wagtail_textract
1.0.0
แพ็คเกจนี้ไม่มีการบำรุงรักษา และเราไม่มีแผนจะบำรุงรักษา
เราแนะนำให้คุณใช้มันเป็นตัวอย่าง อาจคัดลอกโค้ดไปยังโปรเจ็กต์ของคุณเอง แต่อย่าติดตั้งแพ็คเกจ
แพ็คเกจนี้ใช้สำหรับการแทนที่คลาส Document ของ Wagtail ด้วยคลาสที่อนุญาตให้ค้นหาในเนื้อหาไฟล์เอกสารโดยใช้ข้อความ
Textrac สามารถแยกข้อความจากไฟล์ PDF, Excel และ Word ได้
แพ็คเกจนี้ได้รับแรงบันดาลใจจากปัญหา "การค้นหา: แยกข้อความจากเอกสาร" ใน Wagtail
เอกสารจะทำงานเหมือนเดิม ยกเว้นว่าการค้นหาเอกสารในส่วนติดต่อผู้ดูแลระบบของ Wagtail จะค้นหาคำค้นหาในเนื้อหาของไฟล์ด้วย
ภาพหน้าจอบางส่วนเพื่อแสดง
ในไซต์ Wagtail ใหม่ของเราที่ติดตั้ง wagtail_textract เราได้อัปโหลดไฟล์ชื่อ test_document.pdf โดยมีข้อความที่เขียนด้วยลายมืออยู่ในนั้น มีการระบุไว้ในส่วนต่อประสานผู้ดูแลระบบภายใต้เอกสาร:
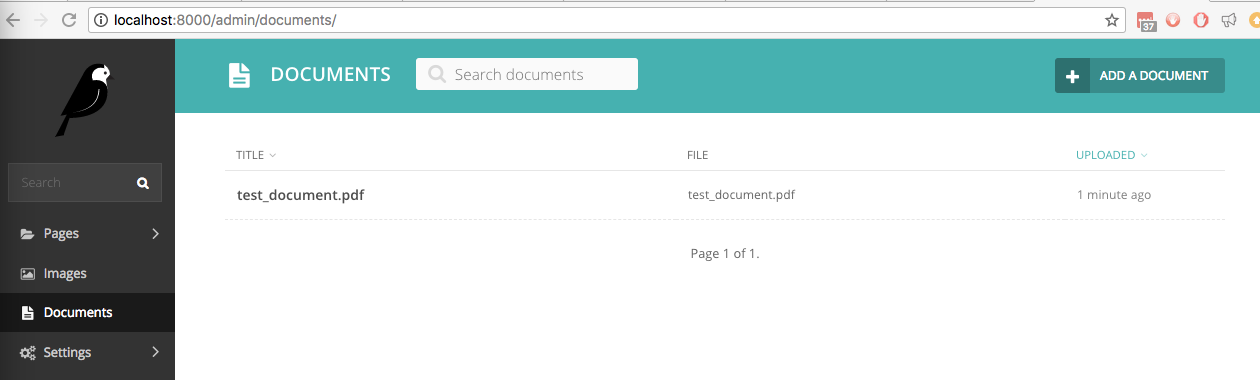
หากตอนนี้เราค้นหาคำว่า " correct ในเอกสาร ซึ่งเป็นหนึ่งในคำที่เขียนด้วยลายมือ การค้นหาแบบสดจะค้นหา:
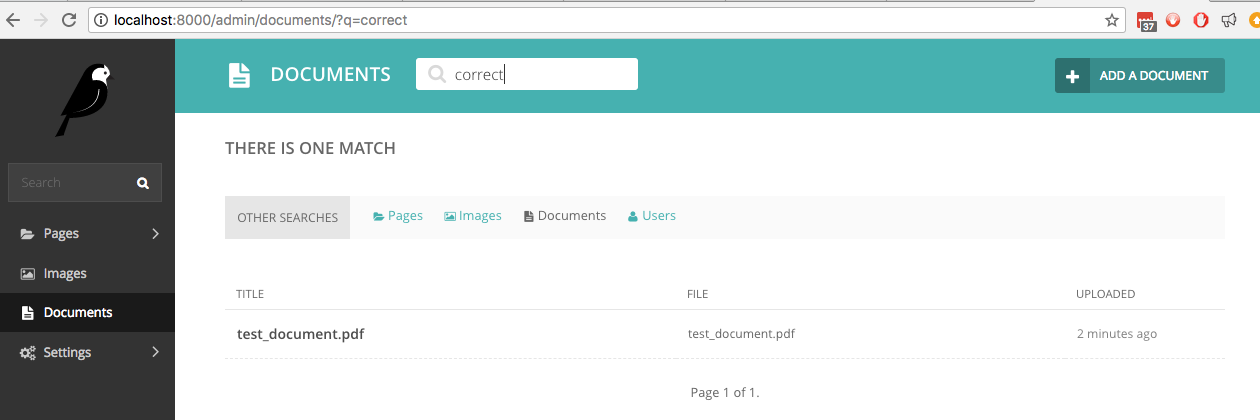
สมมติฐานคือการค้นหานี้ไม่เพียงแต่ควรมีในอินเทอร์เฟซผู้ดูแลระบบของ Wagtail เท่านั้น แต่ยังอยู่ในมุมมองการค้นหาแบบสาธารณะด้วย ซึ่งเราให้ตัวอย่างโค้ดไว้
เราใช้แพ็คเกจนี้ในการผลิตตั้งแต่เดือนสิงหาคม 2018 บน https://nuffic.nl
wagtail_textract ตามความต้องการของคุณและ/หรือ pip install wagtail_textractINSTALLED_APPS ของคุณWAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" ในการตั้งค่า Django ของคุณหมายเหตุ: คุณจะได้รับคำเตือนความไม่เข้ากันระหว่างการติดตั้ง wagtail_texttract (ติดตั้ง Wagtail 2.0.1):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
