ChatGPT, GenerativeAI และ LLMs Timeline
พื้นที่เก็บข้อมูลนี้จะจัดระเบียบไทม์ไลน์ของเหตุการณ์สำคัญ (ผลิตภัณฑ์ บริการ เอกสาร GitHub บล็อกโพสต์ และข่าวสาร) ที่เกิดขึ้นก่อนและหลังการประกาศ ChatGPT
มีการรวบรวมข้อมูลที่หลากหลายในไทม์ไลน์นี้ โดยเน้นไปที่ LLM และ Generative AI โดยเฉพาะ
บางทีมันอาจเป็นฉากจากประวัติศาสตร์ที่ร้อนแรงที่สุด ฉันก็เลยคิดว่ามันสำคัญที่จะเก็บความทรงจำเหล่านั้นไว้ให้ดี ฉันก็เลยจัดระเบียบมัน
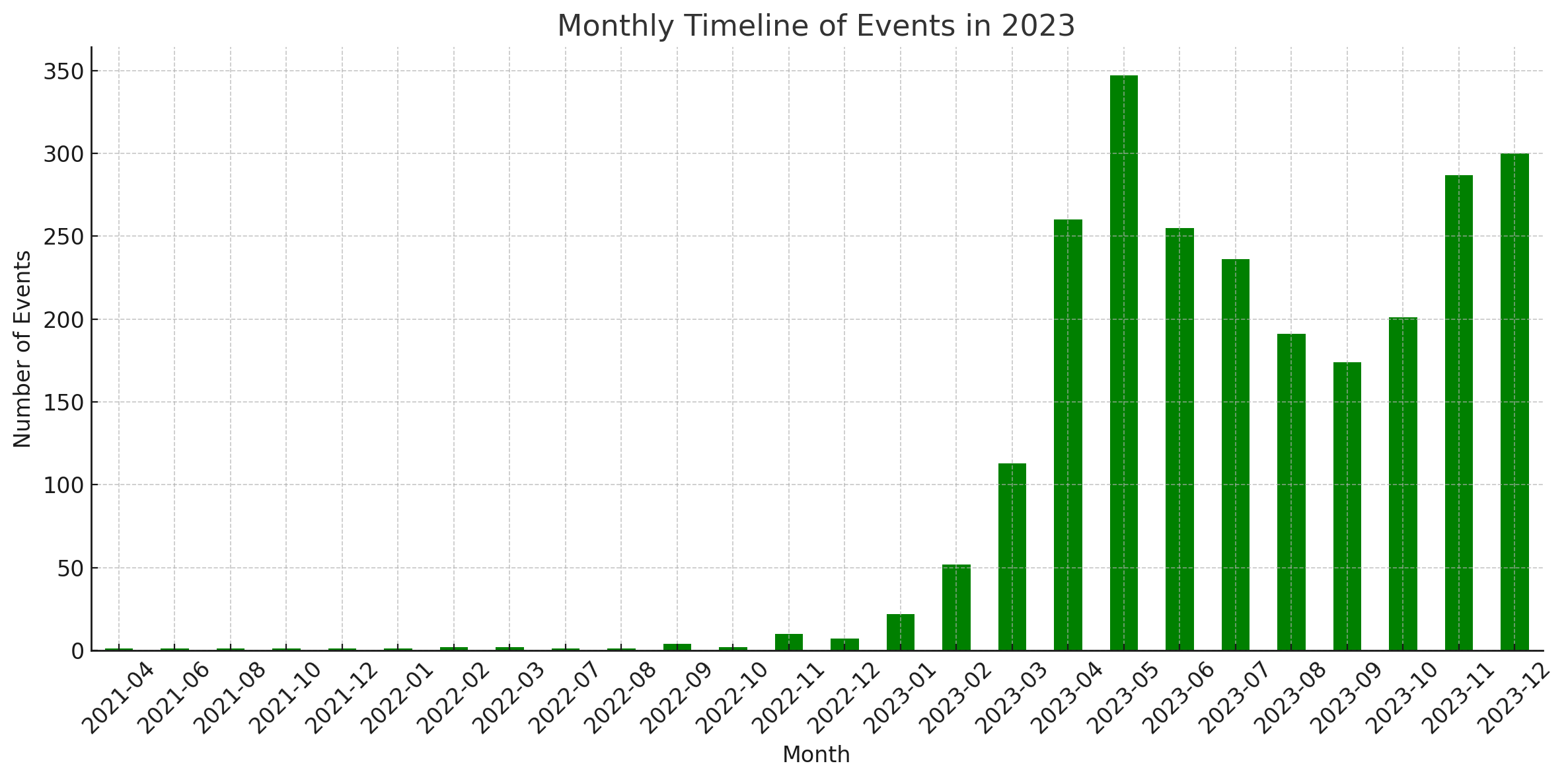
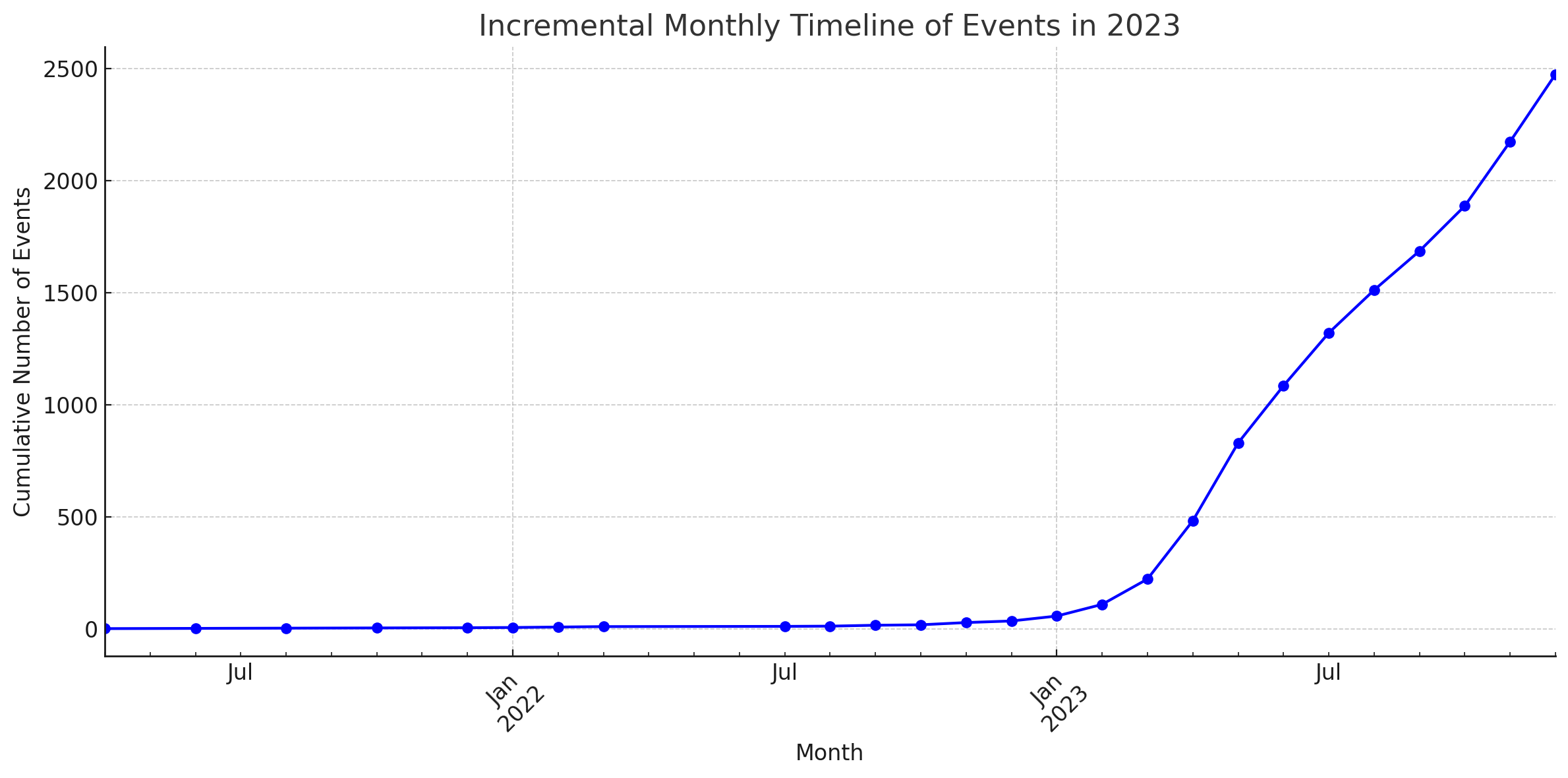
สถิติ
ไดอะแกรมเหล่านี้สร้างขึ้นโดย Code Interpreter ของ ChatGPT
มีส่วนร่วม
ปัญหาและคำขอดึงได้รับการชื่นชมอย่างมาก หากคุณไม่เคยมีส่วนร่วมในโครงการโอเพ่นซอร์สมาก่อน ฉันยินดีเป็นอย่างยิ่งที่จะแนะนำวิธีสร้างคำขอดึงข้อมูลให้คุณทราบ
คุณสามารถเริ่มต้นด้วยการเปิดปัญหาที่อธิบายถึงปัญหาที่คุณต้องการแก้ไข แล้วเราจะดำเนินการต่อจากจุดนั้น
อิโมจิ
arXiv , PDF ?, arxiv-vanity ?, หน้ากระดาษ ?, เอกสารที่มีรหัส ✳️, Github
ใบอนุญาต
เอกสารนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT © Jonghong Jeon(전종홍)
ไทม์ไลน์ V2
2024
- 05/17 - OpenAI โจมตีข้อตกลง Reddit เพื่อฝึก AI บนโพสต์ของคุณ
(ข่าว), - 05/17 - OpenAI ยุบทีมที่เน้นไปที่ความเสี่ยง AI ในระยะยาว น้อยกว่าหนึ่งปีหลังจากประกาศ
(ข่าว), - 05/60 - รายงานทางวิทยาศาสตร์ระหว่างประเทศเกี่ยวกับความปลอดภัยของ AI ขั้นสูง
(บล็อก), - 5/59 - TRANSIC: การถ่ายโอนนโยบาย Sim-to-Real โดยการเรียนรู้จากการแก้ไขออนไลน์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/59 - Toon3D: ชมการ์ตูนจากมุมมองใหม่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/59 - การทดสอบความน่าเชื่อถือของแบบจำลองภาษาขนาดใหญ่ที่ใช้ AI เพื่อดึงข้อมูลระบบนิเวศจากวรรณกรรมทางวิทยาศาสตร์
(ข่าว), - 05/59 - การเรียนรู้ในบริบทจำนวนมากในแบบจำลองพื้นฐานต่อเนื่องหลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - วิธีกดหยุดชั่วคราวบน AI ก่อนที่มันจะสายเกินไป
(ข่าว), - 05/59 - การต่อสายดิน DINO 1.5: พัฒนา "Edge" ของการตรวจจับวัตถุชุดเปิด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - การขุดและการวิเคราะห์ GPT Store
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - Dual3D: การสร้างข้อความเป็น 3D ที่มีประสิทธิภาพและสม่ำเสมอพร้อมการกระจายแฝงแบบหลายมุมมองแบบดูอัลโหมด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - Chameleon: โมเดลรากฐานฟิวชั่นแบบ Modal แบบผสม
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/59 - CAT3D: สร้างทุกสิ่งในรูปแบบ 3 มิติด้วยโมเดลการแพร่กระจายหลายมุมมอง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/5/58 - Xmodel-VLM: ข้อมูลพื้นฐานอย่างง่ายสำหรับโมเดลภาษาการมองเห็นหลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/15 - LoRA เรียนรู้น้อยลงและลืมน้อยลง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/58 - ลายน้ำ AI ที่มองไม่เห็นของ Google จะช่วยระบุข้อความและวิดีโอที่สร้างขึ้น
(ข่าว), - 5/58 - Google I/O 2024: ประกาศทุกอย่างแล้ว
(บล็อก) - 05/58 - BEHAVIOR Vision Suite: การสร้างชุดข้อมูลที่ปรับแต่งได้ผ่านการจำลอง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/58 - ALPINE: เปิดตัวความสามารถในการวางแผนการเรียนรู้แบบถดถอยอัตโนมัติในแบบจำลองภาษา
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - ทำความเข้าใจช่องว่างด้านประสิทธิภาพระหว่างอัลกอริธึมการจัดตำแหน่งออนไลน์และออฟไลน์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - SpeechVerse: โมเดลภาษาเสียงที่สามารถสรุปได้ทั่วไปขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - SpeechGuard: สำรวจความแข็งแกร่งของปฏิปักษ์ของโมเดลภาษาขนาดใหญ่หลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/57 - ไม่ต้องเสียเวลา: บีบเวลาลงในช่องเพื่อทำความเข้าใจเกี่ยวกับวิดีโอบนมือถือ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - Hunyuan-DiT: หม้อแปลงกระจายหลายความละเอียดอันทรงพลังพร้อมความเข้าใจภาษาจีนที่ละเอียด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - การสร้างข้อความเป็นองค์ประกอบที่มีการแสดง Blob หนาแน่น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - นอกเหนือจากกฎหมายมาตราส่วน: การทำความเข้าใจประสิทธิภาพของหม้อแปลงไฟฟ้าด้วยหน่วยความจำแบบเชื่อมโยง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/56 - SambaNova SN40L: การปรับขนาดกำแพงหน่วยความจำ AI ด้วยโฟลว์ข้อมูลและองค์ประกอบของผู้เชี่ยวชาญ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/56 - ขั้นตอนการทำงานของ RLHF: จากการสร้างแบบจำลองรางวัลไปจนถึง RLHF ออนไลน์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - Plot2Code: เกณฑ์มาตรฐานที่ครอบคลุมสำหรับการประเมินแบบจำลองภาษาขนาดใหญ่หลายรูปแบบในการสร้างโค้ดจากโครงเรื่องทางวิทยาศาสตร์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/56 - OpenAI เปิดตัวโมเดล AI ใหม่ล่าสุด GPT-4o
(ข่าว), - 5/56 - MS MARCO Web Search: ชุดข้อมูลเว็บที่มีข้อมูลมากมายขนาดใหญ่พร้อมป้ายกำกับคลิกจริงนับล้าน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - โมเดลภาษาขนาดใหญ่มีการเขียนงานวิจัยมากน้อยเพียงใด
(บล็อก), - 05/13 - สวัสดี GPT-4o
(บล็อก) - 05/13 - Coin3D: การสร้างสินทรัพย์ 3 มิติที่ควบคุมได้และโต้ตอบได้พร้อมการปรับสภาพแบบ Proxy-Guided
