sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
ผู้ดูแล: jcudit และ lsgos
โครงการคงอยู่จนถึงอย่างน้อย (ปปปป-ดด-วว): 2023-03-14
นี่คือตัวอย่างวิธีใช้ Cohere API เพื่อสร้างเครื่องมือค้นหาเชิงความหมายอย่างง่าย ไม่ได้หมายถึงให้พร้อมสำหรับการผลิตหรือปรับขนาดได้อย่างมีประสิทธิภาพ (แม้ว่าจะสามารถปรับให้เข้ากับจุดสิ้นสุดเหล่านี้ได้) แต่ทำหน้าที่เพื่อแสดงความง่ายในการผลิตเครื่องมือค้นหาที่ขับเคลื่อนโดยการนำเสนอที่ผลิตโดย Cohere's Large Language Models (LLM)
อัลกอริธึมการค้นหาที่ใช้ในที่นี้ค่อนข้างง่าย: เพียงค้นหาย่อหน้าที่ตรงกับการเป็นตัวแทนของคำถามมากที่สุด โดยใช้จุดสิ้นสุด co.embed โดยมีการอธิบายโดยละเอียดเพิ่มเติมด้านล่าง แต่นี่คือแผนภาพง่ายๆ ของสิ่งที่เกิดขึ้น อันดับแรก เราจะแบ่งข้อความที่ป้อนออกเป็นชุดของย่อหน้า โดยจัดเก็บที่อยู่ในอินพุตเป็นรายการ และสร้างเวกเตอร์ที่ฝังไว้สำหรับแต่ละย่อหน้าโดยใช้ co.embed :
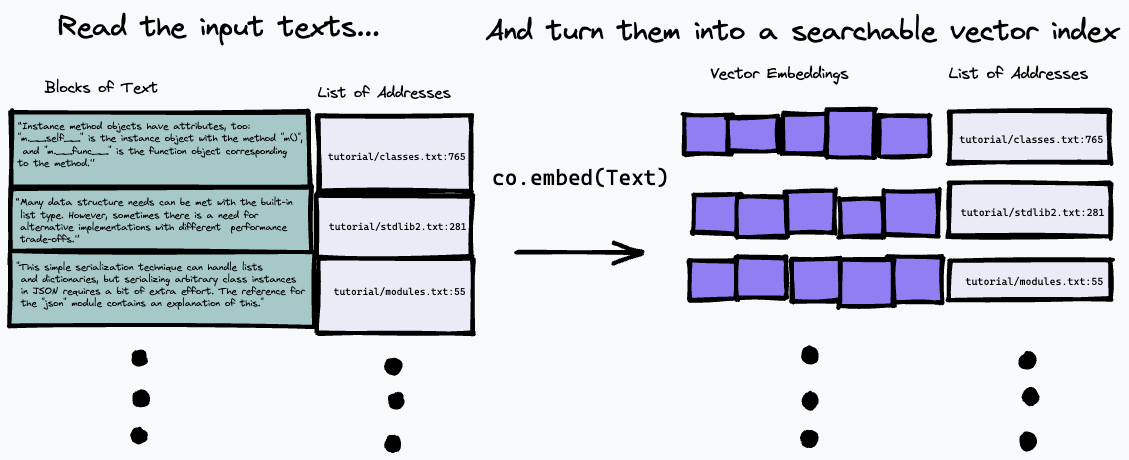
จากนั้น เราสามารถสืบค้นดัชนีของเราได้โดยการฝังข้อความค้นหา และค้นหาย่อหน้าในข้อความต้นฉบับที่ใกล้เคียงที่สุดโดยใช้การวัดความคล้ายคลึงกันของเวกเตอร์ (เราใช้ความคล้ายคลึงโคไซน์): 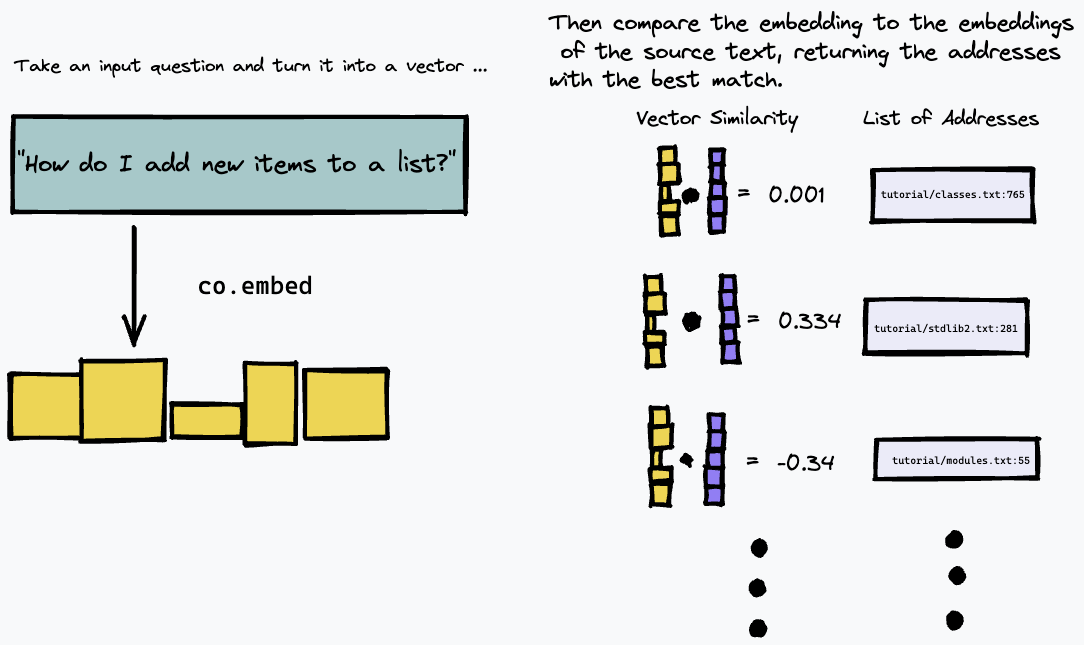
