nnl
gpt2-xl assets
nnl เป็นเครื่องมืออนุมานสำหรับโมเดลขนาดใหญ่บนแพลตฟอร์ม GPU หน่วยความจำต่ำ
โมเดลขนาดใหญ่มีขนาดใหญ่เกินกว่าจะใส่ลงในหน่วยความจำ GPU ได้ nnl แก้ไขปัญหานี้ด้วยการแลกเปลี่ยนระหว่างแบนด์วิธ PCIE และหน่วยความจำ
ไปป์ไลน์การอนุมานทั่วไปจะเป็นดังนี้:
ด้วยพูลหน่วยความจำ GPU และการจัดเรียงข้อมูลหน่วยความจำ NNIL ทำให้สามารถอนุมานโมเดลขนาดใหญ่บนแพลตฟอร์ม GPU ระดับล่างได้
นี่เป็นเพียงโปรเจ็กต์งานอดิเรกที่เขียนขึ้นในอีกไม่กี่สัปดาห์ ปัจจุบันรองรับเฉพาะแบ็กเอนด์ CUDA เท่านั้น
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aคำสั่งนี้จะสร้างไลบรารีแบบสแตติกสองไลบรารี: lib/lib nnl _cuda.a และ lib/lib nnl _cuda_kernels.a อันแรกคือไลบรารีหลักที่มีแบ็กเอนด์ CUDA ใน C++ และอันที่สองสำหรับเคอร์เนล CUDA
