CrawlerTutorial
1.0.0
เมื่อเราท่องอินเทอร์เน็ต เรามักจะเห็นเนื้อหาที่น่าสนใจหลากหลาย เช่น ข่าวสาร สินค้า วีดีโอ รูปภาพ เป็นต้น แต่หากคุณต้องการรวบรวมข้อมูลเฉพาะจำนวนมากจากหน้าเว็บเหล่านี้ การดำเนินการด้วยตนเองจะใช้เวลานานและลำบาก
ขณะนี้โปรแกรมรวบรวมข้อมูลเว็บ (Web Crawler) มีประโยชน์มาก! พูดง่ายๆ ก็คือโปรแกรมรวบรวมข้อมูลเว็บคือโปรแกรมที่สามารถเลียนแบบพฤติกรรมของเบราว์เซอร์ของมนุษย์และรวบรวมข้อมูลเว็บโดยอัตโนมัติ การใช้ความสามารถอัตโนมัติของโปรแกรมนี้ทำให้เราสามารถ "รวบรวมข้อมูล" ข้อมูลที่เราสนใจจากเว็บไซต์ได้อย่างง่ายดาย จากนั้นจึงจัดเก็บข้อมูลนี้ไว้เพื่อการวิเคราะห์ในภายหลัง
วิธีการทำงานของโปรแกรมรวบรวมข้อมูลเว็บโดยปกติคือส่งคำขอ HTTP ไปยังเว็บไซต์เป้าหมายก่อน จากนั้นจึงรับการตอบกลับ HTML จากเว็บไซต์ แยกวิเคราะห์เนื้อหาของหน้า จากนั้นจึงแยกข้อมูลที่เป็นประโยชน์ ตัวอย่างเช่น หากเราต้องการรวบรวมชื่อเรื่อง ผู้แต่ง เวลา และข้อมูลอื่น ๆ ของบทความบนกระดานซุบซิบของ PTT เราสามารถใช้เทคโนโลยีโปรแกรมรวบรวมข้อมูลเว็บเพื่อรวบรวมข้อมูลนี้และจัดเก็บโดยอัตโนมัติ วิธีนี้ทำให้คุณสามารถรับข้อมูลที่ต้องการได้โดยไม่ต้องเข้าดูเว็บไซต์ด้วยตนเอง
โปรแกรมรวบรวมข้อมูลเว็บมีแอปพลิเคชันที่เป็นประโยชน์มากมาย เช่น:
แน่นอนว่าเมื่อใช้โปรแกรมรวบรวมข้อมูลเว็บ เราต้องปฏิบัติตามข้อกำหนดการใช้งานและนโยบายความเป็นส่วนตัวของเว็บไซต์ และไม่สามารถรวบรวมข้อมูลที่ละเมิดกฎระเบียบของเว็บไซต์ได้ ในเวลาเดียวกัน เพื่อให้เว็บไซต์ทำงานได้ตามปกติ เรายังจำเป็นต้องออกแบบกลยุทธ์การรวบรวมข้อมูลที่เหมาะสมเพื่อหลีกเลี่ยงการโหลดบนเว็บไซต์มากเกินไป
บทช่วยสอนนี้ใช้ Python3 และจะใช้ pip เพื่อติดตั้งแพ็คเกจที่จำเป็น จำเป็นต้องติดตั้งแพ็คเกจต่อไปนี้:
requests : ใช้เพื่อส่งและรับคำขอและการตอบกลับ HTTPrequests_html : ใช้เพื่อวิเคราะห์และรวบรวมข้อมูลองค์ประกอบใน HTMLrich : ปล่อยให้ข้อมูลถูกส่งออกไปยังคอนโซลอย่างสวยงาม เช่น การแสดงตารางที่สวยงามlxml หรือ PyQuery : ใช้เพื่อแยกวิเคราะห์องค์ประกอบใน HTMLใช้คำแนะนำต่อไปนี้เพื่อติดตั้งแพ็คเกจเหล่านี้:
pip install requests requests_html rich lxml PyQueryในบทพื้นฐานเราจะแนะนำวิธีการรวบรวมข้อมูลจากหน้าเว็บ ปตท. เช่น ชื่อบทความ ผู้แต่ง และเวลาโดยย่อ
ลองใช้บทความอ่านเวอร์ชันของ ปตท. เป็นเป้าหมายของโปรแกรมรวบรวมข้อมูลของเรา!
