SmartFilteringRAG
1.0.0
เคยค้นหา "หนังตลกขาวดำเก่า" แต่กลับถูกโจมตีด้วยหนังแอ็กชั่นสมัยใหม่ปะปนกันบ้างไหม? น่าหงุดหงิดใช่ไหม? นั่นคือความท้าทายของเครื่องมือค้นหาแบบเดิม เนื่องจากเครื่องมือค้นหามักจะพยายามทำความเข้าใจความแตกต่างเล็กๆ น้อยๆ ของข้อความค้นหาของเรา ส่งผลให้เราต้องเจอกับผลลัพธ์ที่ไม่เกี่ยวข้อง
นี่คือที่มาของการกรองอัจฉริยะ เป็นตัวเปลี่ยนเกมที่ใช้ข้อมูลเมตาและการค้นหาเวกเตอร์เพื่อแสดงผลการค้นหาที่ตรงกับความตั้งใจของคุณอย่างแท้จริง ลองจินตนาการถึงการค้นหาภาพยนตร์ตลกคลาสสิกที่คุณปรารถนาโดยไม่ต้องยุ่งยาก
เราจะเจาะลึกว่าการกรองอัจฉริยะคืออะไร วิธีการทำงาน และเหตุใดจึงจำเป็นสำหรับการสร้างประสบการณ์การค้นหาที่ดีขึ้น มาค้นพบความมหัศจรรย์ที่อยู่เบื้องหลังเทคโนโลยีนี้ และสำรวจว่าเทคโนโลยีนี้จะปฏิวัติวิธีการค้นหาของคุณได้อย่างไร
การค้นหาเวกเตอร์เป็นเครื่องมืออันทรงพลังที่ช่วยให้คอมพิวเตอร์เข้าใจความหมายเบื้องหลังข้อมูล ไม่ใช่แค่คำศัพท์เท่านั้น แทนที่จะจับคู่คำหลัก แต่จะเน้นไปที่แนวคิดและความสัมพันธ์ที่ซ่อนอยู่ ลองนึกภาพการค้นหา "สุนัข" และได้รับผลลัพธ์ที่มีคำว่า "ลูกสุนัข" "สุนัข" และแม้แต่รูปภาพของสุนัข นั่นคือความมหัศจรรย์ของการค้นหาเวกเตอร์!
มันทำงานอย่างไร? มันแปลงข้อมูลเป็นการแทนค่าทางคณิตศาสตร์ที่เรียกว่าเวกเตอร์ เวกเตอร์เหล่านี้เปรียบเสมือนพิกัดบนแผนที่ และจุดข้อมูลที่คล้ายกันจะอยู่ใกล้กันมากขึ้นในพื้นที่เวกเตอร์นี้ เมื่อคุณค้นหาบางสิ่งบางอย่าง ระบบจะค้นหาเวกเตอร์ที่ใกล้กับข้อความค้นหาของคุณมากที่สุด ซึ่งจะทำให้คุณได้ผลลัพธ์ที่คล้ายคลึงกันในเชิงความหมาย
แม้ว่าการค้นหาเวกเตอร์จะยอดเยี่ยมในการทำความเข้าใจบริบท แต่บางครั้งก็ยังไม่เพียงพอเมื่อพูดถึงงานกรองแบบง่ายๆ ตัวอย่างเช่น การค้นหาภาพยนตร์ทั้งหมดที่ออกฉายก่อนปี 2000 ต้องใช้การกรองที่แม่นยำ ไม่ใช่แค่การทำความเข้าใจความหมายเท่านั้น นี่คือจุดที่การกรองอัจฉริยะเข้ามาช่วยเสริมการค้นหาเวกเตอร์
แม้ว่าเวกเตอร์จะทำให้เราเข้าใจความหมายที่แท้จริงของข้อความค้นหามากขึ้น แต่ก็ยังมีช่องว่างระหว่างสิ่งที่ผู้ใช้ต้องการและสิ่งที่เครื่องมือค้นหานำเสนอ ข้อความค้นหาที่ซับซ้อน เช่น "ภาพยนตร์ตลกที่เก่าที่สุดก่อนปี 2000" ยังคงเป็นเรื่องที่ท้าทาย การค้นหาความหมายอาจเข้าใจแนวคิดของ "ตลก" และ "ภาพยนตร์" แต่อาจขัดแย้งกับข้อมูลเฉพาะของ "ยุคแรกสุด" และ "ก่อนปี 2000"
