genkitx hnsw
1.0.0

คุณสามารถสนับสนุนปลั๊กอินนี้ได้ในพื้นที่เก็บข้อมูลนี้
HNSW คือกราฟ Vector Database Hierarchical Navigable Small World (HNSW) เป็นหนึ่งในดัชนีที่มีประสิทธิภาพสูงสุดสำหรับการค้นหาความคล้ายคลึงกันของเวกเตอร์ HNSW เป็นเทคโนโลยีที่ได้รับความนิยมอย่างมากซึ่งครั้งแล้วครั้งเล่าทำให้เกิดประสิทธิภาพที่ล้ำสมัยด้วยความเร็วในการค้นหาที่รวดเร็วเป็นพิเศษและการเรียกคืนข้อมูลที่ยอดเยี่ยม เรียนรู้เพิ่มเติมเกี่ยวกับ HNSW
คุณสามารถเลือกฐานข้อมูลเวกเตอร์นี้ได้หากต้องการ
ด้วยวิธีนี้ คุณสามารถบรรลุการดึงข้อมูล Augmentation Generation (RAG) ที่มีประสิทธิภาพสูงใน Generative AI ได้ ดังนั้นคุณไม่จำเป็นต้องสร้างโมเดล AI ของคุณเองหรือฝึกโมเดล AI ใหม่เพื่อรับบริบทหรือความรู้มากขึ้น คุณสามารถเพิ่มเลเยอร์บริบทเพิ่มเติมเพื่อที่ โมเดล AI ของคุณสามารถเข้าใจความรู้ได้มากกว่าสิ่งที่โมเดล AI พื้นฐานรู้ สิ่งนี้มีประโยชน์ถ้าคุณต้องการได้รับบริบทเพิ่มเติมหรือความรู้เพิ่มเติมตามข้อมูลเฉพาะหรือความรู้ที่คุณกำหนด
คุณมีแอปพลิเคชันหรือเว็บไซต์ร้านอาหาร คุณสามารถเพิ่มข้อมูลเฉพาะเกี่ยวกับร้านอาหาร ที่อยู่ รายการเมนูอาหารพร้อมราคาและสิ่งเฉพาะอื่นๆ เพื่อที่เมื่อลูกค้าของคุณถาม AI เกี่ยวกับร้านอาหารของคุณ AI ของคุณจะสามารถตอบได้อย่างถูกต้อง . สิ่งนี้สามารถขจัดความพยายามของคุณในการสร้าง Chatbot แต่คุณสามารถใช้ Generative AI ที่เสริมความรู้เฉพาะด้านแทนได้
ตัวอย่างการสนทนา :
You : ร้านอาหารของฉันในสุราบายาราคาเท่าไหร่
AI : รายการราคา :
