ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
อินโทร Youtube • แชท Discord • เอกสารฉบับเต็ม
การติดตั้ง UStore เป็นเรื่องง่าย และการใช้งานก็ง่ายดายเหมือนกับ Python dict
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' เราเพิ่งสร้างฐานข้อมูลธุรกรรมที่ฝังอยู่ในหน่วยความจำและเพิ่มหนึ่งรายการในคอลเลกชัน main คุณต้องการให้ข้อมูลนั้นอยู่บนดิสก์หรือไม่? เปลี่ยนหนึ่งบรรทัด
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )คุณต้องการเชื่อมต่อกับเซิร์ฟเวอร์ UStore ระยะไกลหรือไม่? UStore มาพร้อมกับอินเทอร์เฟซ Apache Arrow Flight RPC!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) คุณกำลังจัดเก็บ MultiDiGraph ที่เหมือน NetworkX หรือไม่ หรือ DataFrame ที่เหมือน Pandas ?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1การเรียกใช้ฟังก์ชันอาจดูเหมือนกัน แต่การใช้งานพื้นฐานสามารถจัดการกับข้อมูลหลายร้อยเทราไบต์ที่วางอยู่ที่ไหนสักแห่งในหน่วยความจำถาวรบนเครื่องระยะไกล
มีคนอื่นอัพเดตคอลเลกชันเหล่านั้นพร้อมกันหรือไม่? รวมการดำเนินงานของคุณเพื่อรับประกันความสม่ำเสมอ!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )จนถึงตอนนี้เราได้กล่าวถึงเฉพาะส่วนปลายของ UStore เท่านั้น คุณสามารถใช้มันเพื่อ...
แต่ UStore สามารถทำได้มากกว่านั้น นี่คือแผนที่:
## การใช้งานขั้นพื้นฐาน
UStore ไม่ได้มีวัตถุประสงค์เพียงเพื่อเป็นฐานข้อมูล แต่เป็นชุดเครื่องมือ "สร้างฐานข้อมูลของคุณ" และเป็นมาตรฐานแบบเปิดสำหรับฐานข้อมูลที่อาจเป็นไปได้ของการทำธุรกรรม NoSQL โดยกำหนดอินเทอร์เฟซไบนารี่ที่ไม่มีการคัดลอกสำหรับการดำเนินการ "สร้าง อ่าน อัปเดต ลบ" หรือเรียกย่อว่า CRUD
