Grounding_LLMs_with_online_RL
1.0.0
พื้นที่เก็บข้อมูลนี้มีโค้ดที่ใช้สำหรับเอกสารของเราเรื่อง Grounding Large Language Models with Online Reinforcement Learning
คุณสามารถค้นหาข้อมูลเพิ่มเติมได้จากเว็บไซต์ของเรา
เราดำเนินการพื้นฐานความรู้ของ LLM ใน BabyAI-Text โดยใช้วิธี GLAM : 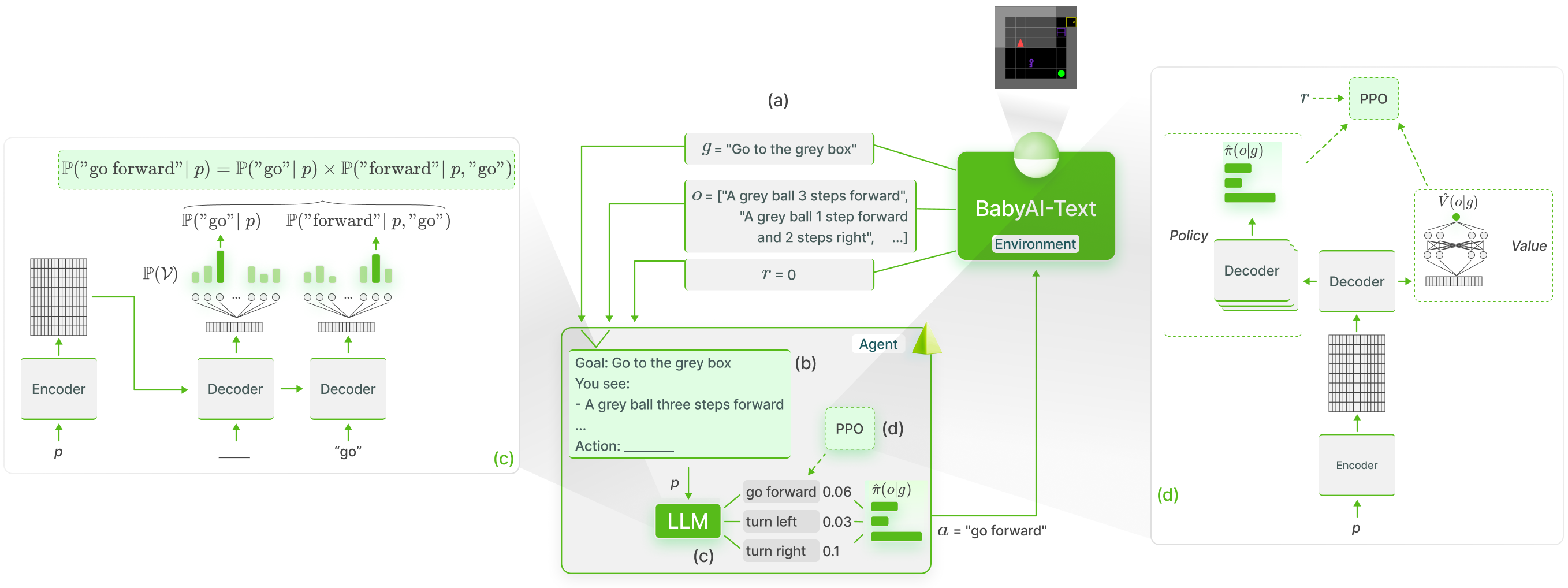
เราเผยแพร่สภาพแวดล้อม BabyAI-Text พร้อมกับโค้ดเพื่อทำการทดลองของเรา (ทั้งฝึกอบรมตัวแทนและประเมินประสิทธิภาพของพวกเขา) เราพึ่งพาไลบรารี Lamorel เพื่อใช้ LLM
พื้นที่เก็บข้อมูลของเรามีโครงสร้างดังนี้:
- Grounding_LLMs_with_online_RL
┣ babyai-text -- สภาพแวดล้อม BabyAI-Text ของเรา
┣ experiments -- โค้ดสำหรับการทดลองของเรา
┃ ┣ agents -- การดำเนินการของตัวแทนทั้งหมดของเรา
┃ ┃ ┣ bot -- ตัวแทนบอทที่ใช้ประโยชน์จากบอทของ BabyAI
┃ ┃ ┣ random_agent -- ตัวแทนเล่นแบบสุ่มสม่ำเสมอ
┃ ┃ ┣ drrn -- ตัวแทน DRRN จากที่นี่
┃ ┃ ┣ ppo -- ตัวแทนที่ใช้ PPO
┃ ┃ ┃ ┣ symbolic_ppo_agent.py -- SymbolicPPO ดัดแปลงมาจาก PPO ของ BabyAI
┃ ┃ ┃ ┗ llm_ppo_agent.py -- ตัวแทน LLM ของเราถูกต่อสายดินโดยใช้ PPO
┃ ┣ configs -- กำหนดค่า Lamorel สำหรับการทดลองของเรา
┃ ┣ slurm -- ใช้สคริปต์เพื่อเปิดการทดลองของเราบนคลัสเตอร์ SLURM
┃ ┣ campaign -- สคริปต์ SLURM ที่ใช้ในการเริ่มการทดสอบของเรา
┃ ┣ train_language_agent.py -- ฝึกอบรมตัวแทนโดยใช้ BabyAI-Text (LLM และ DRRN) -> ประกอบด้วยการดำเนินการของเราเกี่ยวกับการสูญเสีย PPO สำหรับ LLM เช่นเดียวกับส่วนหัวเพิ่มเติมที่อยู่ด้านบนของ LLM
┃ ┣ train_symbolic_ppo.py -- ฝึก SymbolicPPO บน BabyAI (พร้อมงานของ BabyAI-Text)
┃ ┣ post-training_tests.py -- การทดสอบลักษณะทั่วไปของตัวแทนที่ผ่านการฝึกอบรม
┃ ┣ test_results.py -- ใช้สำหรับจัดรูปแบบผลลัพธ์
┃ ┗ clm_behavioral-cloning.py -- รหัสเพื่อทำการโคลนพฤติกรรมบน LLM โดยใช้วิถี
conda create -n dlp python=3.10.8; conda activate dlp
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
ติดตั้ง BabyAI-Text : ดูรายละเอียดการติดตั้งในแพ็คเกจ babyai-text
ติดตั้งลาโมเรล
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
โปรดใช้ Lamorel ร่วมกับการกำหนดค่าของเรา คุณสามารถดูตัวอย่างสคริปต์การฝึกอบรมของเราได้ในแคมเปญ