เมื่อรวบรวมข้อมูลหน้าเว็บ เราจะใช้ฟังก์ชัน requests.get() เพื่อจำลองเบราว์เซอร์ที่ส่งคำขอ HTTP GET เพื่อ "เรียกดู" หน้าเว็บ ฟังก์ชั่นนี้จะส่งคืนวัตถุ requests.Response ซึ่งมีเนื้อหาตอบกลับของหน้าเว็บ อย่างไรก็ตาม ควรสังเกตว่าเนื้อหานี้นำเสนอในรูปแบบของซอร์สโค้ดข้อความล้วน และไม่ได้แสดงผลโดยเบราว์เซอร์ เราสามารถรับมันผ่านคุณสมบัติ response.text
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
ในการใช้งานครั้งต่อไป เราจะต้องใช้ requests_html เพื่อขยาย requests นอกเหนือจากการเรียกดูแบบเบราว์เซอร์แล้ว เรายังต้องแยกวิเคราะห์หน้าเว็บ HTML อีกด้วย requests_html จะรวม response.text ข้อความธรรมดาลงใน requests_html.HTML เพื่อใช้ในภายหลัง การเขียนใหม่นั้นง่ายมาก ใช้ session.get() เพื่อแทนที่ requests.get() ข้างต้น
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )อย่างไรก็ตาม เมื่อเราพยายามนำวิธีนี้ไปใช้กับ Gossiping เราอาจพบข้อผิดพลาด เนื่องจากเมื่อเราเปิดดูกระดานซุบซิบเป็นครั้งแรก เว็บไซต์จะยืนยันว่าเราอายุเกิน 18 ปีหรือไม่ เมื่อเราคลิกเพื่อยืนยัน เบราว์เซอร์จะบันทึกคุกกี้ที่เกี่ยวข้อง เพื่อที่เราจะไม่ถามอีกในครั้งต่อไปที่เรา เข้าสู่ (คุณสามารถลองใช้โหมดไม่ระบุตัวตนเพื่อเปิดการทดสอบและดูที่หน้าแรกของเวอร์ชัน Bagua) อย่างไรก็ตาม สำหรับโปรแกรมรวบรวมข้อมูลเว็บ เราจำเป็นต้องบันทึกคุกกี้พิเศษนี้ เพื่อที่เราจะได้แกล้งทำเป็นว่าผ่านการทดสอบอายุสิบแปดปีในขณะท่องเว็บ
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) ต่อไป เราสามารถใช้เมธอด response.html.find() เพื่อค้นหาองค์ประกอบ และใช้ตัวเลือก CSS เพื่อระบุองค์ประกอบเป้าหมาย ในขั้นตอนนี้ เราจะสังเกตได้ว่าในเวอร์ชันเว็บของ PTT ข้อมูลชื่อเรื่องของแต่ละบทความจะอยู่ในแท็ก div พร้อมด้วยหมวดหมู่ r-ent ดังนั้นเราจึงสามารถใช้ตัวเลือก CSS div.r-ent เพื่อกำหนดเป้าหมายองค์ประกอบเหล่านี้ได้
