qevals
1.0.0
Evals คือเฟรมเวิร์กการสร้างและประเมินผลข้อมูลสังเคราะห์สำหรับแอปพลิเคชัน LLM และ RAG
มี 2 โมดูลหลัก:
แผนภาพสถาปัตยกรรมระดับสูงของ eval มีดังต่อไปนี้:
แผนภาพสถาปัตยกรรม
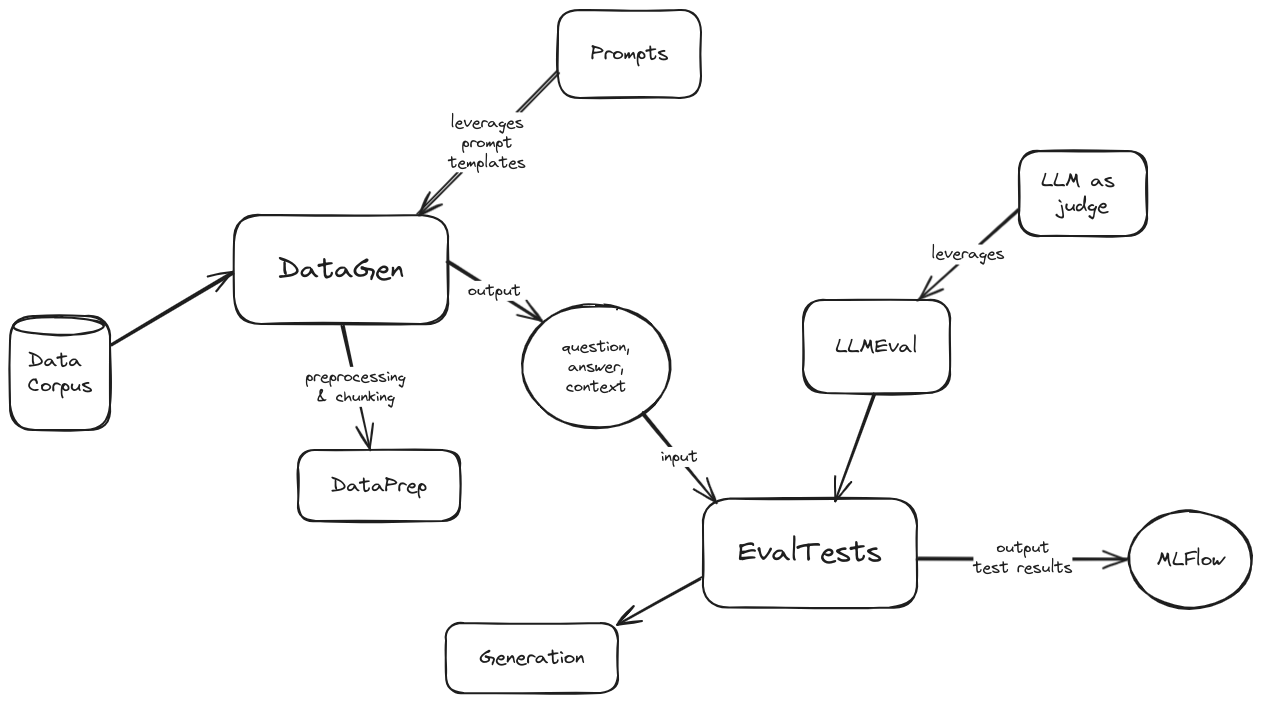
หากต้องการเริ่มต้นใช้งาน eval ให้ทำตามขั้นตอนเหล่านี้:
pip install -r requirements.txt ในไดเร็กทอรีโปรเจ็กต์config/config.toml.template และตั้งชื่อเป็น config/config.tomlconfig.toml :MISCDATAGENDATA_DIR เพื่อควบคุมตำแหน่งของคลังข้อมูลเพื่อสร้างข้อมูลสังเคราะห์ โดยสัมพันธ์กับไดเร็กทอรี datagen/data/ กล่าวอีกนัยหนึ่ง ให้เพิ่มไดเร็กทอรีข้อมูลของคุณลงในนั้นและระบุชื่อในตัวแปรGEN_PROVIDER อนุญาตให้เลือกระหว่าง azure หรือ vertexDATAEVALEVAL_TESTS เสนอรายการการทดสอบประเมินผลที่สนับสนุนโดยเฟรมเวิร์ก ตัวเลือกที่เป็นไปได้ ได้แก่ AnswerRelevancy , Hallucination , Faithfulness , Bias , Toxicity , Correctness , Coherence , PromptInjection , PromptBreaking , PromptLeakageEVAL_RPVODER ช่วยให้สามารถเลือกระหว่าง azure หรือ vertexในการรันโมดูลการสร้างข้อมูลสังเคราะห์:
แก้ไข / ปรับไคลเอนต์ตัวอย่างที่ให้มา ( datagen/client.py )
เรียกใช้ python -m datagen.client
ข้อมูลที่สร้างขึ้นแบบสังเคราะห์จะถูกจัดเก็บไว้ในไดเร็กทอรี datagen/qa_out/ เป็นไฟล์ CSV ที่มีรูปแบบ:
```csv
question,context,ground_truth
```
ในการรันโมดูล eval:
eval/client.py )question context ground_truth )ground_truth อาจใช้หรือไม่ก็ได้ ขึ้นอยู่กับการตั้งค่า use_answers_from_dataset เมื่อตั้งค่าเป็น False ระบบจะเพิกเฉยต่อคอลัมน์ข้อมูลนั้นและสร้างเอาต์พุตใหม่โดยใช้โมเดลกำเนิดที่กำหนดค่าไว้mlflow ui --port 5000python -m eval.client