ด้วยเหตุนี้ จึงทำงานได้ดีที่สุดกับแหล่งข้อความที่คำตอบสำหรับคำถามที่ให้มามีแนวโน้มที่จะได้รับจากย่อหน้าที่เป็นรูปธรรมในข้อความ เช่น เอกสารทางเทคนิคหรือวิกิภายในซึ่งมีโครงสร้างเป็นรายการคำสั่งหรือข้อเท็จจริงที่เป็นรูปธรรม วิธีนี้ทำงานได้ไม่ดีนัก เช่น การตอบคำถามเกี่ยวกับข้อความรูปแบบอิสระ เช่น นวนิยาย ซึ่งข้อมูลอาจกระจายไปหลายย่อหน้า คุณจะต้องใช้วิธีอื่นในการจัดทำดัชนีข้อความสำหรับสิ่งนี้
ตามตัวอย่าง พื้นที่เก็บข้อมูลนี้สร้างเครื่องมือค้นหาเชิงความหมายอย่างง่ายเหนือเวอร์ชันข้อความของเอกสาร Python ล่าสุด
หากต้องการติดตั้งข้อกำหนดของ Python ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งและรันบทกวีแล้ว:
# install python deps
poetry installคุณควรติดตั้งนักเทียบท่าด้วย บน OS X หากคุณใช้โฮมบรูว์ เราขอแนะนำให้รัน
brew install --cask dockerก่อนที่จะเรียกใช้ Docker (เช่น เพื่อเรียกใช้เซิร์ฟเวอร์ของเรา) เป็นครั้งแรกบน OS X ให้เปิดแอป Docker และให้สิทธิ์ที่จำเป็นในการทำงานบนระบบของคุณ
คุณจะต้องมีคีย์ Cohere API ใน COHERE_TOKEN รับบัญชีจากแพลตฟอร์ม Cohere (สร้างบัญชีหากจำเป็น) และเขียนลงในสภาพแวดล้อมของคุณ
export COHERE_TOKEN= < MY_API_KEY > (โดยที่ <MY_API_KEY> คือคีย์ที่คุณได้รับ โดยไม่มีวงเล็บ <...> )
หรือคุณสามารถส่ง COHERE_TOKEN=<MY_API_KEY> เป็นอาร์กิวเมนต์เพิ่มเติมไปยังคำสั่ง make ใดๆ ด้านล่างได้
