VSA
1.0.0
[หน้าโครงการ] [?กระดาษ] [?Hugging Face Space] [สวนสัตว์จำลอง] [บทนำ] [?วิดีโอ]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
การสาธิตในพื้นที่นั้นใช้ gradio และคุณสามารถรันด้วย:
python app.py
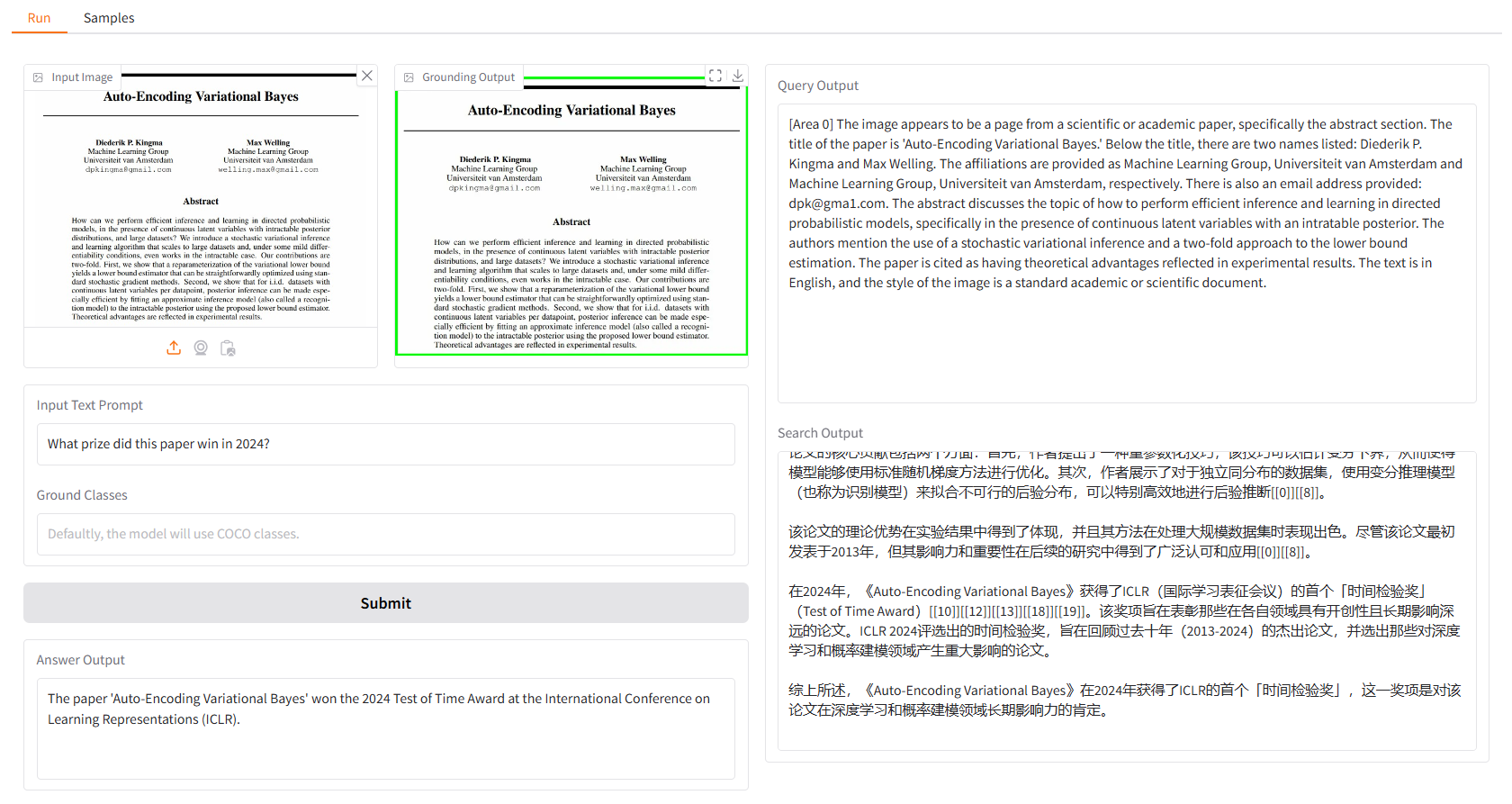
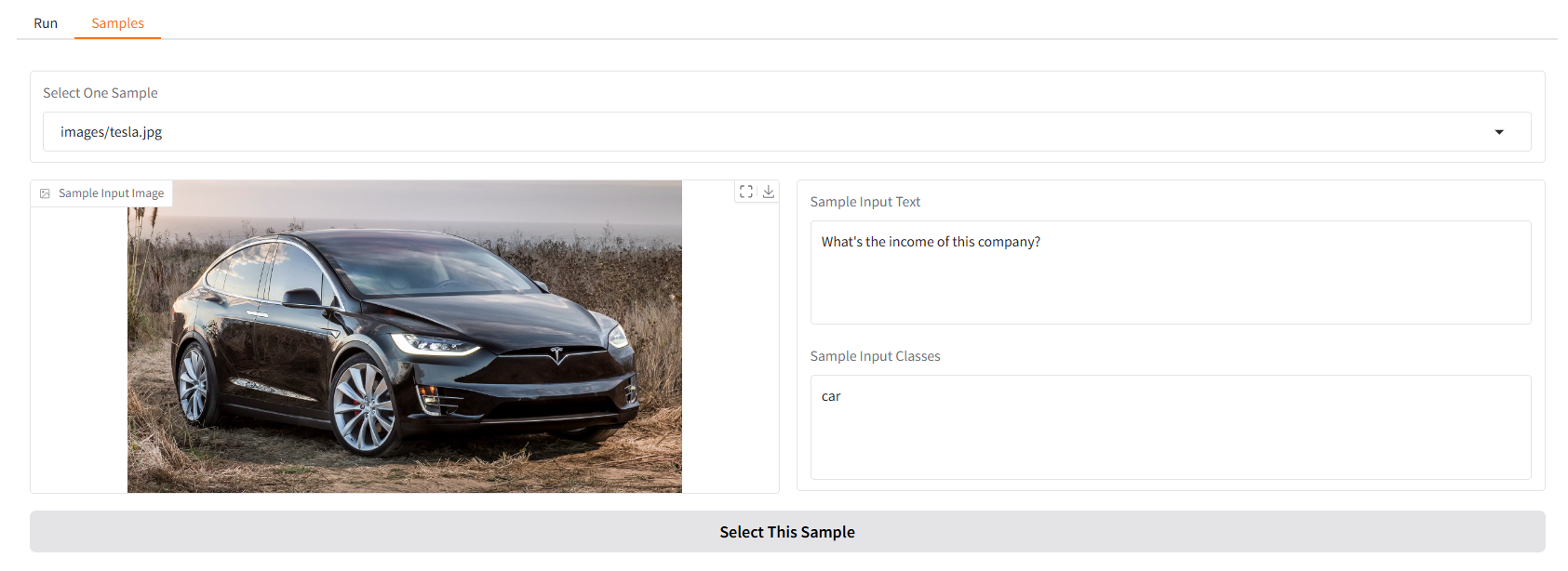
เราจัดเตรียมตัวอย่างบางส่วนไว้ให้คุณเริ่มต้น ใน UI "ตัวอย่าง" คุณสามารถเลือกรายการใดรายการหนึ่งได้ในแผง "ตัวอย่าง" คลิก "เลือกตัวอย่างนี้" และคุณจะพบว่าอินพุตตัวอย่างได้รับการกรอกแล้วใน UI "เรียกใช้"
คุณยังสามารถแชทกับ Vision Search Assistant ของเราในเทอร์มินัลได้ด้วยการเรียกใช้
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
จากนั้นเลือกรูปภาพและพิมพ์คำถามของคุณ
โครงการนี้เผยแพร่ภายใต้ลิขสิทธิ์ Apache 2.0
Vision Search Assistant ได้รับแรงบันดาลใจอย่างมากจากการมีส่วนร่วมที่โดดเด่นต่อไปนี้ในชุมชนโอเพ่นซอร์ส: GroundingDINO, LLaVA, MindSearch
หากคุณพบว่าโครงการนี้มีประโยชน์ในการวิจัยของคุณ โปรดพิจารณาอ้างอิง:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


