DiSQ Score
1.0.0
การนำไปปฏิบัติอย่างเป็นทางการสำหรับรายงานของเรา: Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' allowance of Discourse Relations (2024) Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan. ACL 2024.
เอกสาร PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf
สไลด์: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
โปสเตอร์: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
คุณต้องการทราบ DiSQ Score สำหรับโมเดลภาษาใดๆ หรือไม่ คุณสามารถใช้คำสั่งบรรทัดเดียวนี้ได้!

เรามีคำสั่งแบบง่ายในการประเมินโมเดลภาษา (LM) ใดๆ ที่โฮสต์อยู่ในฮับโมเดล HuggingFace ขอแนะนำให้ใช้สิ่งนี้กับโมเดลใหม่ใดๆ (โดยเฉพาะรุ่นที่ไม่ได้ศึกษาในรายงานของเรา)
bash scripts/one_model.sh <modelurl>
ตัวแปร < modelurl > ระบุเส้นทางที่สั้นลงในฮับของ Huggingface ตัวอย่างเช่น
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
ก่อนที่จะรันไฟล์ bash โปรดแก้ไขไฟล์ bash เพื่อระบุเส้นทางของคุณไปยัง HuggingFace Cache ในเครื่องของคุณ
ตัวอย่างเช่น ใน scripts/one_model.sh:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
คุณสามารถเปลี่ยน YOUR_PATH เป็นตำแหน่งไดเร็กทอรีที่แน่นอนของ Huggingface Cache ของคุณ (เช่น /disk1/yisong/hf-cache )
เราขอแนะนำพื้นที่ว่างอย่างน้อย 200GB
ไฟล์ข้อความเอาต์พุตจะถูกบันทึกไว้ที่ data/results/verbalizations/Meta-Llama-3-8B.txt ซึ่งประกอบด้วย:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
เราจัดเก็บชุดข้อมูลของเราในไฟล์ JSON ซึ่งอยู่ที่ data/datasets/dataset_pdtb.json และ data/datasets/dataset_ted.json ตัวอย่างเช่น สมมติว่ามีหนึ่งอินสแตนซ์จากชุดข้อมูล PDTB:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
ต่อไปนี้เป็นช่องต่างๆ ในรายการพจนานุกรมนี้:
Didx : รหัสวาทกรรมarg1 และ arg2 : สองข้อโต้แย้งDR : วาทกรรมสัมพันธ์Conn : วาทกรรมเชื่อมโยง.events : รายการคู่ที่จัดเก็บคู่เหตุการณ์ที่ทำนายไว้เป็นสัญญาณสำคัญcontext : บริบทวาทกรรม cd DiSQ-Score
bash scripts/question_generation.sh