นี่คือจุดที่ผลลัพธ์เริ่มยุ่งเหยิง เราอาจมีทั้งคอมเมดี้เก่าและใหม่ปะปนกัน หรือแม้แต่ละครที่รวมไว้อย่างไม่ถูกต้อง เพื่อให้ผู้ใช้พึงพอใจอย่างแท้จริง เราจำเป็นต้องมีวิธีปรับแต่งผลการค้นหาเหล่านี้ให้แม่นยำยิ่งขึ้น นั่นคือสิ่งที่ตัวกรองล่วงหน้าเข้ามามีบทบาท
การกรองอัจฉริยะคือคำตอบสำหรับความท้าทายนี้ เป็นเทคนิคที่ใช้ข้อมูลเมตาของชุดข้อมูลเพื่อสร้างตัวกรองเฉพาะ ปรับแต่งผลการค้นหา และทำให้มีความแม่นยำและมีประสิทธิภาพมากขึ้น ด้วยการวิเคราะห์ข้อมูลเกี่ยวกับข้อมูลของคุณ เช่น โครงสร้าง เนื้อหา และคุณลักษณะ การกรองอัจฉริยะสามารถระบุเกณฑ์ที่เกี่ยวข้องเพื่อกรองการค้นหาของคุณได้
ลองนึกภาพการค้นหา "ภาพยนตร์ตลกที่ออกฉายก่อนปี 2000" การกรองอัจฉริยะจะใช้ข้อมูลเมตา เช่น ประเภท วันที่ออกฉาย และอาจรวมถึงการวางแผนคำหลักเพื่อสร้างตัวกรองที่รวมเฉพาะภาพยนตร์ที่ตรงกับเกณฑ์เหล่านั้นเท่านั้น ด้วยวิธีนี้ คุณจะได้รับรายการสิ่งที่คุณต้องการอย่างแท้จริง โดยไม่มีเสียงรบกวนที่ไม่เกี่ยวข้อง
มาเจาะลึกถึงวิธีการทำงานของการกรองอัจฉริยะในหัวข้อถัดไป
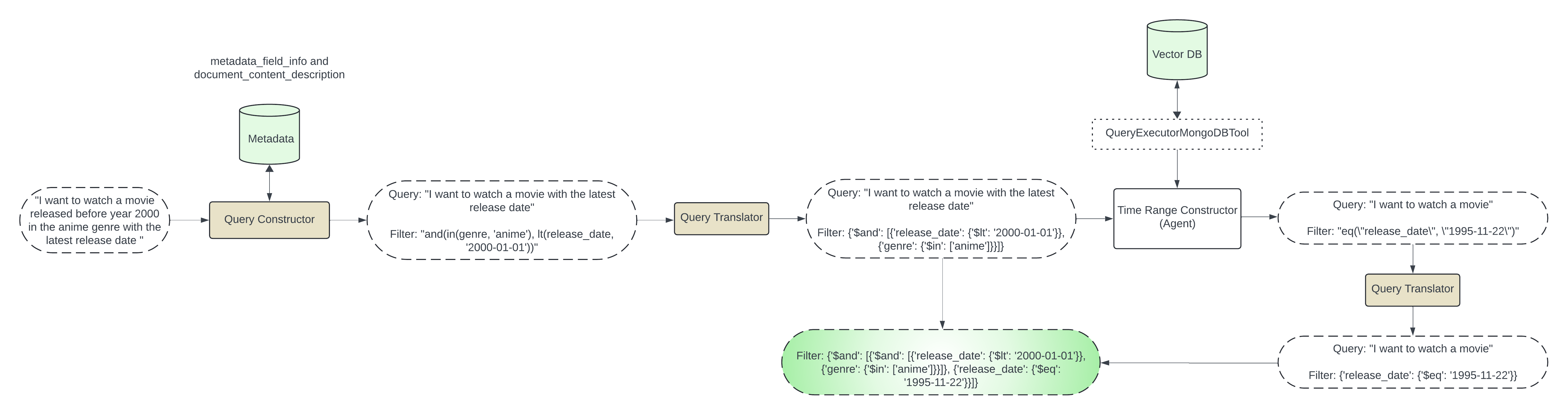
การกรองอัจฉริยะเป็นกระบวนการหลายขั้นตอนที่เกี่ยวข้องกับการแยกข้อมูลจากข้อมูลของคุณ การวิเคราะห์ และสร้างตัวกรองเฉพาะตามความต้องการของคุณ มาทำลายมันกัน:
การดึงข้อมูลเมตา: ขั้นตอนแรกคือการรวบรวมข้อมูลที่เกี่ยวข้องกับข้อมูลของคุณ ซึ่งรวมถึงรายละเอียดเช่น:
การสร้างตัวกรองล่วงหน้า: เมื่อคุณมีข้อมูลเมตาแล้ว คุณสามารถเริ่มสร้างตัวกรองล่วงหน้าได้ นี่เป็นเงื่อนไขเฉพาะที่ข้อมูลต้องปฏิบัติตามจึงจะรวมไว้ในผลการค้นหาได้ ตัวอย่างเช่น หากคุณกำลังค้นหาภาพยนตร์ตลกที่ออกฉายก่อนปี 2000 คุณอาจสร้างตัวกรองล่วงหน้าสำหรับ:
การบูรณาการกับการค้นหาเวกเตอร์: ขั้นตอนสุดท้ายคือการรวมตัวกรองล่วงหน้าเหล่านี้เข้ากับการค้นหาเวกเตอร์ของคุณ เพื่อให้แน่ใจว่าการค้นหาเวกเตอร์จะพิจารณาเฉพาะจุดข้อมูลที่ตรงกับเกณฑ์ที่คุณกำหนดไว้ล่วงหน้าเท่านั้น
เมื่อทำตามขั้นตอนเหล่านี้ การกรองอัจฉริยะจะปรับปรุงความแม่นยำและประสิทธิภาพของผลการค้นหาของคุณได้อย่างมาก