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 5/54 - Piccolo2: การฝังข้อความทั่วไปพร้อมการฝึกอบรมการสูญเสียแบบไฮบริดแบบมัลติทาสก์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 - LogoMotion: การสร้างโค้ดที่มองเห็นได้สำหรับแอนิเมชั่น Content-Aware
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 10/05 - INSPECT - เฟรมเวิร์กโอเพ่นซอร์สสำหรับการประเมินโมเดลภาษาขนาดใหญ่
(บล็อก) - 5/53 - สถาบันความปลอดภัย AI เปิดตัวแพลตฟอร์มการประเมินความปลอดภัยของ AI ใหม่
(ข่าว), - 05/07 - SUTRA: สถาปัตยกรรมโมเดลภาษาหลายภาษาที่ปรับขนาดได้
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/07 - Meta เปิดตัว Llama 3 Open-Source LLM
(ข่าว), - 05/03 - อะไรสำคัญเมื่อสร้างโมเดลภาษาวิสัยทัศน์?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - WildChat: บันทึกการโต้ตอบ ChatGPT 1 ล้านรายการในป่า
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - StoryDiffusion: การเอาใจใส่ตนเองอย่างสม่ำเสมอสำหรับการสร้างรูปภาพและวิดีโอระยะไกล
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - Prometheus 2: โมเดลภาษาโอเพ่นซอร์สที่เชี่ยวชาญในการประเมินโมเดลภาษาอื่น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - NeMo-Aligner: ชุดเครื่องมือที่ปรับขนาดได้เพื่อการจัดตำแหน่งโมเดลที่มีประสิทธิภาพ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - LLM-AD: ระบบคำอธิบายเสียงที่ใช้โมเดลภาษาขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - FLAME: การจัดแนวการรับรู้ข้อเท็จจริงสำหรับโมเดลภาษาขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - การปรับแต่งโมเดลข้อความเป็นรูปภาพด้วยคู่รูปภาพเดี่ยว
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - ตัดสนามเกาส์เซียนแบบสเปกตรัมพร้อมการชดเชยทางประสาท
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - การเพิ่มประสิทธิภาพการตั้งค่าการเล่นด้วยตนเองสำหรับการจัดตำแหน่งโมเดลภาษา
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - ขนาดชุดการแก้ไขที่ใหญ่กว่าดีกว่าเสมอหรือไม่? -- การศึกษาเชิงประจักษ์เกี่ยวกับการแก้ไขแบบจำลองด้วย Llama-3
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Clover: การถอดรหัสแบบเก็งกำไรน้ำหนักเบาแบบถดถอยพร้อมความรู้ตามลำดับ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - การตรวจสอบประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่เกี่ยวกับเลขคณิตของโรงเรียนประถมศึกษาอย่างรอบคอบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Visual Fact Checker: เปิดใช้งานการสร้างคำอธิบายภาพที่มีรายละเอียดความเที่ยงตรงสูง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - STT: การติดตามสถานะด้วยหม้อแปลงสำหรับการขับขี่อัตโนมัติ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - SemantiCodec: ตัวแปลงสัญญาณเสียงความหมายบิตเรตต่ำเป็นพิเศษสำหรับเสียงทั่วไป
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Octopus v4: กราฟของโมเดลภาษา
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MotionLCM: การสร้างการเคลื่อนไหวที่ควบคุมได้แบบเรียลไทม์ผ่านโมเดลความสอดคล้องแฝง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MicroDreamer: การสร้าง 3D แบบ Zero-shot ใน sim20 วินาทีโดยการสร้างซ้ำตามคะแนน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Lightplane: ส่วนประกอบที่ปรับขนาดได้สูงสำหรับสนาม Neural 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - KAN: Kolmogorov-Arnold Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - การเพิ่มประสิทธิภาพการตั้งค่าการใช้เหตุผลซ้ำ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/30 - รอยต่อที่มองไม่เห็น: การสร้างฉาก 3 มิติที่ราบรื่นพร้อมการลงสีเชิงลึก
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - InstantFamily: ความสนใจที่ถูกปกปิดสำหรับการสร้างภาพ Multi-ID แบบ Zero-shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - GS-LRM: แบบจำลองการสร้างใหม่ขนาดใหญ่สำหรับการสาดแบบเกาส์เซียน 3 มิติ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - ขยายบริบทของ Llama-3 สิบเท่าในชั่วข้ามคืน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - DOCCI: คำอธิบายของภาพที่เชื่อมต่อและตัดกัน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - โมเดลภาษาขนาดใหญ่ที่ดีขึ้นและเร็วขึ้นผ่านการทำนายโทเค็นหลายโทเค็น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - สไตลัส: การเลือกอะแดปเตอร์อัตโนมัติสำหรับรุ่นการแพร่กระจาย
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - SAGS: การสาดแบบเกาส์เซียนแบบโครงสร้างที่รับรู้ถึงโครงสร้าง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - การแทนที่ผู้พิพากษาด้วยคณะลูกขุน: การประเมินรุ่น LLM ด้วยแผงแบบจำลองที่หลากหลาย
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - โปรไฟล์ AI ทั่วไปของ NIST AI RMF
(ข่าว), - 29/04 - LoRA Land: LLM ที่ได้รับการปรับแต่ง 310 รายการซึ่งเทียบได้กับ GPT-4, รายงานทางเทคนิค
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Kangaroo: การถอดรหัสการเก็งกำไรด้วยตนเองแบบไม่สูญเสียผ่านการออกก่อนกำหนดสองครั้ง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - ความสามารถของแบบจำลองราศีเมถุนในด้านการแพทย์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/28 - ระบายสีโดย Inpaint: เรียนรู้การเพิ่มวัตถุรูปภาพโดยการลบออกก่อน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - LEGENT: แพลตฟอร์มแบบเปิดสำหรับตัวแทนที่เป็นตัวเป็นตน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 27/04 - Ag2Manip: การเรียนรู้ทักษะการจัดการนวนิยายด้วยการนำเสนอด้วยภาพและการกระทำของผู้ไม่เชื่อเรื่องพระเจ้า
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - MaPa: การลงสีวัสดุเสมือนจริงด้วยข้อความสำหรับรูปทรง 3 มิติ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - BlenderAlchemy: การแก้ไขกราฟิก 3D ด้วยโมเดลภาษาวิชั่น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - รายงานทางเทคนิค Tele-FLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - SEED-Bench-2-Plus: การเปรียบเทียบโมเดลภาษาขนาดใหญ่หลายรูปแบบพร้อมความเข้าใจภาพที่มีข้อความมากมาย
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - ทบทวนการประเมินข้อความเป็นรูปภาพกับ Gecko: เกี่ยวกับเมตริก การแจ้ง และการให้คะแนนโดยมนุษย์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - PLLaVA : ส่วนขยาย LLaVA ที่ไม่มีพารามิเตอร์จากรูปภาพไปเป็นวิดีโอสำหรับคำบรรยายวิดีโอที่มีความหนาแน่นสูง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - ทำให้ LLM ของคุณใช้บริบทอย่างเต็มที่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - แสดงรายการทีละรายการ: แหล่งข้อมูลใหม่และกระบวนทัศน์การเรียนรู้สำหรับ LLM หลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - การข้ามเลเยอร์: การเปิดใช้งานการอนุมานทางออกล่วงหน้าและการถอดรหัสการคาดเดาด้วยตนเอง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Interactive3D: สร้างสิ่งที่คุณต้องการด้วยการสร้าง 3D แบบโต้ตอบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - GPT-4V อยู่ไกลแค่ไหน? ปิดช่องว่างของโมเดลหลายรูปแบบเชิงพาณิชย์ด้วย Open-Source Suites
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - ConsistentID: การสร้างภาพบุคคลพร้อมการรักษาเอกลักษณ์แบบละเอียดต่อเนื่องหลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - XC-Cache: การเข้าร่วมข้ามบริบทในแคชเพื่อการอนุมาน LLM ที่มีประสิทธิภาพ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - จริยธรรมของผู้ช่วย AI ขั้นสูง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - PuLID: การปรับแต่ง ID ที่แท้จริงและสายฟ้าผ่านการจัดตำแหน่งที่ตัดกัน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - NeRF-XL: การปรับขนาด NeRF ด้วย GPU หลายตัว
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MotionMaster: การถ่ายโอนการเคลื่อนไหวของกล้องที่ไม่ต้องฝึกฝนสำหรับการสร้างวิดีโอ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - โหมด: ผู้เชี่ยวชาญด้านข้อมูลคลิปผ่านการทำคลัสเตอร์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MMT-Bench: เกณฑ์มาตรฐานหลายรูปแบบที่ครอบคลุมสำหรับการประเมินแบบจำลองภาษาการมองเห็นขนาดใหญ่สู่ AGI แบบมัลติทาสก์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MaGGIe: การปูผิวแทนมนุษย์แบบค่อยเป็นค่อยไปพร้อมคำแนะนำแบบสวมหน้ากาก
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - ID-Aligner: การเพิ่มประสิทธิภาพการรักษาเอกลักษณ์การสร้างข้อความเป็นรูปภาพด้วยการเรียนรู้ผลตอบรับที่ได้รับรางวัล
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - องค์ประกอบภาพที่แก้ไขได้สำหรับการสังเคราะห์ที่ควบคุมได้
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - CatLIP: ความแม่นยำในการจดจำภาพระดับ CLIP พร้อมการฝึกอบรมล่วงหน้าที่เร็วขึ้น 2.7 เท่าบนข้อมูลรูปภาพและข้อความขนาดเว็บ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - BASS: การสุ่มตัวอย่างเก็งกำไรที่ปรับให้เหมาะสมตามความสนใจเป็นกลุ่ม
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - Transformers สามารถเป็นตัวแทนโมเดลภาษา n-gram
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - รายงานทางเทคนิค Pegasus-v1
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - ผู้เชี่ยวชาญแบบผสมผสานหลายหัว
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - FlashSpeech: การสังเคราะห์คำพูดแบบ Zero-Shot ที่มีประสิทธิภาพ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SnapKV: LLM รู้ว่าคุณกำลังมองหาอะไรก่อนการสร้าง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SEED-X: โมเดลหลายรูปแบบพร้อมความเข้าใจและการสร้างหลายรายละเอียดแบบครบวงจร
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - การสร้างฉากประสานงานขึ้นใหม่: การวางคอลเลกชันภาพผ่านการเรียนรู้ส่วนเพิ่มของ Relocalizer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - รายงานทางเทคนิคของ Phi-3: โมเดลภาษาที่มีความสามารถสูงในโทรศัพท์ของคุณ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - OpenELM: กลุ่มโมเดลภาษาที่มีประสิทธิภาพพร้อมกรอบการฝึกอบรมแบบโอเพ่นซอร์สและการอนุมาน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - MultiBooth: มุ่งสู่การสร้างแนวคิดทั้งหมดของคุณในรูปภาพจากข้อความ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - การเรียนรู้การควบคุมการเคลื่อนที่แบบ H-Infinity
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - โมเดล LLaMA3 เชิงปริมาณบิตต่ำดีแค่ไหน? การศึกษาเชิงประจักษ์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - จัดขั้นตอนของคุณ: ปรับตารางการสุ่มตัวอย่างให้เหมาะสมในแบบจำลองการแพร่กระจาย
