ndvr
1.0.0
อันดับที่ 2 สำหรับ Neural Search Hackathon ?
เราได้เห็นการเติบโตอย่างรวดเร็วของข้อมูลวิดีโอในเว็บไซต์แบ่งปันวิดีโอที่หลากหลาย โดยมีวิดีโอนับพันล้านรายการอยู่บนอินเทอร์เน็ต จึงกลายเป็นความท้าทายที่สำคัญในการเรียกค้นวิดีโอที่เกือบจะซ้ำซ้อน (NDVR) จากฐานข้อมูลวิดีโอขนาดใหญ่ NDVR มุ่งหวังที่จะดึงข้อมูลวิดีโอที่เกือบจะซ้ำกันจากฐานข้อมูลวิดีโอขนาดใหญ่ โดยที่วิดีโอที่เกือบจะซ้ำกันนั้นถูกกำหนดให้เป็นวิดีโอที่มองเห็นได้ใกล้เคียงกับวิดีโอต้นฉบับ
ผู้ใช้มีแรงจูงใจอย่างมากในการคัดลอกวิดีโอสั้นที่กำลังมาแรงและอัปโหลดเวอร์ชันเสริมเพื่อดึงดูดความสนใจ ด้วยการเติบโตของวิดีโอสั้น ปัญหาและความท้าทายใหม่ในการตรวจจับวิดีโอสั้นที่เกือบจะซ้ำกันก็ปรากฏขึ้น
ที่นี่ เราได้สร้างโซลูชัน Neural Search โดยใช้ Jina เพื่อแก้ปัญหาความท้าทายของ NDVR
สารบัญ

ตัวอย่างวิดีโอผู้สมัครเชิงบวกเชิงบวก แถวบนสุด: ด้านข้างมีรอยเปื้อน กรองสี และล้างด้วยน้ำ แถวกลาง: หน้าจอแนวนอนเปลี่ยนเป็นหน้าจอแนวตั้งโดยมีขอบสีดำขนาดใหญ่ แถว Botton: หมุนแล้ว
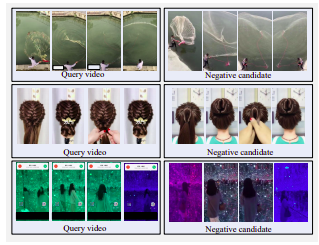
ตัวอย่างวิดีโอเชิงลบที่รุนแรง ผู้สมัครทั้งหมดจะมีลักษณะคล้ายกับแบบสอบถามแต่ไม่เกือบจะซ้ำกัน
มีสามกลยุทธ์ในการเลือกวิดีโอที่เข้าข่าย:
เราตัดสินใจใช้กลยุทธ์ Transformed Recoveryal เนื่องจากข้อจำกัดด้านเวลาและทรัพยากร ในการใช้งานจริง ผู้ใช้จะคัดลอกวิดีโอที่กำลังมาแรงเพื่อจูงใจส่วนตัว ผู้ใช้มักจะเลือกที่จะแก้ไขวิดีโอที่คัดลอกไว้เล็กน้อยเพื่อหลีกเลี่ยงการตรวจจับ การแก้ไขเหล่านี้ประกอบด้วยการครอบตัดวิดีโอ การแทรกเส้นขอบ และอื่นๆ
เพื่อเลียนแบบพฤติกรรมของผู้ใช้ดังกล่าว เราให้คำจำกัดความของการเปลี่ยนแปลงชั่วคราวอย่างหนึ่ง นั่นคือ การเร่งความเร็วของวิดีโอ และการแปลงเชิงพื้นที่สามแบบ ได้แก่ การครอบตัดวิดีโอ การแทรกเส้นขอบสีดำ และการหมุนวิดีโอ
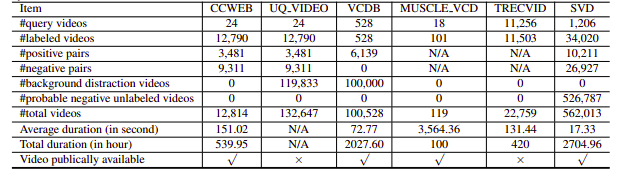
น่าเสียดายที่ชุดข้อมูล NDVR ที่ทำการวิจัยนั้นมีความละเอียดต่ำ หรือมีจำนวนมาก หรือเฉพาะโดเมน หรือไม่พร้อมใช้งานแบบสาธารณะ (เราติดต่อเป็นการส่วนตัวบางส่วนเช่นกัน) ดังนั้นเราจึงตัดสินใจสร้างชุดข้อมูลขนาดเล็กที่กำหนดเองเพื่อทำการทดลอง
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexดัชนีโฟลถูกกำหนดดังนี้:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueสิ่งนี้แบ่งออกเป็นขั้นตอนต่อไปนี้:
ที่นี่เราใช้ไฟล์ YAML เพื่อกำหนดโฟลว์และใช้เพื่อจัดทำดัชนีข้อมูล ฟังก์ชัน index ใช้พารามิเตอร์ input_fn ซึ่งใช้ Iterator เพื่อส่งผ่านพาธของไฟล์ ซึ่งจะถูกห่อเพิ่มเติมใน IndexRequest และส่งไปยัง Flow
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query จากนั้นคุณสามารถเปิด Jinabox ด้วยจุดสิ้นสุดที่กำหนดเอง http://localhost:45678/api/search
คิวรี Flow มีการกำหนดดังนี้:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlขั้นตอนการสืบค้นแบ่งออกเป็นขั้นตอนต่อไปนี้:


