UniIR
1.0.0
หน้าแรก | - ชุดข้อมูล(เกณฑ์มาตรฐาน M-BEIR) | - จุดตรวจ (รุ่น UniIR ) | arXiv | GitHub
การซื้อคืนนี้มีฐานรหัสสำหรับรายงาน ECCV-2024 " UniIR : Training and Benchmarking Universal Multimodal Information Retrievers"
เราเสนอ เฟรมเวิร์ก UniIR (การดึงข้อมูลหลายรูปแบบสากล) เพื่อเรียนรู้ผู้ดึงข้อมูลเพียงตัวเดียวเพื่อบรรลุ (อาจ) งานการดึงข้อมูลใด ๆ แตกต่างจากระบบ IR แบบดั้งเดิม UniIR จำเป็นต้องปฏิบัติตามคำแนะนำในการสืบค้นที่แตกต่างกันเพื่อดึงข้อมูลจากกลุ่มผู้สมัครที่ต่างกันซึ่งมีผู้สมัครหลายล้านคนในรูปแบบที่หลากหลาย
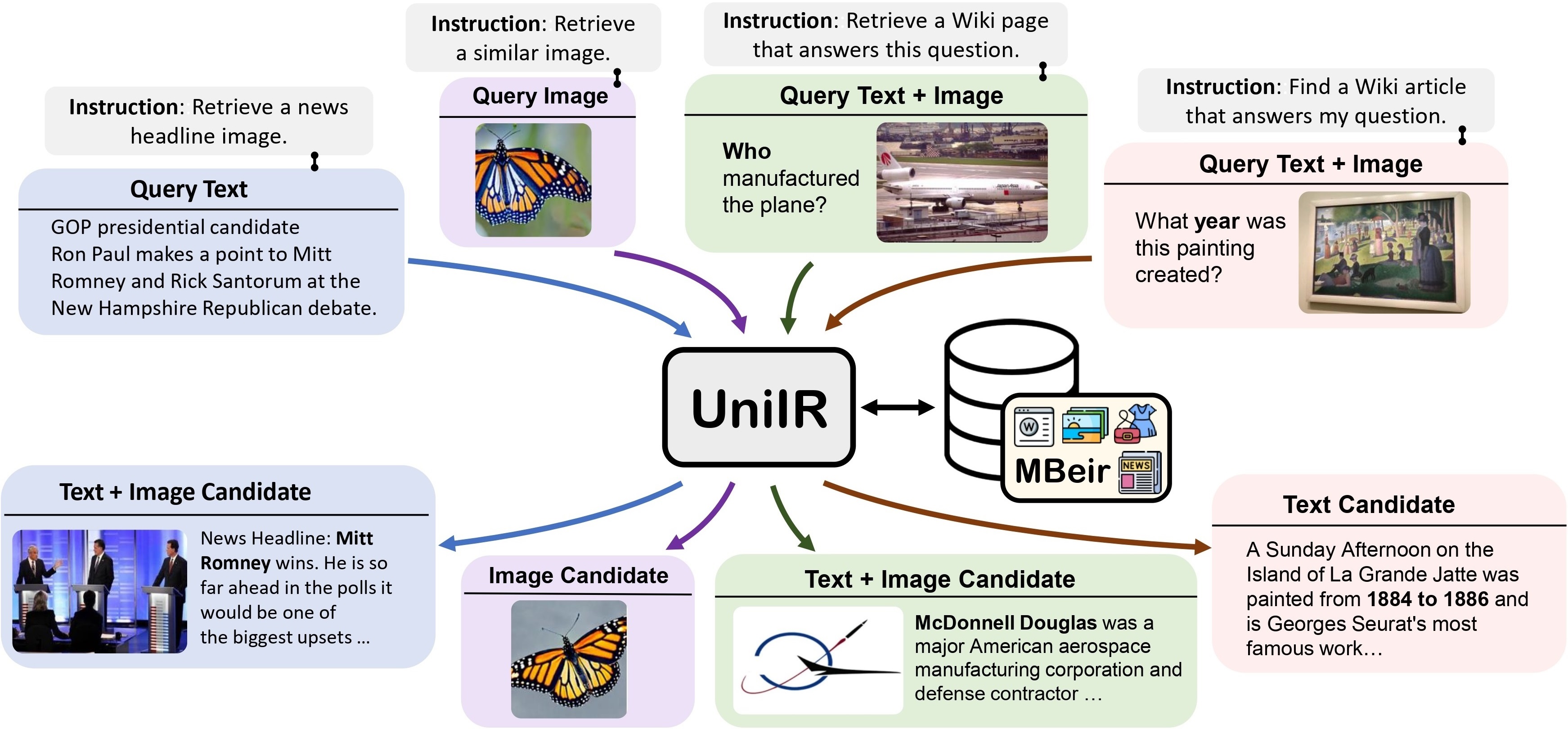 ทีเซอร์ UniIR" style="width: 80%; ความกว้างสูงสุด: 100%;">
ทีเซอร์ UniIR" style="width: 80%; ความกว้างสูงสุด: 100%;">
เพื่อฝึกอบรมและประเมินโมเดลการดึงข้อมูลหลายรูปแบบสากล เราได้สร้างเกณฑ์มาตรฐานการดึงข้อมูลขนาดใหญ่ชื่อ M-BEIR (BEnchmark หลายรูปแบบสำหรับการดึงข้อมูลแบบมีคำสั่ง)
เราจัดเตรียมชุดข้อมูล M-BEIR ไว้ใน ? ชุดข้อมูล โปรดปฏิบัติตามคำแนะนำที่ให้ไว้ในหน้า HF เพื่อดาวน์โหลดชุดข้อมูลและเตรียมข้อมูลสำหรับการฝึกอบรมและการประเมินผล คุณต้องตั้งค่า GiT LFS และโคลน repo โดยตรง:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
เราจัดเตรียมโค้ดเบสสำหรับการฝึกอบรมและประเมินโมเดล UniIR CLIP-ScoreFusion, CLIP-FeatureFusion, BLIP-ScoreFusion และ BLIP-FeatureFusion
เตรียมโค้ดเบสของโปรเจ็กต์ UniIR และสภาพแวดล้อม Conda โดยใช้คำสั่งต่อไปนี้:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.ymlหากต้องการฝึกโมเดล UniIR จากจุดตรวจ CLIP และ BLIP ที่ผ่านการฝึกอบรมแล้ว โปรดปฏิบัติตามคำแนะนำด้านล่าง สคริปต์จะดาวน์โหลดจุดตรวจ CLIP และ BLIP ที่ได้รับการฝึกไว้ล่วงหน้าโดยอัตโนมัติ
โปรดดาวน์โหลดเกณฑ์มาตรฐาน M-BEIR โดยทำตามคำแนะนำในส่วน M-BEIR
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/ แก้ไข inbatch.yaml สำหรับการปรับแต่งไฮเปอร์พารามิเตอร์ และ run_inbatch.sh สำหรับสภาพแวดล้อมและเส้นทางของคุณเอง