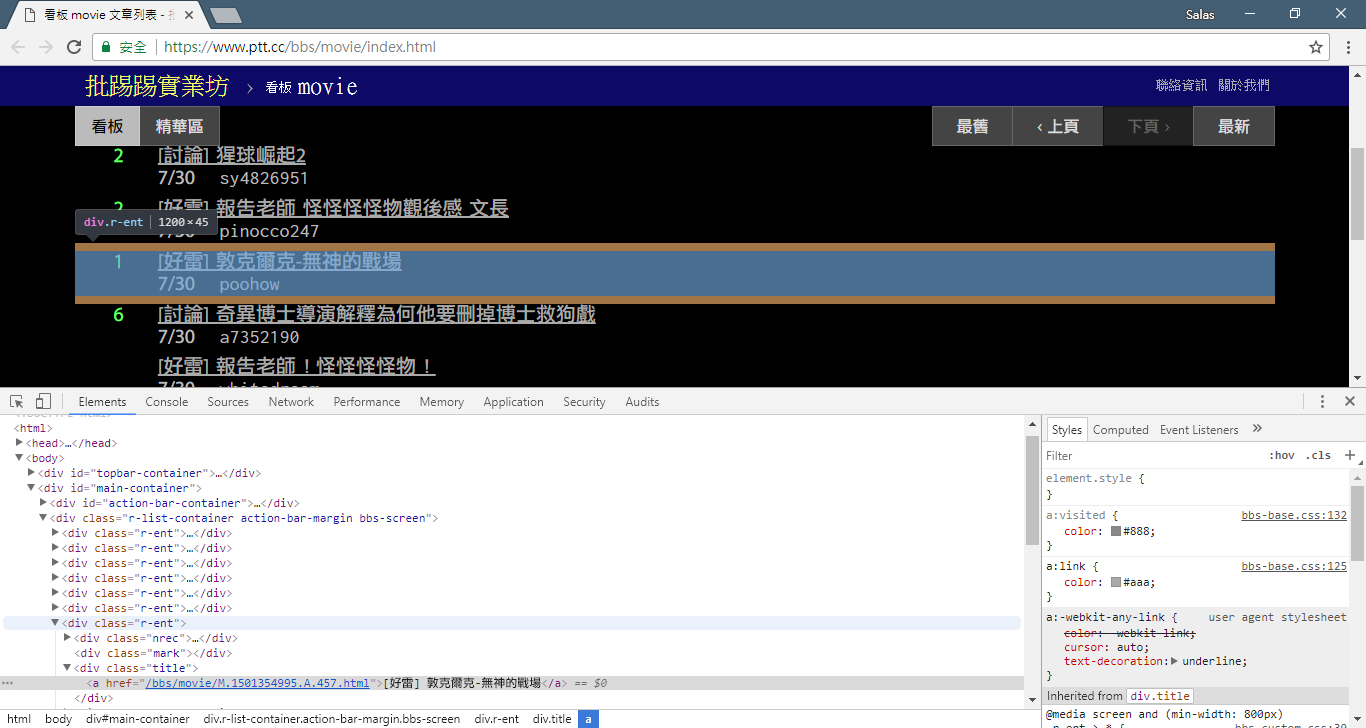
การใช้เมธอด response.html.find() จะส่งคืนรายการองค์ประกอบที่ตรงตามเงื่อนไข ดังนั้นเราจึงสามารถใช้ for loop เพื่อประมวลผลองค์ประกอบเหล่านี้ทีละรายการ ภายในแต่ละองค์ประกอบ เราสามารถใช้เมธอด element.find() เพื่อแยกวิเคราะห์องค์ประกอบเพิ่มเติม และใช้ตัวเลือก CSS เพื่อระบุข้อมูลที่จะแยกออกมา ในตัวอย่างนี้ เราสามารถใช้ตัวเลือก CSS div.title เพื่อกำหนดเป้าหมายองค์ประกอบชื่อได้ ในทำนองเดียวกัน เราสามารถใช้คุณสมบัติ element.text เพื่อรับเนื้อหาข้อความขององค์ประกอบได้
นี่คือโค้ดตัวอย่างโดยใช้ requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... ในขั้นตอนที่แล้ว เราใช้เมธอด response.html.find() เพื่อค้นหาองค์ประกอบของแต่ละบทความ องค์ประกอบเหล่านี้กำหนดเป้าหมายโดยใช้ตัวเลือก CSS div.r-ent คุณสามารถใช้คุณลักษณะเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์เพื่อดูโครงสร้างองค์ประกอบของหน้าเว็บได้ หลังจากเปิดหน้าเว็บและกดปุ่ม F12 แผงเครื่องมือสำหรับนักพัฒนาจะปรากฏขึ้น ซึ่งประกอบด้วยโครงสร้าง HTML ของหน้าเว็บและข้อมูลอื่นๆ
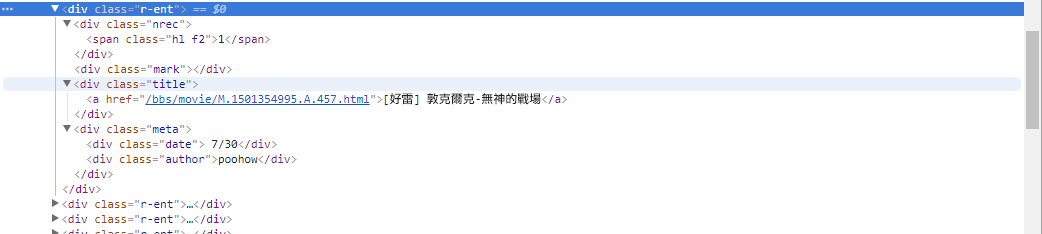
เมื่อใช้เครื่องมือสำหรับนักพัฒนา คุณสามารถใช้ตัวชี้เมาส์เพื่อเลือกองค์ประกอบเฉพาะบนเว็บเพจ จากนั้นดูโครงสร้าง HTML, คุณลักษณะ CSS และรายละเอียดอื่นๆ ขององค์ประกอบในแผงเครื่องมือสำหรับนักพัฒนา ซึ่งช่วยให้คุณกำหนดองค์ประกอบที่จะกำหนดเป้าหมายและตัวเลือก CSS ที่เกี่ยวข้องได้ นอกจากนี้คุณอาจพบว่าเหตุใดบางครั้งโปรแกรมจึงผิดพลาด - เมื่อดูเวอร์ชันเว็บ ฉันพบว่าเมื่อบทความบนเพจถูกลบ結構ซอร์สโค้ดขององค์ประกอบ <本文已被刪除> บนหน้าเว็บแตกต่างจากต้นฉบับ! ดังนั้นเราจึงสามารถเสริมความแข็งแกร่งให้มากขึ้นเพื่อรับมือกับสถานการณ์ที่บทความถูกลบ
