LM SupCon
1.0.0
การซื้อคืนนี้ครอบคลุมถึงการนำเอกสารต่อไปนี้ไปใช้: Contrastive Learning for Prompt-based Few-shot Language Learners โดย Yiren Jian, Chongyang Gao และ Soroush Vosoughi ซึ่งได้รับการยอมรับจาก NAACL 2022
หากคุณพบว่าการซื้อคืนนี้มีประโยชน์สำหรับการวิจัยของคุณ โปรดพิจารณาอ้างอิงบทความนี้
@inproceedings { jian-etal-2022-contrastive ,
title = " Contrastive Learning for Prompt-based Few-shot Language Learners " ,
author = " Jian, Yiren and
Gao, Chongyang and
Vosoughi, Soroush " ,
booktitle = " Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies " ,
month = jul,
year = " 2022 " ,
address = " Seattle, United States " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2022.naacl-main.408 " ,
pages = " 5577--5587 " ,
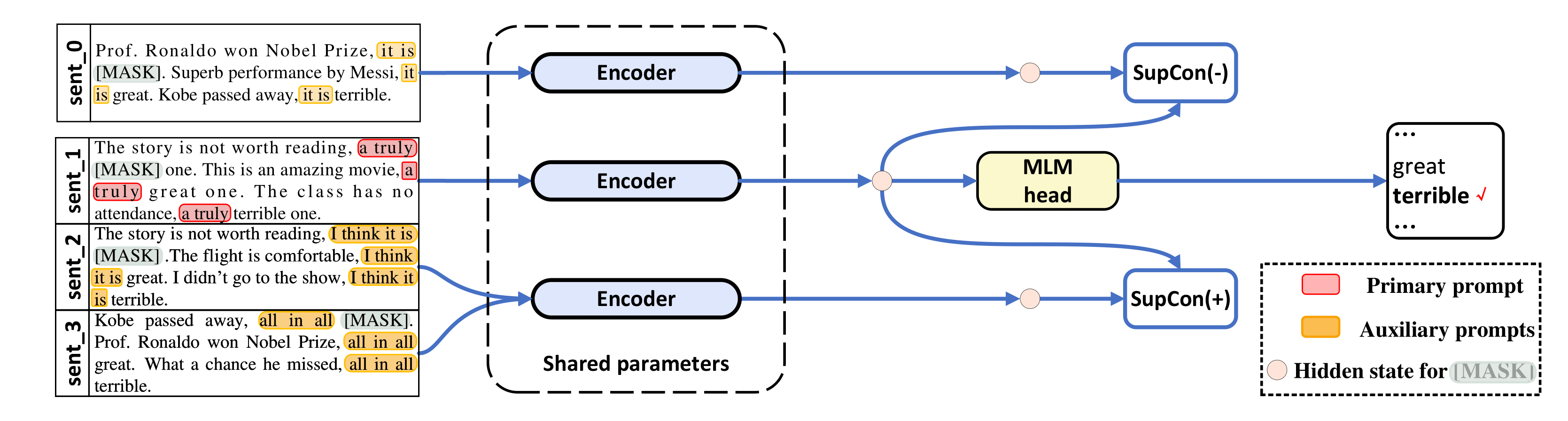
abstract = "The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented {``}views{''} and repel the ones from different classes. We create different {``}views{''} of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification.",
} รหัสของเราถูกยืมอย่างหนักจาก LM-BFF และ SupCon ( /src/losses.py )
repo นี้ได้รับการทดสอบกับ Ubuntu 18.04.5 LTS, Python 3.7, PyTorch 1.6.0 และ CUDA 10.1 คุณจะต้องมี GPU ขนาด 48 GB สำหรับการทดลองกับ RoBERTa-base และ GPU ขนาด 48 GB จำนวน 4x สำหรับ RoBERTa-large เราทำการทดลองกับ Nvidia RTX-A6000 และ RTX-8000 แต่ Nvidia A100 ที่มี 40 GB ก็ควรจะใช้งานได้เช่นกัน
เราใช้ชุดข้อมูลที่ประมวลผลล่วงหน้า (SST-2, SST-5, MR, CR, MPQA, Subj, TREC, CoLA, MNLI, SNLI, QNLI, RTE, MRPC, QQP) จาก LM-BFF LM-BFF นำเสนอสคริปต์ที่เป็นประโยชน์สำหรับการดาวน์โหลดและการเตรียมชุดข้อมูล เพียงเรียกใช้คำสั่งด้านล่าง
cd data
bash download_dataset.shจากนั้นใช้คำสั่งต่อไปนี้เพื่อสร้างชุดข้อมูล 16 ช็อตที่เราใช้ในการศึกษา
python tools/generate_k_shot_data.py พร้อมต์หลัก (เทมเพลต) ที่ใช้สำหรับงานได้ถูกกำหนดไว้ล่วงหน้าใน run_experiments.sh เทมเพลตเสริมที่ใช้เมื่อสร้างอินพุตหลายมุมมองสำหรับการเรียนรู้แบบเปรียบเทียบสามารถพบได้ใน /auto_template/$TASK
สมมติว่าคุณมี GPU หนึ่งตัวในระบบ เราจะแสดงตัวอย่างการทำงานของการปรับแต่งอย่างละเอียดบน SST-5 (เทมเพลตแบบสุ่มและการสาธิตแบบสุ่มสำหรับ "มุมมองเสริม" ของอินพุต)
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 40 # ### batch size
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-base
bash run_experiment.sh
done
done
done
done
rm -rf result/ กรอบงานของเรายังใช้กับวิธีการแบบพร้อมท์โดยไม่มีการสาธิต เช่น TYPE=prompt (ในกรณีนี้ เราจะสุ่มตัวอย่างเทมเพลตสำหรับการสร้าง "มุมมองเสริม") เท่านั้น ผลลัพธ์จะถูกบันทึกไว้ใน log
การใช้ RoBERTa-large เป็นรุ่นพื้นฐานต้องใช้ GPU 4 ตัว โดยแต่ละตัวมีหน่วยความจำ 48 GB คุณต้องแก้ไขบรรทัด 20 ใน src/models.py ให้เป็น def __init__(self, hidden_size=1024) ก่อน
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 10 # ### batch size for each GPU, total batch size is then 40
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-large
bash run_experiment.sh
done
done
done
done
rm -rf result/ python tools/gather_result.py --condition "{'tag': 'exp', 'task_name': 'sst-5', 'few_shot_type': 'prompt-demo'}"
โดยจะรวบรวมผลลัพธ์จาก log และคำนวณค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานจากการทดสอบรถไฟทั้ง 5 ช่วง
หากมีคำถามใด ๆ โปรดติดต่อผู้เขียน
ขอขอบคุณ LM-BFF และ SupCon สำหรับการใช้งานเบื้องต้น


