reflexion
1.0.0
Repo นี้เก็บโค้ด การสาธิต และไฟล์บันทึกสำหรับ reflexion : Language Agents with Verbal Reinforcement Learning โดย Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao
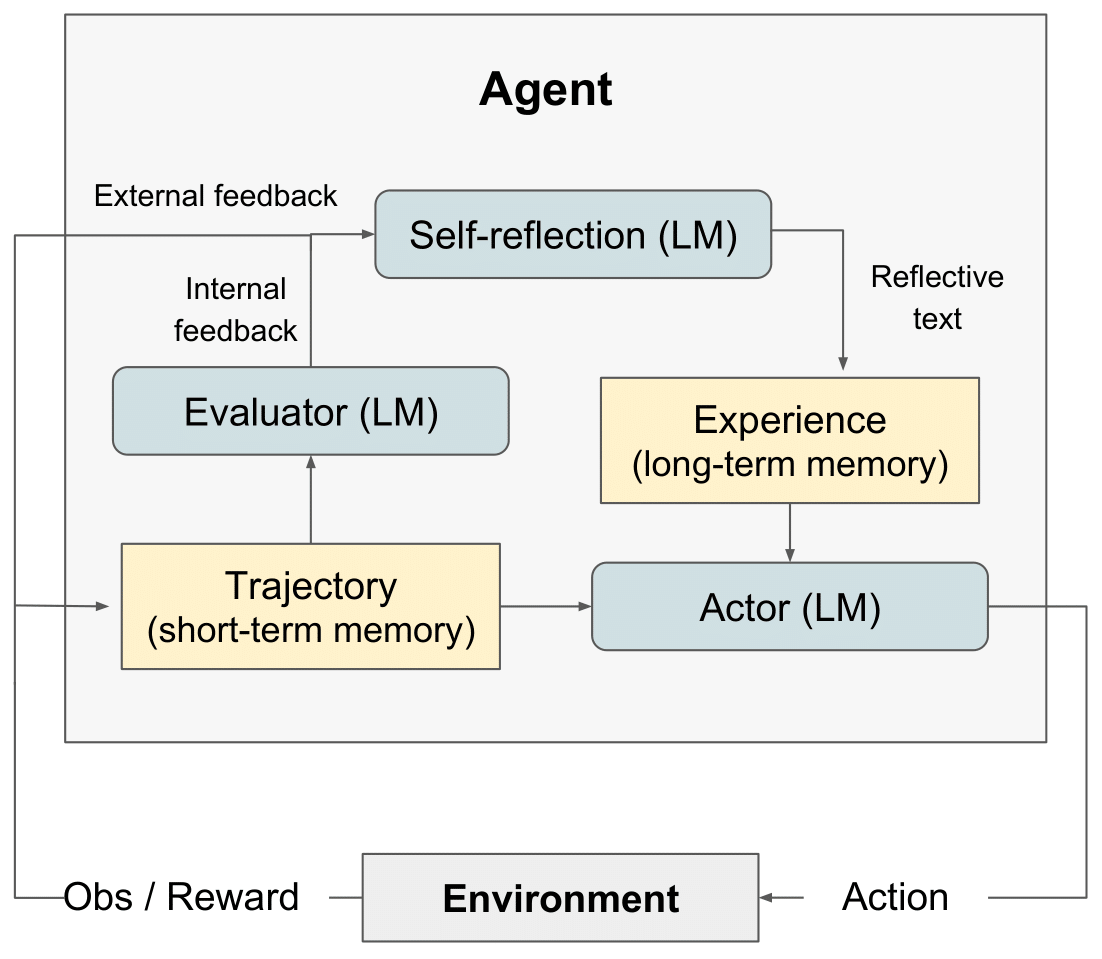 แผนภาพ RL การสะท้อนกลับ" style="max-width: 100%;">
แผนภาพ RL การสะท้อนกลับ" style="max-width: 100%;">
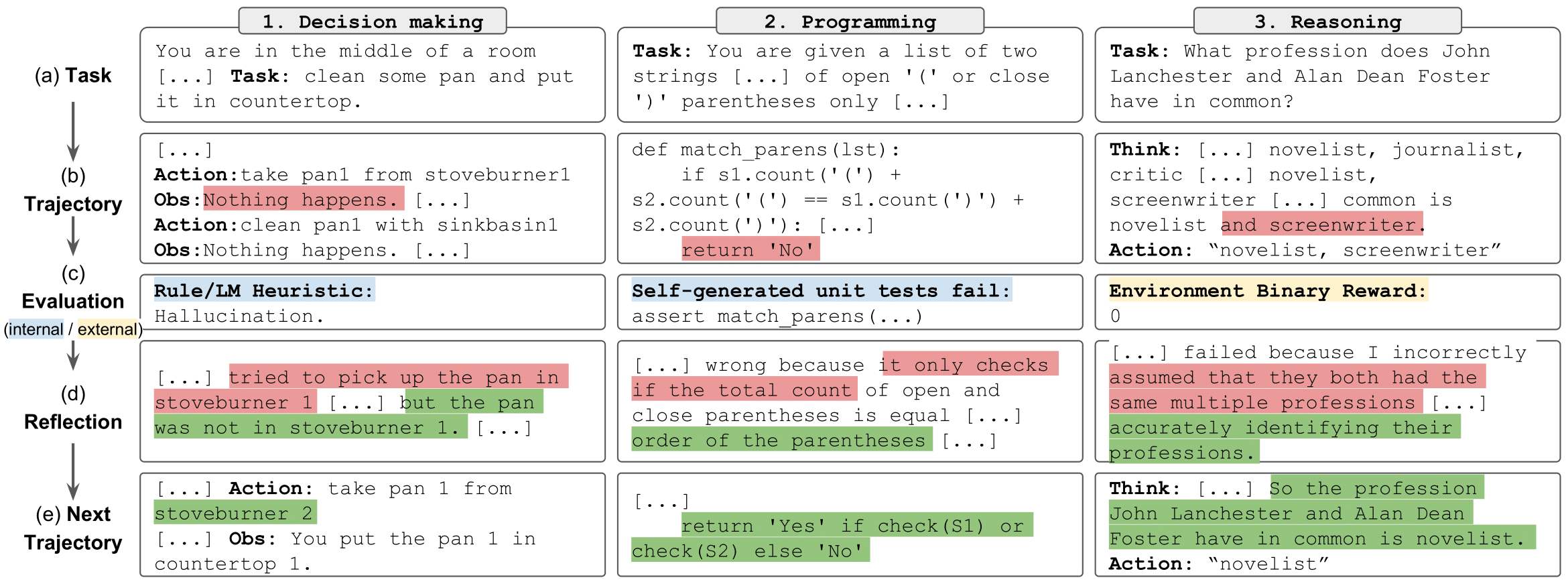 งานสะท้อนกลับ" style="max-width: 100%;">
งานสะท้อนกลับ" style="max-width: 100%;">
เราได้เปิดตัว LeetcodeHardGym ที่นี่
เราได้จัดเตรียมสมุดบันทึกไว้เพื่อเรียกใช้ สำรวจ และโต้ตอบกับผลลัพธ์ของการทดลองการใช้เหตุผลได้อย่างง่ายดาย การทดลองแต่ละครั้งประกอบด้วยตัวอย่างสุ่มคำถาม 100 ข้อจากชุดข้อมูลตัวเบี่ยงเบนความสนใจของ HotPotQA แต่ละคำถามในกลุ่มตัวอย่างจะพยายามโดยตัวแทนที่มีประเภทและกลยุทธ์ reflexion ที่เฉพาะเจาะจง
ในการเริ่มต้น:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY ให้เป็นคีย์ OpenAI API ของคุณ: export OPENAI_API_KEY= < your key > ประเภทตัวแทนจะพิจารณาจากสมุดบันทึกที่คุณเลือกเรียกใช้ ประเภทตัวแทนที่มีอยู่ ได้แก่ :
ReAct - ตัวแทนปฏิกิริยา
CoT_context - CoT Agent ได้รับบริบทสนับสนุนเกี่ยวกับคำถาม
CoT_no_context - CoT Agent ไม่มีบริบทสนับสนุนเกี่ยวกับคำถาม
สมุดบันทึกสำหรับเอเจนต์แต่ละประเภทจะอยู่ในไดเร็กทอรี ./hotpot_runs/notebooks notebooks
สมุดบันทึกแต่ละเครื่องช่วยให้คุณสามารถระบุกลยุทธ์ reflexion ที่เจ้าหน้าที่จะใช้ได้ กลยุทธ์ reflexion ที่มีอยู่ซึ่งกำหนดไว้ใน Enum ประกอบด้วย:
reflexion Strategy.NONE - ตัวแทนไม่ได้รับข้อมูลใด ๆ เกี่ยวกับความพยายามครั้งสุดท้าย