ตอนนี้ กลับไปที่โค้ดตัวอย่างสำหรับการดึงข้อมูลโดยใช้ requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )การประมวลผลคำเอาท์พุต:
ที่นี่เราสามารถใช้ rich เพื่อแสดงผลลัพธ์ที่สวยงาม ขั้นแรก สร้างวัตถุตาราง rich จากนั้นแทนที่ print ในลูปของโค้ดตัวอย่างด้านบนด้วย add_row ลงในตาราง สุดท้ายนี้ เราใช้ฟังก์ชัน print ของ rich เพื่อส่งออกตารางไปยังเทอร์มินัลอย่างถูกต้อง
ผลการดำเนินการ
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )
ตอนนี้เราจะใช้ "วิธีการสังเกต" เพื่อค้นหาลิงก์ไปยังหน้าที่แล้ว ไม่ ฉันไม่ได้ถามคุณว่าปุ่มอยู่ที่ไหนบนเบราว์เซอร์ของคุณ แต่ถามว่า "แผนผังต้นทาง" ในเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ ฉันเชื่อว่าคุณได้ค้นพบว่าไฮเปอร์ลิงก์สำหรับการข้ามหน้านั้นอยู่ในองค์ประกอบ <a class="btn wide"> ของ <div class="action-bar"> ดังนั้นเราจึงสามารถแยกพวกมันออกมาได้ดังนี้:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )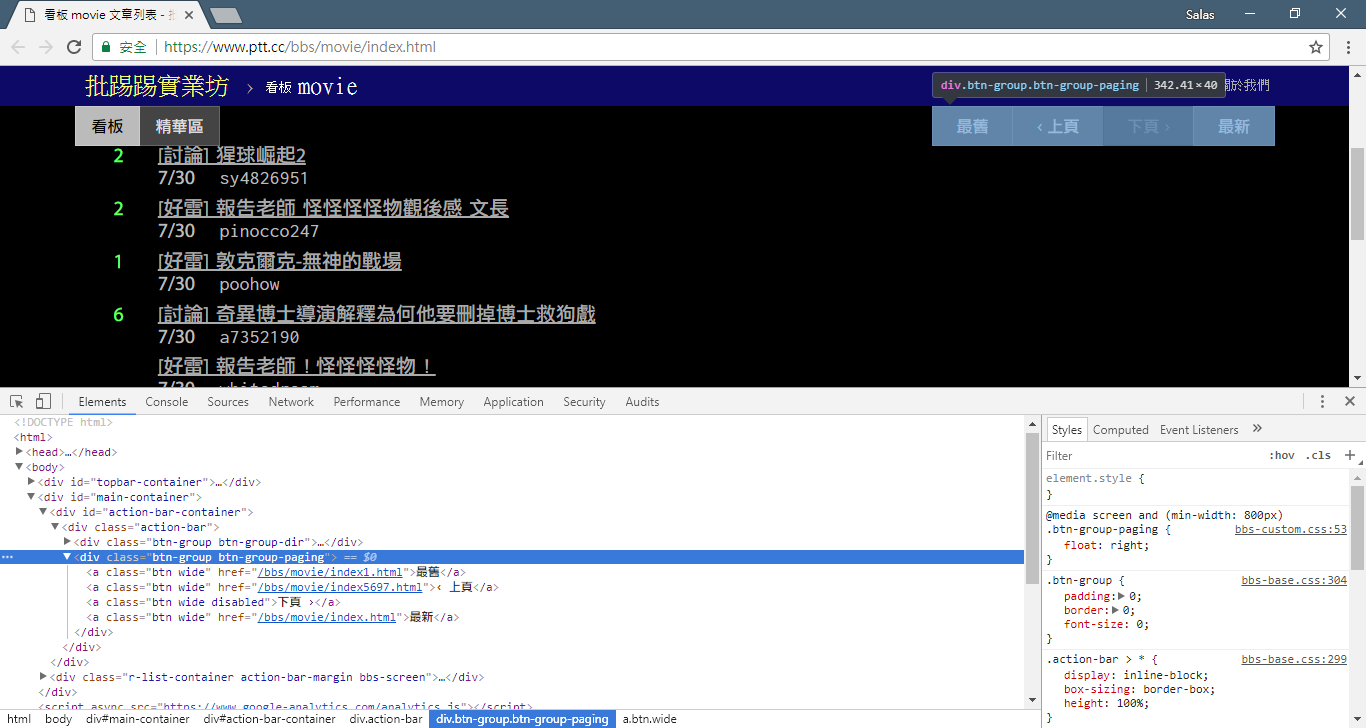
สิ่งที่เราต้องการคือฟังก์ชั่น "หน้าก่อนหน้า" เพราะบทความล่าสุดใน ปตท. จะแสดงอยู่ด้านหน้า ดังนั้น หากต้องการขุดข้อมูลต้องเลื่อนไปข้างหน้า
แล้วจะใช้งานยังไงล่ะ? ขั้นแรกให้คว้า href ที่สองใน control (ดัชนีคือ 1) จากนั้นอาจมีลักษณะเช่นนี้ /bbs/movie/index3237.html ; และที่อยู่เว็บไซต์ที่สมบูรณ์ (URL) จะต้องเป็น https://www.ptt.cc/ ( url โดเมน) ดังนั้นให้ใช้ urljoin() (หรือการเชื่อมต่อสตริงโดยตรง) เพื่อเปรียบเทียบและรวมลิงก์หน้าแรกของภาพยนตร์กับลิงก์ใหม่ให้เป็น URL ที่สมบูรณ์!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url ตอนนี้เรามาจัดเรียงฟังก์ชันใหม่เพื่ออำนวยความสะดวกในการอธิบายในภายหลัง เรามาเปลี่ยนตัวอย่างการประมวลผลแต่ละองค์ประกอบของบทความในขั้นตอนที่ 3: มาดูข้อความชื่อเรื่องเหล่านี้เป็นฟังก์ชันอิสระ parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsต่อไป เราสามารถจัดการเนื้อหาที่มีหลายหน้าได้
