SeekStorm
v0.11.0

SeekStorm เป็น ไลบรารีการค้นหาข้อความแบบเต็มแบบโอเพ่นซอร์สที่ต่ำกว่ามิลลิวินาที และ เซิร์ฟเวอร์หลายผู้เช่า ที่ใช้งานใน Rust
การพัฒนาเริ่มต้นในปี 2558 ในการผลิตตั้งแต่ปี 2563 พอร์ต Rust ในปี 2566 โอเพ่นซอร์สในปี 2567 อยู่ระหว่างดำเนินการ
SeekStorm เป็นโอเพ่นซอร์สที่ได้รับอนุญาตภายใต้ Apache License 2.0
โพสต์ในบล็อก: ขณะนี้ SeekStorm เป็นโอเพ่นซอร์สแล้ว และ SeekStorm ได้รับการค้นหาแบบ Faceted, การค้นหาความใกล้เคียงทางภูมิศาสตร์, การเรียงลำดับผลลัพธ์
ประเภทแบบสอบถาม
ประเภทผลลัพธ์
ผลงาน
เวลาแฝงที่ต่ำกว่า ปริมาณงานที่สูงขึ้น ต้นทุนและการใช้พลังงานที่ลดลง โดยเฉพาะ สำหรับการสืบค้นแบบหลายช่องและพร้อมกัน
เวลาแฝงที่ต่ำทำให้ผู้ใช้ได้รับประสบการณ์ที่ราบรื่นและป้องกันการสูญเสียลูกค้าและรายได้
แม้ว่าบางส่วนจะอาศัยตัวเร่งฮาร์ดแวร์ที่เป็นกรรมสิทธิ์ (FPGA/ASIC) หรือคลัสเตอร์เพื่อปรับปรุงประสิทธิภาพ
SeekStorm ประสบความสำเร็จในการเพิ่มอัลกอริทึมที่คล้ายกันบนเซิร์ฟเวอร์สินค้าโภคภัณฑ์เดียว
ความสม่ำเสมอ
ไม่มีเวลาแฝงในการสืบค้นที่คาดเดาไม่ได้ในระหว่างและหลังการจัดทำดัชนีปริมาณมาก เนื่องจาก SeekStorm ไม่ต้องการการรวมกลุ่มที่ใช้ทรัพยากรจำนวนมาก
