loss_function_search
1.0.0
เสี่ยวโป หวัง*, โชว หวัง*, เฉิง ชิ, จางซือเฟิง, เถาเหมย
นี่คือการดำเนินการอย่างเป็นทางการของการค้นหาฟังก์ชันการสูญเสียสำหรับการจดจำใบหน้า ได้รับการยอมรับจาก ICML 2020
ในการจดจำใบหน้า การออกแบบฟังก์ชันการสูญเสียซอฟต์แม็กซ์ตามระยะขอบ (เช่น เชิงมุม การบวก การบวก การบวก) มีบทบาทสำคัญในการเรียนรู้คุณลักษณะจำแนก อย่างไรก็ตาม วิธีการฮิวริสติกที่สร้างขึ้นด้วยมือเหล่านี้ยังไม่ค่อยเหมาะสมนัก เนื่องจากต้องใช้ความพยายามอย่างมากในการสำรวจพื้นที่การออกแบบขนาดใหญ่ ขั้นแรกเราวิเคราะห์ว่ากุญแจสำคัญในการปรับปรุงการเลือกปฏิบัติคุณลักษณะคือการ ลดความน่าจะเป็นของ softmax จากนั้นเราออกแบบสูตรแบบรวมสำหรับการสูญเสียซอฟต์แม็กซ์ตามมาร์จิ้นในปัจจุบัน ดังนั้นเราจึงกำหนดพื้นที่การค้นหาใหม่และพัฒนาวิธีการค้นหาแบบมีรางวัลตอบแทนเพื่อให้ได้ผู้สมัครที่ดีที่สุดโดยอัตโนมัติ ผลการทดลองเกี่ยวกับเกณฑ์มาตรฐานการจดจำใบหน้าที่หลากหลายได้แสดงให้เห็นถึงประสิทธิผลของวิธีการของเราเหนือทางเลือกที่ล้ำสมัย
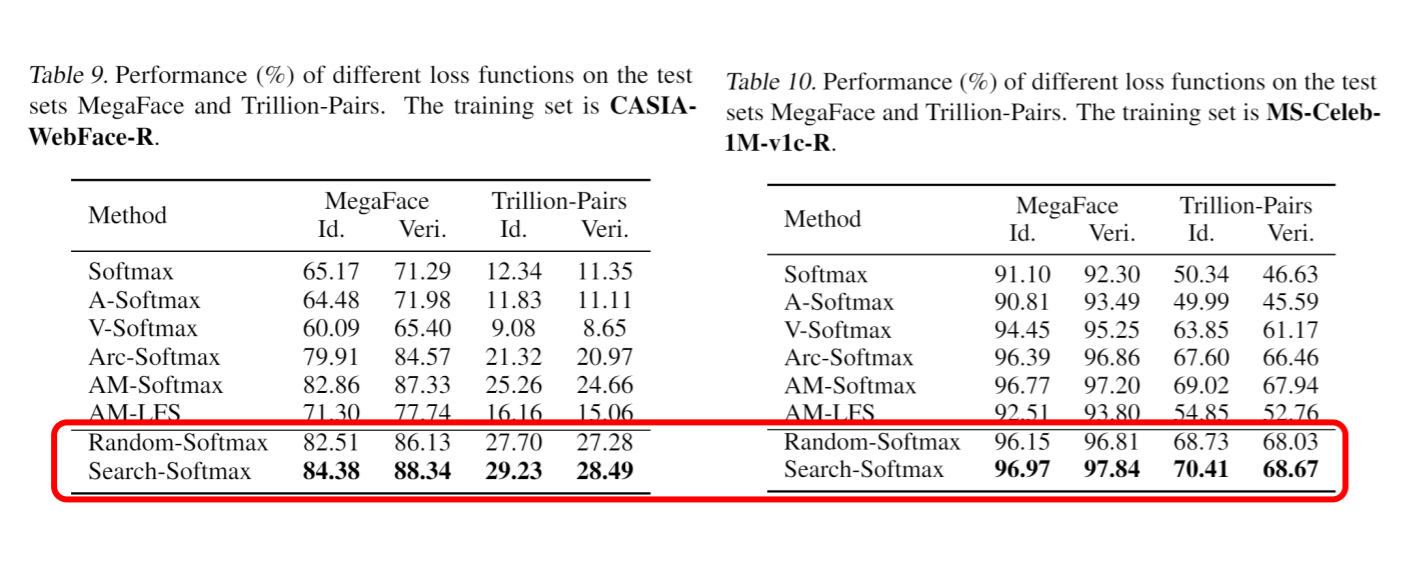

เพื่อตรวจสอบประสิทธิภาพของพื้นที่การค้นหาของเรา เราสามารถเลือก Random-softmax ได้ ใน train.sh คุณสามารถตั้งค่า do_search=1 ได้ หากเราใช้ softmax แบบสุ่มเพื่อฝึกเครือข่ายของเรา เราจะได้ผลลัพธ์ด้านล่าง
ต้องใช้ Pytorch 1.1 หรือสูงกว่า
ในการนำไปใช้งานในปัจจุบัน เราใช้ lmdb เพื่อแพ็คอิมเมจการฝึกของเรา รูปแบบของ lmdb ของเรามาจาก Caffe เป็นหลัก และคุณสามารถเขียนไฟล์ caffe.proto ของคุณเองได้ดังนี้:
syntax = "proto2";
message Datum {
//the acutal image data, in bytes.
optional bytes data=1;
}
นอกเหนือจาก lmdb แล้ว ควรมีไฟล์ข้อความที่อธิบาย lmdb ไฟล์ข้อความแต่ละบรรทัดประกอบด้วย 2 ช่องซึ่งคั่นด้วยช่องว่าง บรรทัดในไฟล์ข้อความมีดังนี้:
lmdb_key label
./train.shคุณสามารถใช้ ./train.sh โปรดทราบว่าก่อนที่คุณจะดำเนินการ train.sh คุณควรจัดเตรียม train_source_lmdb และ train_source_file ของคุณเอง สำหรับการใช้งานเพิ่มเติมกรุณา
python main . py - h