เราไม่เห็นว่าสิ่งนี้นำไปสู่ปัญหา แต่เป็นสิ่งที่ต้องคำนึงถึง
เพื่อให้ textract ใช้ Tesseract ซึ่งจะเกิดขึ้นหาก textract ปกติไม่พบข้อความ คุณจะต้องเพิ่มไฟล์ข้อมูลที่ Tesseract สามารถใช้จับคู่คำได้
สร้างไดเร็กทอรี tessdata ในไดเร็กทอรีโปรเจ็กต์ของคุณ และดาวน์โหลดภาษาที่คุณต้องการ
การถอดเสียงจะดำเนินการโดยอัตโนมัติหลังจากบันทึกเอกสารในโปรแกรมดำเนินการ asyncio เพื่อป้องกันการบล็อกการตอบสนองระหว่างการประมวลผล
หากต้องการถอดเสียงเอกสารที่มีอยู่ทั้งหมด ให้รันคำสั่งการจัดการ::
./manage.py transcribe_documents
การดำเนินการนี้อาจใช้เวลานานอย่างเห็นได้ชัด
นี่คือตัวอย่างโค้ดสำหรับมุมมองการค้นหา (นอกอินเทอร์เฟซผู้ดูแลระบบของ Wagtail) ที่แสดงทั้งผลลัพธ์ของหน้าและเอกสาร
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) เทมเพลตของคุณควรอนุญาตให้จัดการเอกสารแตกต่างจาก Pages ได้ เนื่องจากคุณไม่สามารถสร้าง pageurl result ในเอกสารได้:
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} หากต้องการใช้ wagtail_texttract โมเดล CustomizedDocument ของคุณควรดำเนินการเหมือนกับเอกสารของ wagtail_texttract:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] โปรดทราบว่าคลาสแรกของคลาสย่อยควรเป็น TranscriptionMixin ดังนั้น save() จึงมีความสำคัญมากกว่าคลาสพาเรนต์อื่นๆ
หากต้องการรันการทดสอบ ให้ชำระเงินที่เก็บข้อมูลนี้และ:
make test
รายงานความครอบคลุมจะถูกสร้างขึ้นใน ./coverage_html_report/ coverage_html_report/