ไฟล์ bash นี้จะเรียก question_generation.py เพื่อสร้างคำถามภายใต้การกำหนดค่าที่แตกต่างกัน
อาร์กิวเมนต์สำหรับ question_generation.py มีดังนี้:
--dataset : ระบุชุดข้อมูล pdtb หรือ ted--modelname : มีการสร้างนามแฝงสำหรับโมเดลแล้ว 13b หมายถึง LLaMA2-13B, 13bchat หมายถึง LLaMA2-13B-Chat และ vicuna-13b หมายถึง Vicuna-13B URL เฉพาะสำหรับโมเดลเหล่านี้มีอยู่ใน disq_config.py--version : ระบุเวอร์ชันของเทมเพลตพรอมต์ที่จะใช้ พร้อมด้วยตัวเลือก v1 , v2 , v3 และ v4--paraphrase : แทนที่คำถามมาตรฐานด้วยเวอร์ชันที่ถอดความ โดยมีตัวเลือก p1 และ p2 ไม่เหมือนกับฟังก์ชันมาตรฐานที่เรียก qa_utils.py ฟังก์ชันที่ถอดความจะเรียก qa_utils_p1.py และ qa_utils_p2.py ตามลำดับ--feature : ระบุคุณลักษณะทางภาษาที่จะใช้สำหรับคำถามการอภิปราย คุณลักษณะทางภาษา ได้แก่ conn (การเชื่อมต่อวาทกรรม) และ context (บริบทวาทกรรม) ข้อมูล QA ในอดีตต้องใช้สคริปต์แยกต่างหาก เอาต์พุตจะถูกเก็บไว้ที่ ตัวอย่างเช่น data/questions/dataset_pdtb_prompt_v1.json ภายใต้การกำหนดค่า dataset==pdtb และ version==v1
เราขอให้ผู้ใช้สร้างคำถามด้วยตัวเองเนื่องจากวิธีการนี้เป็นไปโดยอัตโนมัติและช่วยประหยัดพื้นที่ในพื้นที่เก็บข้อมูล GitHub ของเรา (ซึ่งอาจเพิ่มได้ถึง ~200 MB) หากคุณไม่สามารถเรียกใช้ไฟล์ bash ได้ โปรดติดต่อเราเพื่อขอไฟล์คำถาม
cd DiSQ-Score
bash scripts/question_answering.sh
ไฟล์ทุบตีนี้จะเรียก question_answering.py เพื่อดำเนินการ Discursive Socratic Questioning (DiSQ) สำหรับรุ่นใดก็ตาม question_answering.py รับอาร์กิวเมนต์ทั้งหมดจาก question_generation.py รวมถึงอาร์กิวเมนต์ใหม่ต่อไปนี้:
--modelurl : ระบุ URL สำหรับโมเดลใหม่ใด ๆ ที่ไม่ได้อยู่ในไฟล์กำหนดค่าในปัจจุบัน ตัวอย่างเช่น 'meta-llama/Meta-Llama-3-8B' ระบุโมเดล LLaMA3-8B และจะเขียนทับอาร์กิวเมนต์ modelname--hf-path : ระบุเส้นทางเพื่อจัดเก็บพารามิเตอร์โมเดลขนาดใหญ่ แนะนำให้ใช้พื้นที่ว่างในดิสก์อย่างน้อย 200 GB--device_number : ระบุ ID ของ GPU ที่จะใช้ ผลลัพธ์จะถูกเก็บไว้ที่ เช่น data/results/13bchat_dataset_pdtb_prompt_v1/ การทำนายสำหรับคำถามแต่ละข้อคือรายการโทเค็นและความน่าจะเป็น ซึ่งจัดเก็บไว้ในไฟล์ดองภายในโฟลเดอร์