หากต้องการฝึกโมเดลภาษาในสภาพแวดล้อม BabyAI-Text ต้องใช้ไฟล์ train_language_agent.py สคริปต์นี้ (เปิดตัวด้วย Lamorel) ใช้รายการกำหนดค่าต่อไปนี้:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps : 1000 # Total number of training steps
max_episode_steps : 3 # Maximum number of steps in a single episode
frames_per_proc : 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount : 0.99 # Discount factor used in PPO
lr : 1e-6 # Learning rate used to finetune the LLM
beta1 : 0.9 # PPO's hyperparameter
beta2 : 0.999 # PPO's hyperparameter
gae_lambda : 0.99 # PPO's hyperparameter
entropy_coef : 0.01 # PPO's hyperparameter
value_loss_coef : 0.5 # PPO's hyperparameter
max_grad_norm : 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps : 1e-5 # Adam's hyperparameter
clip_eps : 0.2 # Epsilon used in PPO's losses clipping
epochs : 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size : 16 # Minibatch size
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test : 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs : 3 # Number of past observation used in the promptสำหรับรายการกำหนดค่าที่เกี่ยวข้องกับโมเดลภาษา โปรดดูที่ Lamorel
หากต้องการประเมินประสิทธิภาพของตัวแทน (เช่น LLM ที่ได้รับการฝึกอบรม บอทของ BabyAI...) ในงานทดสอบ ให้ใช้ post-training_tests.py และตั้งค่ารายการกำหนดค่าต่อไปนี้:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps : 3 # Maximum number of steps in a single episode
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs : 3 # Number of past observation used in the prompt
number_episodes : 10 # Number of test episodes
language : ' english ' # Useful to perform the French experiment (Section H4)
zero_shot : true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space : false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space : # ["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning : false # Whether a LLM produced with Behavioral Cloning should be used
im_path : " " # Path to the LLM learned with Behavioral Cloning
bot : false # Whether the BabyAI's bot agent should be used