เวลาแฝงที่เสถียร - ไม่มีค่าใช้จ่าย Cold Start เนื่องจากการคอมไพล์แบบทันเวลา ไม่มีความล่าช้าในการรวบรวมขยะที่คาดเดาไม่ได้
การปรับขนาด
รักษาเวลาแฝงต่ำ ปริมาณงานสูง และใช้ RAM ต่ำ แม้กระทั่งกับดัชนีระดับพันล้าน
ไม่จำกัดจำนวนฟิลด์ ความยาวฟิลด์ และขนาดดัชนี
ความเกี่ยวข้อง
การจัดอันดับความใกล้เคียงในระยะให้ผลลัพธ์ที่เกี่ยวข้องมากกว่าเมื่อเปรียบเทียบกับ BM25
เรียลไทม์
การค้นหาแบบเรียลไทม์อย่างแท้จริง ตรงข้ามกับ NRT: ทุกเอกสารที่จัดทำดัชนีสามารถค้นหาได้ทันที แม้กระทั่งก่อนและระหว่างการคอมมิต
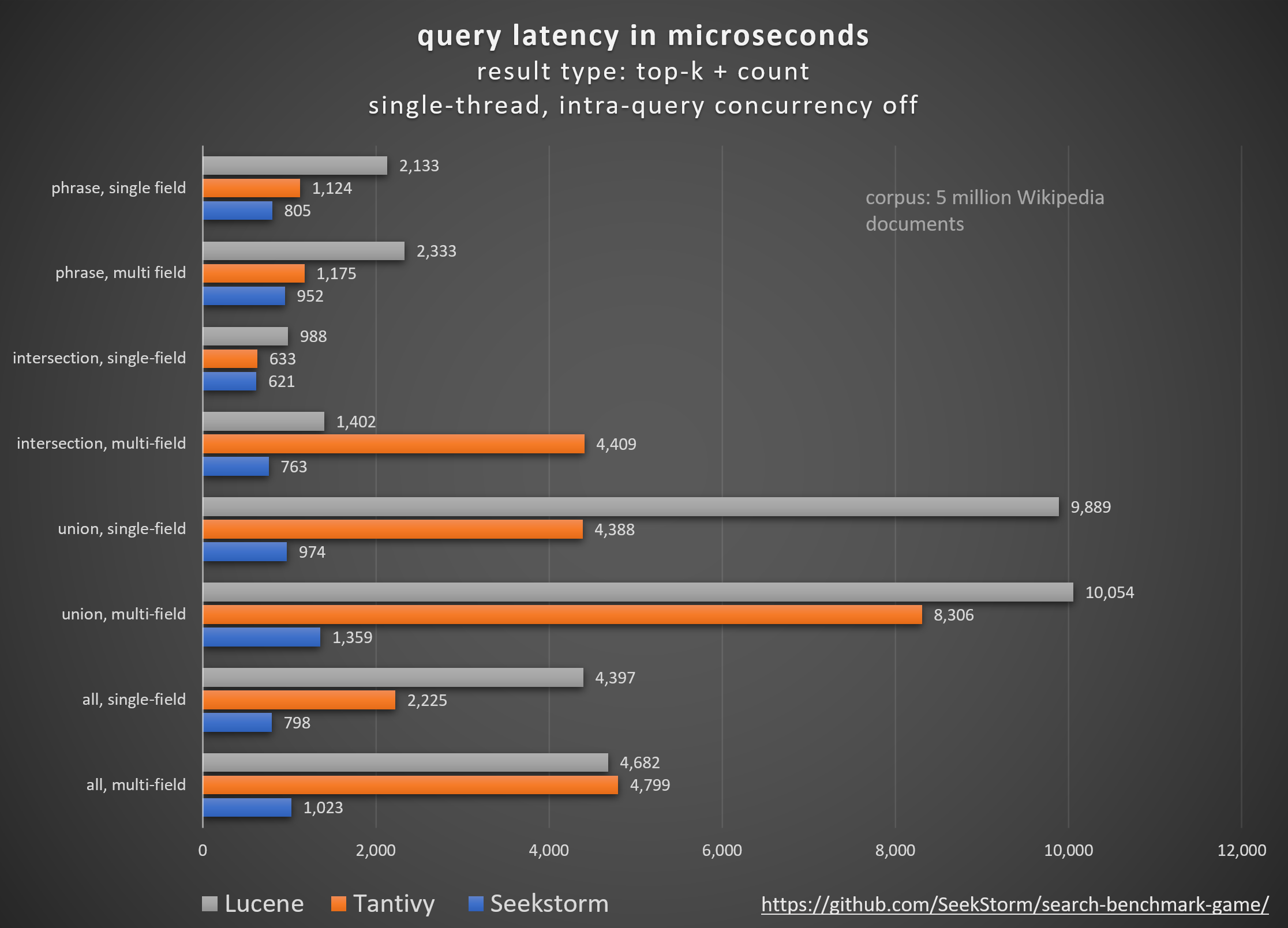
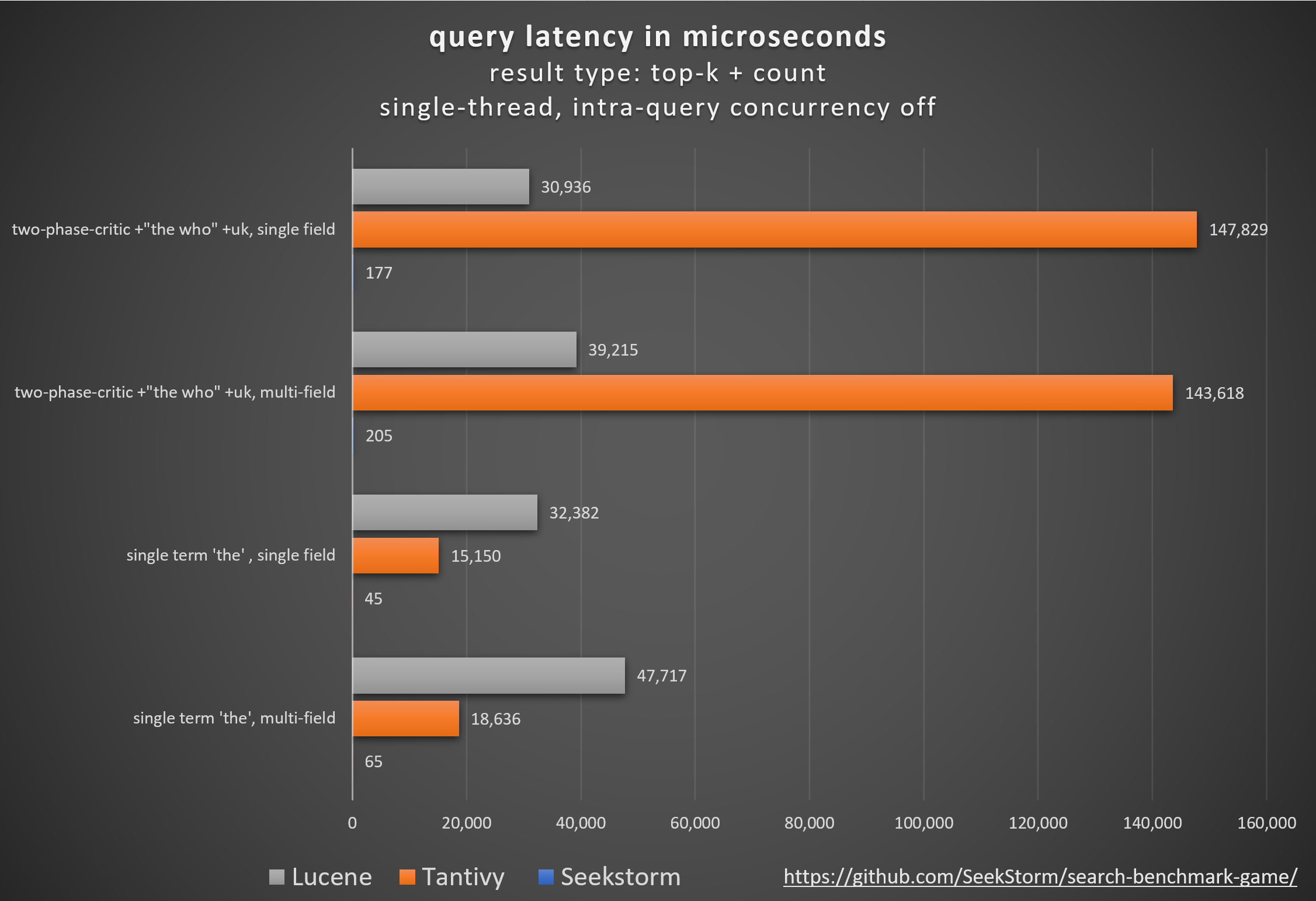
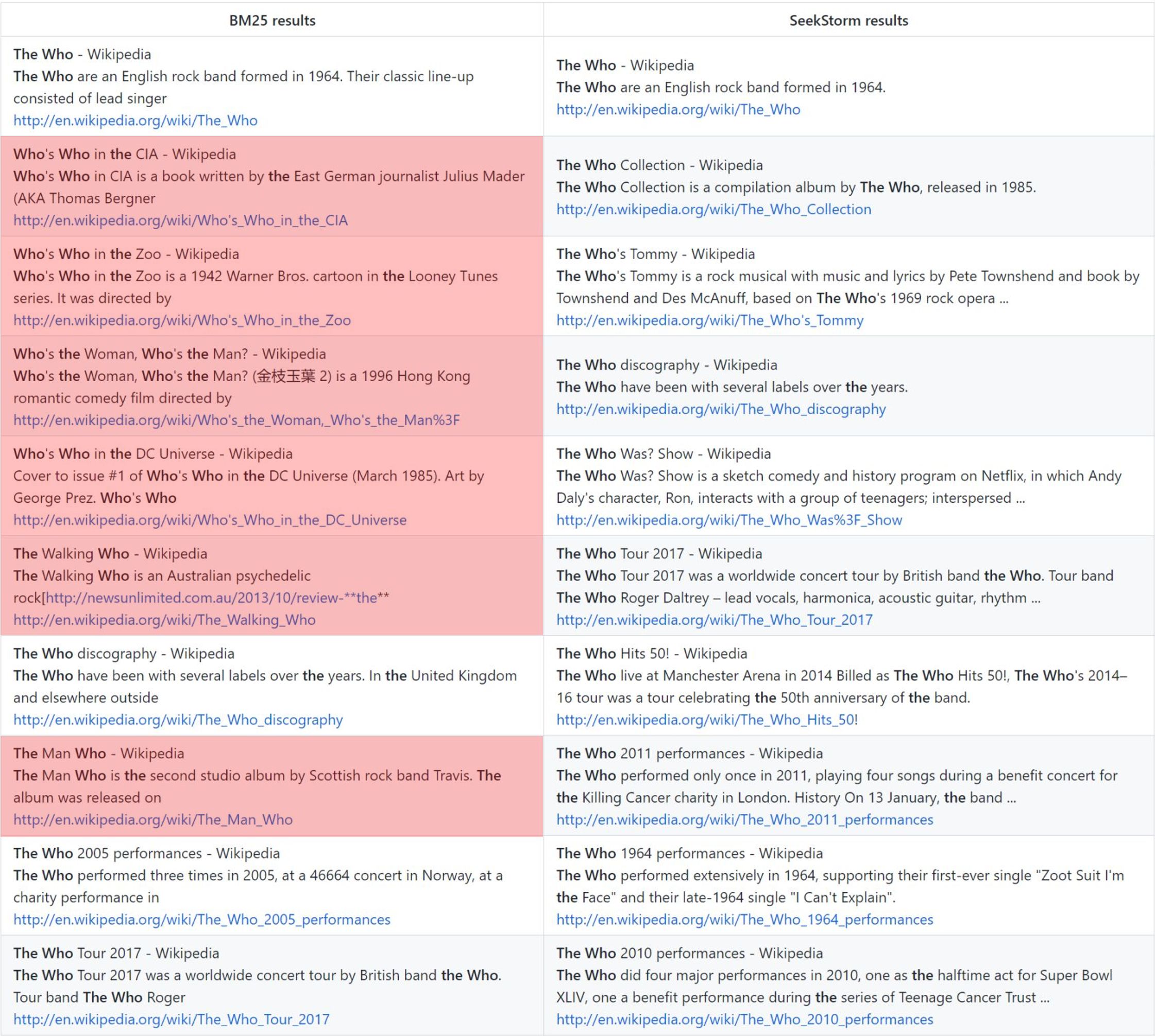
ใคร: การจัดอันดับวานิลลา BM25 เทียบกับการจัดอันดับความใกล้ชิดของ SeekStorm
ระเบียบวิธี
การเปรียบเทียบไลบรารีเครื่องมือค้นหาโอเพ่นซอร์สต่างๆ (การค้นหาคำศัพท์ BM25) โดยใช้โอเพ่นซอร์ส search_benchmark_game ที่พัฒนาโดย Tantivy และ Jason Wolfe
ประโยชน์
ผลการวัดประสิทธิภาพโดยละเอียด https://seekstorm.github.io/search-benchmark-game/
