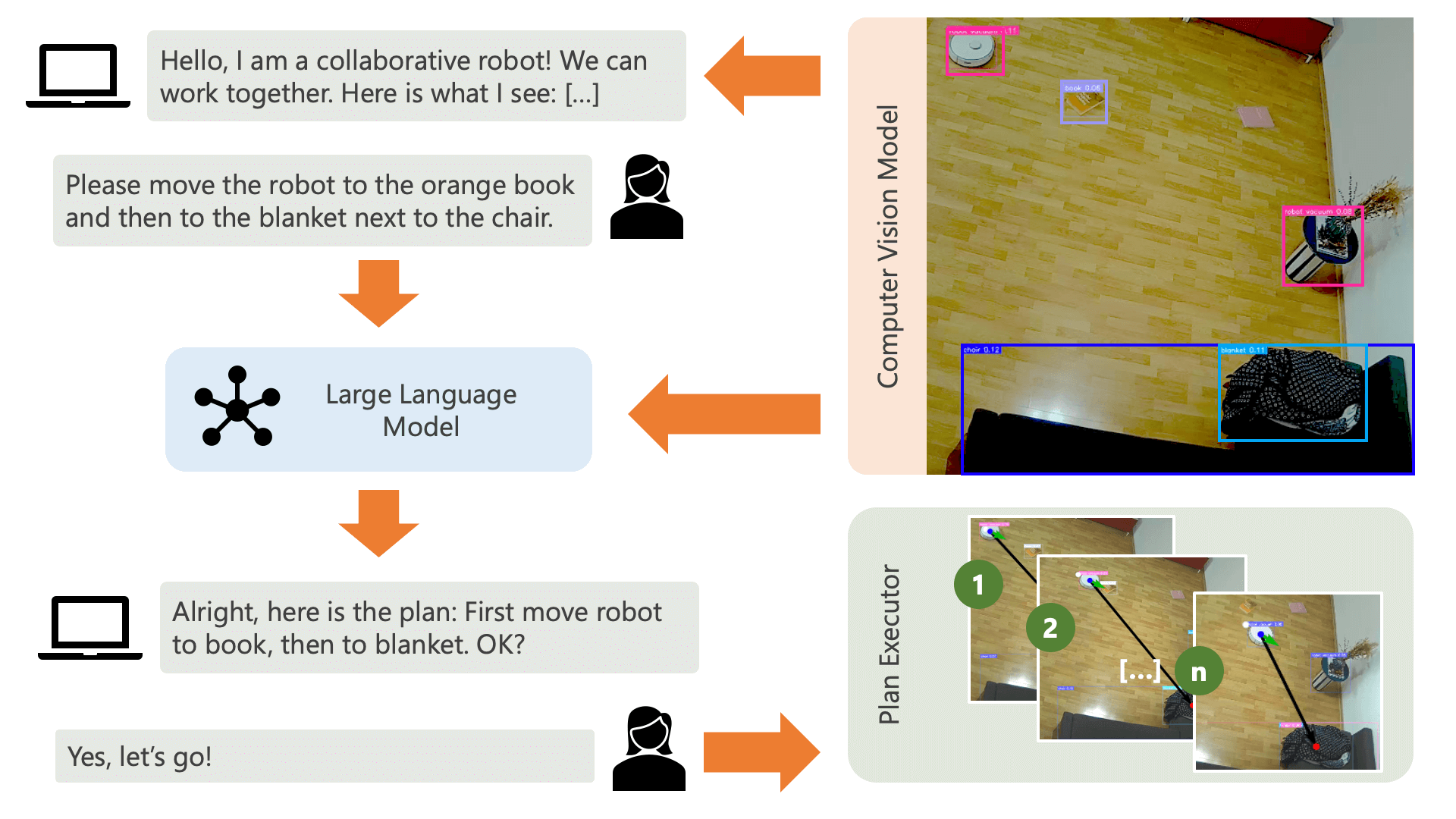
ข้อดีพื้นฐานของวิธีการที่นำเสนอที่นี่คือ:
ระบบได้รับการพัฒนาในแฮ็กกาธอน 3 วันเพื่อเป็นแบบฝึกหัดการเรียนรู้และการพิสูจน์แนวคิดว่าเครื่องมือ AI สมัยใหม่สามารถลดเวลาในการพัฒนาโซลูชันการควบคุมหุ่นยนต์ได้อย่างมาก
หากต้องการใช้ฟีเจอร์ทั้งหมดของที่เก็บนี้ นี่คือสิ่งที่คุณควรมี:
ในการเริ่มต้น ให้ทำตามขั้นตอนด้านล่าง:
requirements.txt ลงในสภาพแวดล้อม Python (ทดสอบด้วย Python 3.11)src/config.template.toml เป็น config.toml สำหรับขั้นตอนทั้งหมดด้านล่าง ให้ใส่ข้อมูลรับรองที่ได้รับลงใน config.tomlpython-roborocksrc/run.py เพื่อรันเวิร์กโฟลว์ วิธีที่ดีที่สุดในการทำความเข้าใจว่าพื้นที่เก็บข้อมูลนี้ทำอะไรโดยละเอียด และองค์ประกอบต่างๆ โต้ตอบกันอย่างไรคือการใช้แผนภาพสถาปัตยกรรม:
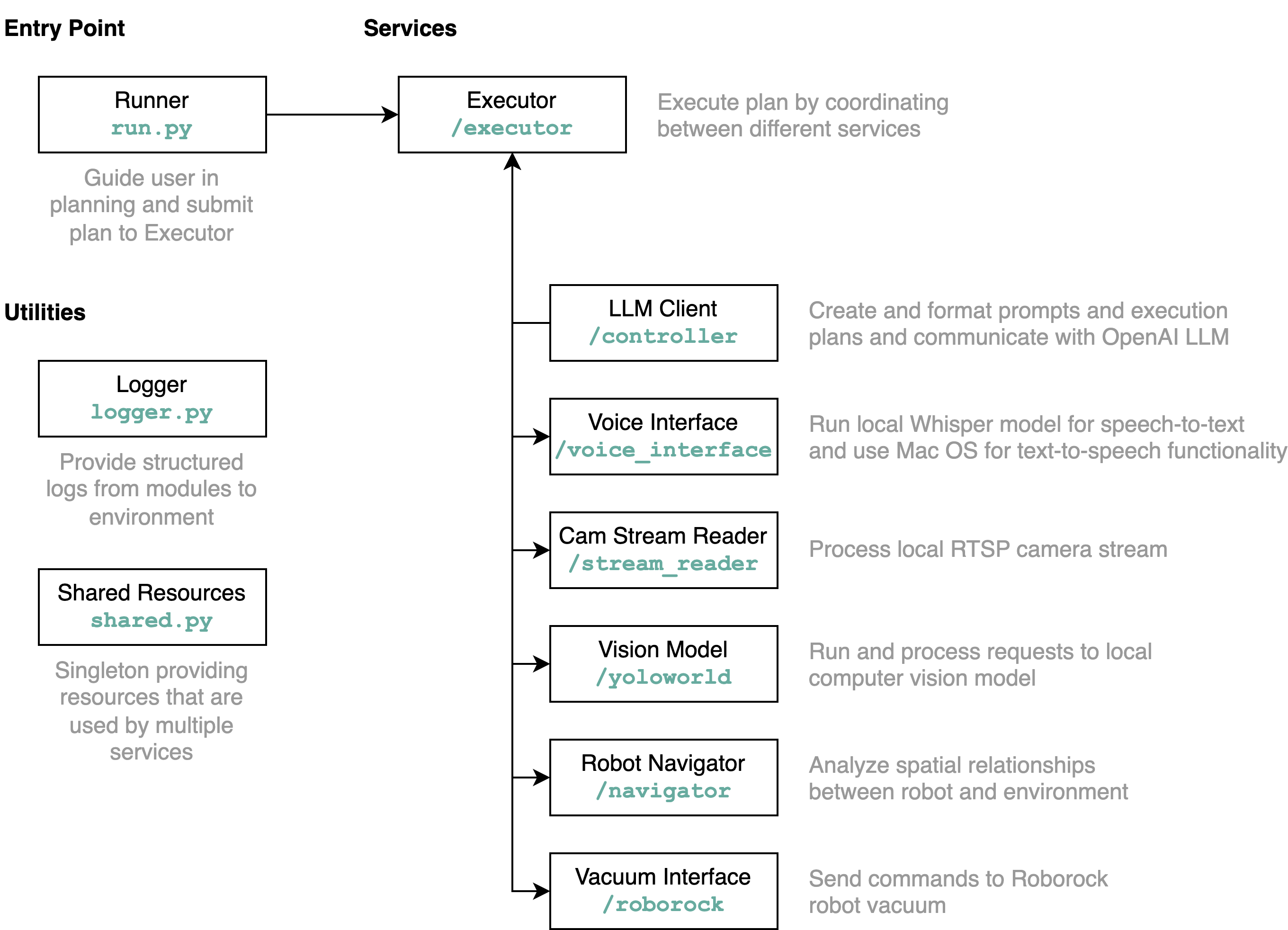
เมื่อคุณเรียกใช้ไฟล์ run.py ตามที่อธิบายไว้ข้างต้น นี่คือสิ่งที่เกิดขึ้นและวิธีการทำงาน:
ระบบกำลังทักทายผู้ใช้ด้วยข้อความเสียงและคาดหวังให้พวกเขาบอกระบบว่าต้องการทำอะไร ตัวอย่างเช่น ผู้ใช้อาจต้องการให้หุ่นยนต์หยิบกาแฟจากคนที่นั่งอยู่บนเก้าอี้สีเหลืองแล้วขนส่งไปให้อีกคนที่นั่งบนโซฟาสีดำ จากนั้นระบบจะสร้างแผนเพื่อดำเนินการการกระทำเหล่านี้