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - ตัวแทนการตีความอัตโนมัติหลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - Hyper-SD: โมเดลความสอดคล้องแบบแบ่งส่วนวิถีเพื่อการสังเคราะห์ภาพที่มีประสิทธิภาพ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - AdvPrompter: การแจ้งฝ่ายตรงข้ามที่ปรับเปลี่ยนได้รวดเร็วสำหรับ LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/20 - โมเดลความสม่ำเสมอทางดนตรี
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - ลำดับชั้นคำสั่ง: การฝึกอบรม LLM เพื่อจัดลำดับความสำคัญของคำสั่งที่มีสิทธิพิเศษ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - TextSquare: ขยายการปรับแต่งคำสั่งด้วยภาพโดยเน้นข้อความเป็นศูนย์กลาง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - PhysDreamer: ปฏิสัมพันธ์ทางฟิสิกส์กับวัตถุ 3 มิติผ่านการสร้างวิดีโอ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - LLM-R2: โมเดลภาษาขนาดใหญ่ที่ปรับปรุงระบบการเขียนซ้ำตามกฎเพื่อเพิ่มประสิทธิภาพในการสืบค้น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - จริงแค่ไหน? กรอบการประเมินโดยมนุษย์สำหรับตัวอย่างฝ่ายตรงข้ามที่ไม่จำกัด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - เราจะไปได้ไกลแค่ไหนด้วยการซ่อมแซมโปรแกรมระดับฟังก์ชันที่ใช้งานได้จริง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - Groma: Visual Tokenization ที่แปลเป็นภาษาท้องถิ่นสำหรับโมเดลภาษาขนาดใหญ่หลายรูปแบบแบบ Grounding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - Gaussian Splatting จำเป็นต้องมีการเริ่มต้น SFM หรือไม่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - AutoCrawler: Web Agent ที่ก้าวหน้าในการทำความเข้าใจสำหรับการสร้าง Web Crawler
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - TriForce: การเร่งความเร็วแบบไม่สูญเสียของการสร้างลำดับยาวด้วยการถอดรหัสเก็งกำไรแบบลำดับชั้น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - สู่การพัฒนาตนเองของ LLM ผ่านจินตนาการ การค้นหา และการวิจารณ์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - นำรางวัลของคุณกลับมาใช้ใหม่: การโอนโมเดลรางวัลสำหรับการจัดแนวข้ามภาษาแบบ Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - Reka Core, Flash และ Edge: ซีรีส์ของโมเดลภาษาหลากหลายรูปแบบอันทรงพลัง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - OpenBezoar: โมเดลแบบเปิดขนาดเล็ก คุ้มต้นทุน และได้รับการฝึกฝนเกี่ยวกับการผสมผสานข้อมูลคำสั่ง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - MeshLRM: แบบจำลองการสร้างใหม่ขนาดใหญ่สำหรับตาข่ายคุณภาพสูง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - ขอแนะนำเกณฑ์มาตรฐานความปลอดภัยของ AI เวอร์ชัน 0.5 จาก MLCommons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - ขอแนะนำ Meta Llama 3: LLM ที่มีความสามารถแบบเปิดกว้างที่สุดจนถึงปัจจุบัน
(บล็อก) - 04/18 - EdgeFusion: การสร้างข้อความเป็นรูปภาพบนอุปกรณ์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - กะพริบตา: โมเดลภาษาขนาดใหญ่หลายรูปแบบสามารถมองเห็นได้แต่ไม่รับรู้
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - AniClipart: แอนิเมชันภาพตัดปะพร้อมลำดับความสำคัญของการแปลงข้อความเป็นวิดีโอ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - MoA: การผสมผสานของความสนใจสำหรับการแยกเนื้อหาและบริบทในการสร้างภาพส่วนบุคคล
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - FlowMind: การสร้างเวิร์กโฟลว์อัตโนมัติด้วย LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - การพิมพ์แบบไดนามิก: ทำให้คำมีชีวิต
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - API การแพร่กระจาย 3 ที่เสถียรพร้อมใช้งานแล้ว
(twitter), (บล็อก), (สาธิต) - 04/16 - VASA-1: ใบหน้าพูดคุยที่ขับเคลื่อนด้วยเสียงเหมือนจริงสร้างขึ้นแบบเรียลไทม์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/16 - Gina Raimondo รัฐมนตรีกระทรวงพาณิชย์ของสหรัฐอเมริกาประกาศขยายทีมผู้นำสถาบันความปลอดภัย AI ของสหรัฐอเมริกา
(ข่าว), - 04/16 - การสร้างดนตรีรูปแบบยาวพร้อมการแพร่กระจายที่แฝงอยู่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/15 - ผู้ประเมิน LLM รับรู้และชื่นชอบคนรุ่นของตนเอง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/15 - Video2Game: สภาพแวดล้อมแบบเรียลไทม์ โต้ตอบ สมจริง และเข้ากันได้กับเบราว์เซอร์จากวิดีโอเดียว
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - Tango 2: การจัดแนวการสร้างข้อความเป็นเสียงตามการแพร่กระจายผ่านการเพิ่มประสิทธิภาพการตั้งค่าโดยตรง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/15 - การฝึกฝนแบบจำลองการแพร่กระจายแฝงสำหรับการลงสีในสนาม Neural Radiance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - Opus สามารถทำงานเหมือนเครื่องจักรทัวริงได้
(ทวิตเตอร์) - 15/04 - MathGPT: ใช้ประโยชน์จาก Llama 2 เพื่อสร้างแพลตฟอร์มสำหรับการเรียนรู้แบบเฉพาะตัวในระดับสูง
- 04/15 - HQ-Edit: ชุดข้อมูลคุณภาพสูงสำหรับการแก้ไขรูปภาพตามคำสั่ง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - Ctrl-Adapter: กรอบงานที่มีประสิทธิภาพและอเนกประสงค์สำหรับการปรับการควบคุมที่หลากหลายให้เข้ากับรูปแบบการแพร่กระจายใด ๆ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/58 - การบีบอัดแสดงถึงความฉลาดเชิงเส้น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - CompGS: การแสดงฉาก 3D ที่มีประสิทธิภาพผ่านการบีบอัด Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/14 - TextHawk: การสำรวจการรับรู้แบบละเอียดที่มีประสิทธิภาพของโมเดลภาษาขนาดใหญ่หลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/13 - Cathie Wood Muscle เข้าสู่ ChatGPT Boom ด้วยการเดิมพัน OpenAI ใหม่
