DialogStudio
1.0.0

กระดาษ, Huggingface, นางแบบ, Twitter
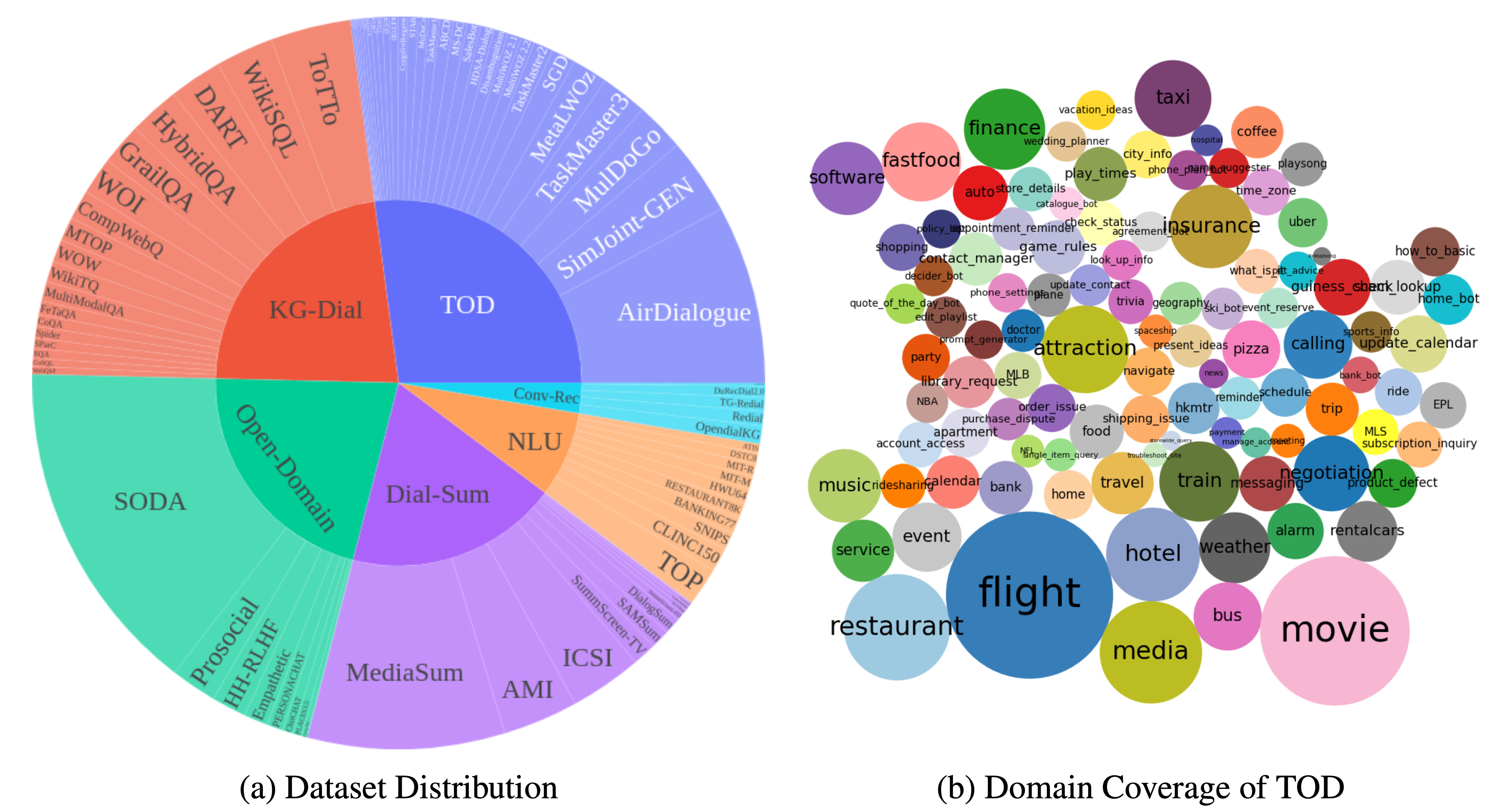
DialogStudio เป็นคอลเล็กชันขนาดใหญ่และชุดข้อมูลไดอะล็อกแบบรวม รูปด้านล่างเป็นการสรุปสถิติทั่วไปที่เกี่ยวข้องกับ DialogStudio DialogStudio รวมชุดข้อมูลแต่ละชุดไว้ด้วยกันโดยยังคงรักษาข้อมูลดั้งเดิมไว้ และสิ่งนี้ช่วยในการสนับสนุนการวิจัยทั้งชุดข้อมูลเดี่ยวและการฝึกอบรม Large Language Model (LLM) รายการชุดข้อมูลทั้งหมดที่มีอยู่อยู่ที่นี่
ข้อมูลสามารถดาวน์โหลดได้ผ่าน Huggingface ตามที่แนะนำใน Loading Data นอกจากนี้เรายังจัดเตรียมตัวอย่างสำหรับชุดข้อมูลแต่ละชุดใน repo นี้ด้วย สำหรับรายละเอียดที่ละเอียดยิ่งขึ้นและเฉพาะหมวดหมู่ โปรดดูแต่ละโฟลเดอร์ที่เกี่ยวข้องกับแต่ละหมวดหมู่ภายในคอลเลกชัน DialogStudio เช่น ชุดข้อมูล MULTIWOZ2_2 ภายใต้หมวดหมู่บทสนทนาเชิงงาน
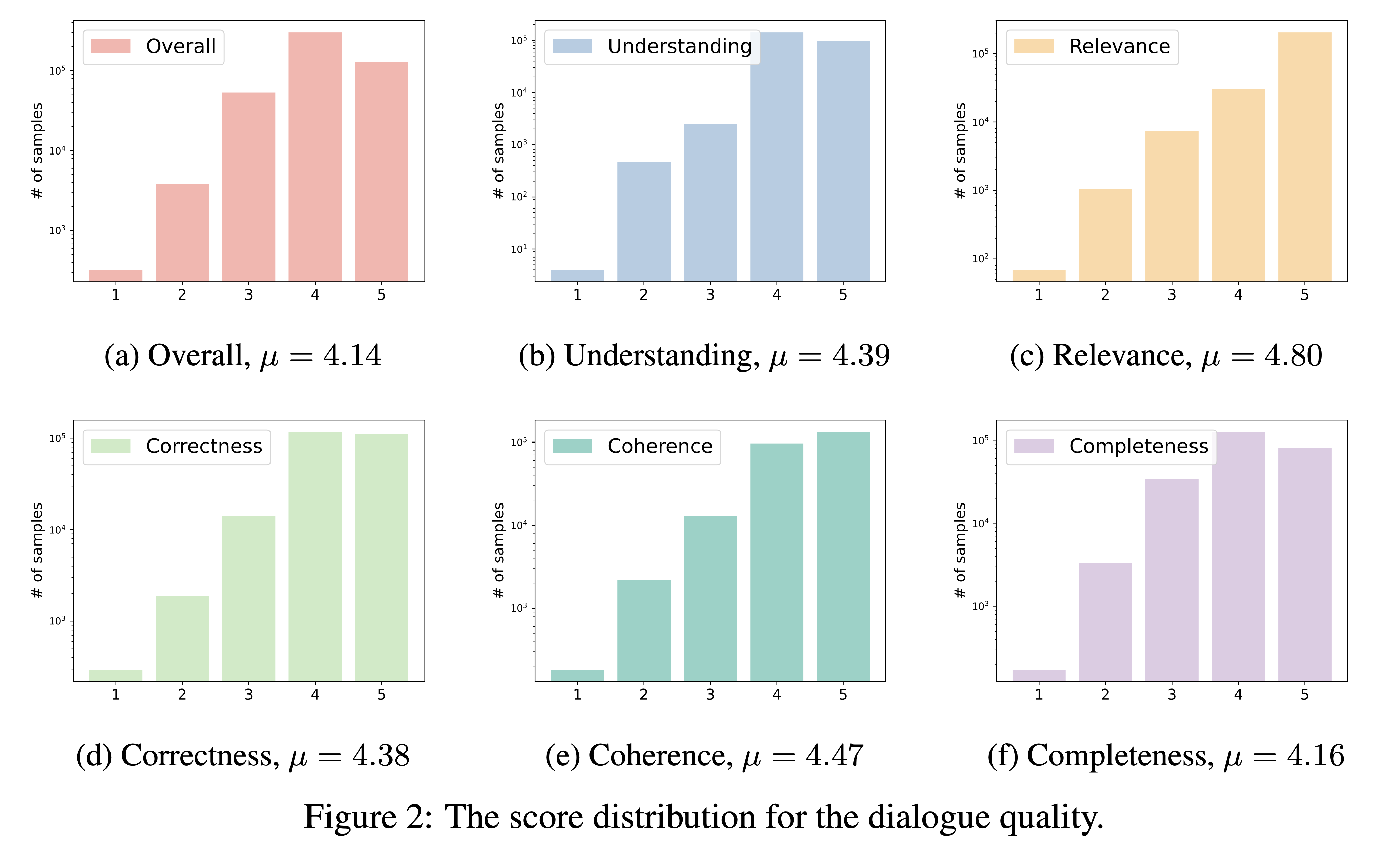
DialogStudio ประเมินคุณภาพบทสนทนาตามเกณฑ์สำคัญ 6 ประการ ได้แก่ ความเข้าใจ ความเกี่ยวข้อง ความถูกต้อง การเชื่อมโยงกัน ความสมบูรณ์ และคุณภาพโดยรวม แต่ละเกณฑ์จะมีการให้คะแนนในระดับ 1 ถึง 5 โดยคะแนนสูงสุดจะสงวนไว้สำหรับการสนทนาที่ยอดเยี่ยม