โปรแกรมสาธิตของ GPT2-XL (1.6B) มีให้ที่นี่ โปรแกรมนี้สามารถคอมไพล์ได้ด้วยคำสั่งนี้:
make gpt2_1558mหลังจากดาวน์โหลดน้ำหนักทั้งหมดจากการเปิดตัว เราสามารถเรียกใช้คำสั่งต่อไปนี้บนแพลตฟอร์ม GPU ระดับล่าง เช่น GTX 1050 (หน่วยความจำ 2 GB):
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " และผลลัพธ์จะเป็นดังนี้: 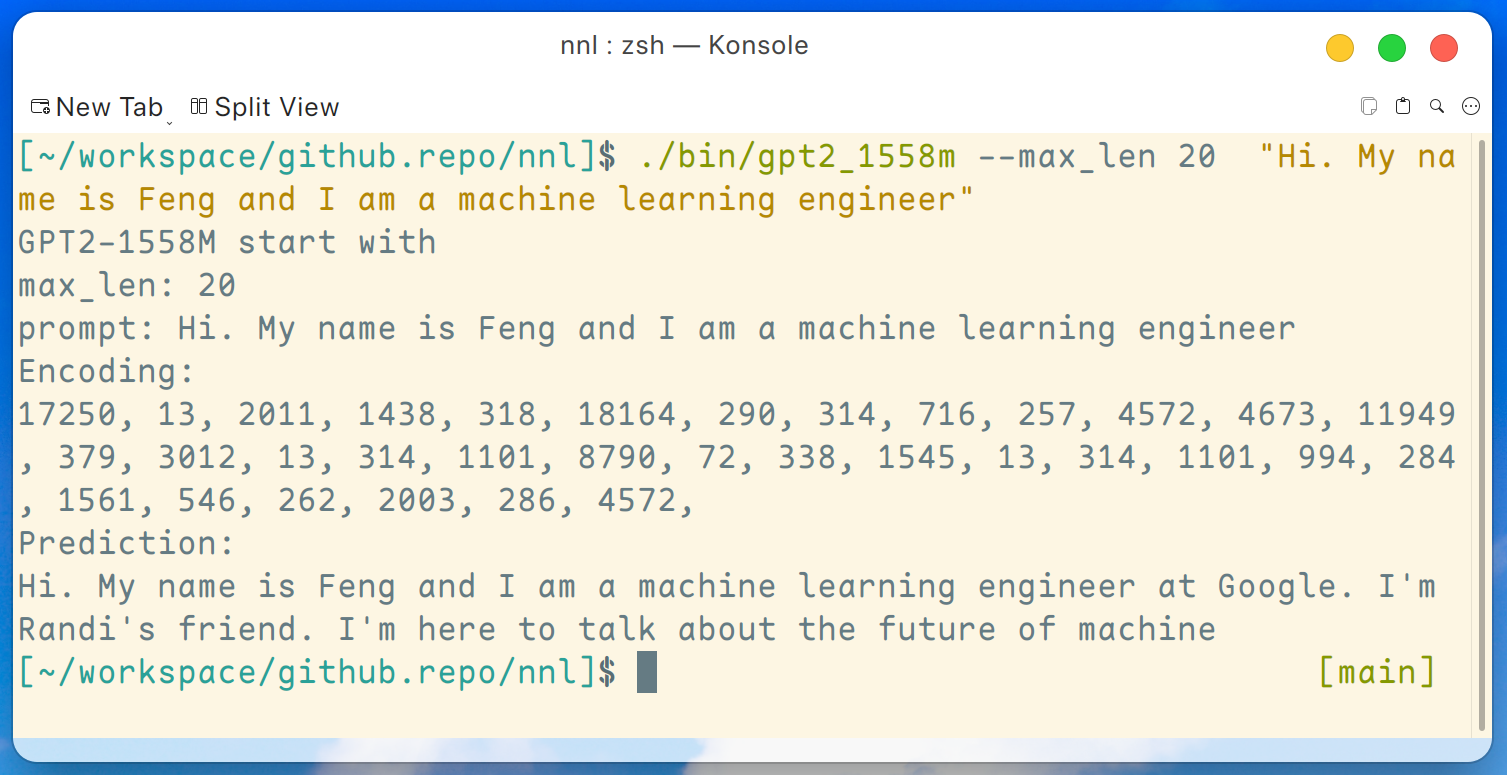
ข้อจำกัดความรับผิดชอบ: นี่เป็นเพียงตัวอย่างที่สร้างโดย gpt2-xl ฉันไม่ได้ทำงานที่ Google และฉันไม่รู้จัก Randi
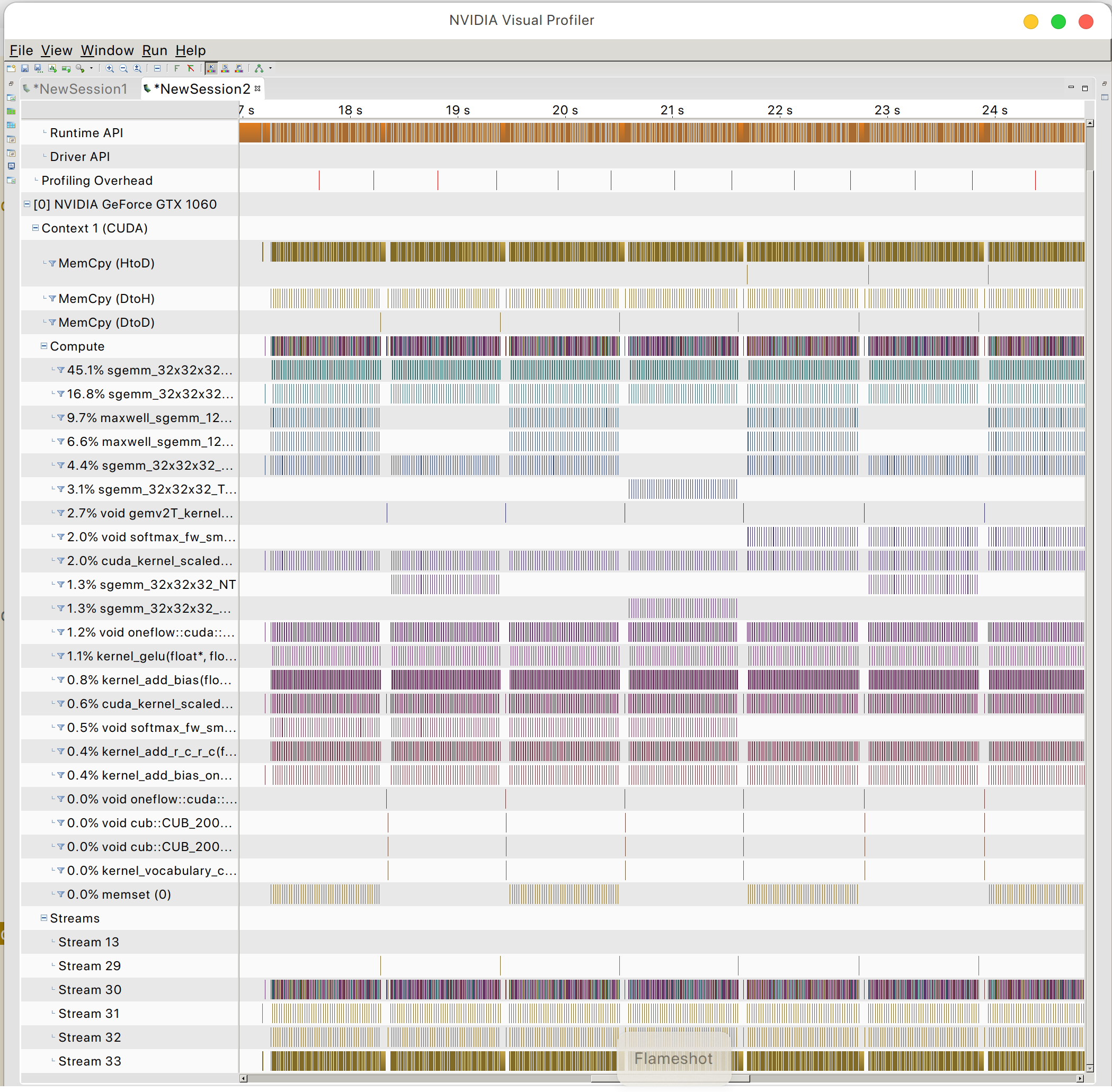
และคุณจะพบรูปแบบการเข้าถึงหน่วยความจำ GPU
สันติภาพ OSL