(ข่าว), - 04/55 - คลิปการปรับขนาด (ลง): การวิเคราะห์ข้อมูล สถาปัตยกรรม และกลยุทธ์การฝึกอบรมที่ครอบคลุม
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - การตรวจสอบการรับรู้ 3 มิติของโมเดล Visual Foundation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - การฝึกอบรม LM ฐานขนาดเล็กล่วงหน้าด้วยโทเค็นน้อยลง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - เรื่องความคงทนของคำแนะนำภาษาสำหรับงานการมองเห็นระดับต่ำ: ข้อค้นพบจากการประมาณความลึก
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - MonoPatchNeRF: การปรับปรุงสนามรัศมีของระบบประสาทด้วยการแนะนำตาข้างเดียวที่ใช้แพทช์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Megalodon: การฝึกอบรม LLM ล่วงหน้าและการอนุมานที่มีประสิทธิภาพพร้อมความยาวบริบทไม่จำกัด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - ChatGPT กำลังเปลี่ยนรูปแบบการเขียนของนักวิชาการหรือไม่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - COCOut: การปรับปรุงการแบ่งส่วน COCO ให้ทันสมัย
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - ชิป AI ลดงบประมาณด้านพลังงานกลับ 99+ เปอร์เซ็นต์
(ข่าว), - 04/12 - AdapterSwap: การฝึกอบรม LLM อย่างต่อเนื่องพร้อมการรับประกันการลบข้อมูลและการควบคุมการเข้าถึง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - ตัวอย่างวิสัยทัศน์ Grok-1.5
(สาธิต) - 04/12 - ความดี ความชั่ว และมนุษยธรรม
(ข่าว), - 04/12 - ผู้ใช้ ChatGPT แบบชำระเงินสามารถเข้าถึง GPT-4 Turbo ได้แล้ว
(ทวิตเตอร์), (ข่าว), , () - 04/11 - ความจำเป็นของบอร์ดมาตรฐานการตรวจสอบ AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/11 - การจดจำหม้อแปลงเพื่อการเรียนรู้อย่างต่อเนื่อง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Amazon เพิ่ม Andrew Ng ซึ่งเป็นผู้นำด้านปัญญาประดิษฐ์เข้ามาในคณะกรรมการบริหาร
(ข่าว), - 04/11 - Adobe กำลังซื้อวิดีโอในราคา 3 ดอลลาร์ต่อนาทีเพื่อสร้างโมเดล AI
(ข่าว), - 04/11 - UltraEval: แพลตฟอร์มน้ำหนักเบาสำหรับการประเมินที่ยืดหยุ่นและครอบคลุมสำหรับ LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - ประสิทธิภาพที่สามารถถ่ายทอดได้และเป็นหลักการสำหรับการแบ่งส่วนคำศัพท์แบบเปิด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - ตัวแทน SWE
(twitter), (สาธิต), , () - 04/11 - ผู้เปลี่ยนเลนเบาบาง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Rho-1: ไม่ใช่ว่าโทเค็นทั้งหมดจะเป็นสิ่งที่คุณต้องการ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - ตัวแทนการวิจัย: การสร้างแนวคิดการวิจัยแบบวนซ้ำผ่านวรรณกรรมทางวิทยาศาสตร์ด้วยแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - RecurrentGemma: การก้าวผ่าน Transformers สำหรับโมเดลภาษาเปิดที่มีประสิทธิภาพ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - OSWorld: การเปรียบเทียบ Multimodal Agents สำหรับงานปลายเปิดในสภาพแวดล้อมคอมพิวเตอร์จริง
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - LLoCO: การเรียนรู้บริบทแบบยาวออฟไลน์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - การใช้ประโยชน์จากโมเดลภาษาขนาดใหญ่ (LLM) เพื่อสนับสนุนคำอธิบายประกอบข้อมูลความเสี่ยงออนไลน์ระหว่างมนุษย์และ AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - JetMoE: เข้าถึงประสิทธิภาพของ Llama2 ด้วยเงิน 0.1 ล้านดอลลาร์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (โครงการ), (twitter), , (✳️), () - 04/11 - HGRN2: Gated Linear RNN พร้อมการขยายสถานะ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - จากคำสู่ตัวเลข: โมเดลภาษาขนาดใหญ่ของคุณเป็นตัวถดถอยที่มีความสามารถอย่างลับๆ เมื่อให้ตัวอย่างในบริบท
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Ferret-v2: พื้นฐานที่ได้รับการปรับปรุงสำหรับการอ้างอิงและการต่อสายดินด้วยโมเดลภาษาขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - ControlNet++: การปรับปรุงการควบคุมแบบมีเงื่อนไขพร้อมผลตอบรับที่สม่ำเสมออย่างมีประสิทธิภาพ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - การตรวจจับความผิดปกติของวิดีโอที่รับรู้บริบทในชุดข้อมูลระยะยาว
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - ChatGPT-3.5, Claude 3 เตะก้นแบบพิกเซลในการแข่งขัน Street Fighter III สำหรับ LLM
(ข่าว), - 11/04 - ChatGPT สามารถทำนายอนาคตได้เมื่อบอกเล่าเรื่องราวที่เกิดขึ้นในอนาคตเกี่ยวกับอดีต
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - แนวทางปฏิบัติที่ดีที่สุดและบทเรียนที่ได้รับจากข้อมูลสังเคราะห์สำหรับโมเดลภาษา
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Benchmark LLM โดยการต่อสู้ใน Street Fighter 3
(สาธิต), , () - 04/11 - บทสนทนาด้วยเสียง: ชุดข้อมูลบทสนทนาสำหรับความเข้าใจด้านเสียงและดนตรี
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - การใช้คำแนะนำในช่วงเวลาที่จำกัดจะปรับปรุงคุณภาพตัวอย่างและการกระจายในแบบจำลองการแพร่กระจาย