เนื่องจากชุดข้อมูลจำนวนมากรวมอยู่ใน DialogStudio เราใช้ 'gpt-3.5-turbo' เพื่อประเมินชุดข้อมูลที่แตกต่างกัน 33 ชุด สคริปต์ที่เกี่ยวข้องที่ใช้สำหรับการประเมินนี้สามารถเข้าถึงได้ผ่านลิงก์
ผลลัพธ์ของการประเมินคุณภาพบทสนทนาของเรามีดังต่อไปนี้ เราตั้งใจที่จะเผยแพร่คะแนนการประเมินสำหรับบทสนทนาที่เลือกเป็นรายบุคคลในช่วงเวลาที่กำลังจะมาถึง
คุณสามารถโหลดชุดข้อมูลใดๆ ใน DialogStudio ได้จากฮับ HuggingFace โดยอ้างสิทธิ์ {dataset_name} ซึ่งเป็นชื่อโฟลเดอร์ชุดข้อมูลทุกประการ ชุดข้อมูลที่มีอยู่ทั้งหมดอธิบายไว้ในเนื้อหาชุดข้อมูล
ด้านล่างนี้เป็นตัวอย่างหนึ่งในการโหลดชุดข้อมูล MULTIWOZ2_2 ภายใต้หมวดหมู่บทสนทนาเชิงงาน:
โหลดชุดข้อมูล
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )นี่คือโครงสร้างเอาต์พุตของ MultiWOZ 2.2
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})ชุดข้อมูลถูกแบ่งออกเป็นหลายประเภทในพื้นที่เก็บข้อมูล GitHub และฮับ HuggingFace คุณสามารถตรวจสอบตารางชุดข้อมูลเพื่อดูข้อมูลเพิ่มเติมได้ และคุณสามารถคลิกเข้าไปในแต่ละโฟลเดอร์เพื่อตรวจสอบตัวอย่างบางส่วนได้:
เราได้เผยแพร่โมเดลเวอร์ชัน 1.0 ( DialogStudio -t5-base-v1.0, DialogStudio -t5-large-v1.0, DialogStudio -t5-3b-v1.0) ที่ได้รับการฝึกในชุดข้อมูล DialogStudio ที่เลือกไว้บางส่วน ตรวจสอบการ์ดโมเดลแต่ละใบเพื่อดูรายละเอียดเพิ่มเติม