ระบบจำเป็นต้องเข้าใจว่าจะสามารถบรรลุสิ่งที่ผู้ใช้ต้องการได้อย่างไร? ระบบจำเป็นต้องคำนึงถึงสภาพแวดล้อมและการดำเนินการที่สามารถดำเนินการได้ในสภาพแวดล้อมนี้ ที่นี่ เราใช้แบบจำลองคอมพิวเตอร์วิทัศน์พร้อมการตรวจจับวัตถุเพื่อให้ข้อมูลเกี่ยวกับสภาพแวดล้อมแก่ระบบ ตัวเครื่องดูดฝุ่นสามารถดำเนินการง่ายๆ 3 ขั้นตอน: เดินหน้า เลี้ยว และไม่ทำอะไรเลย การดำเนินการอื่นในสภาพแวดล้อมกำลังรอให้ผู้ใช้ดำเนินการบางอย่าง
เพื่อหลีกเลี่ยงความสับสนในด้านผู้ใช้ สิ่งสำคัญคือผู้ใช้ต้องรู้ว่า AI รับรู้สภาพแวดล้อมของตนอย่างไร ตัวอย่างเช่น หากโมเดลคอมพิวเตอร์วิทัศน์ไม่รู้จักวัตถุ AI จะไม่สามารถรวมวัตถุนั้นไว้ในแผนได้ สิ่งสำคัญคือผู้ใช้ต้องตระหนักว่ามีความไม่แน่นอนเกี่ยวกับการจดจำแบบจำลอง การใช้โมเดลภาษาขนาดใหญ่ GPT-4o ของ OpenAI พร้อมคำอธิบาย ระบบจะสร้างคำอธิบายเกี่ยวกับสภาพแวดล้อมและอ่านให้ผู้ใช้ฟังก่อนที่จะถามผู้ใช้ว่าพวกเขาต้องการให้ระบบทำอะไร
เมื่อพิจารณาจากข้อมูลสภาพแวดล้อมและการป้อนข้อมูลของผู้ใช้เกี่ยวกับสิ่งที่พวกเขาต้องการทำ ระบบก็สามารถวางแผนได้ ที่นี่ เราขอให้ LLM จัดทำแผนโดยพิจารณาจากข้อมูลของผู้ใช้และคำอธิบายสภาพแวดล้อม คุณสามารถค้นหาเทมเพลตพร้อมต์ได้ในไดเร็กทอรี controller เคล็ดลับที่น่าตื่นเต้นที่นี่คือ LLM รับรู้ถึงสภาพแวดล้อมของตนผ่านสองตารางที่สร้างขึ้นจากผลลัพธ์ของแบบจำลองคอมพิวเตอร์วิทัศน์เท่านั้น นี่คือตัวอย่าง:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
เมื่อ LLM ประมวลผลพร้อมท์การวางแผนแล้ว ผลลัพธ์จะออกมาสองสิ่ง: การใช้เหตุผลและแผน ก่อนที่ระบบจะดำเนินการตามแผน ระบบจะใช้พรอมต์คำอธิบายเพื่อสร้างข้อมูลสรุปสั้นๆ ของแผนเพื่อวัตถุประสงค์ในการได้รับการยืนยันจากผู้ใช้ว่าแผนตรงกับสิ่งที่พวกเขาขอให้ทำ นี่เป็นจิตวิญญาณของแนวทางแบบมนุษย์ในวงที่เราดำเนินการจากมุมมองที่ว่าในสภาพแวดล้อมทางกายภาพที่เปิดกว้างและเป็นจริง ผู้คนอาจได้รับอันตรายจากการกระทำของ AI ดังนั้นจึงสมเหตุสมผลที่จะขอมนุษย์ ข้อเสนอแนะก่อนที่ AI จะดำเนินการตามแผนใดๆ ที่เกิดขึ้นด้วยตัวเอง
เมื่อผู้ใช้ยืนยันแล้ว ระบบจะดำเนินการตามแผนต่อไป แผนดังกล่าวซึ่งสร้างขึ้นโดย LLM อาจมีลักษณะดังนี้:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] การใช้ executor ระบบจะดำเนินการตามแผนทีละขั้นตอน เพื่อลดเวลาการตั้งค่าใดๆ ที่จำเป็น การควบคุมหุ่นยนต์จะปฏิบัติตามอัลกอริธึมที่เรียบง่าย ไม่ถูกต้อง แต่มีประสิทธิภาพ:
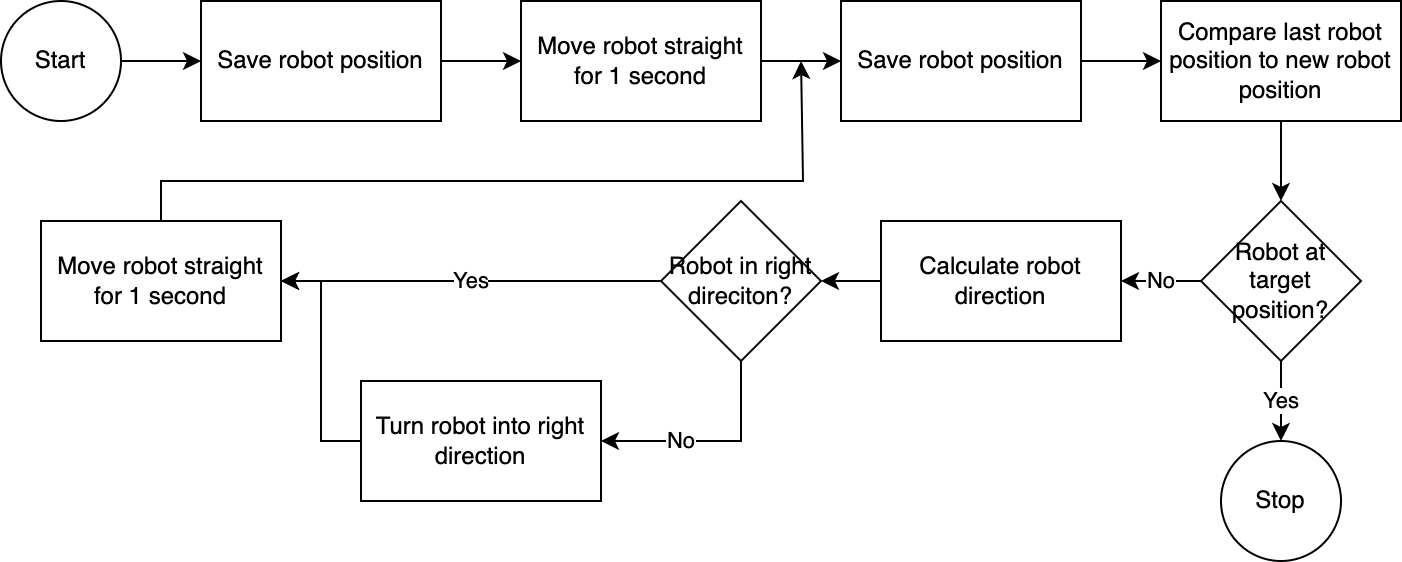