ที่เก็บโค้ดมาตรฐาน https://github.com/SeekStorm/search-benchmark-game/
ดู โพสต์บนบล็อก ของเราสำหรับข้อมูลโดยละเอียดเพิ่มเติม: ขณะนี้ SeekStorm เป็นโอเพ่นซอร์สแล้ว และ SeekStorm ได้รับการค้นหาแบบ Faceted, การค้นหาใกล้เคียงทางภูมิศาสตร์, การเรียงลำดับผลลัพธ์
แม้ว่า https://www.bitecode.dev/p/hype-cycles ต้องการให้คุณเชื่อตามที่ hype-cycles การค้นหาคำหลักยังไม่ตาย เนื่องจาก NoSQL ไม่ใช่จุดจบของ SQL
คุณควรดูแลรักษากล่องเครื่องมือและเลือกเครื่องมือที่ดีที่สุดสำหรับงานของคุณ https://seekstorm.com/blog/vector-search-vs-keyword-search1/
การค้นหาคำหลักเป็นเพียงตัวกรองสำหรับชุดของเอกสาร โดยส่งคืนเอกสารที่มีคำหลักบางคำ โดยทั่วไปจะรวมกับตัวชี้วัดการจัดอันดับ เช่น BM25 ฟังก์ชันการทำงานขั้นพื้นฐานและหลักซึ่งมีความท้าทายอย่างยิ่งในการนำไปใช้งานในวงกว้างโดยมีความหน่วงต่ำ เนื่องจากฟังก์ชันการทำงานเป็นพื้นฐาน จึงมีฟิลด์แอปพลิเคชันไม่จำกัดจำนวน เป็นส่วนประกอบเพื่อใช้ร่วมกับส่วนประกอบอื่นๆ มีหลายกรณีการใช้งานที่สามารถแก้ไขได้ดีกว่าในปัจจุบันด้วยการค้นหาเวกเตอร์และ LLM แต่สำหรับการค้นหาคำหลักอื่นๆ อีกมากมายยังคงเป็นทางออกที่ดีที่สุด การค้นหาคำหลักนั้นแม่นยำ ไม่มีการสูญเสีย และรวดเร็วมาก โดยมีการปรับขนาดที่ดีขึ้น เวลาแฝงที่ดีขึ้น ต้นทุนและการใช้พลังงานลดลง การค้นหาเวกเตอร์ทำงานด้วยความคล้ายคลึงกันทางความหมาย โดยส่งคืนผลลัพธ์ด้วยความใกล้เคียงและความน่าจะเป็นที่กำหนด
หากคุณค้นหาผลลัพธ์ที่แน่นอน เช่น ชื่อเฉพาะ ตัวเลข ป้ายทะเบียน ชื่อโดเมน และวลี (เช่น การตรวจจับการลอกเลียนแบบ) การค้นหาด้วยคำหลักก็เป็นเพื่อนของคุณ ในทางกลับกัน การค้นหาเวกเตอร์จะฝังผลลัพธ์ที่แน่นอนที่คุณกำลังมองหาไว้ท่ามกลางผลลัพธ์มากมายที่เกี่ยวข้องกับความหมายในทางใดทางหนึ่งเท่านั้น ในเวลาเดียวกัน หากคุณไม่ทราบคำศัพท์ที่แน่ชัด หรือสนใจหัวข้อ ความหมาย หรือคำพ้องความหมายที่กว้างขึ้น ไม่ว่าจะใช้คำที่ตรงทั้งหมดเพียงใด การค้นหาคำหลักก็จะทำให้คุณล้มเหลว
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.การค้นหาเวกเตอร์นั้นสมบูรณ์แบบหากคุณไม่ทราบคำค้นหาที่แน่ชัด หรือคุณสนใจหัวข้อ ความหมาย หรือคำพ้องความหมายที่กว้างขึ้น ไม่ว่าจะใช้คำค้นหาที่ตรงกันทุกประการก็ตาม แต่หากคุณกำลังมองหาคำที่เจาะจง เช่น ชื่อเฉพาะ ตัวเลข ป้ายทะเบียน ชื่อโดเมน และวลี (เช่น การตรวจจับการลอกเลียนแบบ) คุณควรใช้การค้นหาด้วยคำหลักเสมอ การค้นหาเวกเตอร์จะฝังผลลัพธ์ที่แน่นอนที่คุณกำลังมองหาไว้ท่ามกลางผลลัพธ์มากมายที่เกี่ยวข้องกันเท่านั้น มีการเรียกคืนที่ดี แต่มีความแม่นยำต่ำ และมีเวลาแฝงสูงกว่า มีแนวโน้มที่จะเกิดผลบวกลวง เช่น ในการตรวจจับการลอกเลียนแบบ เนื่องจากคำที่ตรงกันและลำดับคำหายไป
การค้นหาเวกเตอร์ช่วยให้คุณค้นหาได้ไม่เพียงแค่ข้อความที่คล้ายกันเท่านั้น แต่ยังรวมถึงทุกสิ่งที่สามารถแปลงเป็นเวกเตอร์ได้: ข้อความ รูปภาพ (การจดจำใบหน้า ลายนิ้วมือ) เสียง และช่วยให้คุณทำสิ่งมหัศจรรย์ เช่น ราชินี - ผู้หญิง + ผู้ชาย = ราชา .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationการค้นหาแบบเวกเตอร์ไม่ใช่การแทนที่การค้นหาคำหลัก แต่เป็นการเพิ่มเติมเสริม - ควรใช้ภายในโซลูชันแบบผสมที่นำจุดแข็งของทั้งสองวิธีมารวมกัน การค้นหาคำหลักไม่ล้าสมัย แต่ได้รับการพิสูจน์ตามเวลา
เราได้ย้ายฐานโค้ด SeekStorm จาก C# ไปเป็น Rust (บางส่วน) แล้ว
Rust นั้นยอดเยี่ยมสำหรับแอปพลิเคชันที่เน้นประสิทธิภาพซึ่งจัดการกับข้อมูลขนาดใหญ่และ/หรือผู้ใช้จำนวนมากพร้อมกัน อัลกอริธึมที่รวดเร็วจะโดดเด่นยิ่งขึ้นด้วยภาษาโปรแกรมที่คำนึงถึงประสิทธิภาพ ?
