JustJoking.ai
1.0.0
ในโปรเจ็กต์นี้ ฉันได้ฝึกโมเดลหม้อแปลงเพื่อสร้างเรื่องตลกสั้นๆ จากนั้นด้วยการปรับเปลี่ยนวิธีการอนุมานเล็กน้อย ฉันจึงสามารถใช้โมเดลเดียวกันโดย ให้สตริงเริ่มต้นเป็นอินพุต โมเดลจะพยายามทำให้เสร็จสมบูรณ์ด้วยวิธีที่ตลกขบขัน
มีสมุดบันทึกสองเครื่องที่ทำงานเดียวกัน
ผลลัพธ์ของการสร้างเรื่องตลก 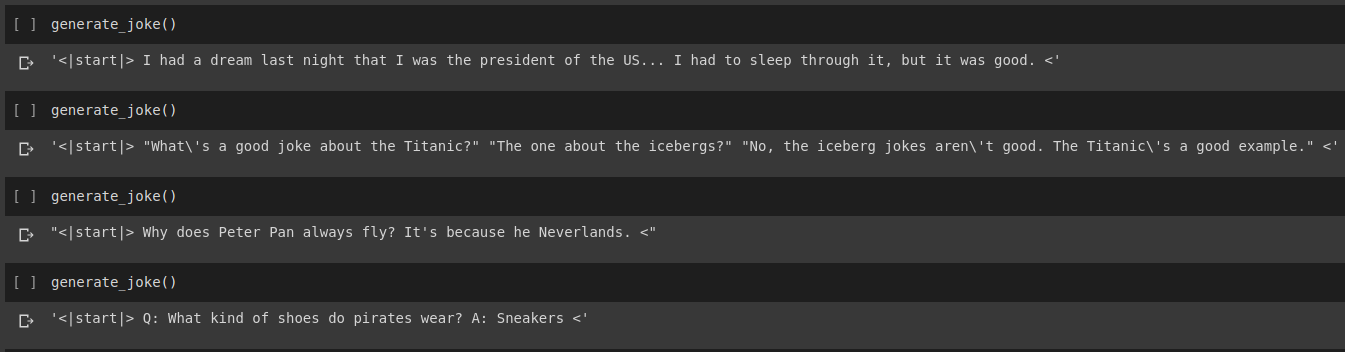
ผลการเติมประโยคให้สมบูรณ์ 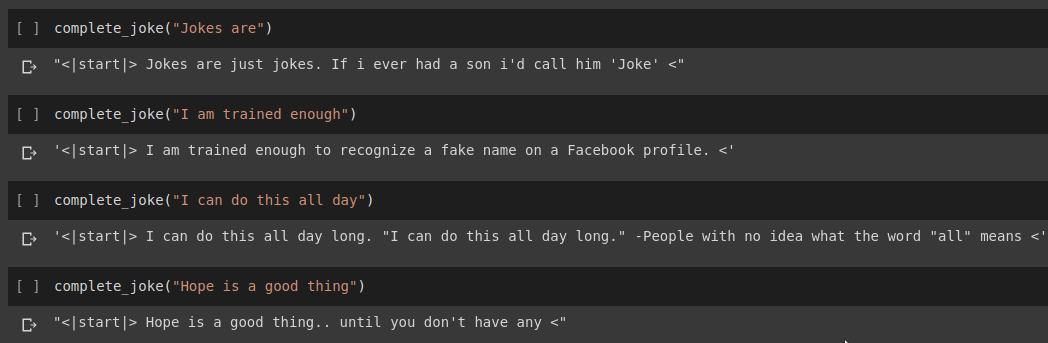
ผลลัพธ์ 
สำหรับงานของเรา เราจะใช้ชุดข้อมูลที่ให้ไว้ใน Kaggle มันเป็น csv ที่มีเรื่องสั้นมากกว่า 200,000 เรื่องที่คัดลอกมาจาก Reddit