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlผลลัพธ์ที่ได้:
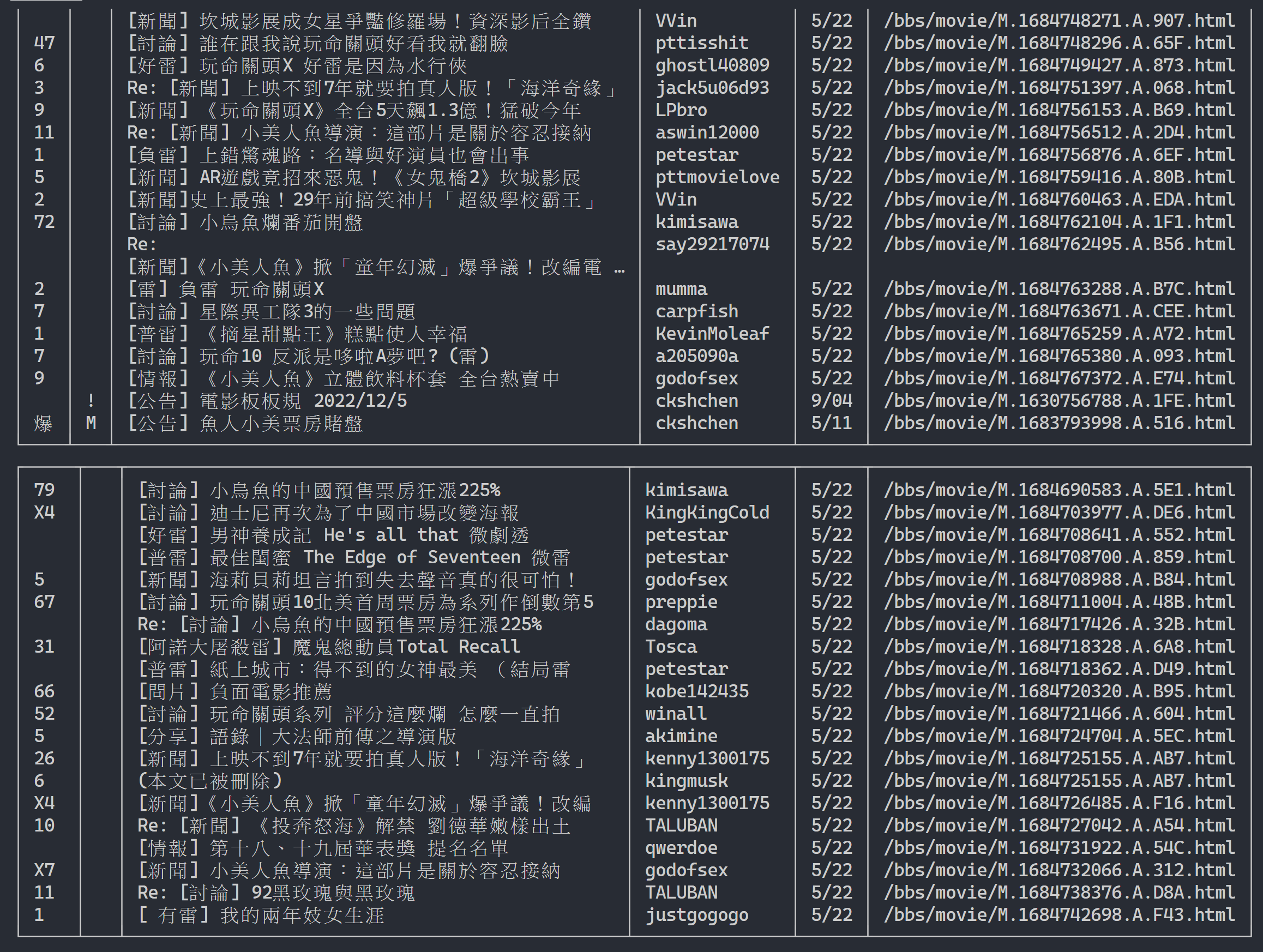
หลังจากได้รับข้อมูลรายการบทความแล้ว ขั้นตอนต่อไปคือการได้รับเนื้อหาบทความ (บทความ PO) (เนื้อหาโพสต์)! link ในข้อมูลเมตาคือลิงก์ของแต่ละบทความ เรายังใช้ urllib.parse.urljoin เพื่อเชื่อม URL ที่สมบูรณ์ จากนั้นออก HTTP GET เพื่อรับเนื้อหาของบทความ เราจะสังเกตได้ว่างานจับเนื้อหาของแต่ละบทความมีความซ้ำซ้อนมากและเหมาะมากสำหรับการประมวลผลโดยใช้วิธีการแบบขนาน
ใน Python คุณสามารถใช้ multiprocessing.Pool เพื่อทำการเขียนโปรแกรมหลายตัวประมวลผลระดับสูง ~ นี่เป็นวิธีที่ง่ายที่สุดในการใช้หลายกระบวนการใน Python! เหมาะมากสำหรับสถานการณ์การใช้งาน SIMD (คำสั่งเดียวหลายข้อมูล) ใช้ไวยากรณ์คำสั่ง with เพื่อเผยแพร่ทรัพยากรกระบวนการโดยอัตโนมัติหลังการใช้งาน การใช้งาน ProcessPool นั้นง่ายมากเช่นกัน pool.map(function, items) ซึ่งคล้ายกับแนวคิดของการเขียนโปรแกรมเชิงฟังก์ชันเล็กน้อย ใช้ฟังก์ชันกับแต่ละรายการ และสุดท้ายจะได้รายการผลลัพธ์จำนวนเท่ากันกับรายการ
ใช้ในงานรวบรวมข้อมูลเนื้อหาบทความที่แนะนำก่อนหน้านี้:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )สิ่งที่แนบมานี้คือผลการทดลอง:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章จะเห็นได้ว่าความเร็วในการดำเนินการโดยรวมเพิ่มขึ้นเกือบห้าเท่า แต่ยิ่งมี Process มากเท่าไรก็ยิ่งดีเท่านั้น นอกเหนือจากข้อกำหนดด้านฮาร์ดแวร์ เช่น CPU แล้ว ส่วนใหญ่ยังขึ้นอยู่กับข้อจำกัดของอุปกรณ์ภายนอก เช่น การ์ดเครือข่ายและ ความเร็วเครือข่าย
โค้ดด้านบนสามารถพบได้ใน ( src/basic_crawler.py )!