ส่วนหัว C99 ง่ายๆ เพียงไม่กี่ตัวสามารถเชื่อมโยงกลไกการจัดเก็บข้อมูลพื้นฐานเกือบทั้งหมดเข้ากับไดรเวอร์ภาษาระดับสูงจำนวนมาก ขยายการรองรับค่าสตริงไบนารีไปยังกราฟ เอกสารสคีมาแบบยืดหยุ่น และรูปแบบอื่น ๆ โดยมีเป้าหมายเพื่อแทนที่ MongoDB, Neo4J, Pinecone และ ElasticSearch ด้วยระบบธุรกรรมกรดเดียว
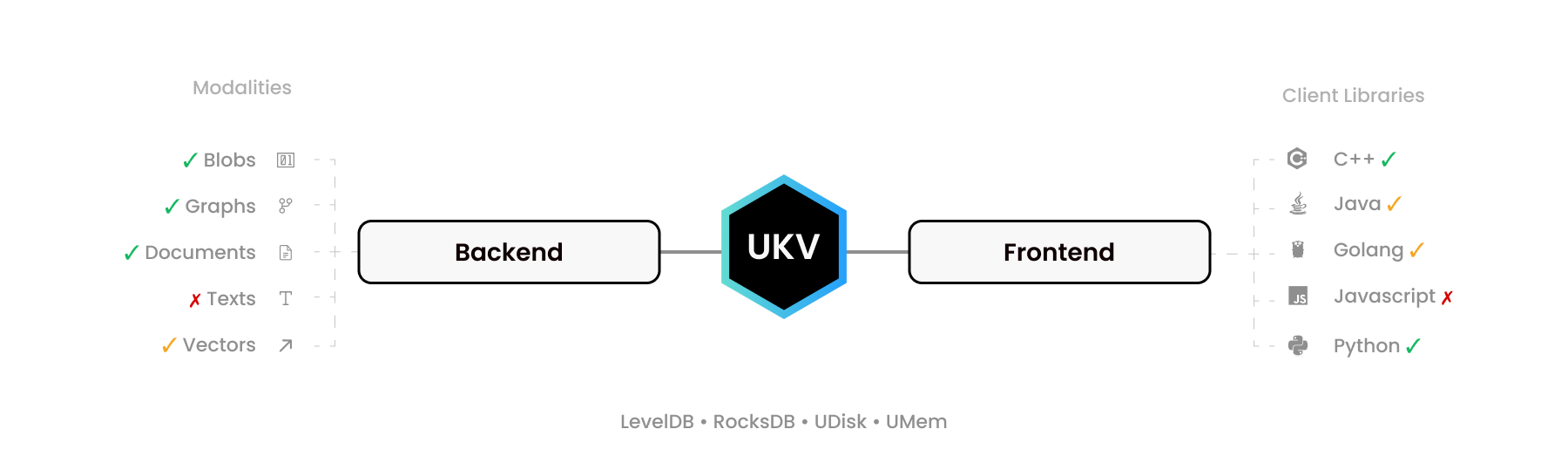
ตัวอย่างเช่น Redis จัดให้มี RediSearch, RedisJSON และ RedisGraph โดยมีวัตถุประสงค์ที่คล้ายกัน UStore ทำได้ดีกว่า ช่วยให้คุณสามารถเพิ่ม Key-Value Stores (KVS) ที่คุณชื่นชอบ แบบฝัง แบบสแตนด์อโลน หรือแบบแบ่งส่วน เช่น FoundationDB เพื่อเพิ่มฟังก์ชันการทำงานได้ทวีคูณ
Binary Large Objects สามารถวางใน UStore ได้ ประสิทธิภาพจะแตกต่างกันอย่างมากขึ้นอยู่กับเทคโนโลยีพื้นฐานที่ใช้ UCSet ในหน่วยความจำจะเร็วที่สุด แต่เหมาะสมน้อยที่สุดสำหรับวัตถุขนาดใหญ่ เมื่อกำหนดค่า UDisk แบบถาวรแล้ว จะสามารถข้ามเคอร์เนล Linux ได้ทั้งหมด รวมถึงเลเยอร์ระบบไฟล์ เพื่อจัดการกับอุปกรณ์บล็อกโดยตรง
IO แบบถาวรสมัยใหม่บนเซิร์ฟเวอร์ระดับไฮเอนด์สามารถเกิน 100 GB/s ต่อซ็อกเก็ต เมื่อสร้างบนไดรเวอร์พื้นที่ผู้ใช้ เช่น SPDK ซึ่งใกล้เคียงกับปริมาณการประมวลผลในโลกแห่งความเป็นจริงของ RAM ระดับไฮเอนด์ และเป็นการปลดล็อกกรณีการใช้งานฐานข้อมูลใหม่ๆ ที่ไม่ธรรมดา ตอนนี้เราอาจวางไฟล์วิดีโอขนาดกิกะไบต์ไว้ในฐานข้อมูลธุรกรรม ACID ถัดจากข้อมูลเมตา แทนที่จะใช้ที่เก็บอ็อบเจ็กต์แยกต่างหาก เช่น MiniIO
JSON เป็นรูปแบบเอกสารที่ใช้กันมากที่สุดในปัจจุบัน คอลเลกชันเอกสาร UStore รองรับ JSON เช่นเดียวกับ MessagePack และ BSON ที่ MongoDB ใช้

UStore ยังไม่ปรับขนาดในแนวนอน แต่ให้ประสิทธิภาพโหนดเดียวที่สูงกว่ามาก และมีความสามารถในการปรับขนาดแนวตั้งเกือบเชิงเส้นบนระบบหลายคอร์ด้วยไลบรารีโอเพ่นซอร์ส simdjson และ yyjson นอกจากนี้ ในการโต้ตอบกับข้อมูล คุณไม่จำเป็นต้องมีภาษาการสืบค้นแบบกำหนดเอง เช่น MQL แต่เราจัดลำดับความสำคัญของมาตรฐาน RFC แบบเปิดเพื่อหลีกเลี่ยงการล็อคของผู้จำหน่ายอย่างแท้จริง:
ฐานข้อมูล Modern Graph เช่น Neo4J ประสบปัญหากับปริมาณงานขนาดใหญ่ พวกเขาต้องการ RAM มากเกินไป และอัลกอริทึมจะสังเกตข้อมูลทีละรายการ เราปรับให้เหมาะสมทั้งสองด้าน:
Feature Stores และ Vector Databases เช่น Pinecone, Milvus และ USearch มีดัชนีแบบสแตนด์อโลนสำหรับการค้นหาเวกเตอร์ UStore นำไปใช้เป็นรูปแบบที่แยกจากกัน เทียบเท่ากับเอกสารและกราฟ คุณสมบัติ:
UStore สำหรับ Python และสำหรับ C++ ดูแตกต่างออกไปมาก Python SDK ของเราเลียนแบบไลบรารี Python อื่นๆ - Pandas และ NetworkX ในทำนองเดียวกัน ไลบรารี C++ จัดเตรียมอินเทอร์เฟซที่นักพัฒนา C++ คาดหวังไว้
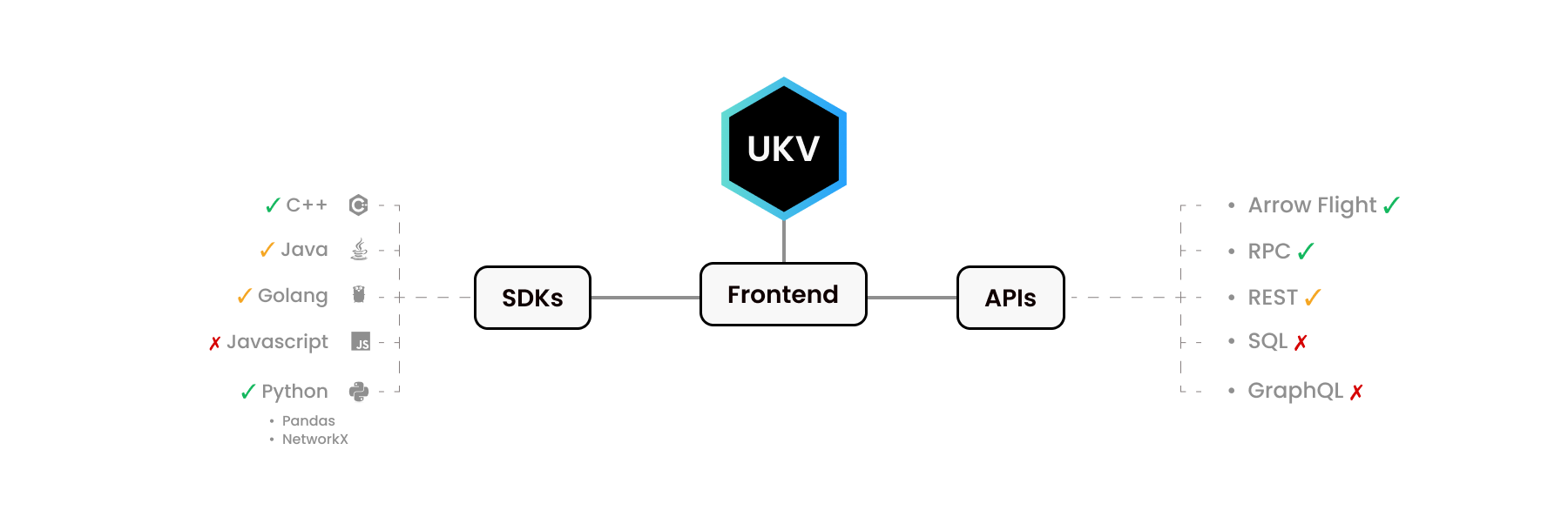
ดังที่เราทราบ ผู้คนใช้ภาษาที่แตกต่างกันเพื่อวัตถุประสงค์ที่แตกต่างกัน ฟังก์ชันระดับ C บางอย่างไม่ได้ถูกนำมาใช้กับบางภาษา อาจเป็นเพราะยังไม่มีความต้องการหรือเนื่องจากเรายังไปไม่ถึง
| ชื่อ | การทำธุรกรรม | คอลเลกชัน | แบตช์ | เอกสาร | กราฟ | สำเนา |
|---|---|---|---|---|---|---|
| มาตรฐาน C99 | 0 | |||||
| C++ SDK | 0 | |||||
| หลาม SDK | 0-1 | |||||
| GoLang SDK | 1 | |||||
| จาวา SDK | 1 | |||||
| API การบินของแอร์โรว์ | 0-2 |
ส่วนหน้าบางส่วนที่นี่มีระบบนิเวศทั้งหมดรอบตัว! ตัวอย่างเช่น Apache Arrow Flight API มีไดรเวอร์ของตัวเองสำหรับ C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby และ Rust
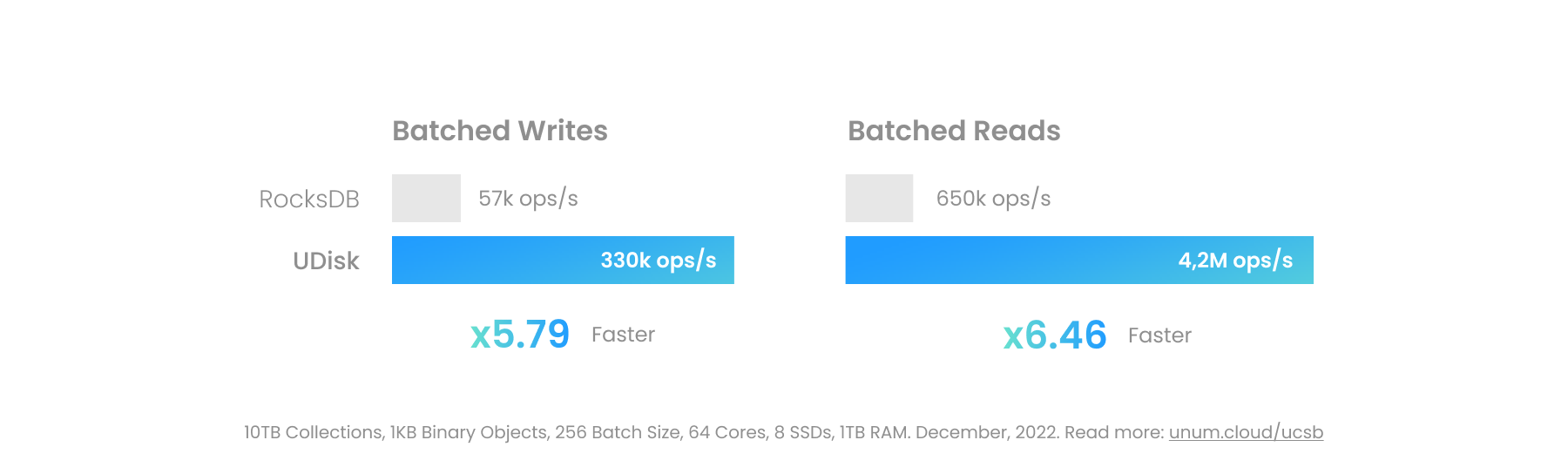
เครื่องยนต์ต่อไปนี้สามารถใช้แทนกันได้เกือบหมด ในอดีต LevelDB เป็นอันแรก จากนั้น RocksDB ก็ปรับปรุงฟังก์ชันการทำงานและประสิทธิภาพ ปัจจุบันทำหน้าที่เป็นรากฐานสำหรับครึ่งหนึ่งของสตาร์ทอัพ DBMS