ระบบคอมพิวเตอร์วิทัศน์ประเมินตำแหน่งของหุ่นยนต์ ด้วยโค้ดในโมดูล navigator ตำแหน่งหุ่นยนต์ที่สัมพันธ์กับตำแหน่งเป้าหมายและสัมพันธ์กับตำแหน่งที่ทราบล่าสุดจะถูกวิเคราะห์และเปรียบเทียบ วิธีการนี้ไม่สมบูรณ์เนื่องจากตำแหน่งและการบิดเบี้ยวของเลนส์ของกล้องไม่ได้ถูกนำมาพิจารณาด้วย มุมที่วัดด้วยวิธีนี้มีความคลาดเคลื่อน อย่างไรก็ตาม เนื่องจากระบบเป็นแบบวนซ้ำ ข้อผิดพลาดจึงได้รับการชดเชยบ่อยครั้ง อย่างไรก็ตาม เป็นที่น่าสังเกตว่าสิ่งนี้ต้องแลกมาด้วยความเร็ว ระบบทำงานช้าเนื่องจากต้องใช้เวลาในการวิเคราะห์ภาพ คำนวณเส้นทาง และแจ้งให้หุ่นยนต์ทราบถึงขั้นตอนต่อไปที่จะดำเนินการ
เมื่อหุ่นยนต์ไปถึงตำแหน่งเป้าหมายแล้ว ผู้ดำเนินการจะดำเนินขั้นตอนต่อไปของแผน สำหรับการดำเนินการที่เกี่ยวข้องกับการป้อนข้อมูลของผู้ใช้ ผู้ดำเนินการจะใช้ฟังก์ชันการแปลงข้อความเป็นคำพูดและคำพูดเป็นข้อความเพื่อโต้ตอบกับผู้ใช้
ในระบบนี้ เราใช้บริการที่ทำงานบนเครื่องหรือเครือข่ายเป็นส่วนใหญ่ ข้อยกเว้นคือ GPT-4o เราส่งข้อมูลข้อความไปยังโมเดลของ OpenAI ผ่านทางอินเทอร์เน็ต ข้อมูลข้อความประกอบด้วยอินพุตของผู้ใช้ที่ถอดเสียงและตารางของออบเจ็กต์ที่รู้จัก เหตุผลเดียวที่เราใช้ GPT-4o ที่นี่ก็เพราะว่านี่คือหนึ่งในโมเดลที่ดีที่สุดที่มีอยู่ในช่วงเวลาของแฮ็กกาธอน – เรายังสามารถเรียกใช้ LLM ในพื้นที่และทำงานได้อย่างเต็มที่โดยไม่ต้องเชื่อมต่อกับอินเทอร์เน็ต โดยรักษาความเป็นส่วนตัวระหว่างการไหลของ การดำเนินงาน