ทำตามขั้นตอนเหล่านี้เพื่อสร้างดัชนีความหมายของคอลเลกชันเอกสารของคุณก่อน ขั้นตอนเหล่านี้สร้างดัชนีความหมายสำหรับเอกสาร Python อย่างเป็นทางการ แต่สามารถปรับให้เข้ากับการรวบรวมข้อมูลตามอำเภอใจได้
ขั้นแรก ดาวน์โหลดเอกสาร Python โดยรันคำสั่งใดคำสั่งหนึ่งต่อไปนี้
หากคุณต้องการเริ่มต้นอย่างรวดเร็วให้วิ่ง
make download-python-docs-smallเพื่อจำกัดเอกสารที่ตั้งค่าไว้สำหรับบทช่วยสอน Python เราแนะนำให้ทำเช่นนี้สำหรับการทดสอบอย่างรวดเร็วเท่านั้น เนื่องจากผลลัพธ์จะมีจำกัดมาก
หากคุณต้องการทดสอบเครื่องมือค้นหาในเอกสาร Python ทั้งหมด ให้รัน
make download-python-docsแต่โปรดทราบว่าการผลิตการฝังจะใช้เวลา หลายชั่วโมง (แม้ว่าจะต้องทำเพียงครั้งเดียวก็ตาม)
หรือหากคุณต้องการทดลองใช้ข้อความของคุณเอง เพียงดาวน์โหลดเป็นไฟล์ .txt ไปยังไดเร็กทอรีชื่อ txt/ ในที่เก็บนี้
เมื่อคุณมีข้อความแล้ว เราจำเป็นต้องประมวลผลเป็นดัชนีการค้นหาของการฝังและที่อยู่
ซึ่งสามารถทำได้โดยใช้คำสั่ง
make embeddings สมมติว่าข้อความเป้าหมายของคุณอยู่ภายใต้ไดเร็กทอรี ./txt/ /
คำสั่งจะค้นหาไดเร็กทอรี ./txt/ แบบวนซ้ำเพื่อค้นหาไฟล์ที่มีนามสกุล .txt และสร้างฐานข้อมูลอย่างง่ายของการฝัง ชื่อไฟล์ และหมายเลขบรรทัดของแต่ละย่อหน้า
คำเตือน: หากคุณมีข้อความที่ต้องค้นหาเป็นจำนวนมาก อาจใช้เวลาสักครู่จึงจะเสร็จสิ้น!