ฟีเจอร์ใหม่ในเว็บ ปตท.: ค้นหา! ในที่สุดก็มีให้บริการบนเวอร์ชันเว็บ
มาใช้เวอร์ชันภาพยนตร์ของ PTT เป็นเป้าหมายในการรวบรวมข้อมูลของเราด้วย! เนื้อหาที่สามารถค้นหาได้ในฟีเจอร์ใหม่นี้ประกอบด้วย:
สามรายการแรกสามารถค้นหากฎจากซอร์สโค้ดของหน้าเวอร์ชันใหม่และส่งคำขอได้ แต่การค้นหาจำนวนทวีตดูเหมือนจะไม่ปรากฏในอินเทอร์เฟซ UI เวอร์ชันเว็บ ดังนั้นนี่คือพารามิเตอร์ที่ผู้เขียนขุดจาก PTT 網站原始碼โดยปกติแล้ว PTT ที่เราเรียกดูจะรวมเซิร์ฟเวอร์ BBS (นั่นคือ BBS) และเว็บเซิร์ฟเวอร์ส่วนหน้า (เวอร์ชันเว็บ) เว็บเซิร์ฟเวอร์ส่วนหน้าเขียนด้วยภาษา Go (Golang) และสามารถเข้าถึงส่วนหลังได้โดยตรง ข้อมูล BBS และการใช้งาน โหมดโต้ตอบเว็บไซต์ทั่วไปจะแสดงเนื้อหาลงในหน้าเว็บเพื่อการเรียกดู
ในความเป็นจริง การใช้ฟังก์ชันใหม่เหล่านี้ทำได้ง่ายมาก คุณเพียงต้องใช้คำขอ HTTP GET และเพิ่มสตริงการสืบค้นมาตรฐานเพื่อรับข้อมูลนี้ URL endpoint ที่มีฟังก์ชันการค้นหาคือ /bbs/{看板名稱}/search เพียงใช้คำค้นหาที่เกี่ยวข้องเพื่อรับผลการค้นหาจากที่นี่ ขั้นแรก ให้นำคีย์เวิร์ดชื่อมาเป็นตัวอย่าง
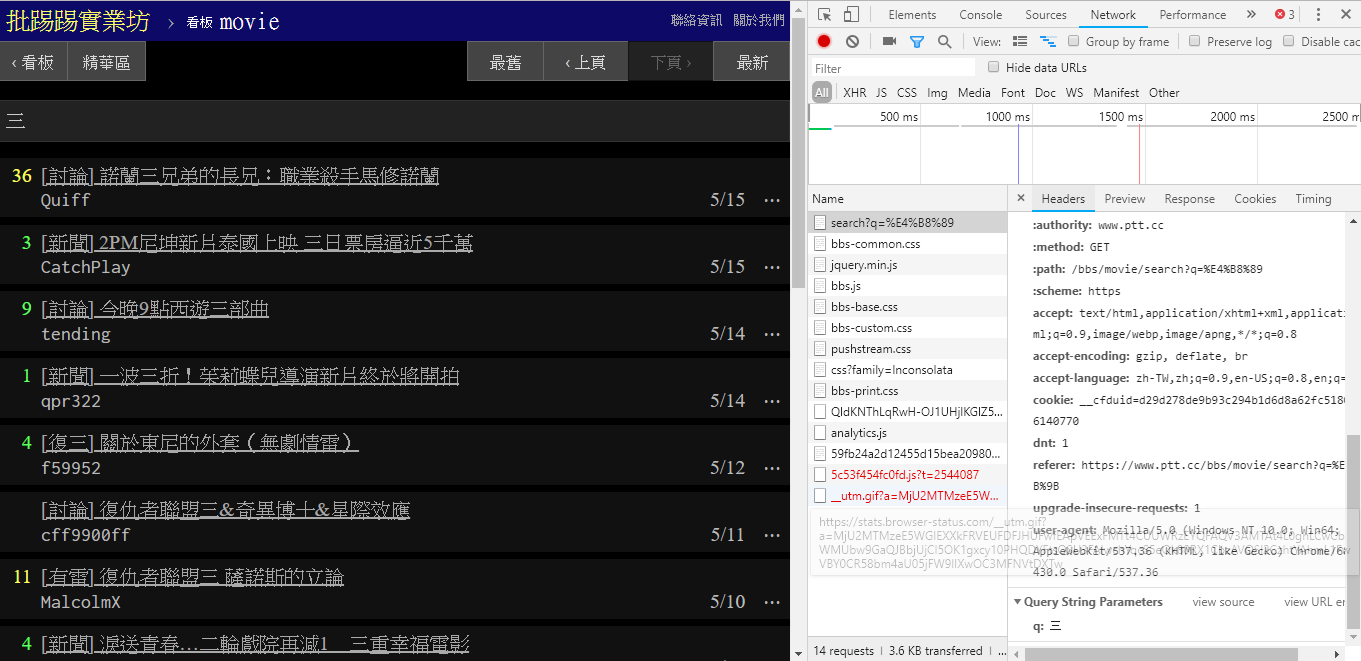
