full stack on prem cv mlops
1.0.0
ยินดีต้อนรับสู่ระบบนิเวศ MLOps ภายในองค์กรที่ครอบคลุมของเรา ซึ่งออกแบบมาโดยเฉพาะสำหรับงาน Computer Vision โดยเน้นที่การจัดหมวดหมู่รูปภาพเป็นหลัก พื้นที่เก็บข้อมูลนี้จัดเตรียมทุกสิ่งที่คุณต้องการ ตั้งแต่พื้นที่ทำงานด้านการพัฒนาใน Jupyter Lab/Notebook ไปจนถึงบริการระดับการผลิต ส่วนที่ดีที่สุด? ใช้เวลาเพียง "1 config และ 1 command" เพื่อรันทั้งระบบตั้งแต่การสร้างแบบจำลองไปจนถึงการใช้งาน! เราได้รวมแนวทางปฏิบัติที่ดีที่สุดมากมายเพื่อให้มั่นใจถึงความสามารถในการปรับขนาดและความน่าเชื่อถือ ในขณะเดียวกันก็รักษาความยืดหยุ่นไว้ด้วย แม้ว่ากรณีการใช้งานหลักของเราเกี่ยวข้องกับการจำแนกรูปภาพ โครงสร้างโปรเจ็กต์ของเราสามารถปรับให้เข้ากับการพัฒนา ML/DL ที่หลากหลายได้อย่างง่ายดาย แม้กระทั่งการเปลี่ยนจากในองค์กรไปสู่ระบบคลาวด์!
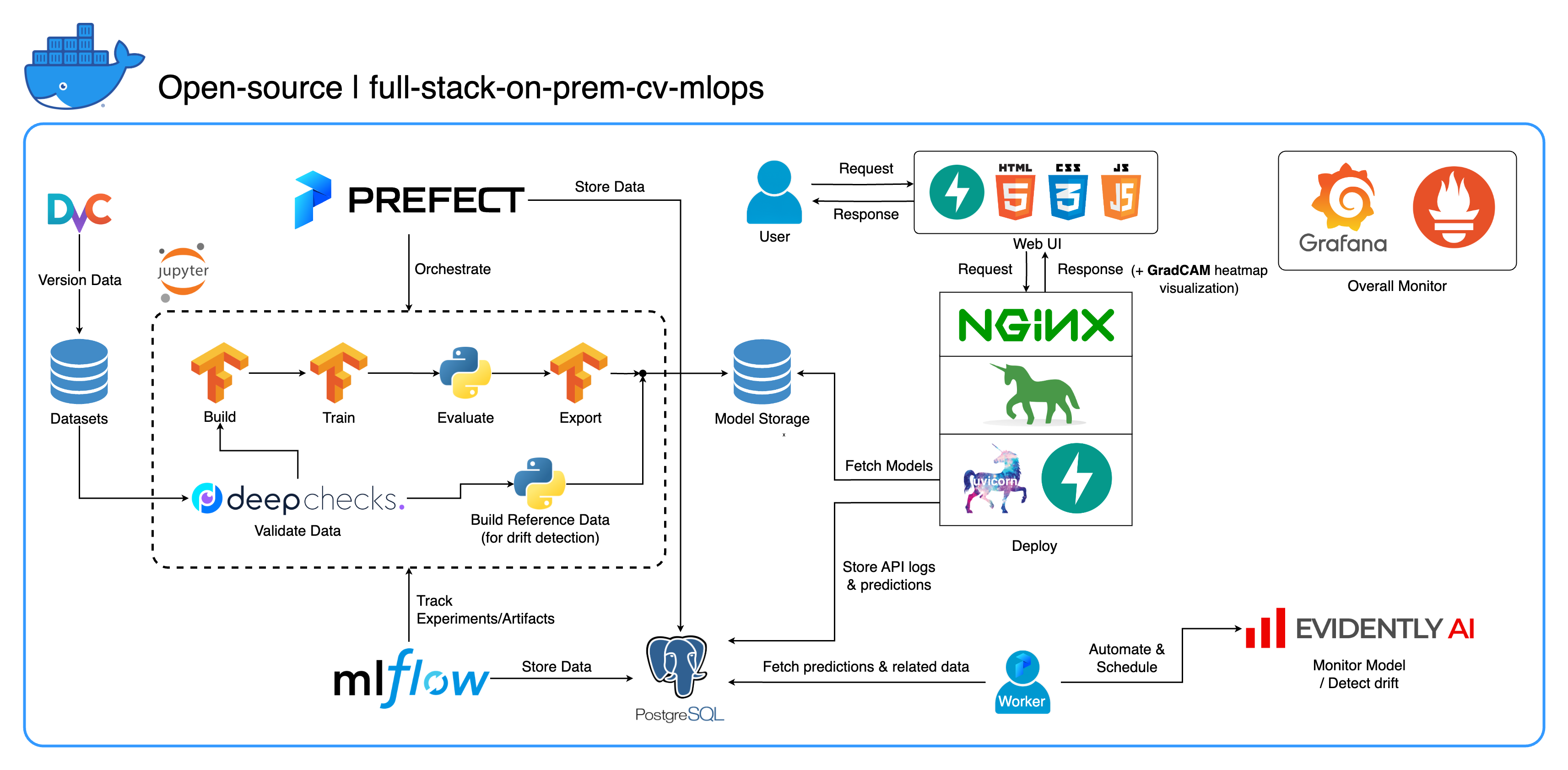
เป้าหมายอีกประการหนึ่งคือการแสดงวิธีผสานรวมเครื่องมือเหล่านี้ทั้งหมดและทำให้พวกเขาทำงานร่วมกันในระบบเต็มรูปแบบเพียงระบบเดียว หากคุณสนใจส่วนประกอบหรือเครื่องมือเฉพาะ อย่าลังเลที่จะเลือกสิ่งที่เหมาะสมกับความต้องการของโครงการของคุณ
ระบบทั้งหมดถูกรวมไว้ในไฟล์ Docker Compose ไฟล์เดียว ในการตั้งค่า สิ่งที่คุณต้องทำคือเรียกใช้ docker-compose up ! นี่คือระบบภายในองค์กรเต็มรูปแบบ ซึ่งหมายความว่าไม่จำเป็นต้องมีบัญชีคลาวด์ และ ไม่มีค่าใช้จ่ายแม้แต่เล็กน้อย ในการใช้ทั้งระบบ!
เราขอแนะนำให้ดูวิดีโอสาธิตในส่วน วิดีโอสาธิต เพื่อดูภาพรวมที่ครอบคลุมและทำความเข้าใจวิธีใช้ระบบนี้กับโครงการของคุณ วิดีโอเหล่านี้มีรายละเอียดที่สำคัญซึ่งอาจยาวเกินไปและไม่ชัดเจนพอที่จะครอบคลุมที่นี่
สาธิต: https://youtu.be/NKil4uzmmQc
คำแนะนำทางเทคนิคเชิงลึก: https://youtu.be/l1S5tHuGBA8
แหล่งข้อมูลในวิดีโอ:
หากต้องการใช้พื้นที่เก็บข้อมูลนี้ คุณจำเป็นต้องมี Docker เท่านั้น เพื่อเป็นข้อมูลอ้างอิง เราใช้ Docker เวอร์ชัน 24.0.6, build ed223bc และ Docker Compose เวอร์ชัน v2.21.0-desktop.1 บน Mac M1
เราได้นำแนวทางปฏิบัติที่ดีที่สุดหลายประการไปใช้ในโครงการนี้:
tf.data สำหรับ TensorFlowimgaug lib เพื่อความยืดหยุ่นที่มากขึ้นในตัวเลือกการเพิ่มมากกว่าฟังก์ชันหลักจาก TensorFlowos.env สำหรับการกำหนดค่าที่สำคัญหรือระดับบริการlogging แทน print.env สำหรับตัวแปรใน docker-compose.ymldefault.conf.template สำหรับ Nginx เพื่อใช้ตัวแปรสภาพแวดล้อมในการกำหนดค่า Nginx อย่างหรูหรา (คุณสมบัติใหม่ใน Nginx 1.19)พอร์ตส่วนใหญ่สามารถปรับแต่งได้ในไฟล์ .env ที่รากของที่เก็บนี้ นี่คือค่าเริ่มต้น:
123456789 )[email protected] , pw: SuperSecurePwdHere )admin , pw: admin ) คุณต้องพิจารณาแสดงความคิดเห็นเกี่ยวกับ platform: linux/arm64 ใน docker-compose.yml หากคุณไม่ได้ใช้คอมพิวเตอร์ที่ใช้ ARM (เราใช้ Mac M1 เพื่อการพัฒนา) ไม่เช่นนั้นระบบนี้จะใช้งานไม่ได้
--recurse-submodules flag ในคำสั่งของคุณ: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy ภายใต้บริการ jupyter ใน docker-compose.yml และเปลี่ยนอิมเมจพื้นฐานใน services/jupyter/Dockerfile จาก ubuntu:18.04 เป็น nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (ข้อความอยู่ในไฟล์ คุณเพียงแค่ต้องแสดงความคิดเห็นและ ไม่แสดงความคิดเห็น) เพื่อใช้ประโยชน์จาก GPU ของคุณ คุณอาจต้องติดตั้ง nvidia-container-toolkit บนเครื่องโฮสต์เพื่อให้ทำงานได้ สำหรับผู้ใช้ Windows/WSL2 เราพบว่าบทความนี้มีประโยชน์มากdocker-compose up หรือ docker-compose up -d เพื่อแยกเทอร์มินัลออกdatasets/animals10-dvc และทำตามขั้นตอนในส่วน วิธีใช้ http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasksflowsrun_flow.py ที่รูทของ repostart(config) ในไฟล์โฟลว์ของคุณ ฟังก์ชันนี้ยอมรับการกำหนดค่าเป็น Python dict จากนั้นเรียกโฟลว์เฉพาะในไฟล์นั้นโดยทั่วไปdatasets และทั้งหมดควรมีโครงสร้างไดเร็กทอรีเดียวกันกับที่อยู่ใน repo นี้central_storage ที่ ~/ariya/ ควรมีไดเร็กทอรีย่อยอย่างน้อย 2 ไดเร็กทอรีชื่อ models และ ref_data central_storage นี้ทำหน้าที่ในการจัดเก็บอ็อบเจ็กต์ในการจัดเก็บไฟล์ที่จัดฉากทั้งหมดเพื่อใช้ในการพัฒนาและปรับใช้สภาพแวดล้อม (นี่คือหนึ่งในสิ่งที่คุณควรพิจารณาเปลี่ยนเป็นบริการจัดเก็บข้อมูลบนคลาวด์ ในกรณีที่คุณต้องการปรับใช้บนคลาวด์และทำให้สามารถปรับขนาดได้มากขึ้น)ข้อตกลง สำคัญ ที่ต้อง ระมัดระวังเป็นพิเศษ หากคุณต้องการเปลี่ยนแปลง (เนื่องจากสิ่งเหล่านี้เชื่อมโยงและใช้ในส่วนต่าง ๆ ของระบบ):