หมายเหตุ : เนื่องจากชุดข้อมูลถูกแยกออกจาก subreddits ต่างๆ เรื่องตลกจำนวนมากในชุดข้อมูลจึงค่อนข้างเหยียดเชื้อชาติและเหยียดเพศ เนื่องจาก AI ใดๆ จะถือว่าข้อมูลการฝึกอบรมเป็นแหล่งความรู้แหล่งเดียว จึงควรคาดหวังว่าบางครั้งแบบจำลองของเราจะสร้างเรื่องตลกที่คล้ายกัน
เมื่อเราสร้างโทเค็นสตริงตลกแล้ว เราจะเพิ่ม start_token และ end_token ที่ส่วนท้ายของรายการโทเค็น นอกจากนี้ เนื่องจากสตริงตลกของเราอาจมีความยาวต่างกัน เราจึงใช้การเสริมในสตริงทั้งหมดตาม max_length ที่ระบุ เพื่อให้เทนเซอร์ทั้งหมดมีรูปร่างคล้ายกันในชุดของเรา
รหัสนี้สามารถพบได้ในสมุดบันทึก Joke Generation.ipynb ในนี้เราจะนำเข้า GPT2Tokenizer และ TFGPT2LMHead Model จากไลบรารี HuggingFace รหัสถูกเขียนใน Tensorflow2 สมุดบันทึกมีความคิดเห็นพร้อมคำอธิบายโค้ดในตำแหน่งที่เหมาะสม