ดังที่เห็นจากมุมขวาล่างของภาพ เมื่อค้นหา คำขอ GET ที่มี q=三จะถูกส่งไป endpoint ดังนั้น URL ที่สมบูรณ์ทั้งหมดควรมีลักษณะดังนี้ https://www.ptt.cc/bbs/movie/search?q=三URL ที่คัดลอกมาจากแถบที่อยู่อาจอยู่ในรูปแบบ https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 เนื่องจากภาษาจีนมี เข้ารหัส HTML แต่แสดงถึงความหมายเดียวกัน ใน requests หากคุณต้องการเพิ่มพารามิเตอร์การสืบค้นเพิ่มเติม คุณไม่จำเป็นต้องสร้างรูปแบบสตริงด้วยตนเอง คุณเพียงแค่ต้องใส่พารามิเตอร์เหล่านั้นลงในพารามิเตอร์ฟังก์ชันผ่าน dict() ของ param= เช่นนี้
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })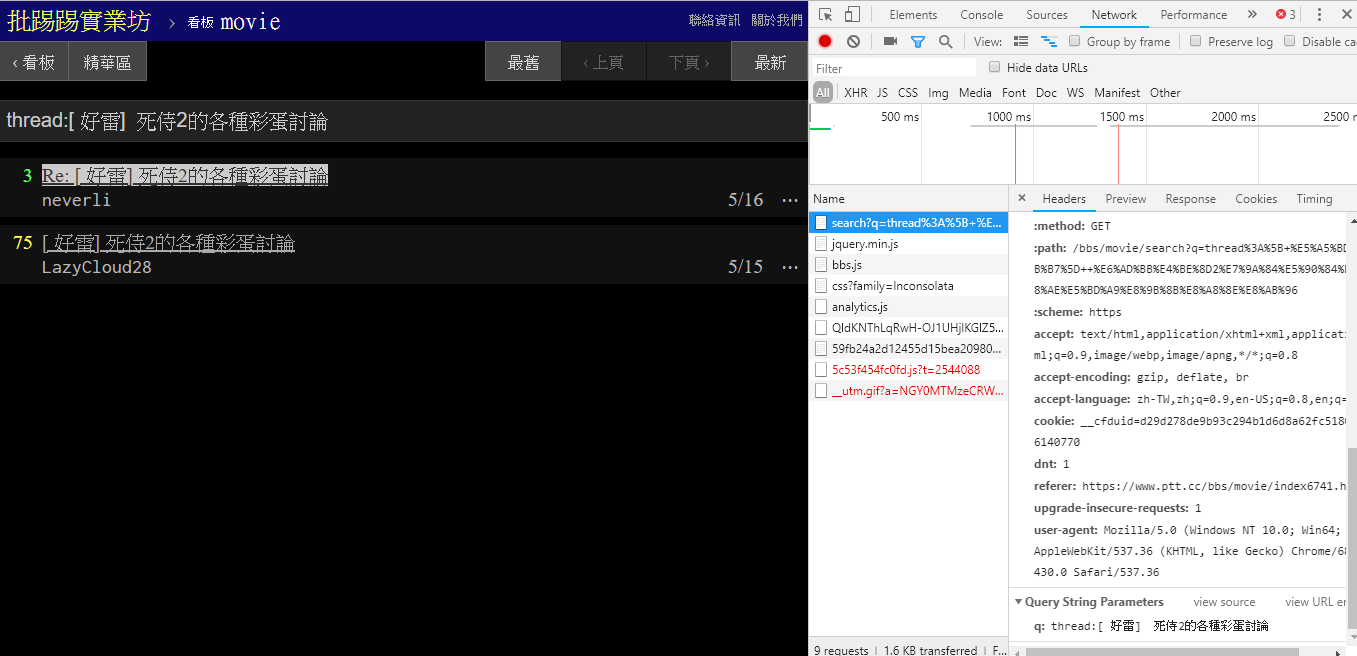
เมื่อค้นหาบทความเดียวกัน (ชุดข้อความ) คุณจะเห็นจากข้อมูลที่มุมล่างขวาว่าคุณร้อย thread: หน้าชื่อเรื่องแล้วส่งข้อความค้นหา
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })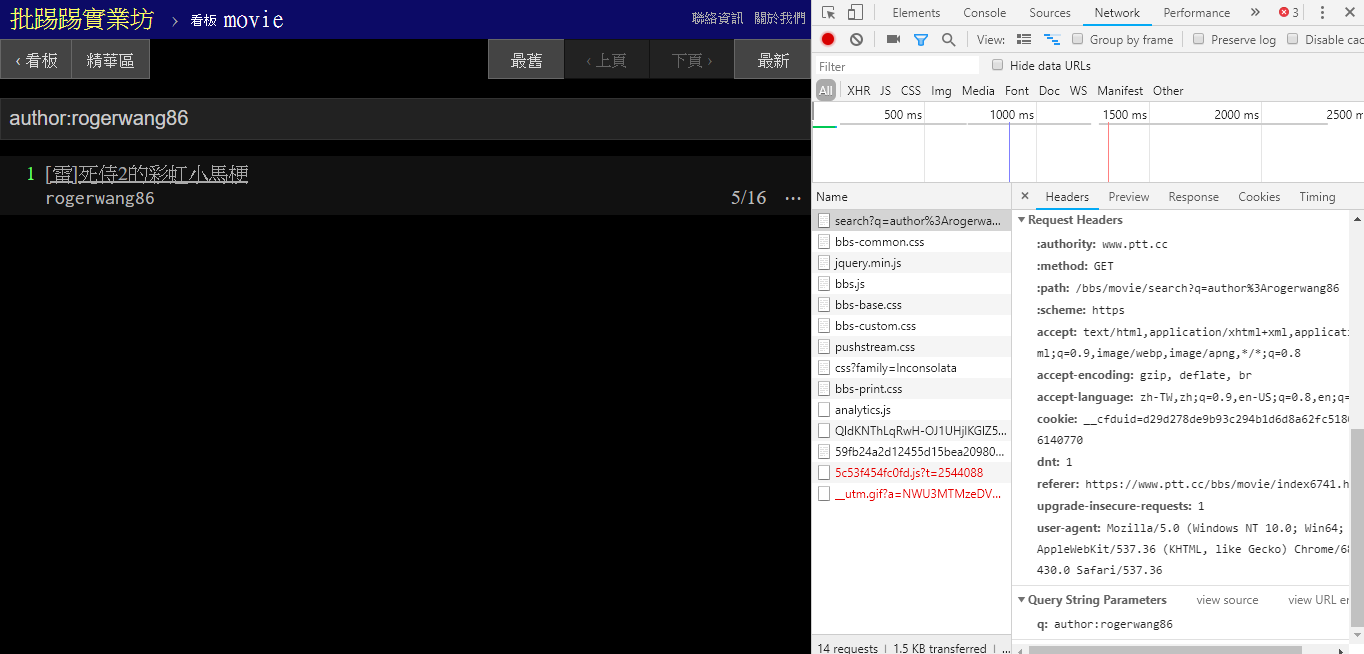
เมื่อค้นหาบทความที่มีผู้เขียนคนเดียวกัน (ผู้เขียน) สามารถดูได้จากข้อมูลที่มุมล่างขวาว่า author: สตริงเชื่อมกับชื่อผู้เขียนแล้วจึงส่งข้อความค้นหา
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })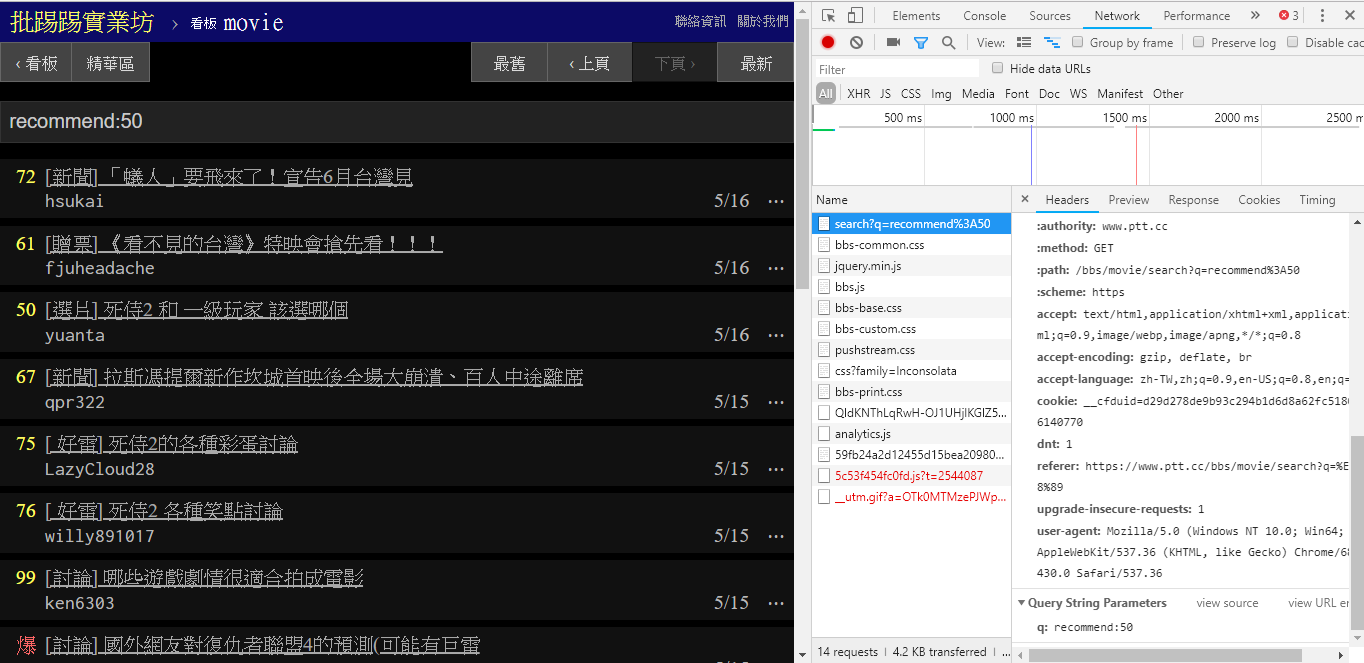