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - AmpleGCG: การเรียนรู้รูปแบบการสร้างสากลและที่สามารถถ่ายโอนได้ของคำต่อท้ายฝ่ายตรงข้ามสำหรับการแหกคุก LLM ทั้งแบบเปิดและแบบปิด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 - เครื่องมือความโปร่งใส LM: เครื่องมือเชิงโต้ตอบสำหรับการวิเคราะห์โมเดลภาษาของ Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Gemini 1.5 Pro เข้าใจเสียงแล้ว
(ทวิตเตอร์) - 04/10 - การสำรวจความลึกของแนวคิด: โมเดลภาษาขนาดใหญ่ได้รับความรู้ในเลเยอร์ต่างๆ ได้อย่างไร
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 - สถาปนิกในเมือง: การสร้างฉากในเมือง 3 มิติที่ควบคุมทิศทางได้พร้อมเค้าโครงก่อนหน้า
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - RealmDreamer: การสร้างฉาก 3 มิติที่ขับเคลื่อนด้วยข้อความพร้อมการลงสีและการกระจายความลึก
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - OpenAI และ Meta ใกล้จะปล่อยโมเดล AI ที่สามารถให้เหตุผลได้เหมือนมนุษย์ รายงานกล่าว
(ข่าว), - 04/10 - MetaCheckGPT - เครื่องตรวจจับอาการประสาทหลอนแบบหลายงานโดยใช้ความไม่แน่นอนของ LLM และแบบจำลอง Meta
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Meta ยืนยันว่า LLM โอเพ่นซอร์ส Llama 3 กำลังจะมาในเดือนหน้า
(ข่าว), - 04/10 - ไม่ทิ้งบริบทไว้เบื้องหลัง: Transformers บริบทที่ไม่มีที่สิ้นสุดที่มีประสิทธิภาพพร้อมความสนใจแบบ Infini
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - XAI ที่เพิ่มขึ้น: ความเข้าใจที่น่าจดจำของ AI พร้อมคำอธิบายที่เพิ่มขึ้น
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - DreamScene360: การสร้างฉากข้อความเป็น 3D ที่ไม่จำกัดพร้อมการสาดแบบเกาส์เซียนแบบพาโนรามา
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - มาโปโทฟุมีกาแฟไหม? การสอบสวน LLM เพื่อความรู้ทางวัฒนธรรมที่เกี่ยวข้องกับอาหาร
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - BRAVE: ขยายขอบเขตการเข้ารหัสภาพของโมเดลภาษาวิสัยทัศน์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Mistral สตาร์ทอัพด้าน AI เปิดตัวโมเดล AI ขนาด 281GB เพื่อแข่งขันกับ OpenAI, Meta และ Google
(ข่าว), - 04/10 - การสื่อสารเชิงความหมายทั่วไปที่ขับเคลื่อนโดยเอเจนต์เพื่อการเฝ้าระวังระยะไกล
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - การปรับตัวถอดรหัส LLaMA ให้เป็น Vision Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - แบบสำรวจเกี่ยวกับการบูรณาการ Generative AI เพื่อการคิดอย่างมีวิจารณญาณในเครือข่ายมือถือ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - ลองดูสิ! ทบทวนวิธีประเมิน Jailbreak โมเดลภาษา
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - ไม้บรรทัด: โมเดลภาษาบริบทยาวของคุณมีขนาดบริบทที่แท้จริงเท่าใด
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - การแก้ไขความหนาแน่นในการสาดแบบเกาส์เซียน
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - การสร้างวัตถุมือถือขึ้นใหม่ในรูปแบบ 3 มิติ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - RAR-b: การใช้เหตุผลเป็นเกณฑ์มาตรฐานในการดึงข้อมูล
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - วิศวกรรมการรักษาความเป็นส่วนตัวทันที: แบบสำรวจ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - ในการประเมินประสิทธิภาพของซอร์สโค้ดที่สร้างโดย LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/09 - รายงานทางเทคนิค OmniFusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - MuPT: หม้อแปลงไฟฟ้าที่ได้รับการฝึกฝนเชิงสัญลักษณ์เชิงสัญลักษณ์
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - MiniCPM: เผยศักยภาพของโมเดลภาษาขนาดเล็กพร้อมกลยุทธ์การฝึกอบรมที่ปรับขนาดได้
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Magic-Boost: เพิ่มการสร้าง 3D ด้วย Mutli-View Conditioned Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - LLM2Vec: โมเดลภาษาขนาดใหญ่เป็นเครื่องมือเข้ารหัสข้อความที่ทรงพลังอย่างลับๆ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - InternLM-XComposer2-4KHD: โมเดลภาษาการมองเห็นขนาดใหญ่รุ่นบุกเบิกในการจัดการความละเอียดตั้งแต่ 336 พิกเซลไปจนถึง 4K HD
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Hash3D: การเร่งความเร็วโดยไม่ต้องฝึกฝนสำหรับการสร้าง 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Google เปิดตัวโครงการโอเพ่นซอร์สสำหรับ AI เชิงสร้างสรรค์
(ข่าว), - 04/52 - ช้างไม่มีวันลืม: การท่องจำและการเรียนรู้ข้อมูลแบบตารางในแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Apple เพิ่งเปิดตัว Ferret-UI LLM ใหม่ ซึ่ง AI นี้สามารถอ่านหน้าจอ iPhone ของคุณได้
(ข่าว), - 04/09 - AEGIS: การดูแลความปลอดภัยของเนื้อหา AI ที่ปรับเปลี่ยนได้แบบออนไลน์พร้อมคณะผู้เชี่ยวชาญ LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - YaART: อีกหนึ่งเทคโนโลยีการเรนเดอร์ ART
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - WILBUR: การเรียนรู้ในบริบทที่ปรับเปลี่ยนได้สำหรับตัวแทนเว็บที่แข็งแกร่งและแม่นยำ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - UniFL: ปรับปรุงการแพร่กระจายที่เสถียรผ่านการเรียนรู้คำติชมแบบรวม
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - อิคารัสที่ไร้การควบคุม: การสำรวจความเสี่ยงที่อาจเกิดขึ้นจากการป้อนข้อมูลรูปภาพในความปลอดภัยของโมเดลภาษาขนาดใหญ่หลายรูปแบบ