reflexion Strategy.LAST_ATTEMPT - ตัวแทนจะได้รับการติดตามเหตุผลจากความพยายามครั้งสุดท้ายในคำถามตามบริบท
reflexion Strategy. reflexion - ตัวแทนจะได้รับการสะท้อนตนเองในความพยายามครั้งสุดท้ายตามบริบท
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - ตัวแทนจะได้รับทั้งการติดตามการให้เหตุผลและการสะท้อนตนเองในความพยายามครั้งสุดท้ายตามบริบท
โคลน repo นี้และย้ายไปยังไดเร็กทอรี AlfWorld
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs ระบุพารามิเตอร์การรันใน ./run_ reflexion .sh num_trials : จำนวนขั้นตอนการเรียนรู้แบบวนซ้ำ num_envs : จำนวนคู่สภาพแวดล้อมงานต่อการทดลอง run_name : ชื่อสำหรับการรันนี้ use_memory : ใช้หน่วยความจำที่มีอยู่เพื่อจัดเก็บการสะท้อนตนเอง (ปิดเพื่อรันการรันพื้นฐาน) is_resume : ใช้ไดเร็กทอรีการบันทึกเพื่อดำเนินการต่อ การรันครั้งก่อนหน้า resume_dir : ไดเร็กทอรีการบันทึกที่จะเริ่มการรันครั้งก่อนต่อ start_trial_num : หากการรันต่อ ดังนั้นหมายเลขทดลองที่จะเริ่มต้น
ดำเนินการทดลอง
./run_ reflexion .sh บันทึกจะถูกส่งไปยัง ./root/<run_name>
เนื่องจากลักษณะของการทดสอบเหล่านี้ นักพัฒนาซอฟต์แวร์แต่ละรายจึงอาจไม่สามารถเรียกใช้ผลลัพธ์ซ้ำได้ เนื่องจาก GPT-4 มีการเข้าถึงที่จำกัดและมีค่าบริการ API จำนวนมาก การรันทั้งหมดจากกระดาษและผลลัพธ์เพิ่มเติมจะถูกบันทึกไว้ใน ./alfworld_runs/root /root สำหรับการตัดสินใจ, ./hotpotqa_runs/root สำหรับการให้เหตุผล และ ./programming_runs/root สำหรับการเขียนโปรแกรม
ตรวจสอบรหัสสำหรับรหัสต้นฉบับที่นี่
อ่านโพสต์บล็อกที่นี่
ตรวจสอบการใช้งานการทำนายประเภทที่น่าสนใจที่นี่: OpenTau
หากมีคำถามทั้งหมด โปรดติดต่อ [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