| ระดับDB | RocksDB | ยูดิสก์ | UCSet | |
|---|---|---|---|---|
| ความเร็ว | 1x | 2x | 10x | 30x |
| ดื้อดึง | ||||
| การทำธุรกรรม | ||||
| การสนับสนุนอุปกรณ์บล็อก | ||||
| การเข้ารหัส | ||||
| นาฬิกา | ||||
| สแนปชอต | ||||
| การสุ่มตัวอย่าง | ||||
| การแจงนับจำนวนมาก | ||||
| คอลเลกชันที่มีชื่อ | ||||
| โอเพ่นซอร์ส | ||||
| ความเข้ากันได้ | ใดๆ | ใดๆ | ลินุกซ์ | ใดๆ |
| ผู้ดูแล | เฟสบุ๊ค | อูนัม | อูนัม |
UCSet และ UDisk ได้รับการออกแบบและดูแลโดย Unum ทั้งสองมีคุณสมบัติครบถ้วน แต่คุณสมบัติที่สำคัญที่สุดที่ทางเลือกอื่นของเรามอบให้คือประสิทธิภาพ การจำได้อย่างรวดเร็วเป็นเรื่องง่าย ตรรกะหลักของ UCSet สามารถพบได้ในไลบรารี ucset ส่วนหัวที่มีเทมเพลตเท่านั้น
การออกแบบ UDisk ถือเป็นความพยายามที่ยาวนานถึง 7 ปีที่ท้าทายยิ่งกว่ามาก ซึ่งรวมถึงการประดิษฐ์โครงสร้างที่เหมือนต้นไม้ใหม่ การใช้เคอร์เนลบายพาสบางส่วนด้วย io_uring การบายพาสที่สมบูรณ์ด้วย SPDK การเร่งความเร็ว CUDA GPU และแม้แต่ระบบไฟล์ภายในที่กำหนดเอง UDisk เป็นเอ็นจิ้นแรกที่ได้รับการออกแบบตั้งแต่เริ่มต้นโดยคำนึงถึงสถาปัตยกรรมแบบขนานและเคอร์เนลบายพาส
รับประกันความเป็นอะตอมมิกเสมอ แม้แต่ในการเขียนที่ไม่ใช่ธุรกรรม - การอัปเดตทั้งหมดจะผ่านหรือล้มเหลวทั้งหมด
ความสม่ำเสมอถูกนำมาใช้ในรูปแบบที่เข้มงวดที่สุดเท่าที่จะเป็นไปได้ - "Strict Serializability" หมายความว่า:
อย่างไรก็ตาม พฤติกรรมเริ่มต้นสามารถปรับแต่งได้ในระดับการดำเนินการเฉพาะ เพื่อที่ ::ustore_option_transaction_dont_watch_k สามารถส่งผ่านไปยัง ustore_transaction_init() หรือการดำเนินการอ่าน/เขียนธุรกรรมใด ๆ เพื่อควบคุมการตรวจสอบความสอดคล้องระหว่างการแสดงละคร
| อ่าน | เขียน | |
|---|---|---|
| ศีรษะ | อนุกรมที่เข้มงวด | อนุกรมที่เข้มงวด |