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - กระดานผู้นำภาพหลอน - ความพยายามแบบเปิดเพื่อวัดภาพหลอนในแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - ปัญหาการเลือกข้อเท็จจริงในการซ่อมแซมโปรแกรมที่ใช้ LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/08 - Swapanything: การเปิดใช้งานการแลกเปลี่ยนวัตถุโดยพลการในการแก้ไขภาพส่วนตัว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - Sambalingo: การสอนรูปแบบภาษาขนาดใหญ่ภาษาใหม่ภาษาใหม่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - การเพิ่มประสิทธิภาพการตั้งค่าเชิงลบ: จากการล่มสลายของหายนะ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - Naver เปิดตัว Hyperclova X LLM หลายภาษามันจะใช้ในการสร้าง Sovereign AI สำหรับเอเชีย
(ข่าว), - 04/08 - MOMA: อะแดปเตอร์ LLM Multimodal สำหรับการสร้างภาพส่วนบุคคลที่รวดเร็ว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - MedExpqa: การเปรียบเทียบหลายภาษาของแบบจำลองภาษาขนาดใหญ่สำหรับการตอบคำถามทางการแพทย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08- MA-LMM: โมเดลขนาดใหญ่หลายรูปแบบสำหรับการทำความเข้าใจวิดีโอระยะยาว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - Layoutllm: การปรับแต่งการปรับแต่งด้วยโมเดลภาษาขนาดใหญ่สำหรับการทำความเข้าใจเอกสาร
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/08 - ferret -ui: ความเข้าใจ UI มือถือที่มีสายงานด้วย LLMs หลายรูปแบบ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - การประเมินความสามารถในการใช้เหตุผลของการแทรกแซงของแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - Eagle and Finch: RWKV พร้อมสถานะเมทริกซ์และการเกิดซ้ำแบบไดนามิก
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/08 - codeclm: การจัดแนวโมเดลภาษากับข้อมูลสังเคราะห์ที่ปรับแต่ง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/08 - Autocoderover: การปรับปรุงโปรแกรมอัตโนมัติ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/07 - TIMEGPT ในการพยากรณ์โหลด: มุมมองของโมเดลชุดเวลาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/07 - Openai ถอดความวิดีโอ YouTube มากกว่าล้านชั่วโมงเพื่อฝึก GPT -4
(ข่าว), - 04/07 - MAGICTIME: การสร้างวิดีโอแบบไทม์แลปส์เป็นตัวจำลองการเปลี่ยนแปลง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/07 - byteedit: เพิ่ม, ปฏิบัติตามและเร่งการแก้ไขภาพทั่วไป
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/06 - การลงคะแนนเสียงส่วนใหญ่ของแพทย์ช่วยเพิ่มความเหมาะสมของการพึ่งพา AI ในพยาธิวิทยา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (SS) - 04/06- Diffusion-RWKV: สเกลสถาปัตยกรรมคล้าย RWKV สำหรับรุ่นการแพร่กระจาย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/06- Datenerf: การแก้ไขข้อความเชิงลึกที่รับรู้ของ NERFS
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/06- BeyondScene: การสร้างฉากที่มีความละเอียดสูงของมนุษย์เป็นศูนย์กลางด้วยการแพร่กระจายก่อนหน้า
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/06 - การจัดรูปแบบการแพร่กระจายโดยการเพิ่มประสิทธิภาพยูทิลิตี้ของมนุษย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/06 - กรณีสำหรับการพัฒนารูปแบบพื้นฐานสำหรับการวางแผนงานที่คล้ายกันตั้งแต่เริ่มต้น
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - ช่องโหว่ LLM ที่เพิ่มขึ้นจากการปรับแต่งและการคำนวณเชิงปริมาณ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - SpatialTracker: ติดตามพิกเซล 2D ใด ๆ ในพื้นที่ 3D
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - การฝึกทักษะทางสังคมด้วยรูปแบบภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - ซิกมา: เครือข่าย Siamese Mamba สำหรับการแบ่งส่วนความหมายแบบหลายรูปแบบ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/05 - Splatting Gaussian ที่แข็งแกร่ง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - Physavatar: การเรียนรู้ฟิสิกส์ของอวตาร 3 มิติที่แต่งตัว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05- Koala: Key Frame-onditioned Long Video-llm
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - เบาะแส: การประเมินความเข้าใจภาษาทางคลินิกสำหรับ LLMS
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - LLM เล็ก ๆ ของจีน: การเตรียมรูปแบบภาษาขนาดใหญ่ที่เน้นภาษาจีนเป็นศูนย์กลาง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/05 - ช่วยเหลือมนุษย์ในการเปรียบเทียบที่ซับซ้อน: การเปรียบเทียบข้อมูลอัตโนมัติในระดับ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - AI embodied AI ที่มีสองแขน: การเรียนรู้แบบไม่มีการยิงความปลอดภัยและโมดูลาร์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (SS) - 04/04 - วิวัฒนาการแบบจำลองภาษา: มุมมองการเรียนรู้ซ้ำ ๆ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04- การสร้างภาพของการใช้เหตุผลเชิงพื้นที่ในรูปแบบภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) (Twitter), - 04/04 - ไม่มี "zero -shot" โดยไม่มีข้อมูลแบบเอ็กซ์โปเนนเชีย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/04 - การประเมิน LLMs ในการตรวจจับข้อผิดพลาดในการตอบสนอง LLM
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/04 - การประเมินแบบจำลองภาษากำเนิดในการสกัดข้อมูลเป็นการแก้ไขคำถามอัตนัย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/04 - การเพิ่มประสิทธิภาพของแนชโดยตรง: การสอนแบบจำลองภาษาเพื่อปรับปรุงตนเองด้วยความชอบทั่วไป