เมื่อคุณสร้างไฟล์ embeddings.npz แล้ว คุณสามารถใช้คำสั่งต่อไปนี้เพื่อสร้างอิมเมจนักเทียบท่าซึ่งจะให้บริการแอป REST ง่ายๆ เพื่อให้คุณสามารถสืบค้นฐานข้อมูลที่คุณสร้างขึ้น:
make buildจากนั้นคุณสามารถเริ่มเซิร์ฟเวอร์โดยใช้
make runนี่เป็นตัวอย่างที่ต้องใช้ความพยายามมากเกินไปเล็กน้อยสำหรับตัวอย่างง่ายๆ แต่ได้รับการออกแบบมาเพื่อสะท้อนถึงความจริงที่ว่าการสร้างดัชนีของข้อความขนาดใหญ่นั้นค่อนข้างช้า และทำให้แน่ใจว่าการสืบค้นกลไกนั้นรวดเร็ว
หากคุณต้องการใช้โปรเจ็กต์นี้เป็นแบบเอกสารสำเร็จรูปสำหรับแอปพลิเคชันจริง มีแนวโน้มว่าคุณจะต้องการรักษาฐานข้อมูลของการฝังข้อความในสถาปัตยกรรมเซิร์ฟเวอร์ และสืบค้นด้วยไคลเอนต์แบบน้ำหนักเบา การรวมเซิร์ฟเวอร์เป็นแอปพลิเคชันนักเทียบท่าหมายความว่าเป็นเรื่องง่ายมากที่จะเปลี่ยนสิ่งนี้ให้เป็นแอปพลิเคชัน 'ของจริง' โดยการปรับใช้กับบริการคลาวด์
หากคุณเปิดหน้าต่างเทอร์มินัลใหม่สำหรับตัวเลือกใดๆ ด้านล่าง อย่าลืมเรียกใช้
export COHERE_TOKEN= < MY_API_KEY > ตัวเลือกที่ง่ายที่สุดคือการเรียกใช้สคริปต์ตัวช่วยของเรา:
scripts/ask.sh " My query here "เพื่อสอบถามฐานข้อมูล สคริปต์ใช้อาร์กิวเมนต์ที่สองที่เป็นทางเลือกซึ่งระบุจำนวนผลลัพธ์ที่ต้องการ
สคริปต์จะแสดงอินเทอร์เฟซ vim ที่แก้ไขแล้ว โดยมีคำสั่งต่อไปนี้:
q เพื่อออกบานหน้าต่างด้านบนจะแสดงตำแหน่งในเอกสารที่พบผลลัพธ์
เมื่อเซิร์ฟเวอร์ทำงาน คุณสามารถสืบค้นได้โดยใช้ REST API แบบธรรมดา คุณสามารถสำรวจ API ได้โดยตรงโดยไปที่ /docs#/default/search_search_post ที่นี่ เป็น JSON REST API แบบธรรมดา นี่คือวิธีที่คุณสามารถถามคำถามโดยใช้ curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
สิ่งนี้จะส่งคืนรายการ JSON ที่มีความยาว num_results โดยแต่ละรายการมีชื่อไฟล์และหมายเลขบรรทัด ( doc_url และ block_url ) ของบล็อกที่ตรงกับความหมายที่ใกล้เคียงที่สุดกับข้อความค้นหาของคุณ แต่คุณอาจต้องการอ่านไฟล์เพียงเล็กน้อยซึ่งเป็นคำตอบที่ดีที่สุด
ในขณะที่เรากำลังค้นหาไฟล์ข้อความในเครื่อง จริงๆ แล้วการแยกวิเคราะห์ผลลัพธ์โดยใช้เครื่องมือบรรทัดคำสั่งจะง่ายกว่าเล็กน้อย ใช้สคริปต์ python utils/query_server.py ที่ให้มาเพื่อสืบค้นบนบรรทัดคำสั่ง query_server.py พิมพ์ผลลัพธ์ในรูป file_name:line_number: มาตรฐาน เพื่อให้เราสามารถเลื่อนดูผลลัพธ์จริงด้วยวิธีที่ดีในการใช้ประโยชน์จากโหมด Quickfix ของ vim
สมมติว่าคุณมีเสียงเรียกเข้าในเครื่องของคุณ คุณก็ทำได้ง่ายๆ
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
