
ผู้ประเมินการจัดอันดับจัดอันดับ
Rated Ranking Evaluator (RRE) เป็นเครื่องมือประเมินคุณภาพการค้นหา ซึ่งจะประเมินคุณภาพของผลลัพธ์ที่มาจากโครงสร้างพื้นฐานการค้นหา ตามชื่อเลย
ลิงค์
- การประเมินคุณภาพการค้นหา: มุมมองของนักพัฒนา
- RRE ที่ Haystack EU, ลอนดอน, 2018
- RRE ที่ Fosdem 2019
- Rated Ranking Evaluator (RRE) การทดสอบความเกี่ยวข้องเชิงปฏิบัติ @Chorus, 2021
- Rated Ranking Evaluator Enterprise: เครื่องมือประเมินคุณภาพการค้นหาฟรีรุ่นใหม่ ปาโดวา ปี 2021
- โครงการ Wiki อยู่ที่ https://github.com/SeaseLtd/rated-ranking-evaluator/wiki
- รายชื่อผู้รับจดหมาย RRE-User: https://groups.google.com/g/rre-user
ในขณะนี้ รองรับ Apache Solr และ Elasticsearch (ดูเอกสารประกอบสำหรับเวอร์ชันที่รองรับ)
รูปภาพต่อไปนี้แสดงให้เห็นถึงระบบนิเวศ RRE:
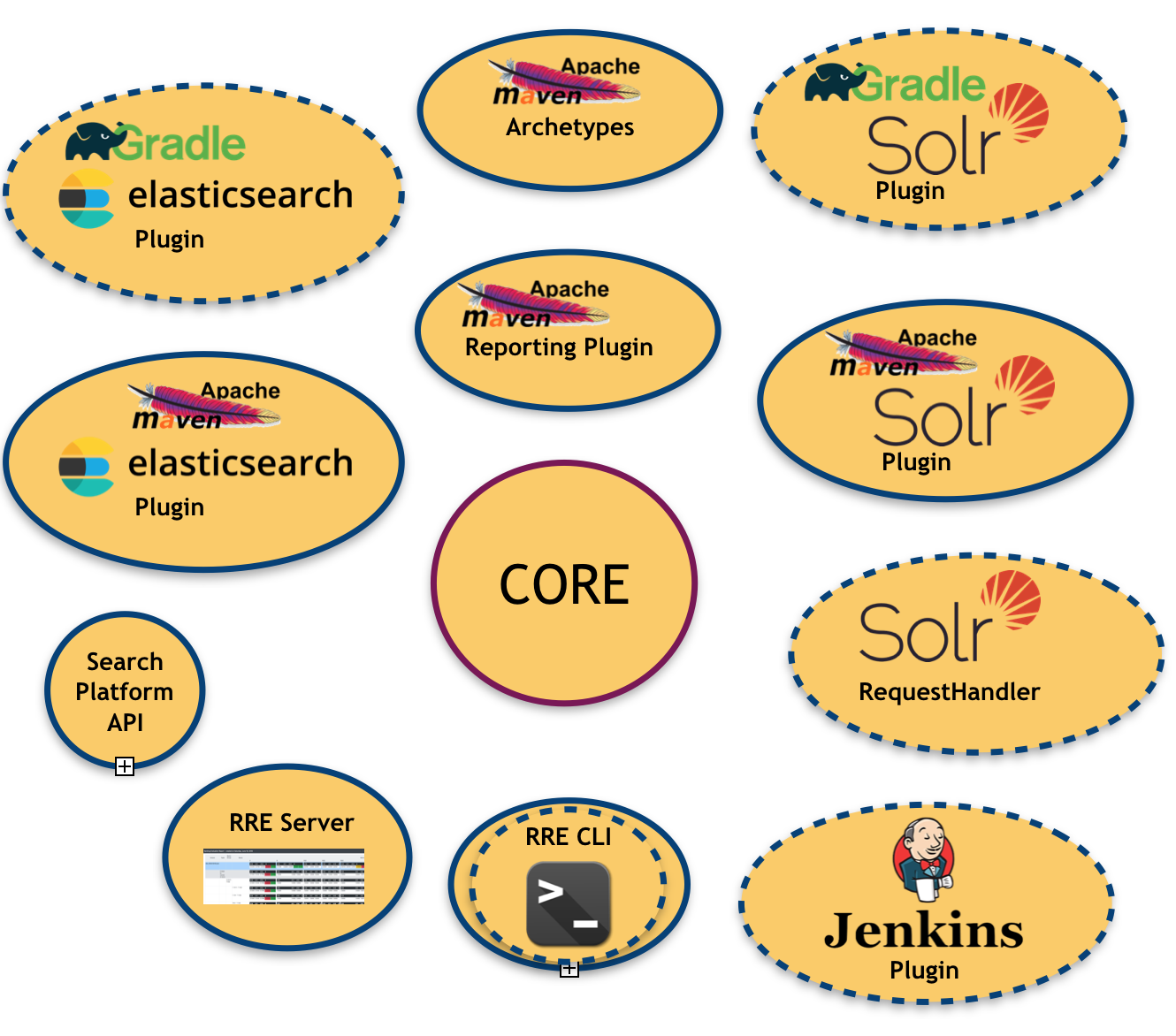
อย่างที่คุณเห็น มีโมดูลจำนวนมากอยู่แล้วและวางแผนไว้แล้ว (โมดูลที่มีเส้นขอบประ)
- แกนกลาง คือ ห้องสมุดกลางที่มีหน้าที่จัดทำผลการประเมิน
- API แพลตฟอร์มการค้นหา : สำหรับการสรุป (และการเชื่อมโยง) แพลตฟอร์มการค้นหาพื้นฐาน
- ชุด การเชื่อมโยงแพลตฟอร์มการค้นหา : ตามที่กล่าวไว้ข้างต้น ในขณะนี้ เรามีการเชื่อมโยงที่มีอยู่สองรายการ (Apache Solr และ Elasticsearch)
- ปลั๊กอิน Apache Maven สำหรับแต่ละแพลตฟอร์มการค้นหาที่มีอยู่: ซึ่งอนุญาตให้ฉีด RRE ลงในระบบบิลด์ที่ใช้ Maven
- ปลั๊กอินการรายงาน Apache Maven : สำหรับสร้างรายงานการประเมินในรูปแบบที่มนุษย์สามารถอ่านได้ (เช่น PDF, Excel) ซึ่งมีประโยชน์สำหรับการกำหนดเป้าหมายผู้ใช้ที่ไม่ใช่ด้านเทคนิค