นอกจากนี้ เอกสาร HuggingFace ยังมีเอกสารที่ดีเกี่ยวกับพารามิเตอร์อินพุตและค่าส่งคืนของโมเดล สำหรับการใช้งานที่ใช้ PyTorch โปรดดู repo Humour.ai ของ Tanul Singh
รหัสนี้สามารถพบได้ในสมุดบันทึก Joke_Completion_Pure_TF2_Implementation.ipynb ยกระดับโครงการไปอีกขั้นเพื่อทำความเข้าใจให้ลึกซึ้งยิ่งขึ้นว่าสิ่งต่าง ๆ ทำงานอย่างไร ฉันพยายามสร้างหม้อแปลงไฟฟ้าที่ไม่มีไลบรารีภายนอก ฉันได้อ้างอิงถึงบทช่วยสอนสำหรับ Transformers ที่จัดทำโดย Tensorflow และได้ใส่คำอธิบายบางส่วนที่กล่าวถึงในบทช่วยสอนของพวกเขาลงในสมุดบันทึกของฉันพร้อมคำอธิบายเพิ่มเติมเพื่อให้เข้าใจได้ง่ายว่าเกิดอะไรขึ้น
ขั้นแรก ฉันสร้างโทเค็นไนเซอร์สำหรับชุดข้อมูลของเรา และแปลงสตริงโดยใช้โทเค็นดังกล่าว จากนั้น สร้างเลเยอร์สำหรับ Positional Encodings และ MultiHeadAttention นอกจากนี้ ฉันยังใช้ Lambda layer เพื่อสร้างมาสก์ที่เหมาะสมสำหรับข้อมูลของเรา
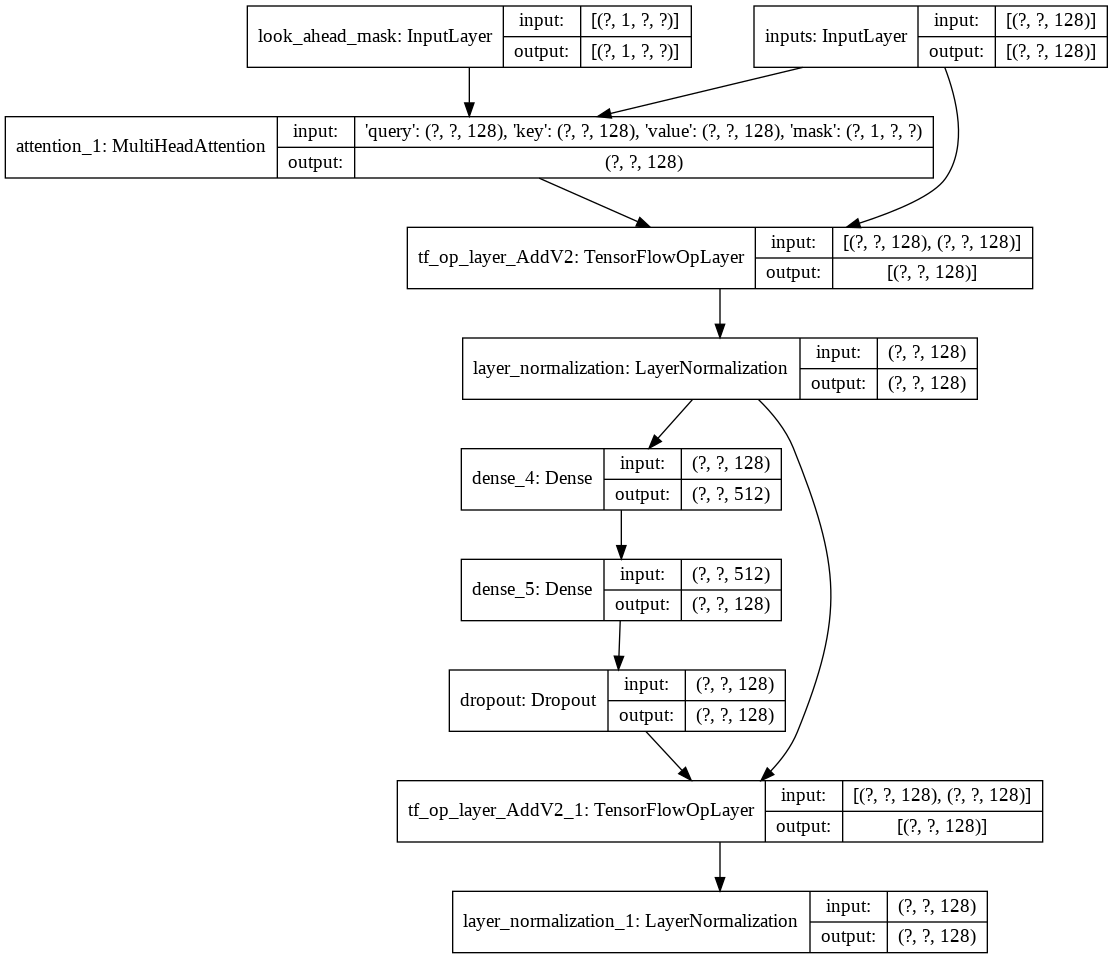
จากนั้นฉันก็สร้าง decoder layer เดียวสำหรับตัวถอดรหัสของเรา ต่อไปนี้เป็นสถาปัตยกรรมของเลเยอร์ตัวถอดรหัสเดี่ยว
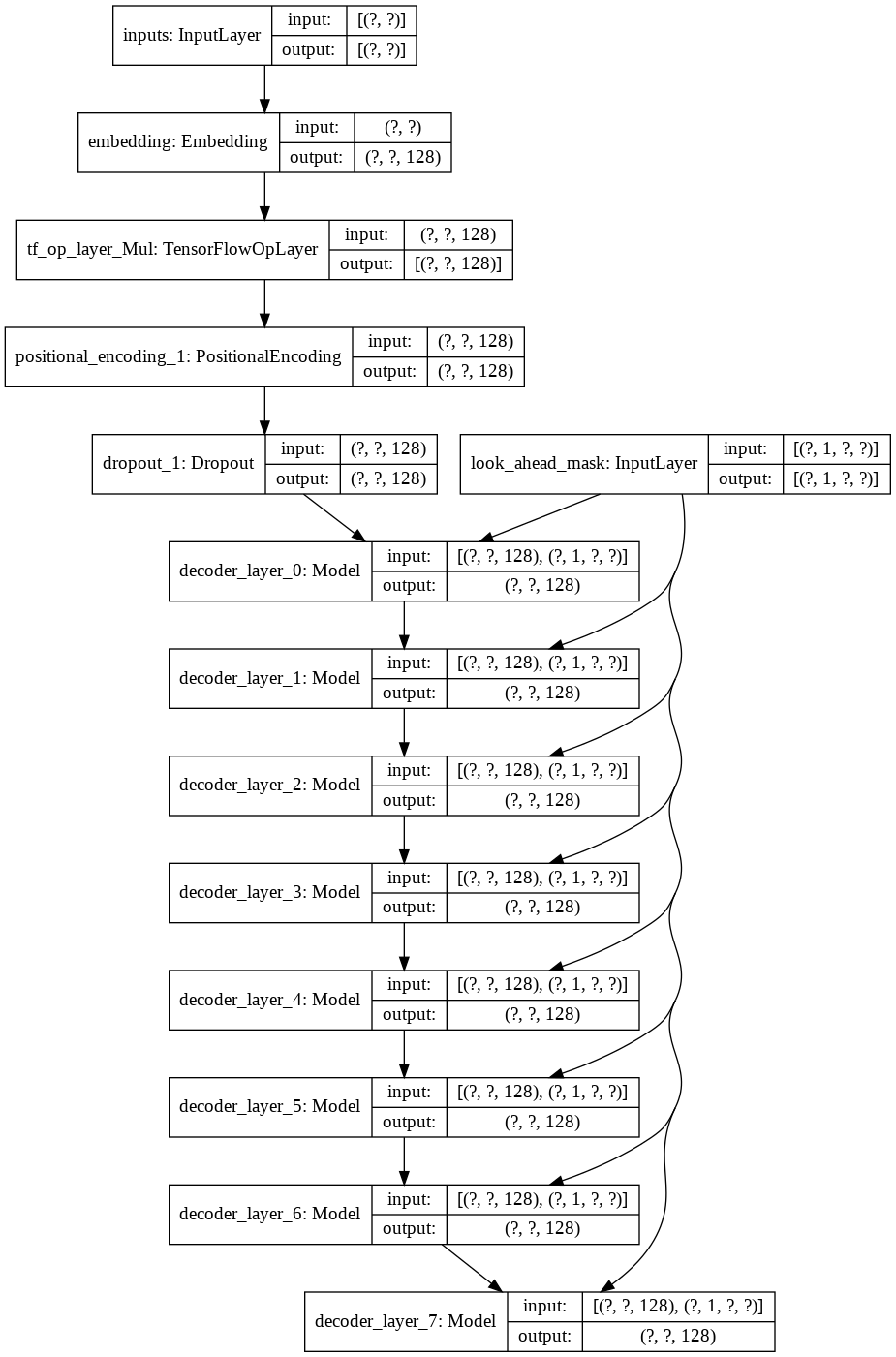
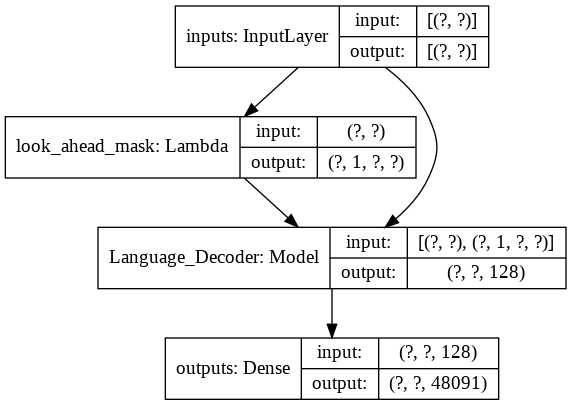
สำหรับโมเดล transformer ขั้นสุดท้าย จะใช้โทเค็นอินพุต ส่งผ่านเลเยอร์ lamda เพื่อรับมาสก์ และส่งทั้งมาสก์และโทเค็นไปยังตัวถอดรหัสภาษาของเรา ซึ่งเอาต์พุตจะถูกส่งผ่านเลเยอร์หนาแน่น ต่อไปนี้เป็นสถาปัตยกรรมของโมเดลสุดท้ายของเรา