elastic_transformers
1.0.0
Semantic Elasticsearch พร้อม Sentence Transformers เราจะใช้พลังของ Elastic และความมหัศจรรย์ของ BERT เพื่อจัดทำดัชนีบทความนับล้านบทความ และทำการค้นหาคำศัพท์และความหมายในบทความเหล่านั้น
จุดประสงค์คือเพื่อให้วิธีที่ใช้งานง่ายในการตั้งค่า Elasticsearch ของคุณเองด้วยความสามารถที่เกือบจะล้ำสมัยของการฝังตามบริบท / การค้นหาความหมายโดยใช้หม้อแปลง NLP
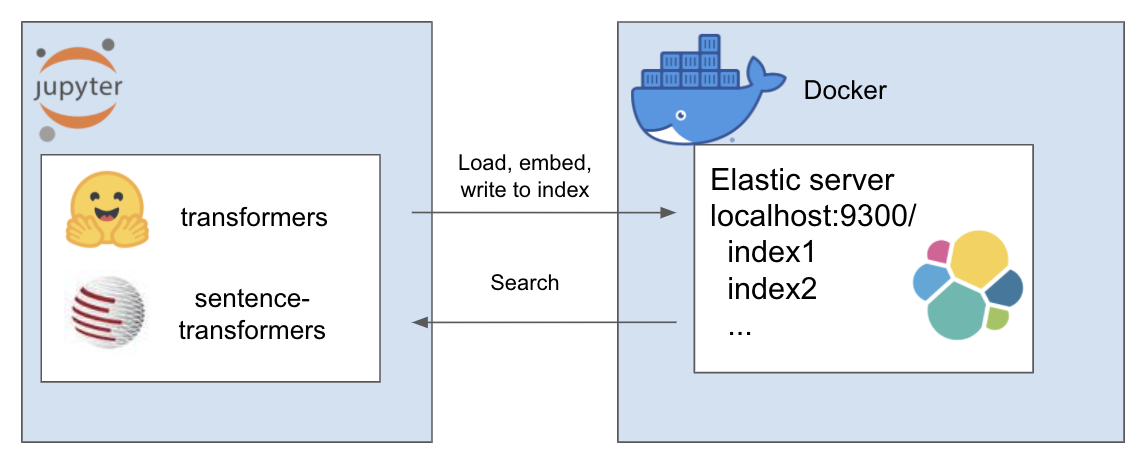
การตั้งค่าข้างต้นทำงานดังนี้
สภาพแวดล้อมของฉันเรียกว่า et และฉันใช้ conda สำหรับสิ่งนี้ นำทางภายในไดเรกทอรีโครงการ
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtสำหรับบทช่วยสอนนี้ ฉันใช้ A Million News Headlines โดย Rohk และวางไว้ในโฟลเดอร์ข้อมูลภายใน dir ของโครงการ
elastic_transformers/
├── data/
คุณจะพบว่าขั้นตอนต่างๆ ค่อนข้างเป็นนามธรรม ดังนั้นคุณจึงสามารถดำเนินการนี้กับชุดข้อมูลที่คุณเลือกได้
ทำตามคำแนะนำในการตั้งค่า Elastic ด้วย Docker จากหน้าของ Elastic ที่นี่ สำหรับบทช่วยสอนนี้ คุณจะต้องดำเนินการเพียงสองขั้นตอนเท่านั้น:
repo แนะนำคลาส ElasiticTransformers ยูทิลิตี้ที่ช่วยสร้าง จัดทำดัชนี และสืบค้นดัชนี Elasticsearch ซึ่งรวมถึงการฝัง
เริ่มต้นลิงก์การเชื่อมต่อตลอดจน (ทางเลือก) ชื่อของดัชนีที่จะใช้งาน
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec กำหนดการแมปสำหรับดัชนี รายการฟิลด์ที่เกี่ยวข้องสามารถระบุได้สำหรับการค้นหาคำหลักหรือการค้นหาความหมาย (เวกเตอร์หนาแน่น) นอกจากนี้ยังมีพารามิเตอร์สำหรับขนาดของเวกเตอร์หนาแน่นเนื่องจากสามารถเปลี่ยนแปลง create_index - ใช้ข้อมูลจำเพาะที่สร้างขึ้นก่อนหน้านี้เพื่อสร้างดัชนีที่พร้อมสำหรับการค้นหา
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - แบ่งไฟล์ csv ขนาดใหญ่ออกเป็นชิ้น ๆ และใช้ยูทิลิตี้การฝังที่กำหนดไว้ล่วงหน้าซ้ำ ๆ เพื่อสร้างรายการการฝังสำหรับแต่ละชิ้นและต่อมาป้อนผลลัพธ์ไปยังดัชนี
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )ค้นหา - อนุญาตให้เลือกคำหลัก ('จับคู่' ใน Elastic) หรือการค้นหาเชิงความหมาย (หนาแน่นใน Elastic) โดยเฉพาะอย่างยิ่ง ต้องใช้ฟังก์ชันการฝังแบบเดียวกับที่ใช้ใน write_large_csv
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )หลังจากตั้งค่าสำเร็จแล้ว ให้ใช้สมุดบันทึกต่อไปนี้เพื่อทำให้ทั้งหมดนี้ใช้งานได้
การซื้อคืนนี้รวมเอาผลงานที่น่าทึ่งต่อไปนี้โดยคนเก่งๆ เข้าด้วยกัน โปรดตรวจสอบผลงานของพวกเขาหากคุณยังไม่ได้ดำเนินการ...