ดู ARCHITECTURE.md
cargo build --release
คำเตือน : ตรวจสอบให้แน่ใจว่าได้ตั้งค่าตัวแปรสภาพแวดล้อม MASTER_KEY_SECRET เป็นความลับ ไม่เช่นนั้นคีย์ API ที่คุณสร้างขึ้นจะถูกบุกรุก
https://docs.rs/seekstorm
สร้างเอกสาร
cargo doc --no-deps
เข้าถึงเอกสารภายในเครื่อง
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
เพิ่มลังที่จำเป็นในโครงการของคุณ
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;ใช้รันไทม์ Rust แบบอะซิงโครนัส
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {สร้างดัชนี
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;เปิดดัชนี (หรือสร้างดัชนี)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; เอกสารดัชนี
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; มอบเอกสาร
index_arc . commit ( ) . await ;ดัชนีการค้นหา
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;แสดงผล
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}ค้นหาแบบหลายเธรด
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}ไฟล์ดัชนี JSON ในรูปแบบ JSON, JSON ที่คั่นด้วยบรรทัดใหม่ และรูปแบบ JSON ที่ต่อกัน
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;สร้างดัชนีไฟล์ PDF ทั้งหมดในไดเร็กทอรีและไดเร็กทอรีย่อย
ingest คอนโซล): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;ไฟล์ดัชนี PDF
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;ไบต์ของไฟล์ดัชนี PDF
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;รับไบต์ของไฟล์ PDF
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;ดัชนีที่ชัดเจน
index . clear_index ( ) ;ลบดัชนี
index . delete_index ( ) ;ปิดดัชนี
index . close_index ( ) ;สตริงเวอร์ชันไลบรารีของ Seestorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;Facets ถูกกำหนดไว้ใน 3 ตำแหน่งที่แตกต่างกัน:
ตัวอย่างการทำงานขั้นต่ำของการจัดทำดัชนีและการค้นหาแบบเหลี่ยมต้องใช้โค้ดเพียง 60 บรรทัด แต่การไขปริศนาทั้งหมดจากเอกสารประกอบเพียงอย่างเดียวอาจเป็นเรื่องที่น่าเบื่อ นี่คือเหตุผลที่เราแสดงตัวอย่างการเริ่มต้นอย่างรวดเร็วที่นี่:
เพิ่มลังที่จำเป็นในโครงการของคุณ
cargo add seekstorm
cargo add tokio
cargo add serde_jsonเพิ่มประกาศการใช้งาน