Caveat: โมเดล Wizard ได้ถูกถอดออกโดยนักพัฒนา เราแนะนำให้ผู้ใช้อย่าลองใช้รุ่นเหล่านี้ ตรวจสอบกระทู้สนทนาได้ที่: https://huggingface.co/posts/WizardLM/329547800484476
cd DiSQ-Score
bash scripts/eval.sh
ไฟล์ทุบตีนี้จะเรียก eval.py เพื่อประเมินการคาดการณ์โมเดลที่ได้รับก่อนหน้านี้
eval.py ใช้ชุดพารามิเตอร์เดียวกันกับ question_answering.py
ผลลัพธ์ของการประเมินจะถูกจัดเก็บไว้ใน disq_score_pdtb.csv หากชุดข้อมูลที่ระบุคือ PDTB
ไฟล์ CSV มี 20 คอลัมน์ ได้แก่:
taskcode : ระบุการกำหนดค่าที่กำลังทดสอบ เช่น dataset_pdtb_prompt_v1_13bchatmodelname : ระบุรุ่นภาษาที่กำลังทดสอบversion : ระบุเวอร์ชันของพรอมต์paraphrase : พารามิเตอร์สำหรับการถอดความfeature : ระบุคุณลักษณะที่ถูกใช้Overall : DiSQ Score โดยรวมTargeted : คะแนนเป้าหมาย ซึ่งเป็นหนึ่งในสามองค์ประกอบใน DiSQ ScoreCounterfactual : คะแนน Counterfactual ซึ่งเป็นหนึ่งในสามองค์ประกอบใน DiSQ ScoreConsistency : คะแนนความสม่ำเสมอ ซึ่งเป็นหนึ่งในสามองค์ประกอบใน DiSQ ScoreComparison.Concession : DiSQ Score สำหรับความสัมพันธ์วาทกรรมเฉพาะนี้โปรดทราบว่าเราเลือกผลลัพธ์ที่ดีที่สุดระหว่างเวอร์ชัน v1 ถึง v4 เพื่อลดผลกระทบของเทมเพลตพร้อมท์
ในการทำเช่นนั้น eval.py จะแยกผลลัพธ์ที่ดีที่สุดโดยอัตโนมัติ:
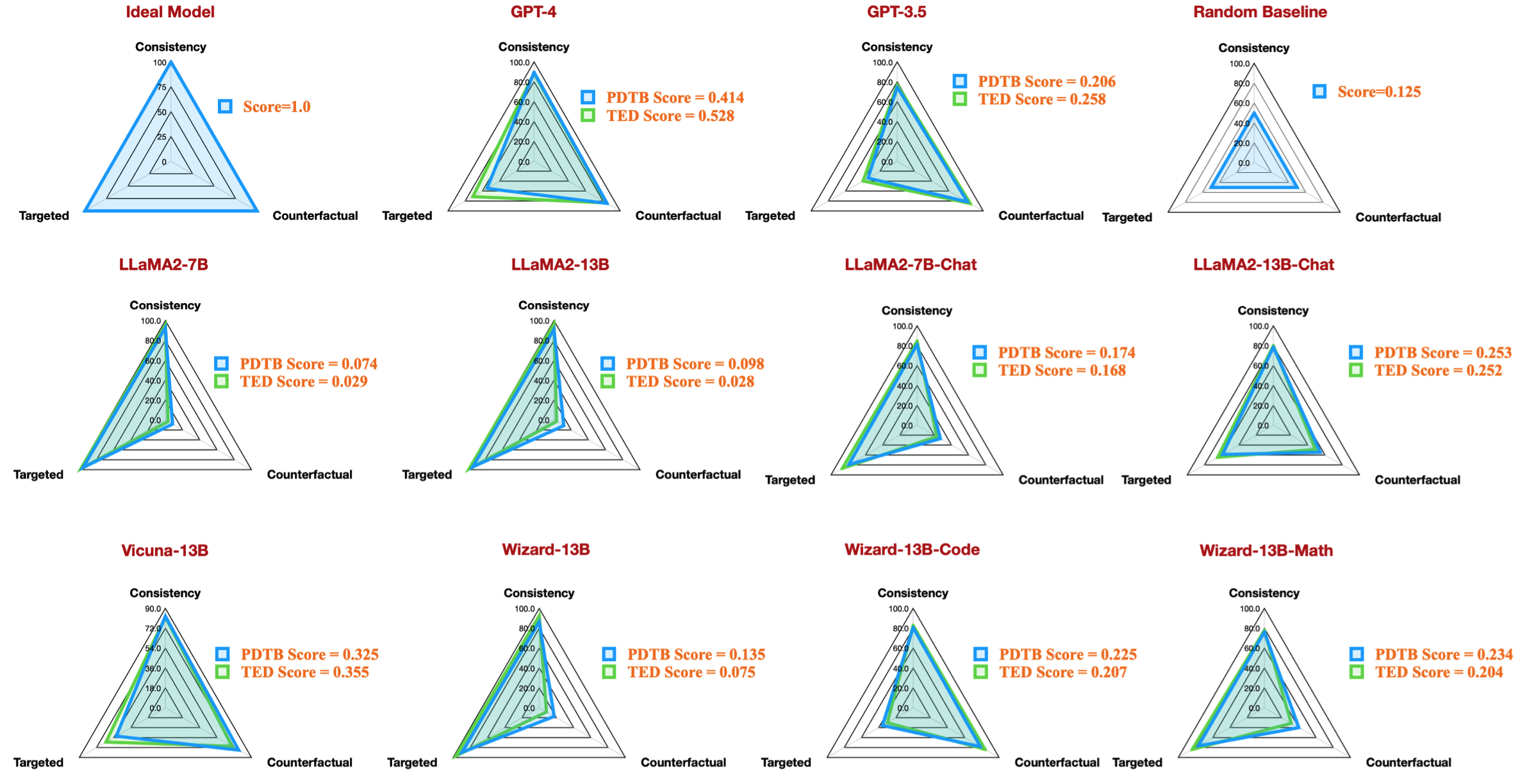
| รหัสงาน | ชื่อรุ่น | รุ่น | ถอดความ | คุณสมบัติ | โดยรวม | กำหนดเป้าหมาย | ต่อต้านข้อเท็จจริง | ความสม่ำเสมอ | การเปรียบเทียบสัมปทาน | การเปรียบเทียบคอนทราสต์ | เหตุฉุกเฉิน.เหตุผล | เหตุฉุกเฉิน.ผลลัพธ์ | การขยายตัว การเชื่อมต่อ | การขยายตัวความเท่าเทียมกัน | การขยายตัว การสร้างอินสแตนซ์ | การขยายตัวระดับของรายละเอียด | การขยายตัว การทดแทน | ชั่วคราวแบบอะซิงโครนัส | ชั่วขณะซิงโครนัส |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7b | v4 | 0.074 | 0.956 | 0.084 | 0.929 | 0.03 | 0.083 | 0.095 | 0.095 | 0.077 | 0.054 | 0.086 | 0.068 | 0.155 | 0.036 | 0.047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7bchat | เวอร์ชัน 1 | 0.174 | 0.794 | 0.271 | 0.811 | 0.231 | 0.435 | 0.132 | 0.173 | 0.214 | 0.105 | 0.121 | 0.15 | 0.199 | 0.107 | 0.04 | ||