| ธุรกรรมผ่านสแนปชอต | อนุกรม | อนุกรมที่เข้มงวด |
| ธุรกรรมที่ไม่มี Snapshots | อนุกรมที่เข้มงวด | อนุกรมที่เข้มงวด |
| การทำธุรกรรมโดยไม่ต้องมีนาฬิกา | อนุกรมที่เข้มงวด | ตามลำดับ |
หากหัวข้อนี้เป็นหัวข้อใหม่สำหรับคุณ โปรดตรวจสอบบล็อกของ Jepsen.io เกี่ยวกับความสม่ำเสมอ
| อ่าน | เขียน | |
|---|---|---|
| ธุรกรรมผ่านสแนปชอต | ||
| ธุรกรรมที่ไม่มี Snapshots |
ความทนทานใช้ไม่ได้กับระบบในหน่วยความจำตามคำจำกัดความ ในระบบไฮบริดหรือระบบถาวร เราต้องการปิดการใช้งานตามค่าเริ่มต้น เกือบทุก DBMS ที่สร้างขึ้นบน KVS ชอบที่จะใช้กลไกความทนทานของตัวเอง ยิ่งไปกว่านั้นในฐานข้อมูลแบบกระจาย ซึ่งอาจมีบันทึกการเขียนล่วงหน้าสามรายการแยกกัน:
หากคุณยังต้องการความทนทาน ให้ล้างการเขียนเมื่อคอมมิตด้วยแฟล็กเสริม ในไดรเวอร์ C คุณจะเรียก ustore_transaction_commit() ด้วยแฟล็ก ::ustore_option_write_flush_k
DBMS ทั้งหมดมีขนาดพอดีกับอิมเมจ Docker ขนาดย่อย 100 MB รันสคริปต์ต่อไปนี้เพื่อดึงและรันคอนเทนเนอร์ โดยเปิดเผยเซิร์ฟเวอร์ Apache Arrow Flight บนพอร์ต 38709 SDK ของไคลเอ็นต์จะสื่อสารผ่านพอร์ตเดียวกันนั้นตามค่าเริ่มต้น
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreไฟล์การกำหนดค่าเริ่มต้นสามารถเรียกค้นได้ด้วย:
cat /var/lib/ustore/config.jsonวิธีที่ง่ายที่สุดในการเชื่อมต่อและทดสอบคือคำสั่งต่อไปนี้:
python ...อิมเมจ UStore แบบแพ็กเกจล่วงหน้ามีจำหน่ายบนหลายแพลตฟอร์ม:
อย่าลังเลที่จะทำการค้าและจัดจำหน่าย UStore อีกครั้ง
การปรับแต่งฐานข้อมูลถือเป็นศิลปะพอๆ กับวิทยาศาสตร์ โปรเจ็กต์อย่าง RocksDB มีปุ่มมากมายเพื่อปรับพฤติกรรมให้เหมาะสม เราอนุญาตให้ส่งต่อไฟล์การกำหนดค่าพิเศษไปยังกลไกพื้นฐาน