- เซิร์ฟเวอร์ RRE : แผงควบคุมบนเว็บที่เรียบง่าย ซึ่งผลการประเมินจะได้รับการอัปเดตแบบเรียลไทม์หลังจากแต่ละรอบการสร้าง
ระบบทั้งหมดได้รับการสร้างขึ้นเป็นเฟรมเวิร์กที่สามารถกำหนดค่า/เปิดใช้งานตัววัดและแม้แต่เสียบปลั๊กได้ (แน่นอนว่าตัวเลือกนี้ต้องมีการพัฒนาบางอย่าง) ตัววัดที่เป็นส่วนหนึ่งของ RRE รุ่นปัจจุบันคือ:
- ความแม่นยำ : เศษส่วนของเอกสารที่ดึงมาซึ่งมีความเกี่ยวข้อง
- Recall : ส่วนของเอกสารที่เกี่ยวข้องที่ถูกดึงมา
- ความแม่นยำที่ 1 : ตัวชี้วัดนี้ระบุว่าผลลัพธ์อันดับแรกในรายการเกี่ยวข้องหรือไม่
- ความแม่นยำที่ 2 : เหมือนข้างบนแต่พิจารณาสองผลลัพธ์แรก
- ความแม่นยำที่ 3 : เหมือนข้างบนแต่พิจารณาผลลัพธ์สามตัวแรก
- ความแม่นยำที่ 10 : ตัวชี้วัดนี้วัดจำนวนผลลัพธ์ที่เกี่ยวข้องในผลการค้นหา 10 อันดับแรก
- อันดับซึ่งกันและกัน : เป็นการผกผันการคูณของอันดับของคำตอบที่ "ถูกต้อง" ตัวแรก: 1 สำหรับอันดับที่ 1, 1/2 สำหรับอันดับที่สอง, 1/3 สำหรับอันดับที่สาม และต่อๆ ไป
- อันดับซึ่งกันและกันที่คาดหวัง (ERR) ส่วนขยายของอันดับซึ่งกันและกันที่มีความเกี่ยวข้องแบบให้คะแนน จะวัดระยะเวลาที่ผู้ใช้จะใช้เพื่อค้นหาเอกสารที่เกี่ยวข้อง
- ความแม่นยำเฉลี่ย : พื้นที่ใต้เส้นโค้งการเรียกคืนความแม่นยำ
- NDCG ที่ 10 : กำไรสะสมลดราคาปกติที่ 10; ดู: https://en.wikipedia.org/w/index.php?title=Discounted_cumulative_gain§ion=4#Normalized_DCG
- F-Measure : วัดประสิทธิผลของการดึงข้อมูลโดยคำนึงถึงผู้ใช้ที่ให้ความสำคัญกับการเรียกคืนมากกว่าความแม่นยำถึง β เท่า RRE มีอินสแตนซ์ F-Measure ที่ได้รับความนิยมสูงสุดสามอินสแตนซ์: F0.5, F1 และ F2