central_storage path -> ภายในควรมี models/ ref_data/ subdirectories<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file และ monitor_pool_namecomputer-viz-dl (ค่าเริ่มต้น) พร้อมด้วยแพ็คเกจที่จำเป็นทั้งหมดสำหรับพื้นที่เก็บข้อมูลนี้ คำสั่ง/รหัส Python ทั้งหมดควรจะทำงานภายใน Jupyter นี้central_storage ทำหน้าที่เป็นพื้นที่จัดเก็บไฟล์ส่วนกลางที่ใช้ตลอดการพัฒนาและการปรับใช้ โดยส่วนใหญ่ประกอบด้วยไฟล์โมเดล (รวมถึงเครื่องตรวจจับดริฟท์) และข้อมูลอ้างอิงในรูปแบบปาร์เก้ เมื่อสิ้นสุดขั้นตอนการฝึกโมเดล โมเดลใหม่จะถูกบันทึกที่นี่ และบริการปรับใช้จะดึงโมเดลจากตำแหน่งนี้ ( หมายเหตุ : นี่เป็นสถานที่ที่เหมาะสมที่สุดที่จะแทนที่ด้วยบริการจัดเก็บข้อมูลบนคลาวด์เพื่อความสามารถในการขยายขนาด)model ในการกำหนดค่าเพื่อสร้างโมเดลตัวแยกประเภท โมเดลนี้สร้างขึ้นด้วย TensorFlow และสถาปัตยกรรมของโมเดลนั้นได้รับการฮาร์ดโค้ดที่ tasks/model.py:build_modeldataset ในการกำหนดค่าเพื่อเตรียมชุดข้อมูลสำหรับการฝึก ขั้นตอนนี้ใช้ DvC เพื่อตรวจสอบความสอดคล้องของข้อมูลในดิสก์เปรียบเทียบกับเวอร์ชันที่ระบุในการกำหนดค่า หากมีการเปลี่ยนแปลง ระบบจะแปลงกลับเป็นเวอร์ชันที่ระบุโดยทางโปรแกรม หากคุณต้องการเก็บการเปลี่ยนแปลงไว้ ในกรณีที่คุณกำลังทดลองกับชุดข้อมูล คุณสามารถตั้งค่าฟิลด์ dvc_checkout ในการกำหนดค่าเป็น false เพื่อที่ DvC จะไม่ดำเนินการดังกล่าวtrain ในการกำหนดค่าเพื่อสร้างตัวโหลดข้อมูลและเริ่มกระบวนการฝึกอบรม ข้อมูลการทดลองและสิ่งประดิษฐ์ได้รับการติดตามและบันทึกด้วย MLflow หมายเหตุ: รายงานผลลัพธ์ (ในไฟล์ .html ) จาก DeepChecks จะถูกอัปโหลดไปยังการทดสอบการฝึกบน MLflow สำหรับแบบแผนด้วยmodel ในการกำหนดค่าcentral_storage (ในกรณีนี้ เป็นเพียงการทำสำเนาไปยังตำแหน่ง central_storage นี่คือขั้นตอนที่คุณสามารถเปลี่ยนเป็นการอัปโหลดไฟล์ไปยังที่เก็บข้อมูลบนคลาวด์)model/drift_detection ในการกำหนดค่าcentral_storagecentral_storagecentral_storage (นี่เป็นข้อกังวลประการหนึ่งที่กล่าวถึงในวิดีโอสาธิตการสอน