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}นอกจากนี้เรายังมีขั้นตอนที่ง่ายกว่า ซึ่งเพียงพอสำหรับผู้ใช้ 80% ที่สามารถขยายเพื่อใช้อุปกรณ์หรือไดเร็กทอรีหลายรายการ หรือเพื่อส่งต่อการกำหนดค่ากลไกพิเศษ
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}คอลเลกชันฐานข้อมูลสามารถกำหนดค่าด้วยไฟล์ JSON ได้เช่นกัน
ในเวอร์ชันปัจจุบัน มีการใช้จำนวนเต็มที่ลงนามแบบ 64 บิต อนุญาตให้ใช้คีย์เฉพาะในช่วงตั้งแต่ [0, 2^63) รุ่น 128 บิตที่มี UUID กำลังจะมา แต่คีย์ที่มีความยาวผันแปรได้ไม่แนะนำอย่างยิ่ง ทำไมเป็นเช่นนั้น?
การใช้คีย์ที่มีความยาวผันแปรได้ทำให้มีข้อจำกัดมากมายในการออกแบบที่เก็บคีย์-ค่า ประการแรก มันแสดงถึงการเปรียบเทียบตัวละครที่ช้า — นักฆ่าประสิทธิภาพบน CPU ไฮเปอร์สเกลาร์สมัยใหม่ ประการที่สอง จะบังคับให้คีย์และค่าถูกรวมเข้าด้วยกันบนดิสก์เพื่อลดเมตาดาต้าที่จำเป็นสำหรับการนำทางให้เหลือน้อยที่สุด สุดท้ายนี้ มันละเมิดมุมมองเชิงตรรกะที่เรียบง่ายของเราเกี่ยวกับ KVS ในฐานะ "ตัวจัดสรรหน่วยความจำถาวร" ซึ่งทำให้มีความรับผิดชอบมากขึ้น
แนวทางที่แนะนำในการจัดการกับคีย์สตริงคือ:
ซึ่งจะส่งผลให้เกิดจุดแปลงเดียวจากสตริงเป็นการแสดงจำนวนเต็ม และจะทำให้ระบบส่วนใหญ่รวดเร็วและอินเทอร์เฟซระดับ C เรียบง่ายกว่าที่เคยเป็น
ในปัจจุบันเราสามารถระบุค่าได้เพียง 4 GB หรือน้อยกว่าเท่านั้น ทำไม โดยทั่วไปแล้ว ร้านค้าคีย์-ค่ามีไว้สำหรับการดำเนินการความถี่สูง บ่อยครั้ง (หลายพันครั้งในแต่ละวินาที) การเข้าถึงและแก้ไขไฟล์ขนาด 4 GB และไฟล์ขนาดใหญ่นั้นเป็นไปไม่ได้บนฮาร์ดแวร์สมัยใหม่ ดังนั้นเราจึงยึดติดกับประเภทที่มีความยาวน้อยกว่า ทำให้การใช้การแสดง Apache Arrow ง่ายขึ้นเล็กน้อย และช่วยให้ KVS บีบอัดดัชนีได้ดีขึ้น
แผนงานการพัฒนาของเราเป็นแบบสาธารณะและโฮสต์ภายในพื้นที่เก็บข้อมูล GitHub งานที่จะเกิดขึ้น ได้แก่:
อ่านแผนงานฉบับเต็มในเอกสารของเราที่นี่