ก่อนที่จะติดตั้งปลั๊กอิน ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งข้อกำหนดเบื้องต้นต่อไปนี้:
npm install -g typescript )หากต้องการติดตั้งปลั๊กอินนี้ คุณสามารถรันคำสั่งนี้หรือกับตัวจัดการแพ็คเกจที่คุณต้องการได้
npm install genkitx-hnswปลั๊กอินนี้มีฟังก์ชันการทำงานหลายอย่างดังนี้:
HNSW Indexer ใช้เพื่อสร้างดัชนีเวกเตอร์ตามข้อมูลและข้อมูลทั้งหมดที่คุณให้ไว้ ดัชนีเวกเตอร์นี้จะใช้เป็นข้อมูลอ้างอิงความรู้ของ HNSW รีทรีฟเวอร์HNSW Retriever ใช้เพื่อรับการตอบสนอง Generative AI ด้วยโมเดล Gemini เป็นฐานที่เสริมความรู้และบริบทเพิ่มเติมตามดัชนีเวกเตอร์ของคุณ นี่คือการใช้โฟลว์ปลั๊กอิน Genkit เพื่อบันทึกข้อมูลลงในร้านค้าเวกเตอร์ด้วย HNSW Vector Store, Gemini Embedder และ Gemini LLM
เตรียมข้อมูลหรือเอกสารของคุณในโฟลเดอร์ 
นำเข้าปลั๊กอินไปยังโปรเจ็กต์ Genkit ของคุณ
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; เปิด Genkit UI และเลือกปลั๊กอิน HNSW Indexer ที่ลงทะเบียนไว้
ดำเนินการโฟลว์ด้วยพารามิเตอร์อินพุตและเอาต์พุตที่จำเป็น
dataPath : ข้อมูลของคุณและเส้นทางเอกสารอื่น ๆ ที่ AI จะเรียนรู้indexOutputPath : พาธเอาต์พุตที่คาดหวังสำหรับดัชนี Vector Store ของคุณที่ได้รับการประมวลผลตามข้อมูลและเอกสารที่คุณระบุ 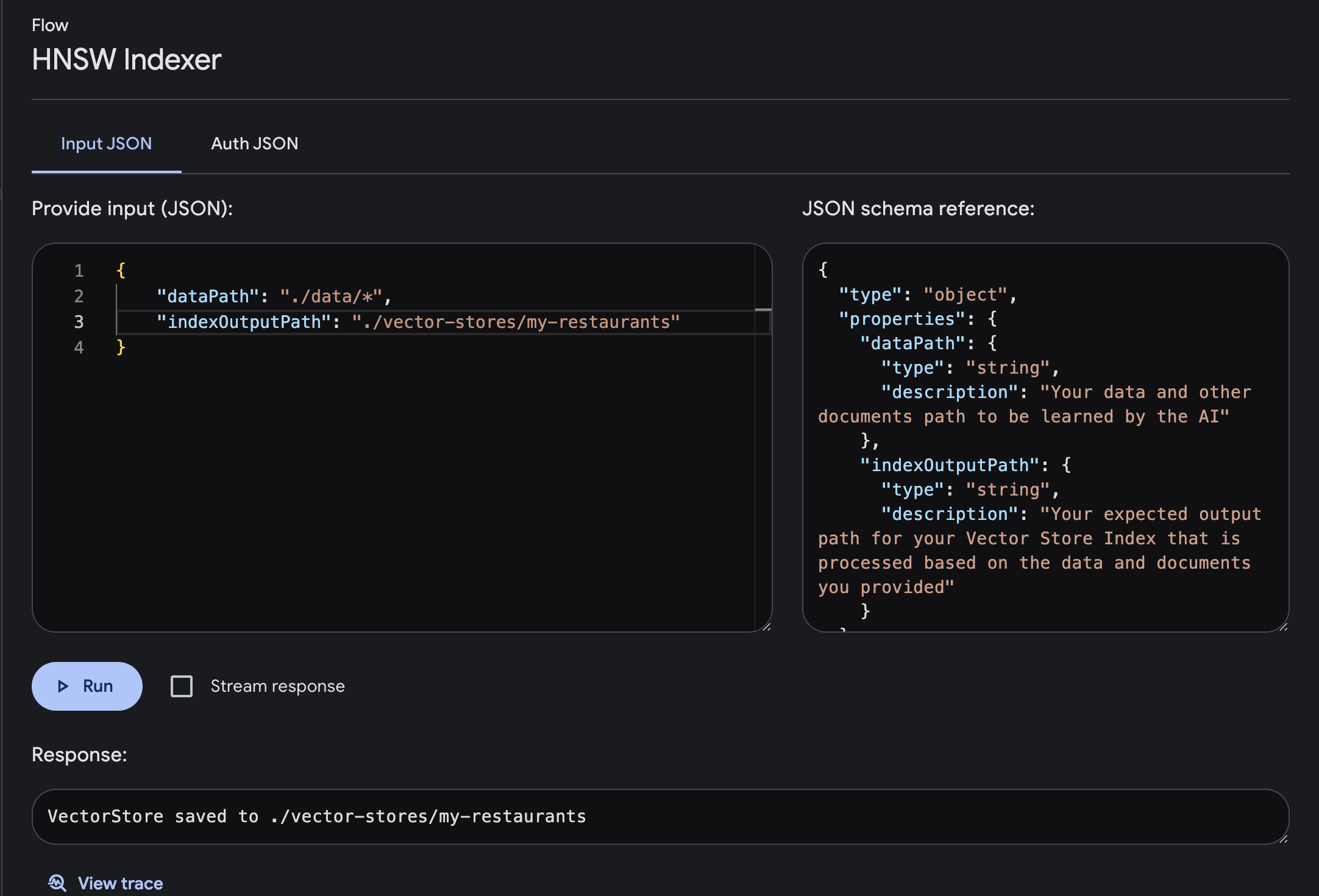
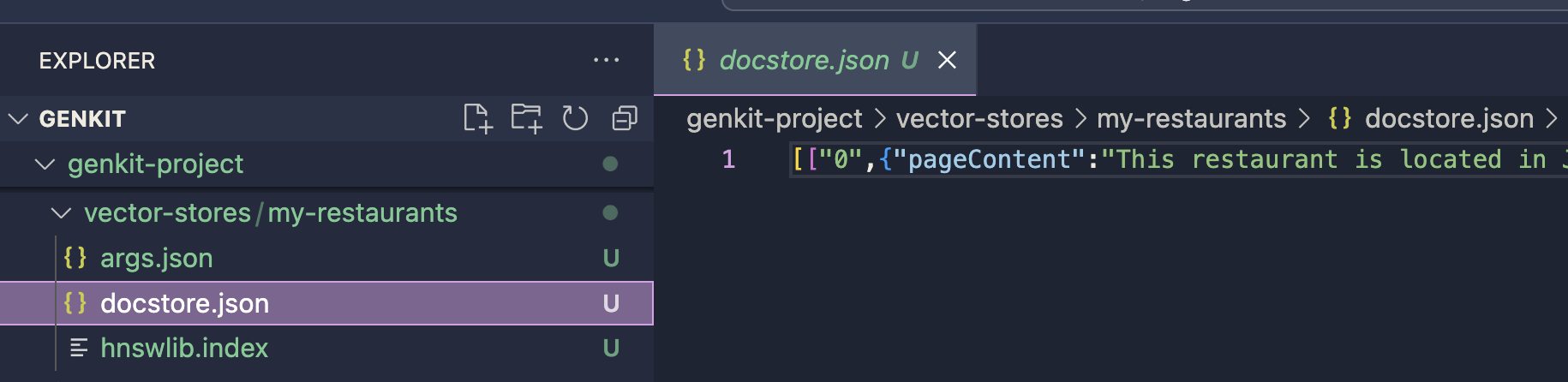 ที่เก็บเวกเตอร์จะถูกบันทึกไว้ในเส้นทางเอาต์พุตที่กำหนด ดัชนีนี้จะใช้สำหรับกระบวนการสร้างพรอมต์ด้วยปลั๊กอิน HNSW Retriever คุณสามารถดำเนินการใช้งานต่อไปได้โดยใช้ปลั๊กอิน HNSW Retriever