| dataset_pdtb_prompt_v2_13b | 13บี | เวอร์ชัน 2 | 0.097 | 0.945 | 0.112 | 0.912 | 0.037 | 0.099 | 0.081 | 0.094 | 0.126 | 0.101 | 0.113 | 0.107 | 0.077 | 0.083 | 0.093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13bchat | เวอร์ชัน 1 | 0.253 | 0.592 | 0.545 | 0.785 | 0.195 | 0.485 | 0.129 | 0.173 | 0.289 | 0.155 | 0.326 | 0.373 | 0.285 | 0.194 | 0.028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | วิคูนา-13b | เวอร์ชัน 2 | 0.325 | 0.512 | 0.766 | 0.829 | 0.087 | 0.515 | 0.201 | 0.352 | 0.369 | 0.0 | 0.334 | 0.46 | 0.199 | 0.511 | 0.074 |
ตัวอย่างเช่น ตารางนี้แสดงผลลัพธ์ที่ดีที่สุดสำหรับชุดข้อมูล PDTB สำหรับโมเดลโอเพ่นซอร์สที่มีอยู่ ซึ่งสร้างตัวเลขเรดาร์ในรายงานของเรา:
นอกจากนี้เรายังให้คำแนะนำในการประเมินคำถามการสนทนาเกี่ยวกับคุณลักษณะทางภาษา:
--feature เป็น conn และ context ใน question_generation.py (ขั้นตอนที่ 1) และทำการทดสอบทั้งหมดอีกครั้งquestion_generation_history.py สคริปต์นี้จะแยกคำตอบจากผลลัพธ์ QA ที่เก็บไว้และสร้างคำถามใหม่สำหรับ NLPers ส่วนใหญ่ คุณอาจจะเรียกใช้โค้ดของเรากับสภาพแวดล้อมเสมือน (conda) ที่มีอยู่ได้
เมื่อเราทำการทดลอง เวอร์ชันของแพ็คเกจจะเป็นดังนี้:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
อย่างไรก็ตาม เราพบว่ารุ่นที่ใหม่กว่านั้นจำเป็นต้องมีเวอร์ชันแพ็คเกจที่อัปเกรด:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
หากคุณพบว่างานของเราน่าสนใจ คุณสามารถลองใช้ชุดข้อมูล/ฐานข้อมูลโค้ดของเราได้
กรุณาอ้างอิงงานวิจัยของเราหากคุณใช้ชุดข้อมูล/ฐานข้อมูลของเรา:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
หากคุณมีคำถามหรือรายงานข้อผิดพลาด โปรดแจ้งปัญหาหรือติดต่อเราโดยตรงผ่านทางอีเมล:
ที่อยู่อีเมล: ?@?
โดยที่ ️= yisong , ?= comp.nus.edu.sg
ซีซีโดย 4.0


