aug pe
1.0.0
- เอกสาร • ข้อมูล (Yelp/OpenReview/PubMed) • หน้าโครงการ
พื้นที่เก็บข้อมูลนี้ใช้อัลกอริธึม Augmented Private Evolution (Aug-PE) โดยใช้ประโยชน์จากการเข้าถึง API การอนุมานสำหรับโมเดลภาษาขนาดใหญ่ (LLM) เพื่อสร้างข้อความสังเคราะห์ที่เป็นส่วนตัวที่แตกต่างกัน (DP) โดยไม่จำเป็นต้องฝึกโมเดล เราเปรียบเทียบการปรับแต่ง DP-SGD และ Aug-PE:

ภายใต้
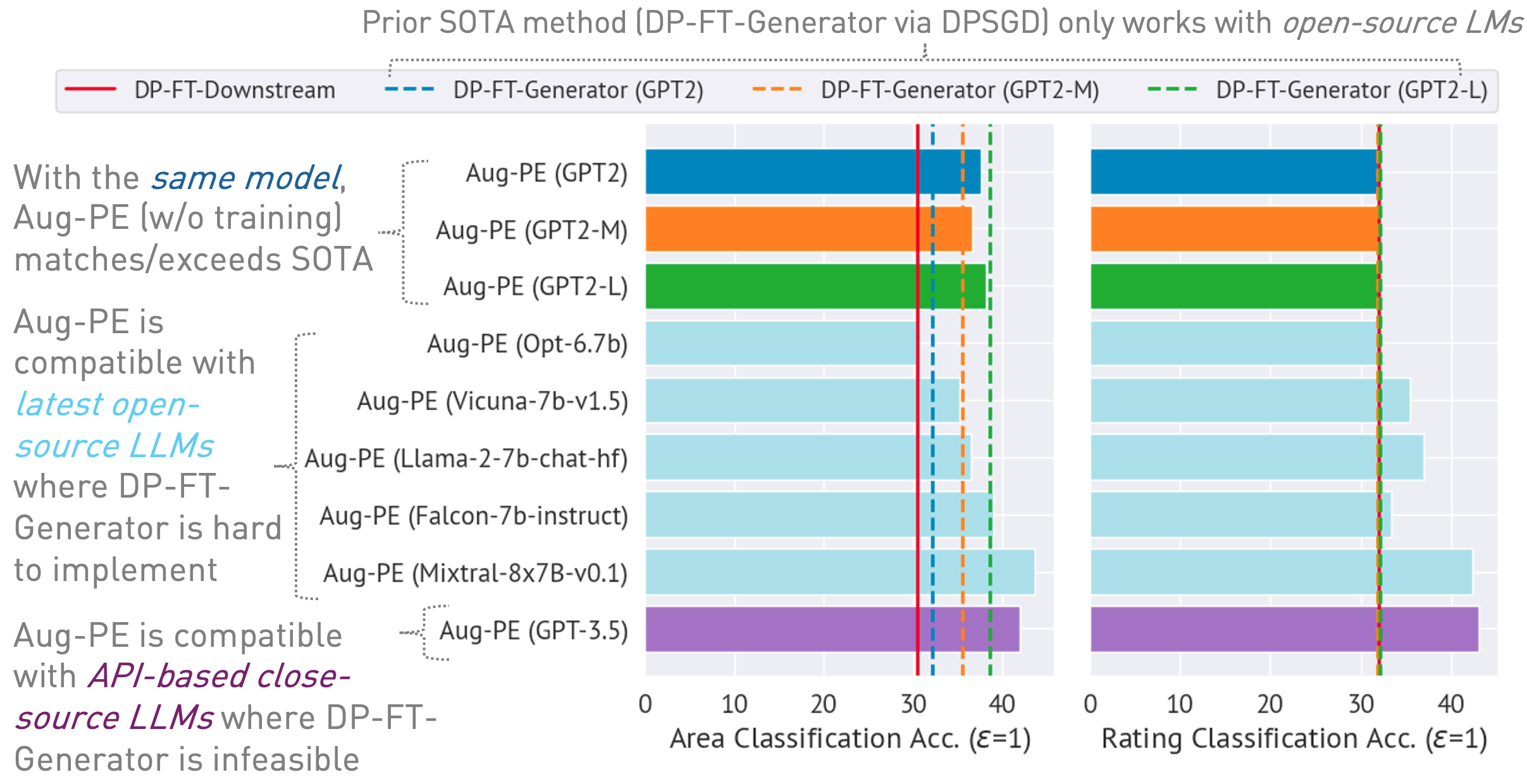
03/13/2024 : หน้าโครงการพร้อมใช้งานแล้ว ซึ่งสรุปอัลกอริทึมและผลลัพธ์03/11/2024 : มีโค้ดและกระดาษ ArXiv จำหน่าย conda env create -f environment.yml
conda activate augpe
ชุดข้อมูลจะอยู่ที่ data/{dataset} โดยที่ dataset คือ yelp , openreview และ pubmed
ดาวน์โหลด Yelp train.csv (1.21G) และ PubMed train.csv (117MB) จากลิงก์นี้หรือดำเนินการ:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvคำอธิบายชุดข้อมูล:
การฝังการประมวลผลล่วงหน้าสำหรับข้อมูลส่วนตัว (บรรทัดที่ 1 ในอัลกอริทึม Aug-PE):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp หมายเหตุ: การฝังคอมพิวเตอร์สำหรับ OpenReview และ PubMed ค่อนข้างรวดเร็ว อย่างไรก็ตาม เนื่องจากชุดข้อมูลขนาดใหญ่ของ Yelp (ตัวอย่างการฝึก 1.9 ล้านตัวอย่าง) กระบวนการจึงอาจใช้เวลาประมาณ 40 นาที
คำนวณระดับเสียงรบกวน DP สำหรับชุดข้อมูลของคุณใน notebook/dp_budget.ipynb โดยพิจารณาจากงบประมาณความเป็นส่วนตัว
สำหรับการแสดงภาพด้วย Wandb ให้กำหนดค่า --wandb_key และ --project ด้วยคีย์และชื่อโปรเจ็กต์ของคุณใน dpsda/arg_utils.py
ใช้ LLM แบบโอเพ่นซอร์สจาก Hugging Face เพื่อสร้างข้อมูลสังเคราะห์:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedไฮเปอร์พารามิเตอร์ที่สำคัญบางประการ:
noise : เสียงรบกวน DPepoch : เราใช้ 10 ยุคสำหรับการตั้งค่า DP สำหรับการตั้งค่าที่ไม่ใช่ DP เราใช้ 20 ยุคสำหรับ Yelp และ 10 ยุคสำหรับชุดข้อมูลอื่นๆmodel_type : โมเดลบนใบหน้ากอด เช่น ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct" , "facebook/opt-6.7b", "lmsys/vicuna-7b-v1.5", "มิสตราไล/Mixtral-8x7B-Instruct-v0.1"]num_seed_samples : จำนวนตัวอย่างสังเคราะห์lookahead_degree : จำนวนรูปแบบสำหรับการประมาณค่าการฝังตัวอย่างสังเคราะห์ (บรรทัดที่ 5 ในอัลกอริทึม Aug-PE) ค่าเริ่มต้นคือ 0 (การฝังตัวเอง)L : เกี่ยวข้องกับจำนวนรูปแบบในการสร้างตัวอย่างสังเคราะห์ของผู้สมัคร (บรรทัดที่ 18 ในอัลกอริทึม Aug-PE)feat_ext : การฝังโมเดลบนตัวแปลงประโยคของ Huggingfaceselect_syn_mode : เลือกตัวอย่างสังเคราะห์ตามคะแนนฮิสโตแกรมหรือความน่าจะเป็น ค่าเริ่มต้นคือ rank (บรรทัดที่ 19 ในอัลกอริทึม Aug-PE)temperature : อุณหภูมิสำหรับการสร้าง LLMปรับแต่งโมเดลดาวน์สตรีมด้วยข้อความสังเคราะห์ DP และประเมินความแม่นยำของโมเดลจากข้อมูลการทดสอบจริง:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance วัดระยะการกระจายการฝัง:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distanceสำหรับกระบวนการที่มีประสิทธิภาพซึ่งรวมขั้นตอนการสร้างและการประเมินผลทั้งหมดไว้ด้วยกัน:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset เราใช้โมเดลโอเพนซอร์สผ่าน Azure OpenAI API โปรดตั้งค่าคีย์และจุดสิ้นสุดของคุณใน apis/azure_api.py
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} engine ที่นี่อาจเป็น gpt-35-turbo ใน Azure
รันสคริปต์ต่อไปนี้เพื่อสร้างข้อมูลสังเคราะห์ ประเมินงานดาวน์สตรีม และคำนวณระยะการกระจายแบบฝังระหว่างข้อมูลจริงและข้อมูลสังเคราะห์:
bash scripts/gpt-3.5-turbo/{dataset}.shเราใช้ข้อความแจ้งที่เกี่ยวข้องกับความยาวของข้อความสำหรับ GPT-3.5 เพื่อควบคุมความยาวของข้อความที่สร้างขึ้น เราขอแนะนำไฮเปอร์พารามิเตอร์เพิ่มเติมหลายรายการที่นี่:
dynamic_len ใช้เพื่อเปิดใช้งานกลไกความยาวไดนามิกword_var_scale : ความแปรปรวนของสัญญาณรบกวนแบบเกาส์ที่ใช้ในการกำหนด target_wordmax_token_word_scale : จำนวนโทเค็นสูงสุดต่อคำ เราตั้งค่า max_token สำหรับการสร้าง LLM ตาม targeted_word (ระบุไว้ในข้อความแจ้ง) และ max_token_word_scale ใช้สมุดบันทึกเพื่อคำนวณความแตกต่างการกระจายความยาวข้อความระหว่างข้อมูลจริงและข้อมูลสังเคราะห์: notebook/text_lens_distribution.ipynb
หากคุณพบว่างานของเรามีประโยชน์ โปรดพิจารณาอ้างอิงดังต่อไปนี้:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}หากคุณมีคำถามใด ๆ ที่เกี่ยวข้องกับรหัสหรือรายงาน โปรดส่งอีเมลถึง Chulin ([email protected]) หรือเปิดประเด็น


