auctus
1.0.0
โปรเจ็กต์นี้เป็นโปรแกรมรวบรวมข้อมูลเว็บและเครื่องมือค้นหาสำหรับชุดข้อมูล ซึ่งมีไว้สำหรับงานเสริมข้อมูลในแมชชีนเลิร์นนิงโดยเฉพาะ สามารถค้นหาชุดข้อมูลในที่เก็บข้อมูลต่างๆ และจัดทำดัชนีเพื่อการเรียกค้นในภายหลัง
เอกสารมีอยู่ที่นี่
แบ่งออกเป็นหลายองค์ประกอบ:
datamart_geo ประกอบด้วยข้อมูลเกี่ยวกับเขตบริหารที่ดึงมาจาก Wikidata และ OpenStreetMap มันอาศัยอยู่ในพื้นที่เก็บข้อมูลของตัวเองและถูกใช้ที่นี่เป็นโมดูลย่อยdatamart_profiler ไคลเอนต์สามารถติดตั้งได้ ซึ่งจะทำให้ไลบรารีไคลเอนต์สามารถสร้างโปรไฟล์ชุดข้อมูลในเครื่องแทนที่จะส่งไปยังเซิร์ฟเวอร์ นอกจากนี้ยังใช้โดยบริการ apiserver และผู้สร้างโปรไฟล์อีกด้วยdatamart_materialize ใช้เพื่อสร้างชุดข้อมูลจากแหล่งต่างๆ ที่ Auctus รองรับ ไคลเอนต์สามารถติดตั้งได้ ซึ่งจะช่วยให้พวกเขาสามารถสร้างชุดข้อมูลในเครื่องแทนการใช้เซิร์ฟเวอร์เป็นพร็อกซีdatamart_augmentation การดำเนินการนี้จะรวมหรือรวมชุดข้อมูลสองชุดเข้าด้วยกันและใช้งานโดยบริการ apiserver แต่อาจใช้แบบสแตนด์อโลนได้datamart_core ประกอบด้วยรหัสทั่วไปสำหรับบริการ ใช้สำหรับส่วนประกอบเซิร์ฟเวอร์เท่านั้น รหัสล็อคระบบไฟล์แยกเป็น datamart_fslock ด้วยเหตุผลด้านประสิทธิภาพ (ต้องนำเข้าอย่างรวดเร็ว)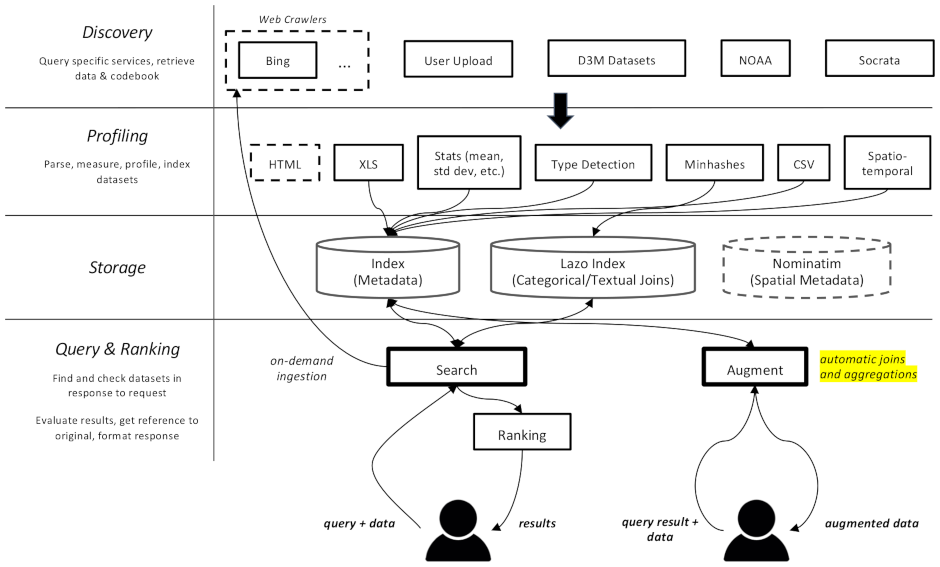
Elasticsearch ใช้เป็นดัชนีการค้นหา โดยจัดเก็บหนึ่งเอกสารต่อชุดข้อมูลที่รู้จัก
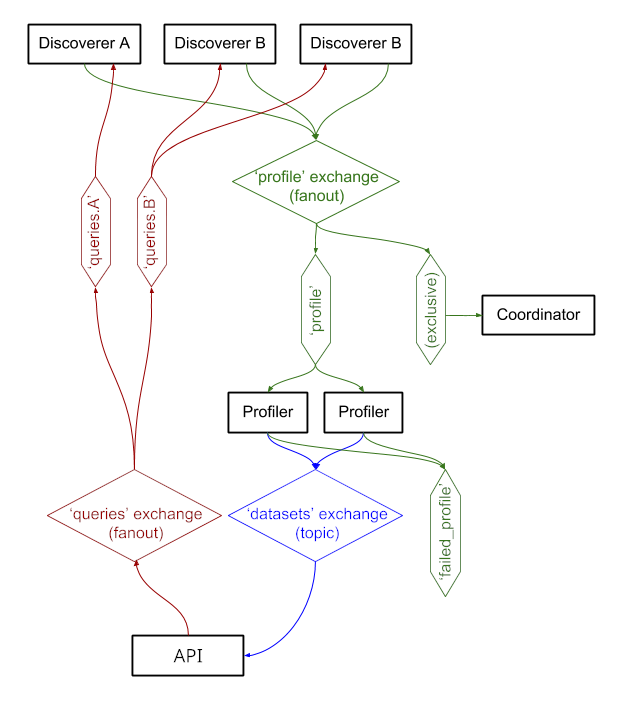
บริการแลกเปลี่ยนข้อความผ่าน RabbitMQ ทำให้เรามีรูปแบบการส่งข้อความที่ซับซ้อนพร้อมการจัดคิวและลองซีแมนทิกส์ซ้ำ และรูปแบบที่ซับซ้อน เช่น การสืบค้นตามความต้องการ
ขณะนี้ระบบกำลังทำงานอยู่ที่ https://auctus.vida-nyu.org/ สามารถดูสถานะระบบได้ที่ https://grafana.auctus.vida-nyu.org/
หากต้องการปรับใช้ระบบภายในเครื่องโดยใช้ docker-compose ให้ทำตามขั้นตอนเหล่านี้:
ตรวจสอบให้แน่ใจว่าคุณได้ตรวจสอบโมดูลย่อยด้วย git submodule init && git submodule update
ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งและกำหนดค่า Git LFS แล้ว ( git lfs install )
คัดลอก env.default ไปที่ .env และอัปเดตตัวแปรที่นั่น คุณอาจต้องการอัปเดตรหัสผ่านสำหรับการปรับใช้จริง
ตรวจสอบให้แน่ใจว่าโหนดของคุณได้รับการตั้งค่าสำหรับการเรียกใช้ Elasticsearch คุณอาจต้องเพิ่มขีดจำกัด mmap
API_URL คือ URL ที่คอนเทนเนอร์ apiserver จะปรากฏแก่ไคลเอ็นต์ ในการปรับใช้ที่ใช้งานจริง นี่อาจเป็น HTTPS URL ที่เปิดเผยต่อสาธารณะ อาจเป็น URL เดียวกันกับที่คอมโพเนนต์ "ผู้ประสานงาน" จะให้บริการหากใช้พร็อกซีย้อนกลับ (ดู nginx.conf)
หากต้องการรันสคริปต์ในเครื่อง คุณสามารถโหลดตัวแปรสภาพแวดล้อมลงในเชลล์ของคุณได้โดยการรัน . scripts/load_env.sh (นั่นคือ สคริปต์ dot space... )
เรียกใช้ scripts/setup.sh เพื่อเริ่มต้นปริมาณข้อมูล นี่จะเป็นการตั้งค่าการอนุญาตที่ถูกต้องบน volumes/ ไดเร็กทอรีย่อย
หากคุณต้องการเริ่มต้นใหม่ทั้งหมด คุณสามารถลบ volumes/ ได้ แต่อย่าลืมเรียกใช้ scripts/setup.sh อีกครั้งในภายหลังเพื่อตั้งค่าสิทธิ์
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
สิ่งเหล่านี้จะใช้เวลาไม่กี่วินาทีในการเริ่มต้นและทำงาน จากนั้นคุณสามารถเริ่มส่วนประกอบอื่นๆ ได้:
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
คุณสามารถใช้ตัวเลือก --scale เพื่อเริ่มสร้างโปรไฟล์หรือคอนเทนเนอร์ apiserver เพิ่มเติมได้ เช่น:
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
พอร์ต:
$ scripts/docker_import_snapshot.sh
การดำเนินการนี้จะดาวน์โหลดดัมพ์ Elasticsearch จาก auctus.vida-nyu.org และนำเข้าลงในคอนเทนเนอร์ Elasticsearch ในเครื่องของคุณ
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
Prometheus ได้รับการกำหนดค่าให้ค้นหาคอนเทนเนอร์โดยอัตโนมัติ (ดู prometheus.yml)
ใช้อิมเมจ RabbitMQ แบบกำหนดเองพร้อมปลั๊กอินเพิ่มเติม (การจัดการและโพร)