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;ใช้รันไทม์ Rust แบบอะซิงโครนัส
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {สร้างดัชนี
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;เอกสารดัชนี
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; มอบเอกสาร
index_arc . commit ( ) . await ;ดัชนีการค้นหา
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;แสดงผล
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}แสดงแง่มุม
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;สิ้นสุดฟังก์ชันหลัก
Ok ( ( ) )
} บทช่วยสอนทีละขั้นตอนอย่างรวดเร็วเกี่ยวกับวิธีสร้างเครื่องมือค้นหา Wikipedia จากคลังข้อมูล Wikipedia โดยใช้เซิร์ฟเวอร์ SeekStorm ใน 5 ขั้นตอนง่ายๆ

ดาวน์โหลด SeekStorm.dll
ดาวน์โหลด SeekStorm จากที่เก็บ GitHub
แตกไฟล์ในไดเร็กทอรีที่คุณเลือก เปิดในโค้ด Visual Studio
หรืออีกทางหนึ่ง
git clone https://github.com/SeekStorm/SeekStorm.git
สร้าง SeekStorm
ติดตั้ง Rust (หากยังไม่มี): https://www.rust-lang.org/tools/install
ในเทอร์มินัลประเภท Visual Studio Code:
cargo build --release
รับคลังวิกิพีเดีย
คลังวิกิพีเดียภาษาอังกฤษที่ประมวลผลล่วงหน้า (เอกสาร 5,032,105 เอกสาร, แตกขนาด 8,28 GB) แม้ว่า wiki-articles.json จะมีนามสกุล .JSON แต่ก็ไม่ใช่ไฟล์ JSON ที่ถูกต้อง เป็นไฟล์ข้อความที่ทุกบรรทัดมีออบเจ็กต์ JSON พร้อมด้วยแอตทริบิวต์ url, title และ body รูปแบบนี้เรียกว่า ndjson ("Newline delimited JSON")
ดาวน์โหลดวิกิพีเดียคลังข้อมูล
ขยายคลังข้อมูล Wikipedia
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
ย้าย wiki-articles.json ที่คลายการบีบอัดไปยังไดเร็กทอรี release
เริ่มเซิร์ฟเวอร์ SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
การจัดทำดัชนี
พิมพ์ 'ingest' ลงในบรรทัดคำสั่งของเซิร์ฟเวอร์ SeekStorm ที่ทำงานอยู่:
ingest
สิ่งนี้จะสร้างดัชนีสาธิตและจัดทำดัชนีไฟล์วิกิพีเดียในเครื่อง
เริ่มค้นหาภายใน WebUI ที่ฝังไว้
เปิด Web UI แบบฝังในเบราว์เซอร์: http://127.0.0.1
ป้อนคำค้นหาลงในช่องค้นหา
การทดสอบจุดสิ้นสุด REST API
เปิด src/seekstorm_server/test_api.rest ใน VSC พร้อมกับส่วนขยาย VSC "Rest client" เพื่อดำเนินการเรียก API และตรวจสอบการตอบสนอง