เพื่อรับ vim เพื่อเปิดไฟล์ข้อความที่จัดทำดัชนีในตำแหน่งที่ส่งคืนโดยอัลกอริธึมการค้นหา (ใช้ :qall เพื่อปิดทั้งหน้าต่างและตัวนำทางแบบรวดเร็ว) คุณสามารถหมุนเวียนผลลัพธ์ที่ส่งคืนได้โดยใช้ :cn และ :cp ผลลัพธ์ที่ได้ไม่สมบูรณ์แบบ เป็นการค้นหาเชิงความหมาย ดังนั้นคุณคงคาดหวังว่าการจับคู่จะคลุมเครือเล็กน้อย อย่างไรก็ตาม ฉันมักจะพบว่าคุณสามารถได้รับคำตอบสำหรับคำถามของคุณในผลการค้นหาสองสามรายการแรก และการใช้ API ของ Cohere ช่วยให้คุณสามารถแสดงคำถามของคุณในภาษาที่เป็นธรรมชาติ และให้คุณสร้างเครื่องมือค้นหาที่มีประสิทธิภาพอย่างน่าประหลาดใจโดยใช้โค้ดเพียงไม่กี่บรรทัด
ข้อความค้นหาที่น่าลองใช้ในกรณีเอกสารหลามที่แสดงว่าการค้นหาทำงานได้ดีกับคำถามทั่วไปที่เป็นภาษาธรรมชาติ ได้แก่:
How do I put new items in a list? (โปรดทราบว่าคำถามนี้หลีกเลี่ยงการใช้คำหลัก 'append' และไม่ตรงกับวิธีการอธิบายเอกสารต่อท้ายทุกประการ (พวกเขาบอกว่าใช้เพื่อ เพิ่ม รายการใหม่ต่อท้ายรายการ) แต่การค้นหาเชิงความหมายระบุอย่างถูกต้องว่า ย่อหน้าที่เกี่ยวข้องยังคงเป็นรายการที่ตรงที่สุด)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (โปรดสังเกตสำหรับคำถามนี้ว่าผลลัพธ์แรกสำหรับฉันคือคำถามที่พบบ่อยเกี่ยวกับหัวข้อนี้โดยพื้นฐานแล้ว แต่มีคำถามที่ใช้คำต่างกัน อย่างไรก็ตาม เนื่องจากเป็นการค้นหาเชิงความหมาย อัลกอริทึมของเราจึงเลือกผลลัพธ์ที่ตรงกับความหมายอย่างถูกต้อง ไม่ใช่แค่ ถ้อยคำของแบบสอบถามของเรา)How do I remove an item from a set?How do list comprehensions work? การซื้อคืนนี้ใช้กลยุทธ์ที่ง่ายมากในการจัดทำดัชนีเอกสาร และค้นหารายการที่ตรงกันที่สุด ขั้นแรก จะแบ่งเอกสารทุกฉบับออกเป็นย่อหน้าหรือ 'บล็อก' จากนั้นจะเรียก co.embed ในแต่ละย่อหน้า เพื่อสร้างเวกเตอร์ที่ฝังโดยใช้โมเดลภาษาของ Cohere จากนั้นจะจัดเก็บเวกเตอร์ที่ฝังแต่ละตัว พร้อมด้วยเอกสารที่เกี่ยวข้องและหมายเลขบรรทัดของย่อหน้า ในอาร์เรย์แบบง่ายเป็น 'ฐานข้อมูล'
เพื่อดำเนินการค้นหาจริงๆ เราใช้ไลบรารีการค้นหาความคล้ายคลึงกันของ FAISS เมื่อเราได้รับข้อความค้นหา เราจะใช้การเรียก Cohere API เดียวกันเพื่อฝังข้อความค้นหา จากนั้นเราใช้ FAISS เพื่อค้นหาจุดสูงสุด
หากคุณมีคำถามหรือความคิดเห็น โปรดแจ้งปัญหาหรือติดต่อเราทาง Discord
หากคุณต้องการมีส่วนร่วมในโครงการนี้ โปรดอ่าน CONTRIBUTORS.md ในพื้นที่เก็บข้อมูลนี้ และลงนามในข้อตกลงใบอนุญาตผู้สนับสนุนก่อนที่จะส่งคำขอดึงข้อมูลใดๆ ลิงก์สำหรับลงนาม Cohere CLA จะถูกสร้างขึ้นในครั้งแรกที่คุณส่งคำขอดึงไปยังพื้นที่เก็บข้อมูล Cohere
Toy Semantic Search มีใบอนุญาต MIT ตามที่พบในไฟล์ใบอนุญาต


