content dicovery platform gcp
1.0.0
พื้นที่เก็บข้อมูลนี้มีโค้ดและระบบอัตโนมัติที่จำเป็นในการสร้างแพลตฟอร์มการค้นพบเนื้อหาอย่างง่ายที่ขับเคลื่อนโดยโมเดลพื้นฐานของ VertexAI แพลตฟอร์มนี้ควรจะสามารถจับภาพเนื้อหาเอกสารได้ (เริ่มแรกคือ Google Docs) และด้วยเนื้อหานั้นจะสร้างเวกเตอร์การฝังเพื่อจัดเก็บไว้ในฐานข้อมูลเวกเตอร์ที่ขับเคลื่อนโดย VertexAI Matching Engine หลังจากนั้น การฝังนี้สามารถใช้เพื่อกำหนดบริบทของคำถามทั่วไปของผู้บริโภคภายนอกและด้วย บริบทนั้นขอคำตอบสำหรับโมเดลพื้นฐานของ VertexAI เพื่อรับคำตอบ
แพลตฟอร์มสามารถแยกออกเป็น 4 องค์ประกอบหลัก ได้แก่ ชั้นบริการการเข้าถึง ไปป์ไลน์การจับเนื้อหา พื้นที่จัดเก็บเนื้อหา และ LLM ชั้นบริการช่วยให้ผู้บริโภคภายนอกสามารถส่งคำขอการนำเข้าเอกสาร และส่งคำถามเกี่ยวกับเนื้อหาที่รวมอยู่ในเอกสารที่นำเข้าก่อนหน้านี้ได้ในภายหลัง ไปป์ไลน์การจับเนื้อหามีหน้าที่จับเนื้อหาของเอกสารใน NRT แยกการฝังและแมปการฝังด้วยเนื้อหาจริงที่สามารถนำมาใช้ในภายหลังเพื่อกำหนดบริบทคำถามของผู้ใช้ภายนอกไปยัง LLM การจัดเก็บเนื้อหาถูกแยกออกตามวัตถุประสงค์ที่แตกต่างกัน 3 ประการ ได้แก่ การปรับแต่ง LLM อย่างละเอียด การจับคู่การฝังแบบออนไลน์และเนื้อหาแบบเป็นก้อน ซึ่งแต่ละรายการได้รับการจัดการโดยระบบจัดเก็บข้อมูลแบบพิเศษ และมีวัตถุประสงค์ทั่วไปในการจัดเก็บข้อมูลที่จำเป็นสำหรับส่วนประกอบของแพลตฟอร์มเพื่อดำเนินการนำเข้าและสืบค้น ใช้กรณี สุดท้ายแต่ไม่ท้ายสุด แพลตฟอร์มใช้ LLM เฉพาะทาง 2 ตัวเพื่อสร้างการฝังแบบเรียลไทม์จากเนื้อหาเอกสารที่นำเข้า และอีกตัวหนึ่งรับผิดชอบในการสร้างคำตอบที่ผู้ใช้แพลตฟอร์มร้องขอ
ส่วนประกอบทั้งหมดที่อธิบายไว้ก่อนหน้านี้ได้รับการนำไปใช้งานโดยใช้บริการ GCP ที่เปิดเผยต่อสาธารณะ เพื่อระบุ: Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, โมเดล Vertex AI Fundational (การฝังและ text-bison) พร้อมด้วย Google Docs และ Google Drive เป็นข้อมูลสารสนเทศของเนื้อหา แหล่งที่มา