ที่เก็บเวกเตอร์จะถูกบันทึกไว้ในเส้นทางเอาต์พุตที่กำหนด ดัชนีนี้จะใช้สำหรับกระบวนการสร้างพรอมต์ด้วยปลั๊กอิน HNSW Retriever คุณสามารถดำเนินการใช้งานต่อไปได้โดยใช้ปลั๊กอิน HNSW Retriever
chunkSize: number ข้อมูลที่ถูกประมวลผลในแต่ละครั้ง มันเหมือนกับการแบ่งงานใหญ่ออกเป็นชิ้นเล็ก ๆ เพื่อให้จัดการได้ง่ายขึ้น ด้วยการตั้งค่าขนาดก้อน เราจะตัดสินใจว่า AI จะจัดการข้อมูลได้มากเพียงใดในครั้งเดียว ซึ่งอาจส่งผลต่อทั้งความเร็วและความแม่นยำของกระบวนการเรียนรู้ของ AI
default value : 12720
separator: string ในระหว่างการสร้างดัชนีเวกเตอร์จะมีสัญลักษณ์หรืออักขระที่ใช้ในการแยกส่วนข้อมูลต่างๆ ในข้อมูลอินพุต ช่วยให้ AI เข้าใจว่าหน่วยข้อมูลหนึ่งสิ้นสุดที่ใดและอีกหน่วยหนึ่งเริ่มต้นที่ใด ทำให้สามารถประมวลผลและเรียนรู้จากข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น
default value : "n"
นี่คือการใช้โฟลว์ปลั๊กอิน Genkit เพื่อประมวลผลพร้อมท์ของคุณด้วยโมเดล Gemini LLM ที่เสริมด้วยข้อมูลหรือความรู้เพิ่มเติมเฉพาะเจาะจงภายในฐานข้อมูล HNSW Vector ที่คุณให้ไว้ ด้วยปลั๊กอินนี้ คุณจะได้รับการตอบสนอง LLM พร้อมบริบทเฉพาะเพิ่มเติม
นำเข้าปลั๊กอินไปยังโปรเจ็กต์ Genkit ของคุณ
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;ตรวจสอบให้แน่ใจว่าคุณนำเข้าปลั๊กอิน GoogleAI สำหรับผู้ให้บริการโมเดล Gemini LLM ซึ่งปัจจุบันปลั๊กอินนี้รองรับเฉพาะ Gemini เท่านั้น และจะมีโมเดลเพิ่มเติมเร็วๆ นี้!