โปรดดูรายละเอียดเพิ่มเติม)current_model_metadata_file ที่จัดเก็บชื่อไฟล์ข้อมูลเมตาของโมเดลที่ลงท้ายด้วย .yaml และ monitor_pool_name จัดเก็บชื่อพูลงานสำหรับการปรับใช้ Prefect worker และโฟลว์cd ใส่เข้าไปใน deployments/prefect-deployments และรัน prefect --no-prompt deploy --name {deploy_name} โดยใช้อินพุตจากส่วน deploy/prefect ในการกำหนดค่า เนื่องจากทุกอย่างได้รับการเชื่อมต่อและบรรจุในคอนเทนเนอร์ใน Repo นี้แล้ว การแปลงบริการจากภายในองค์กรไปเป็นบนคลาวด์จึงค่อนข้างตรงไปตรงมา เมื่อคุณพัฒนาและทดสอบ API บริการของคุณเสร็จแล้ว คุณสามารถแยก services/dl_service ออกไปได้โดยการสร้างคอนเทนเนอร์จาก Dockerfile และพุชไปยังบริการรีจิสทรีคอนเทนเนอร์บนคลาวด์ (เช่น AWS ECR) แค่นั้นแหละ!
หมายเหตุ: มีปัญหาที่อาจเกิดขึ้นอย่างหนึ่งในรหัสบริการ หากคุณต้องการใช้ในสภาพแวดล้อมการใช้งานจริง ฉันได้กล่าวถึงมันในวิดีโอเชิงลึกแล้วและขอแนะนำให้คุณใช้เวลาดูวิดีโอทั้งหมด 
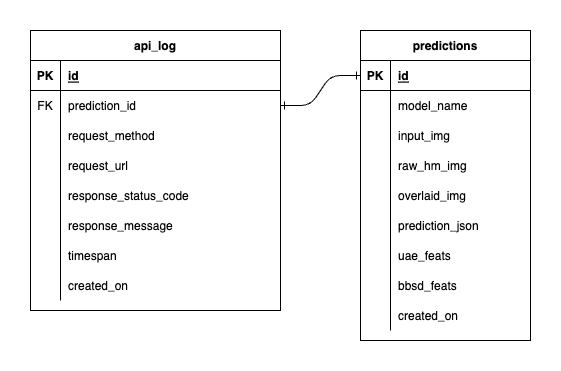
เรามีฐานข้อมูลสามฐานข้อมูลภายใน PostgreSQL: หนึ่งฐานข้อมูลสำหรับ MLflow หนึ่งฐานข้อมูลสำหรับ Prefect และอีกหนึ่งฐานข้อมูลที่เราสร้างขึ้นสำหรับบริการโมเดล ML ของเรา เราจะไม่เจาะลึกสองรายการแรก เนื่องจากเครื่องมือเหล่านั้นจัดการด้วยตนเอง ฐานข้อมูลสำหรับบริการโมเดล ML ของเราเป็นฐานข้อมูลที่เราออกแบบเอง
เพื่อหลีกเลี่ยงความซับซ้อนอย่างล้นหลาม เราได้ทำให้มันเรียบง่ายโดยมีเพียงสองตารางเท่านั้น ความสัมพันธ์และคุณลักษณะแสดงอยู่ใน ERD ด้านล่าง โดยพื้นฐานแล้ว เรามุ่งมั่นที่จะจัดเก็บรายละเอียดที่สำคัญเกี่ยวกับคำขอที่เข้ามาและการตอบกลับของบริการของเรา ตารางทั้งหมดนี้ถูกสร้างขึ้นและจัดการโดยอัตโนมัติ ดังนั้นคุณจึงไม่ต้องกังวลกับการตั้งค่าด้วยตนเอง
น่าสังเกต: input_img , raw_hm_img และ overlaid_img เป็นภาพที่เข้ารหัส base64 ซึ่งจัดเก็บเป็นสตริง uae_feats และ bbsd_feats เป็นอาร์เรย์ของฟีเจอร์การฝังสำหรับอัลกอริธึมการตรวจจับดริฟท์ของเรา
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block ให้ลอง export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 จากนั้นรันใหม่ สคริปต์