รูปภาพถัดไปแสดงให้เห็นว่าส่วนประกอบต่างๆ ของสถาปัตยกรรมและเทคโนโลยีมีปฏิสัมพันธ์ระหว่างกันอย่างไร
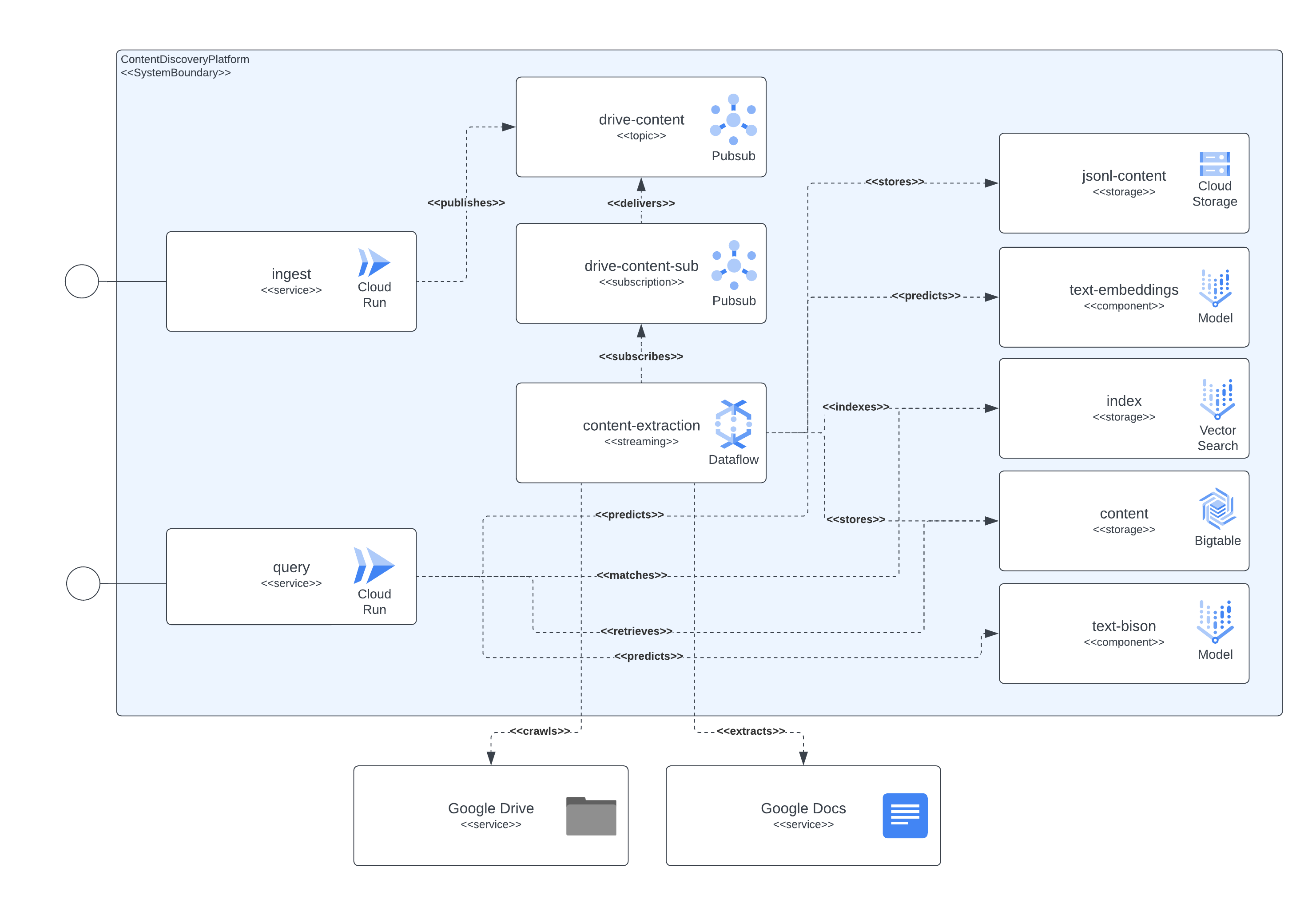
แพลตฟอร์มนี้ใช้ Terraform สำหรับการตั้งค่าส่วนประกอบทั้งหมด สำหรับผู้ที่ไม่มีการสนับสนุนแบบเนทีฟในขณะนี้ เราได้สร้าง wrappers null_resource นี่เป็นวิธีแก้ปัญหาที่ดี แต่มีแนวโน้มที่จะมีขอบที่หยาบมาก ดังนั้นโปรดระวังข้อผิดพลาดที่อาจเกิดขึ้น
การปรับใช้ให้เสร็จสมบูรณ์ ณ วันนี้ (มิถุนายน 2023) อาจใช้เวลาถึง 90 นาทีจึงจะเสร็จสมบูรณ์ ต้นเหตุที่ใหญ่ที่สุดคือส่วนประกอบที่เกี่ยวข้องกับ Matching Engine ซึ่งใช้เวลาส่วนใหญ่ในการสร้างและพร้อมใช้งาน เมื่อเวลาผ่านไป รันไทม์ที่ขยายออกไปนี้จะปรับปรุงเท่านั้น
การตั้งค่าควรดำเนินการได้จากสคริปต์ที่รวมอยู่ในพื้นที่เก็บข้อมูล
มีข้อกำหนดบางประการที่ต้องปฏิบัติตามเพื่อปรับใช้แพลตฟอร์มนี้ ได้แก่:
เพื่อให้ส่วนประกอบทั้งหมดใช้งานได้ใน GCP เราจำเป็นต้องสร้าง สร้างโครงสร้างพื้นฐาน และปรับใช้บริการและไปป์ไลน์ในภายหลัง
เพื่อให้บรรลุเป้าหมายนี้ เราได้รวมสคริปต์ start.sh ซึ่งโดยทั่วไปจะประสานสคริปต์อื่นๆ ที่รวมไว้เพื่อให้บรรลุเป้าหมายการปรับใช้ทั้งหมด
นอกจากนี้ เรายังรวมสคริปต์ cleanup.sh ที่รับผิดชอบในการทำลายโครงสร้างพื้นฐานและล้างข้อมูลที่รวบรวมไว้อีกด้วย
ในกรณีปกติ เอกสาร Google Workspace จะถูกสร้างขึ้นในองค์กรเดียวกันกับที่โฮสต์โปรเจ็กต์ที่ไปป์ไลน์การนำเข้าเนื้อหา ดังนั้นเพื่อที่จะให้สิทธิ์แก่เอกสารเหล่านั้นโดยเพิ่มบัญชีบริการที่เรียกใช้ไปป์ไลน์ไปยังเอกสารหรือโฟลเดอร์ของเอกสาร ควรจะเพียงพอแล้ว
