Patron
1.0.0
การซื้อคืนนี้มีโค้ดสำหรับเอกสาร ACL 2023 การเลือกข้อมูล Cold-Start สำหรับการปรับแต่งโมเดลภาษาแบบ Few-shot: แนวทางการแพร่กระจายความไม่แน่นอนโดยทันที
ผลลัพธ์ของชุดข้อมูลต่างๆ (โดยใช้ 128 ป้ายกำกับเป็นงบประมาณ) สำหรับการปรับแต่งโดยละเอียดสรุปได้ดังนี้:
| วิธี | ไอเอ็มดีบี | Yelp-เต็ม | เอจีนิวส์ | ยาฮู! | ดีบีพีเดีย | ธกส | หมายถึง |
|---|---|---|---|---|---|---|---|
| การกำกับดูแลเต็มรูปแบบ (ฐาน RoBERTa) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| การสุ่มตัวอย่าง | 86.6 | 47.7 | 84.5 | 60.2 | 95.0 | 85.6 | 76.7 |
| พื้นฐานที่ดีที่สุด (Chang และคณะ 2021) | 88.5 | 46.4 | 85.6 | 61.3 | 96.5 | 87.7 | 77.6 |
| Patron (ของเรา) | 89.6 | 51.2 | 87.0 | 65.1 | 97.0 | 91.1 | 80.2 |
สำหรับการเรียนรู้แบบทันทีทันใด เราใช้ไปป์ไลน์เดียวกันกับ LM-BFF ผลลัพธ์ที่มี 128 ป้ายกำกับแสดงดังนี้
| วิธี | ไอเอ็มดีบี | Yelp-เต็ม | เอจีนิวส์ | ยาฮู! | ดีบีพีเดีย | ธ.ก.ส | หมายถึง |
|---|---|---|---|---|---|---|---|
| การกำกับดูแลเต็มรูปแบบ (ฐาน RoBERTa) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| การสุ่มตัวอย่าง | 87.7 | 51.3 | 84.9 | 64.7 | 96.0 | 85.0 | 78.2 |
| พื้นฐานที่ดีที่สุด (หยวนและคณะ 2020) | 88.9 | 51.7 | 87.5 | 65.9 | 96.8 | 86.5 | 79.5 |
| Patron (ของเรา) | 89.3 | 55.6 | 87.8 | 67.6 | 97.4 | 88.9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
เราใช้ชุดข้อมูลสี่ชุดต่อไปนี้สำหรับการทดลองหลัก
| ชุดข้อมูล | งาน | จำนวนชั้นเรียน | จำนวนข้อมูลที่ไม่มีป้ายกำกับ/ข้อมูลการทดสอบ |
|---|---|---|---|
| ไอเอ็มดีบี | ความรู้สึก | 2 | 25k/25k |
| Yelp-เต็ม | ความรู้สึก | 5 | 39,000/10,000 |
| ข่าวเอจี | หัวข้อข่าว | 4 | 119,000/7.6k |
| ยาฮู! คำตอบ | หัวข้อการประกันคุณภาพ | 5 | 180k/30.1k |
| ดีบีพีเดีย | หัวข้ออภิปรัชญา | 14 | 280k/70k |
| ธกส | หัวข้อคำถาม | 6 | 5k/0.5k |
ข้อมูลที่ประมวลผลสามารถดูได้ที่ลิงค์นี้ โฟลเดอร์สำหรับใส่ชุดข้อมูลเหล่านี้จะอธิบายไว้ในส่วนต่อไปนี้
รันคำสั่งต่อไปนี้
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
เราจัดเตรียม การทำนายหลอก ที่ได้รับผ่านทางข้อความแจ้งในลิงก์ด้านบนสำหรับชุดข้อมูล โปรดดูเอกสารต้นฉบับสำหรับรายละเอียด
เรียกใช้คำสั่งต่อไปนี้ (ตัวอย่างบนชุดข้อมูล AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
ไฮเปอร์พารามิเตอร์ที่สำคัญบางประการ:
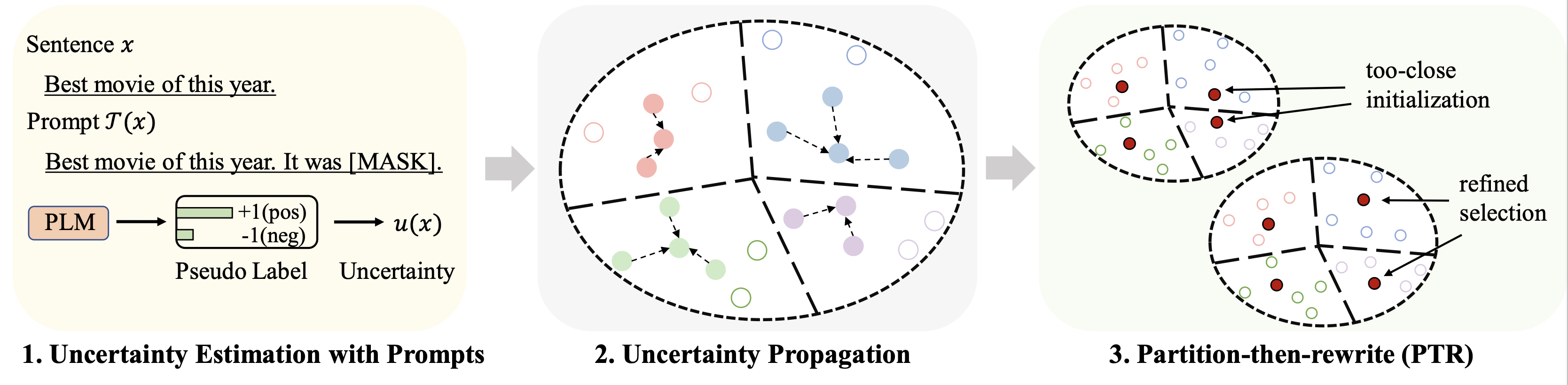
rho : พารามิเตอร์ที่ใช้สำหรับการแพร่กระจายความไม่แน่นอนในสมการ 6 ของกระดาษbeta : การทำให้ระยะทางเป็นปกติในสมการ 8 ของกระดาษgamma : น้ำหนักของเทอมการทำให้เป็นมาตรฐานในสมการ 10 ของกระดาษ ดูโฟลเดอร์ finetune สำหรับคำแนะนำโดยละเอียด
ดูโฟลเดอร์ prompt_learning สำหรับคำแนะนำโดยละเอียด
ดูลิงก์นี้เป็นช่องทางสำหรับสร้างการคาดการณ์ตามพรอมต์ โปรดทราบว่าคุณต้องปรับแต่งโปรแกรมอ่านออกเสียงและเทมเพลตพร้อมท์ของคุณ
หากต้องการสร้างการฝังเอกสาร คุณสามารถทำตามคำสั่งข้างต้นได้โดยใช้ SimCSE
เมื่อคุณสร้างดัชนีสำหรับข้อมูลที่เลือกแล้ว คุณสามารถใช้ไปป์ไลน์ใน Running Fine-tuning Experiments และ Running Prompt-based Learning Experiments สำหรับการปรับแต่งแบบละเอียดเพียงไม่กี่ช็อตและการทดสอบการเรียนรู้แบบพร้อมท์
โปรดอ้างอิงเอกสารต่อไปนี้หากคุณพบว่า repo นี้มีประโยชน์สำหรับการวิจัยของคุณ ขอบคุณล่วงหน้า!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
เราขอขอบคุณผู้เขียนจาก repo SimCSE และ OpenPrompt สำหรับโค้ดที่มีการจัดระเบียบอย่างดี