ตัวอย่างจุดสิ้นสุด API แบบโต้ตอบ
ตั้งค่า 'คีย์ API ส่วนบุคคล' ใน test_api.rest เป็นคีย์ api ที่แสดงในคอนโซลเซิร์ฟเวอร์เมื่อคุณพิมพ์ 'ดัชนี' ด้านบน
ลบดัชนีสาธิต
พิมพ์ 'ลบ' ลงในบรรทัดคำสั่งของเซิร์ฟเวอร์ SeekStorm ที่ทำงานอยู่:
delete
ปิดเซิร์ฟเวอร์
พิมพ์ 'quit' ลงในบรรทัดคำสั่งของเซิร์ฟเวอร์ SeekStorm ที่ทำงานอยู่
quit
การปรับแต่ง
คุณต้องการใช้สิ่งที่คล้ายกันสำหรับโครงการของคุณเองหรือไม่? ดูเอกสารประกอบการนำเข้าและ UI ของเว็บ
บทช่วยสอนทีละขั้นตอนอย่างรวดเร็วเกี่ยวกับวิธีสร้างเครื่องมือค้นหา PDF จากไดเร็กทอรีที่มีไฟล์ PDF โดยใช้เซิร์ฟเวอร์ SeekStorm
ทำให้สามารถค้นหาเอกสารทางวิทยาศาสตร์ ebooks ประวัติย่อ รายงาน สัญญา คู่มือ จดหมาย ใบแจ้งยอดธนาคาร ใบแจ้งหนี้ ใบส่งมอบสินค้า ที่บ้านหรือในองค์กรของคุณ
สร้าง SeekStorm
ติดตั้ง Rust (หากยังไม่มี): https://www.rust-lang.org/tools/install
ในเทอร์มินัลประเภท Visual Studio Code:
cargo build --release
ดาวน์โหลด PDFium
ดาวน์โหลดและคัดลอกไลบรารี Pdfium ลงในโฟลเดอร์เดียวกับ Seekstorm_server.exe: https://github.com/bblanchon/pdfium-binaries
เริ่มเซิร์ฟเวอร์ SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
การจัดทำดัชนี
เลือกไดเร็กทอรีที่มีไฟล์ PDF ที่คุณต้องการสร้างดัชนีและค้นหา เช่น เอกสารของคุณหรือไดเร็กทอรีดาวน์โหลด
พิมพ์ 'ingest' ลงในบรรทัดคำสั่งของเซิร์ฟเวอร์ SeekStorm ที่ทำงานอยู่:
ingest C:UsersJohnDoeDownloads
ซึ่งจะสร้าง pdf_index และจัดทำดัชนีไฟล์ PDF ทั้งหมดจากไดเร็กทอรีที่ระบุ รวมถึงไดเร็กทอรีย่อยด้วย
เริ่มค้นหาภายใน WebUI ที่ฝังไว้
เปิด Web UI แบบฝังในเบราว์เซอร์: http://127.0.0.1
ป้อนคำค้นหาลงในช่องค้นหา
ลบดัชนีสาธิต
พิมพ์ 'delete' ลงในบรรทัดคำสั่งของเซิร์ฟเวอร์ SeekStorm ที่ทำงานอยู่:
delete
ปิดเซิร์ฟเวอร์
พิมพ์ 'quit' ลงในบรรทัดคำสั่งของเซิร์ฟเวอร์ SeekStorm ที่ทำงานอยู่
quit
ค้นหาข้อความแบบเต็ม 30 ล้านโพสต์ข่าวแฮ็กเกอร์และหน้าเว็บที่เชื่อมโยง
DeepHN.org
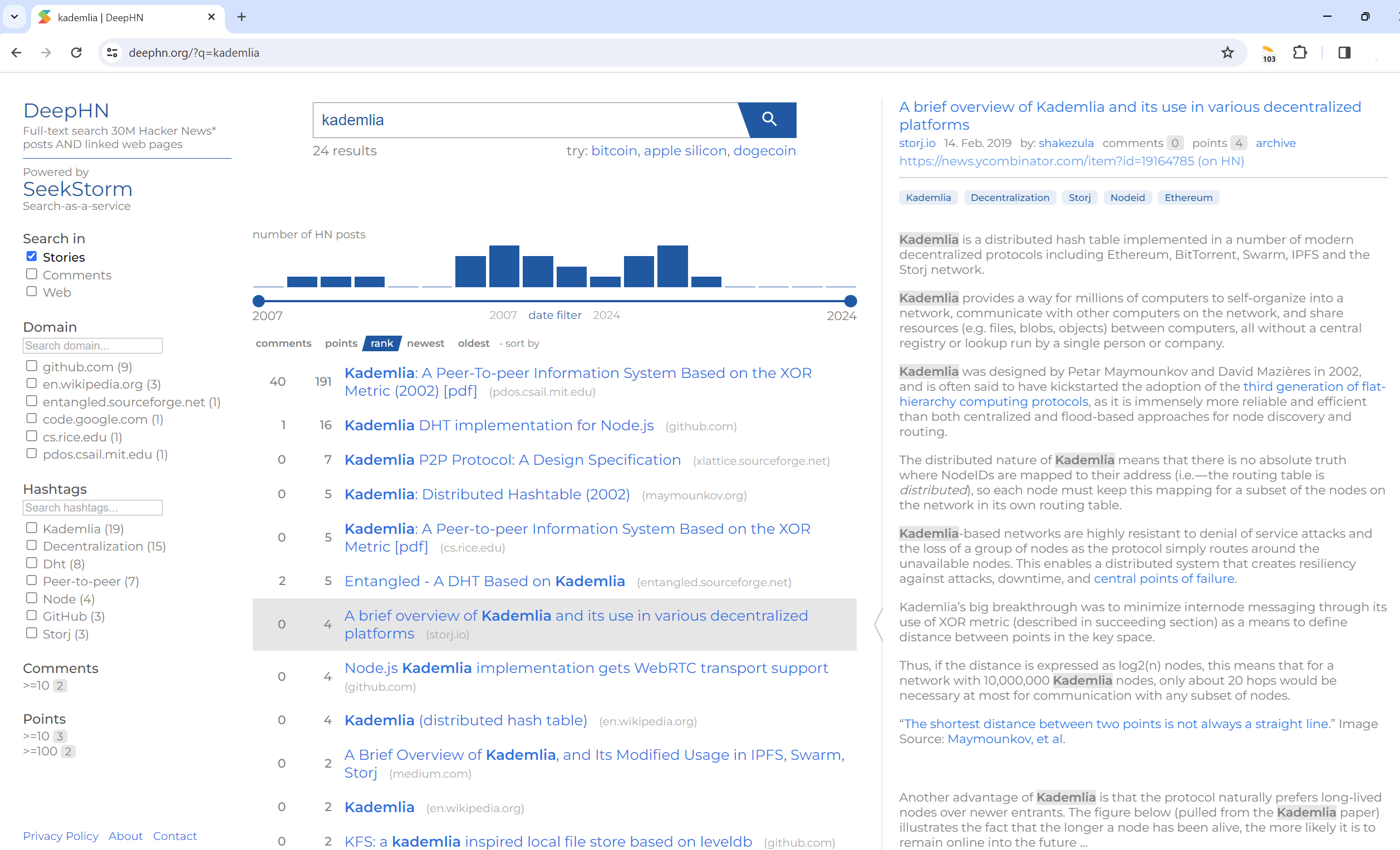
การสาธิต DeepHN ยังคงใช้โค้ดเบส SeekStorm C#
ขณะนี้เรากำลังย้ายฟีเจอร์ที่ขาดหายไปที่จำเป็นทั้งหมด
ดูแผนงานด้านล่าง
พอร์ต Rust ยังไม่เสร็จสมบูรณ์ คุณลักษณะต่อไปนี้ได้รับการย้ายแล้ว
การพอร์ต
การปรับปรุง
คุณสมบัติใหม่