ในกรณีที่ต้องการเข้าถึงเอกสารหรือโฟลเดอร์ที่มีอยู่ภายนอกองค์กรของโครงการ ควรดำเนินการขั้นตอนเพิ่มเติมให้เสร็จสิ้น เมื่อตั้งค่าโครงสร้างพื้นฐานแล้ว กระบวนการปรับใช้จะพิมพ์คำแนะนำเพื่อมอบสิทธิ์ให้กับบัญชีบริการที่เรียกใช้สิทธิ์ไปป์ไลน์การแยกเนื้อหาเพื่อเลียนแบบการเข้าถึงเอกสาร Google Workspace ผ่านการมอบหมายทั่วทั้งโดเมน สามารถดูข้อมูลในการทำตามขั้นตอนต่างๆ ได้ที่นี่: https://developers.google.com/workspace/guides/create-credentials#Option_set_up_domain-wide_delegation_for_a_service_account
โซลูชันนี้เปิดเผยทรัพยากรบางส่วนผ่าน GCP CloudRun และ API Gateway ซึ่งสามารถใช้เพื่อโต้ตอบกับการนำเข้าเนื้อหาและการค้นหาเนื้อหา ในตัวอย่างทั้งหมด เราใช้สตริง <service-address> สัญลักษณ์ ซึ่งควรแทนที่ด้วย URL ที่ได้รับจาก CloudRun ( backend_service_url จากเอาต์พุต Terraform) หรือ API Gateway ( sevice_url จากเอาต์พุต Terraform) หลังจากการปรับใช้บริการเสร็จสมบูรณ์
เมื่อต้องการโต้ตอบ CORS ตำแหน่งข้อมูล API Gateway อาจถูกนำมาใช้เมื่อต้องการดำเนินการโปรโตคอล preflight ให้เสร็จสิ้น ปัจจุบัน CloudRun ไม่รองรับคำสั่ง OPTIONS ที่ไม่ได้รับการรับรองความถูกต้อง แต่เส้นทางเหล่านั้นที่เปิดเผยผ่าน API Gateway รองรับคำสั่งเหล่านั้น
บริการนี้สามารถนำเข้าข้อมูลจากเอกสารที่โฮสต์ใน Google ไดรฟ์หรือคำขอที่มีหลายส่วนในตัวเองซึ่งมีตัวระบุเอกสารและเนื้อหาของเอกสารที่เข้ารหัสเป็นไบนารี
การส่งผ่านข้อมูลของ Google Drive ทำได้โดยการส่งคำขอ HTTP คล้ายกับตัวอย่างถัดไป
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' คำขอนี้จะระบุแพลตฟอร์มที่จะดึงเอกสารจาก url ที่ให้ไว้ และในกรณีที่บัญชีบริการที่ดำเนินการนำเข้ามีสิทธิ์เข้าถึงเอกสาร ก็จะแยกเนื้อหาจากเอกสารนั้นและจัดเก็บข้อมูลไว้สำหรับการจัดทำดัชนี การค้นพบและการเรียกข้อมูลในภายหลัง
คำขออาจมี URL ของเอกสาร Google หรือโฟลเดอร์ Google ไดรฟ์ ในกรณีสุดท้าย การนำเข้าจะรวบรวมข้อมูลโฟลเดอร์เพื่อให้เอกสารประมวลผล นอกจากนี้ คุณสามารถใช้ urls ของคุณสมบัติที่คาดหวัง JSONArray ของค่า string โดยแต่ละรายการเป็น URL เอกสาร Google ที่ถูกต้อง