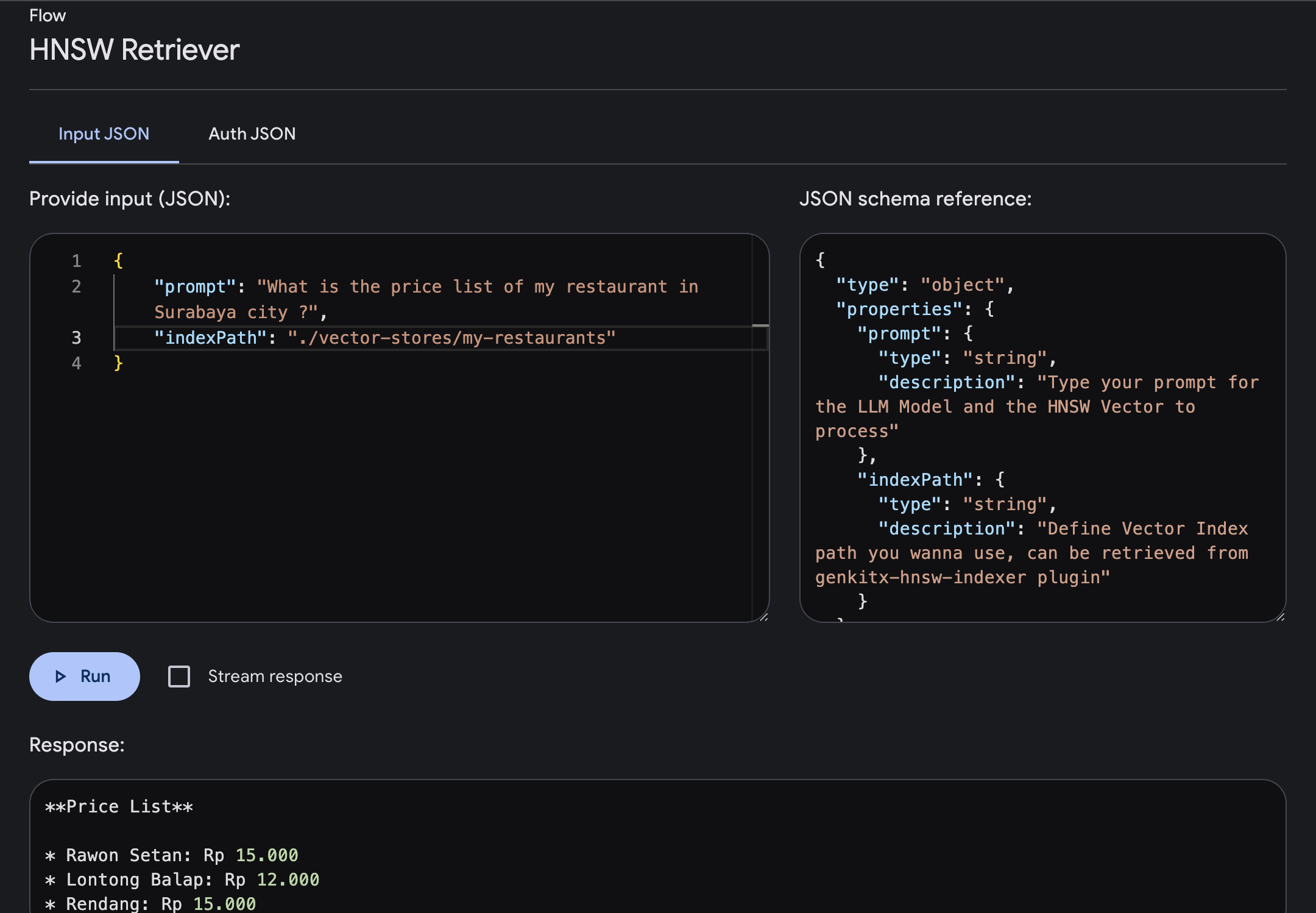
เปิด Genkit UI และเลือกปลั๊กอิน HNSW Retriever ที่ลงทะเบียนไว้ ดำเนินการโฟลว์ด้วยพารามิเตอร์ที่ต้องการ
prompt : พิมพ์พร้อมท์ของคุณโดยที่คุณจะได้รับคำตอบพร้อมบริบทที่สมบูรณ์ยิ่งขึ้นตามเวกเตอร์ที่คุณระบุindexPath : กำหนดพาธดัชนีเวกเตอร์ของโฟลเดอร์ที่คุณต้องการใช้เป็นข้อมูลอ้างอิง โดยที่คุณจะได้รับพาธของไฟล์นี้จากปลั๊กอิน HNSW Indexerในตัวอย่างนี้ ลองถามเกี่ยวกับข้อมูลรายการราคาของร้านอาหารในเมืองสุราบายาซึ่งมีการระบุไว้ในดัชนีเวกเตอร์
เราสามารถพิมพ์พรอมต์และเรียกใช้ได้ หลังจากโฟลว์เสร็จสิ้น คุณจะได้รับคำตอบที่เสริมความรู้เฉพาะทางตามดัชนีเวกเตอร์ของคุณ
temperature: number จะควบคุมความสุ่มของเอาต์พุตที่สร้างขึ้น อุณหภูมิที่ต่ำลงส่งผลให้ได้เอาท์พุตที่กำหนดได้มากขึ้น โดยแบบจำลองจะเลือกโทเค็นที่เป็นไปได้มากที่สุดในแต่ละขั้นตอน อุณหภูมิที่สูงขึ้นจะเพิ่มการสุ่ม ทำให้แบบจำลองสามารถสำรวจโทเค็นที่น่าจะเป็นไปได้น้อยลง และอาจสร้างข้อความที่สร้างสรรค์มากขึ้นแต่มีความสอดคล้องกันน้อยลง
default value : 0.1