การดึงข้อมูลเมตา: เพื่อจุดประสงค์ในการทำให้สิ่งต่าง ๆ ง่ายขึ้น เราจะใช้ข้อมูลตัวอย่างและกำหนดข้อมูลเมตาด้วยตนเอง อ้างถึง: get_docs_metadata ใน prepare_test_data.py
การสร้างตัวกรองล่วงหน้า: เราจะสร้างตัวกรองล่วงหน้าในสองขั้นตอน
ขั้นตอนที่ 1: ตัวกรองตามข้อมูลเมตา
ขั้นตอนนี้รวมถึงการสร้างตัวกรองตามข้อมูลเมตา เราจะส่งข้อความค้นหาของผู้ใช้และข้อมูลเมตาไปยัง LLM และสร้างตัวกรองข้อมูลเมตา
เราจะใช้ query_constructor ที่เริ่มต้นด้วย DEFAULT_SCHEMA_PROMPT นี้
หมายเหตุ: อัปเดตพรอมต์และตัวอย่างช็อตบางส่วนตามกรณีการใช้งานของคุณ
ตัวอย่างเช่น: หากข้อมูลเมตามี genre และ release_date และผู้ใช้ขอให้มีภาพยนตร์ประเภท action ที่ออกก่อนปี 2020 เราสามารถใช้ LLM เพื่อสร้างตัวกรองดังนี้:
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
ขั้นตอนที่ 2: การกรองตามเวลา
ในขั้นตอนนี้ เราจะจัดการกับกรณีที่ผู้ใช้ขอข้อมูลประเภท latest most recent และ earliest เราจะต้องสืบค้นข้อมูลจริงเพื่อดึงข้อมูลนี้ เราจะใช้ LLM Agent ในขั้นตอนนี้เพื่อสืบค้นคอลเลกชัน mongodb โดยใช้เครื่องมือดำเนินการ: QueryExecutorMongoDBTool เรากำลังสร้างตัวกรองตามเวลาใน Generate_time_based_filter นอกจากนี้เรายังจะใช้ pre_filter ที่สร้างขึ้นในขั้นตอนแรกใน $match ในขั้นตอนการรวมกลุ่ม ตัวอย่างเช่น: หากผู้ใช้ต้องการภาพยนตร์ล่าสุด ตัวแทน LLM จะทำงานด้านล่างแบบสอบถามรวมโดยใช้เครื่องมือดำเนินการ:
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
การบูรณาการกับ Vector Search: ตัวกรองล่วงหน้าที่สร้างขึ้นจะถูกใช้กับ MongoDBATlasVectorSearch รีทรีฟเวอร์:
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)สร้างสภาพแวดล้อมหลามใหม่
python3 -m venv env
source env/bin/activateติดตั้งข้อกำหนด
pip3 install -r requirements.txtตั้งค่าการกำหนดค่าใน config.yaml
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002ตั้งค่าตัวแปรสภาพแวดล้อม
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "เริ่มต้นคอลเลกชัน mongodb ด้วยข้อมูลตัวอย่าง คำสั่งนี้จะสร้างดัชนีข้อมูลตัวอย่างบางส่วนและสร้างดัชนีการค้นหาเวกเตอร์ในคอลเลกชันด้วย
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] 'Pre_filters ที่สร้างขึ้น:
ข้อความค้นหา: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
เอาท์พุท: 
อินพุตแบบสอบถาม: "Recommend a thriller or action movie release after Feb, 2010"
เอาท์พุท: 
อินพุตแบบสอบถาม: "Recommend an anime movie released before 2023 with the latest release date"
เอาท์พุท: 
การกรองอัจฉริยะนำข้อดีมากมายมาสู่ตาราง ทำให้เป็นเครื่องมืออันมีค่าสำหรับการปรับปรุงประสบการณ์การค้นหา:
ความแม่นยำในการค้นหาที่ได้รับการปรับปรุง: ด้วยการกำหนดเป้าหมายข้อมูลที่ตรงกับข้อความค้นหาของคุณอย่างแม่นยำ การกรองอัจฉริยะจะช่วยเพิ่มโอกาสในการค้นหาผลลัพธ์ที่เกี่ยวข้องได้อย่างมาก ไม่ต้องลุยข้อมูลที่ไม่เกี่ยวข้องอีกต่อไป
ผลลัพธ์การค้นหาที่รวดเร็วยิ่งขึ้น: เนื่องจากการกรองอัจฉริยะทำให้ขอบเขตการค้นหาแคบลง ระบบจึงสามารถประมวลผลข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น ส่งผลให้ได้ผลลัพธ์ที่รวดเร็วยิ่งขึ้น
ประสบการณ์ผู้ใช้ที่ได้รับการปรับปรุง: เมื่อผู้ใช้พบสิ่งที่ต้องการอย่างรวดเร็วและง่ายดาย จะนำไปสู่ความพึงพอใจที่สูงขึ้นและประสบการณ์โดยรวมที่ดีขึ้น
ความคล่องตัว: การกรองอัจฉริยะสามารถนำไปใช้กับโดเมนต่างๆ ตั้งแต่การค้นหาผลิตภัณฑ์อีคอมเมิร์ซไปจนถึงการแนะนำเนื้อหา ทำให้เป็นเครื่องมืออเนกประสงค์
ด้วยการใช้ประโยชน์จากข้อมูลเมตาและการสร้างตัวกรองล่วงหน้าที่เป็นเป้าหมาย Smart Filtering ช่วยให้คุณสามารถนำเสนอผลการค้นหาที่ตรงกับความคาดหวังของผู้ใช้อย่างแท้จริง
การกรองอัจฉริยะเป็นเครื่องมืออันทรงพลังที่เปลี่ยนแปลงประสบการณ์โดยการเชื่อมช่องว่างระหว่างความตั้งใจของผู้ใช้และผลลัพธ์ ด้วยการควบคุมพลังของเมทาดาทาและการค้นหาเวกเตอร์ จึงสามารถให้ผลลัพธ์การค้นหาที่แม่นยำ ตรงประเด็น และมีประสิทธิภาพมากขึ้น
ไม่ว่าคุณกำลังสร้างแพลตฟอร์มอีคอมเมิร์ซ ระบบแนะนำเนื้อหา หรือแอปพลิเคชันใดๆ ที่ต้องอาศัยการค้นหาที่มีประสิทธิภาพ การรวมระบบกรองอัจฉริยะจะช่วยเพิ่มความพึงพอใจของผู้ใช้ได้อย่างมากและขับเคลื่อนผลลัพธ์ที่ดีขึ้น
ด้วยการทำความเข้าใจพื้นฐานของการกรองอัจฉริยะ คุณจะพร้อมที่จะสำรวจศักยภาพและนำไปใช้ในโครงการของคุณ แล้วจะรอทำไม? เริ่มใช้ประโยชน์จากพลังของการกรองอัจฉริยะวันนี้และปฏิวัติเกมการค้นหาของคุณ!
แรงบันดาลใจจาก Self Query Retriever ของ LangChain