นอกเหนือจากตัววัด "ใบไม้" เหล่านั้นซึ่งคำนวณในระดับการสืบค้นแล้ว RRE ยังมีโมเดลข้อมูลที่ซ้อนกันแบบสมบูรณ์ ซึ่งสามารถรวมตัววัดเดียวกันได้หลายระดับ ตัวอย่างเช่น การสืบค้นจะถูกจัดกลุ่มในกลุ่มการสืบค้น และกลุ่มการสืบค้นจะถูกจัดกลุ่มในหัวข้อ นั่นหมายความว่าหน่วยวัดเดียวกันที่แสดงไว้ด้านบนยังมีให้ใช้งานในระดับบนโดยใช้ค่าเฉลี่ยเลขคณิตเป็นเกณฑ์การรวม ด้วยเหตุนี้ RRE จึงจัดให้มีหน่วยวัดต่อไปนี้ด้วย:
- Mean Average Precision : ค่าเฉลี่ยของความแม่นยำเฉลี่ยที่คำนวณในระดับแบบสอบถาม
- Mean Reciprocal Rank : ค่าเฉลี่ยของอันดับ Reciprocal ที่คำนวณในระดับแบบสอบถาม
- หน่วยวัดอื่นๆ ทั้งหมดที่แสดงไว้ข้างต้น รวมกันตามค่าเฉลี่ยเลขคณิต
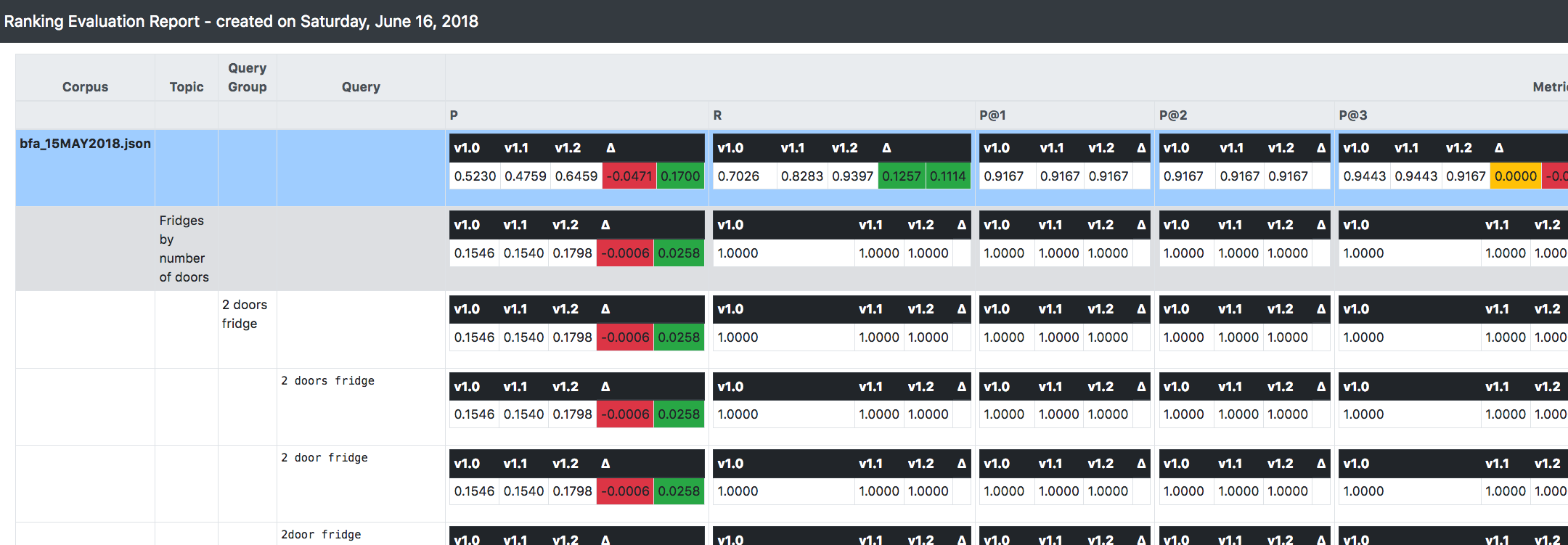
สิ่งที่สำคัญที่สุดอย่างหนึ่งที่คุณเห็นในภาพหน้าจอด้านบนคือ RRE สามารถติดตาม (และทำการเปรียบเทียบ) ระหว่างระบบหลายเวอร์ชันที่อยู่ระหว่างการประเมินได้
สนับสนุนแนวทางที่เพิ่มขึ้น/วนซ้ำ/ไม่เปลี่ยนรูปเมื่อพัฒนาและพัฒนาระบบการค้นหา: สมมติว่าคุณเริ่มต้นจากเวอร์ชัน 1.0 เมื่อคุณใช้การเปลี่ยนแปลงที่เกี่ยวข้องบางอย่างกับการกำหนดค่าของคุณ แทนที่จะเปลี่ยนเวอร์ชันนั้น เป็นการดีกว่าที่จะโคลนมันและใช้ เปลี่ยนเป็นเวอร์ชันใหม่ (เรียกว่า 1.1)
ด้วยวิธีนี้ เมื่อสร้างระบบ RRE จะคำนวณทุกอย่างที่อธิบายไว้ข้างต้น (เช่น ตัวชี้วัด) สำหรับแต่ละเวอร์ชันที่มีอยู่
นอกจากนี้ ยังให้ข้อมูลเดลต้า/แนวโน้มระหว่างเวอร์ชันต่อๆ ไป เพื่อให้คุณทราบทิศทางโดยรวมที่ระบบดำเนินไปในทันทีในแง่ของการปรับปรุงความเกี่ยวข้อง