โมเดลคอมพิวเตอร์วิทัศน์ที่รวมอยู่ในพื้นที่เก็บข้อมูลนี้จัดทำขึ้นโดยโมเดล YOLO-World ในพื้นที่ HuggingFace โดยมีข้อความแจ้งต่อไปนี้: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human หากคุณต้องการจดจำออบเจ็กต์เพิ่มเติม โปรดปรับข้อความแจ้งและดาวน์โหลดโมเดล ONNX ผ่านพื้นที่นี้ จากนั้น คุณสามารถแทนที่โมเดลในไดเร็กทอรี src/yoloworld/models/rev0
โปรดทราบว่าหากต้องการแยกโมเดลอย่างถูกต้อง คุณต้องเปลี่ยนพารามิเตอร์จำนวนกล่องสูงสุดและเกณฑ์คะแนนในพื้นที่ HuggingFace ด้วยตนเองก่อนที่จะส่งออกโมเดล
คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับโมเดล YOLO-World ที่น่าตื่นเต้น ซึ่งสร้างขึ้นจากความก้าวหน้าล่าสุดในการสร้างแบบจำลองภาษาวิสัยทัศน์บนเว็บไซต์ YOLO-World
โครงการนี้เผยแพร่ภายใต้ใบอนุญาต MIT
พื้นที่เก็บข้อมูลนี้ไม่ได้รับการตรวจสอบอย่างแข็งขัน และไม่มีความตั้งใจที่จะขยายพื้นที่เก็บข้อมูล - ถือเป็นแบบฝึกหัดการเรียนรู้เป็นอันดับแรกและสำคัญที่สุด อย่างไรก็ตาม หากคุณรู้สึกมีแรงบันดาลใจ คุณสามารถมีส่วนร่วมในโปรเจ็กต์ได้โดยการเปิดปัญหา GitHub หรือดึงคำขอ