UniIR _DIR ใน run_inbatch.sh ไปยังไดเร็กทอรีที่คุณต้องการจัดเก็บจุดตรวจสอบMBEIR_DATA_DIR ใน run_inbatch.sh ไปยังไดเร็กทอรีที่คุณจัดเก็บการวัดประสิทธิภาพ M-BEIRSRC_DIR ใน run_inbatch.sh ไปยังไดเร็กทอรีที่คุณจัดเก็บ codebase ของโปรเจ็กต์ UniIR (repo นี้).env ด้วย WANDB_API_KEY , WANDB_PROJECT และ WANDB_ENTITY แล้วจากนั้นคุณสามารถรันคำสั่งต่อไปนี้เพื่อฝึก UniIR CLIP_SF โมเดลขนาดใหญ่
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/ แก้ไข inbatch.yaml สำหรับการปรับแต่งไฮเปอร์พารามิเตอร์ และ run_inbatch.sh สำหรับสภาพแวดล้อมและเส้นทางของคุณเอง
bash run_inbatch.shเราจัดเตรียมขั้นตอนการประเมินสำหรับโมเดล UniIR บนเกณฑ์มาตรฐาน M-BEIR
โปรดสร้างสภาพแวดล้อมสำหรับห้องสมุด FAISS:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.ymlโปรดดาวน์โหลดเกณฑ์มาตรฐาน M-BEIR โดยทำตามคำแนะนำในส่วน M-BEIR
คุณสามารถฝึกโมเดล UniIR ได้ตั้งแต่เริ่มต้น หรือดาวน์โหลดจุดตรวจ UniIR ที่ได้รับการฝึกมาแล้วโดยทำตามคำแนะนำในส่วน Model Zoo
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/ แก้ไข embed.yaml , index.yaml , retrieval.yaml และ run_eval_pipeline_inbatch.sh สำหรับสภาพแวดล้อม เส้นทาง และการตั้งค่าการประเมินผลของคุณเอง
UniIR _DIR ใน run_eval_pipeline_inbatch.sh ไปยังไดเร็กทอรีที่คุณต้องการจัดเก็บไฟล์ขนาดใหญ่ รวมถึงจุดตรวจสอบ การฝัง ดัชนี และผลลัพธ์การดึงข้อมูล จากนั้นคุณสามารถวางไฟล์ clip_sf_large.pth ในพาธต่อไปนี้: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthmodel.ckpt_config ในไฟล์ embed.yamlMBEIR_DATA_DIR ใน run_eval_pipeline_inbatch.sh ไปยังไดเร็กทอรีที่คุณจัดเก็บการวัดประสิทธิภาพ M-BEIRSRC_DIR ใน run_eval_pipeline_inbatch.sh ไปยังไดเร็กทอรีที่คุณจัดเก็บ codebase ของโปรเจ็กต์ UniIR (repo นี้) การกำหนดค่าเริ่มต้นจะประเมินโมเดลขนาดใหญ่ UniIR CLIP_SF บนทั้งการวัดประสิทธิภาพ M-BEIR (กลุ่มผู้สมัครที่แตกต่างกัน 5.6M) และเกณฑ์มาตรฐาน M-BEIR_local (กลุ่มผู้สมัครที่เป็นเนื้อเดียวกัน) UNION ในไฟล์ yaml อ้างถึง M-BEIR (กลุ่มผู้สมัครที่แตกต่างกัน 5.6M) คุณสามารถติดตามความคิดเห็นในไฟล์ yaml และแก้ไขการกำหนดค่าเพื่อประเมินโมเดลบนเกณฑ์มาตรฐาน M-BEIR_local เท่านั้น
