CTCWordBeamSearch
1.0.0
ตัวถอดรหัส Connectionist Temporal Classification (CTC) พร้อมพจนานุกรมและโมเดลภาษา (LM)
pip install .tests/ และดำเนินการ pytest เพื่อตรวจสอบว่าการติดตั้งใช้งานได้หรือไม่ ตัวอย่างของเล่นต่อไปนี้แสดงวิธีใช้การค้นหาลำแสงคำ โมเดลสมมุติ (เช่น โมเดลการจดจำข้อความ) สามารถจดจำอักขระที่แตกต่างกัน 3 ตัว: "a", "b" และ " " (ช่องว่าง) คำในตัวอย่างของเล่นนั้นสามารถมีอักขระ "a" และ "b" ได้ (แต่ไม่ใช่ " " ซึ่งเป็นตัวแยกคำ) โมเดลภาษาได้รับการฝึกฝนจากคลังข้อความที่มีเพียงสองคำ: "a" และ "ba"
ในตัวอย่างโค้ดนี้ อินสแตนซ์ของการค้นหาลำแสงคำจะถูกสร้างขึ้น และอาร์เรย์ numpy ที่มีรูปร่าง TxBx(C+1) จะถูกถอดรหัส:
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )ตัวถอดรหัสส่งคืนรายการพร้อมสตริงป้ายกำกับที่ถอดรหัสแล้วสำหรับแต่ละองค์ประกอบแบตช์ หากต้องการรับสตริงอักขระในที่สุด ให้แมปแต่ละป้ายกำกับกับอักขระที่เกี่ยวข้อง:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )ตัวอย่าง:
tests/test_word_beam_search.py พารามิเตอร์ของตัวสร้างคลาส WordBeamSearch :
0<len(wordChars)<len(chars) . ในกรณีที่ต้องตรวจพบเพียงคำเดียว ไม่จำเป็นต้องแยกอักขระ ดังนั้นพารามิเตอร์ทั้งสองจึงอาจเท่ากัน: 0<len(wordChars)<=len(chars) ป้อนข้อมูลในวิธี WordBeamSearch.compute :
การค้นหาลำแสงคำเป็นอัลกอริธึมการถอดรหัส CTC ใช้สำหรับงานการรู้จำลำดับ เช่น การรู้จำข้อความที่เขียนด้วยลายมือ หรือการรู้จำเสียงพูดอัตโนมัติ
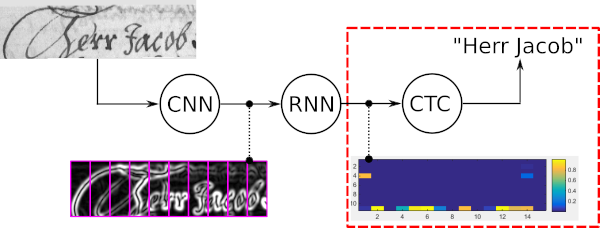
คุณสมบัติหลักสี่ประการของการค้นหาลำแสงคำคือ:
ตัวอย่างต่อไปนี้แสดงกรณีการใช้งานทั่วไปของการค้นหาลำแสงคำพร้อมกับผลลัพธ์ที่ได้รับจากตัวถอดรหัสที่แตกต่างกันห้าตัว การถอดรหัสเส้นทางที่ดีที่สุดและการค้นหาเส้นทางแบบวานิลลาบีมจะทำให้คำผิด เนื่องจากตัวถอดรหัสเหล่านี้ใช้เฉพาะเอาต์พุตที่มีสัญญาณรบกวนของโมเดลออปติคัลเท่านั้น การขยายการค้นหาลำแสงวานิลลาด้วย LM ระดับตัวละครจะปรับปรุงผลลัพธ์โดยอนุญาตเฉพาะลำดับอักขระที่เป็นไปได้เท่านั้น การส่งโทเค็นใช้พจนานุกรมและ LM ระดับคำ ดังนั้นจึงทำให้ทุกคำถูกต้อง อย่างไรก็ตาม ไม่สามารถรับรู้สตริงอักขระที่กำหนดเอง เช่น ตัวเลขได้ การค้นหาลำแสงคำสามารถจดจำคำศัพท์ได้โดยใช้พจนานุกรม แต่ยังสามารถระบุอักขระที่ไม่ใช่คำได้อย่างถูกต้องอีกด้วย

ข้อมูลเพิ่มเติม:
extras/prototype/extras/tf/ โปรดอ้างอิงบทความต่อไปนี้หากคุณใช้การค้นหาแบบลำแสงคำในงานวิจัยของคุณ
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