ในกรณีที่ต้องการรวมเนื้อหาของบทความ เอกสาร หรือเพจที่ไคลเอ็นต์การนำเข้าสามารถเข้าถึงได้ในเครื่อง การใช้จุดสิ้นสุดแบบหลายส่วนควรจะเพียงพอที่จะนำเข้าเอกสาร ดูคำสั่ง curl ถัดไปเป็นตัวอย่าง บริการคาดหวังว่าฟิลด์แบบฟอร์ม documentId จะถูกตั้งค่าเพื่อระบุและจัดทำดัชนีเนื้อหาแบบเดี่ยว:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartบริการนี้เปิดเผยความสามารถในการสืบค้นให้กับผู้ใช้แพลตฟอร์ม โดยการส่งข้อความสืบค้นตามธรรมชาติไปยังบริการ และเนื่องจากมีดัชนีเนื้อหาอยู่แล้วหลังจากการนำเข้าในแพลตฟอร์ม บริการจึงกลับมาพร้อมกับข้อมูลที่สรุปโดยโมเดล LLM
การโต้ตอบกับบริการสามารถทำได้ผ่านการแลกเปลี่ยน REST ซึ่งคล้ายกับการแลกเปลี่ยนในส่วนการนำเข้า ดังที่เห็นในตัวอย่างถัดไป
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}มีกรณีพิเศษที่นี่ ซึ่งยังไม่มีข้อมูลที่จัดเก็บไว้สำหรับหัวข้อใดหัวข้อหนึ่ง หากหัวข้อนั้นอยู่ในแนวนอนของ GCP โมเดลจะทำหน้าที่เป็นผู้เชี่ยวชาญเนื่องจากเราตั้งค่าข้อความแจ้งที่บ่งชี้สิ่งนั้นในคำขอของโมเดล
ในกรณีที่ต้องการมีการแลกเปลี่ยนประเภทที่คำนึงถึงบริบทมากขึ้นกับบริการ ควรระบุตัวระบุเซสชัน (คุณสมบัติ sessionId ในคำขอ JSON) เพื่อให้บริการใช้เป็นคีย์การแลกเปลี่ยนการสนทนา คีย์การสนทนานี้จะใช้เพื่อตั้งค่าบริบทที่ถูกต้องให้กับโมเดล (โดยการสรุปการแลกเปลี่ยนก่อนหน้า) และติดตามการแลกเปลี่ยน 5 ครั้งล่าสุด (อย่างน้อย) นอกจากนี้ ควรทราบด้วยว่าประวัติการแลกเปลี่ยนจะถูกเก็บรักษาไว้เป็นเวลา 24 ชั่วโมง ซึ่งสามารถเปลี่ยนแปลงได้ โดยเป็นส่วนหนึ่งของนโยบาย gc ของพื้นที่เก็บข้อมูล BigTable ในแพลตฟอร์ม
ต่อไป ตัวอย่างสำหรับการสนทนาตามบริบท:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