bash run_eval_pipeline_inbatch.sh embed , index , logger และ retrieval_results จะถูกบันทึกไว้ในไดเร็กทอรี $ UniIR _DIR
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/ ในทำนองเดียวกัน หากคุณดาวน์โหลดโมเดล UniIR ที่ผ่านการฝึกอบรมแล้ว คุณสามารถวางไฟล์ blip_ff_large.pth ในพาธต่อไปนี้:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pthการกำหนดค่าเริ่มต้นจะประเมินโมเดลขนาดใหญ่ UniIR BLIP_FF บนการวัดประสิทธิภาพทั้ง M-BEIR และ M-BEIR_local
bash run_eval_pipeline_inbatch.shการประเมิน UniRAG นั้นคล้ายคลึงกับการประเมินเริ่มต้นมาก โดยมีข้อแตกต่างดังต่อไปนี้:
retrieval_results สิ่งนี้มีประโยชน์เมื่อผลลัพธ์ที่ดึงมาจะถูกใช้ในแอปพลิเคชันดาวน์สตรีม เช่น RAGretrieve_image_text_pairs ใน retrieval.yaml yaml เป็น True ระบบจะดึงตัวเลือกเสริมสำหรับตัวเลือกแต่ละรายการที่มี text หรือ image เท่านั้น ด้วยการตั้งค่านี้ ตัวเลือกและส่วนเสริมจะมี image, text เสมอ ผู้สมัครเสริมจะถูกดึงมาโดยใช้ผู้สมัครดั้งเดิมเป็นแบบสอบถาม (เช่น ข้อความ ค้นหา -> รูปภาพ ผู้สมัคร -> ข้อความ ผู้สมัครเสริม )InBatch และ inbatch ด้วย UniRAG และ unirag ตามลำดับ เราจัดให้มีจุดตรวจสอบโมเดล UniIR ในรูปแบบ ? จุดตรวจ คุณสามารถใช้จุดตรวจสอบสำหรับงานการดึงข้อมูลได้โดยตรง หรือปรับแต่งแบบจำลองสำหรับงานการดึงข้อมูลของคุณเอง
| ชื่อรุ่น | เวอร์ชัน | ขนาดรุ่น | ลิงค์รุ่น |
|---|---|---|---|
| UniIR (คลิป-SF) | ใหญ่ | 5.13GB | ลิงค์ดาวน์โหลด |
| UniIR (BLIP-FF) | ใหญ่ | 7.49GB | ลิงค์ดาวน์โหลด |
คุณสามารถดาวน์โหลดได้โดย
git clone https://huggingface.co/TIGER-Lab/UniIR
บิบเท็กซ์:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