เมื่อค้นหาบทความที่มีจำนวนทวีตมากกว่า (แนะนำ) ให้สตริง recommend: ด้วยจำนวนทวีตขั้นต่ำที่คุณต้องการค้นหาแล้วส่งคำค้นหา นอกจากนี้ยังสามารถค้นหาได้จากซอร์สโค้ดของเว็บเซิร์ฟเวอร์ของ PTT ว่าจำนวนทวีตสามารถตั้งค่าได้ภายใน ±100 เท่านั้น
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })ซอร์สโค้ดฟังก์ชันการแยกวิเคราะห์เว็บปตท. ของพารามิเตอร์เหล่านี้
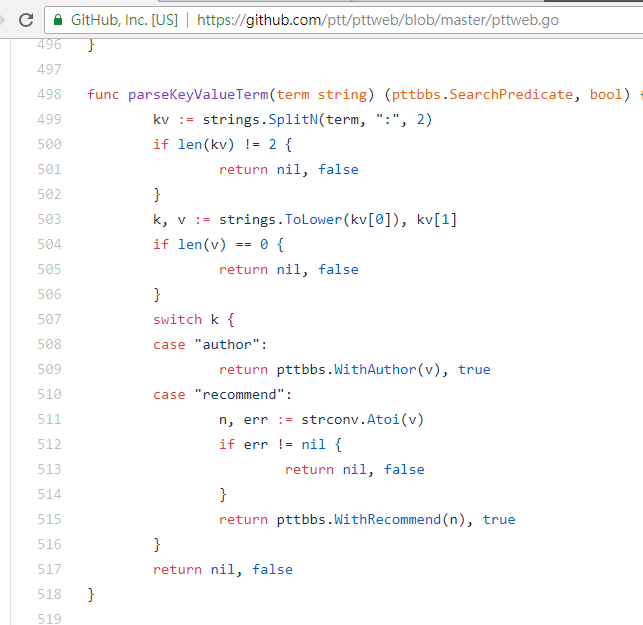
นอกจากนี้ยังควรกล่าวถึงด้วยว่าการนำเสนอผลการค้นหาขั้นสุดท้ายจะเหมือนกับรูปแบบทั่วไปที่กล่าวถึงในพื้นฐาน ดังนั้นคุณจึงสามารถใช้ฟังก์ชันก่อนหน้านี้ซ้ำได้โดยตรง Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] มีพารามิเตอร์อื่นในการค้นหา จำนวน page ก็เหมือนกับการค้นหาของ Google สิ่งที่คุณค้นหาอาจมีหลายหน้า ดังนั้น คุณสามารถใช้พารามิเตอร์เพิ่มเติมนี้เพื่อควบคุมว่าคุณต้องการรับผลลัพธ์หน้าใดโดยไม่ต้องแยกลิงก์ หน้า
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) การรวมฟังก์ชันก่อนหน้านี้ทั้งหมดเข้ากับ ptt-parser สามารถจัดเตรียมฟังก์ชันบรรทัดคำสั่งและ爬蟲ในรูปแบบของ API ที่สามารถเรียกโดยทางโปรแกรมได้
scrapy เพื่อรวบรวมข้อมูลปตท. อย่างเสถียร
งานนี้ผลิตโดย leVirve และเผยแพร่ภายใต้ Creative Commons Attribution 4.0 International License