ด้านล่างนี้เป็นตัวอย่างหนึ่งสำหรับการรันโมเดลบน CPU:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))โครงการของเราเป็นไปตามโครงสร้างต่อไปนี้ที่เกี่ยวข้องกับการออกใบอนุญาต:
สำหรับข้อมูลใบอนุญาตโดยละเอียด โปรดดูใบอนุญาตเฉพาะที่มาพร้อมกับชุดข้อมูลดั้งเดิม สิ่งสำคัญคือต้องทำความคุ้นเคยกับข้อกำหนดเหล่านี้ เนื่องจากเราไม่รับผิดชอบต่อปัญหาด้านใบอนุญาต
เราขอขอบคุณผู้เขียนชุดข้อมูลทุกคนที่มีส่วนร่วมในสาขา Conversational AI อย่างจริงใจ แม้จะมีความพยายามอย่างระมัดระวัง แต่การอ้างอิงหรือการอ้างอิงของเราก็อาจเกิดความไม่ถูกต้องได้ หากคุณพบข้อผิดพลาดหรือการละเว้นใด ๆ โปรดแจ้งปัญหาหรือส่งคำขอดึงเพื่อช่วยเราปรับปรุง ขอบคุณ!
ข้อมูลและโค้ดในพื้นที่เก็บข้อมูลนี้ส่วนใหญ่ได้รับการพัฒนาหรือได้มาจากเอกสารด้านล่างนี้ หากคุณใช้ชุดข้อมูลจาก DialogStudio เราขอให้คุณอ้างอิงทั้งงานต้นฉบับและงานของเราเอง (ได้รับการยอมรับจากผลการวิจัย EACL 2024 ในรูปแบบบทความขนาดยาว)
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
เราขอเชิญชวนการมีส่วนร่วมจากชุมชนอย่างกระตือรือร้น! เข้าร่วมกับเราในภารกิจร่วมกันของเราเพื่อขับเคลื่อนสาขาการสนทนา AI ไปข้างหน้า!