maxOutputTokens: number พารามิเตอร์นี้ระบุจำนวนโทเค็นสูงสุด (คำหรือคำย่อย) ที่โมเดลควรสร้างในขั้นตอนการอนุมานเดียว ช่วยควบคุมความยาวของข้อความที่สร้างขึ้น
default value : 500
topK: number การสุ่มตัวอย่าง Top-K จำกัดตัวเลือกของโมเดลไว้ที่โทเค็น K ที่เป็นไปได้มากที่สุดในแต่ละขั้นตอน ซึ่งจะช่วยป้องกันไม่ให้โมเดลพิจารณาโทเค็นที่หายากหรือไม่น่าจะเป็นไปได้มากเกินไป ซึ่งจะช่วยปรับปรุงการเชื่อมโยงกันของข้อความที่สร้างขึ้น
default value : 1
topP: number การสุ่มตัวอย่าง Top-P หรือที่เรียกว่าการสุ่มตัวอย่างนิวเคลียส พิจารณาการกระจายความน่าจะเป็นสะสมของโทเค็น และเลือกชุดโทเค็นที่เล็กที่สุดซึ่งความน่าจะเป็นสะสมเกินเกณฑ์ที่กำหนดไว้ล่วงหน้า (มักแสดงเป็น P) ซึ่งช่วยให้สามารถเลือกจำนวนโทเค็นที่พิจารณาในแต่ละขั้นตอนแบบไดนามิกได้ ขึ้นอยู่กับความเป็นไปได้ของโทเค็น
default value : 0
stopSequences: string[] คือลำดับของโทเค็นที่เมื่อสร้างขึ้น จะส่งสัญญาณให้โมเดลหยุดการสร้างข้อความ สิ่งนี้มีประโยชน์ในการควบคุมความยาวหรือเนื้อหาของเอาต์พุตที่สร้างขึ้น เช่น การตรวจสอบให้แน่ใจว่าโมเดลหยุดสร้างหลังจากถึงจุดสิ้นสุดของประโยคหรือย่อหน้า
default value : []
ลิขสิทธิ์ : อาปาเช่ 2.0