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04- CBR-RAG: การใช้เหตุผลตามกรณีสำหรับการสร้างการเติมเงินใน LLMS สำหรับการตอบคำถามทางกฎหมาย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - ความสามารถของแบบจำลองภาษาขนาดใหญ่ในวิศวกรรมควบคุม: การศึกษาเกณฑ์มาตรฐานเกี่ยวกับ GPT -4, Claude 3 Opus และ Gemini 1.0 Ultra
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - CanttalkAboutthis: การจัดแนวโมเดลภาษาให้อยู่ในหัวข้อในบทสนทนา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - Autowebglm: bootstrap และเสริมสร้างตัวแทนนำทางเว็บแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/04 - การฝึกอบรม LLMS ผ่านข้อความที่ถูกบีบอัด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - REFT: การเป็นตัวแทน finetuning สำหรับรูปแบบภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/04- Red Teaming GPT-4V: GPT-4V ปลอดภัยต่อการโจมตีของการโจมตีด้วยการแหกคุกแบบ UNI/Multi-Modal หรือไม่?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04- Rall-E: การสร้างแบบจำลองภาษาตัวแปลงสัญญาณที่แข็งแกร่งด้วยการกระตุ้นด้วยความคิดแบบห่วงโซ่สำหรับการสังเคราะห์ข้อความเป็นคำพูด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - PointInfinity: โมเดลการแพร่กระจายของจุดที่มีความละเอียด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04- MinIGPT4-VIDEO: การพัฒนา LLM หลายรูปแบบสำหรับการทำความเข้าใจวิดีโอด้วยโทเค็นภาพรวม interleaved
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04- Comat: การจัดแนวโมเดลการแพร่กระจายแบบข้อความกับภาพกับการจับคู่แนวคิดภาพกับข้อความ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - CodeEditorBench: การประเมินความสามารถในการแก้ไขรหัสของแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/04 - Autowebglm: bootstrap และเสริมสร้างตัวแทนนำทางเว็บแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/03 - การสร้างแบบจำลองอัตโนมัติแบบมองเห็น: การสร้างภาพที่ปรับขนาดได้ผ่านการทำนายระดับถัดไป
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/03- ความสามารถในการปรับขนาดของการสร้างข้อความต่อภาพการแพร่กระจาย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/03 - การแหกคุกหลายครั้ง
- - 04/03- LVLM-Intrepret: เครื่องมือการตีความได้สำหรับโมเดลภาษาวิสัยทัศน์ขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/03 - แบบจำลองภาษาเป็นคอมไพเลอร์: การจำลองการดำเนินการ pseudocode ช่วยปรับปรุงการใช้เหตุผลอัลกอริทึมในรูปแบบภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/03- สทันที ๆ : อาหารกลางวันฟรีไปสู่การรักษาสไตล์ในการสร้างข้อความเป็นภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/03 - Freditor: การแก้ไข NERF ที่มีความบริสุทธิ์สูงและสามารถถ่ายโอนได้โดยการสลายตัวของความถี่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/03- การเชื่อมโยงข้ามทำให้การอนุมานยุ่งยากในรูปแบบการแพร่กระจายแบบข้อความกับภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/03- chatglm-math: การปรับปรุงการแก้ปัญหาทางคณิตศาสตร์ในรูปแบบภาษาขนาดใหญ่ที่มีไปป์ไลน์ critique ด้วยตนเอง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/02 - สหราชอาณาจักรและสหรัฐอเมริกาประกาศความร่วมมือด้านวิทยาศาสตร์แห่งความปลอดภัย AI
(ข่าว), - 04/02 - แบบจำลองภาษาขนาดใหญ่เป็นเครื่องกำเนิดโดเมนการวางแผน
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (SS) - 04/02 - Poro 34b และพรแห่งการพูดได้หลายภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/02 - Octopus v2: รูปแบบภาษาระหว่างอุปกรณ์สำหรับ Super Agent
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/02- ส่วนผสมของความลึก: การจัดสรรการคำนวณแบบไดนามิกในรูปแบบภาษาที่ใช้หม้อแปลง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/02- LLMS บริบทยาวต่อสู้กับการเรียนรู้ในบริบทยาว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/02 - LLM -ABR: การออกแบบอัลกอริทึมบิตเรตแบบปรับตัวผ่านแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/02 - แบบจำลองภาษาขนาดใหญ่สามารถเปลี่ยนอนาคตของการดูแลสุขภาพพฤติกรรม: ข้อเสนอสำหรับการพัฒนาและการประเมินผลที่รับผิดชอบ
- - 04/02 - รายงานทางเทคนิค Hyperclova x
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/02- Cameractrl: เปิดใช้งานการควบคุมกล้องสำหรับการสร้างข้อความถึงวิดีโอ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/02 - การเพิ่มเหตุผล LLM ให้เหตุผลทั่วไปด้วยต้นไม้ที่ชอบ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01 - สตรีมของการค้นหา (SOS): เรียนรู้ที่จะค้นหาในภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01 - LLM เป็นผู้บงการ: การสำรวจการใช้เหตุผลเชิงกลยุทธ์ด้วยแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/01 - การเพิ่มขึ้นและเพิ่มขึ้นของโมเดลภาษาขนาดใหญ่ AI (LLMS)
(บล็อก),, - 04/01 - การสตรีมวิดีโอความหนาแน่น
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01 - รูปแบบการวัดความคล้ายคลึงกันในรูปแบบการแพร่กระจาย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01- ทำให้ถูกต้อง: การปรับปรุงความสอดคล้องเชิงพื้นที่ในโมเดลข้อความเป็นภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01 - สำหรับ บริษัท AI ที่ใช้ข้อมูลทางอินเทอร์เน็ตมีขนาดเล็กเกินไป
(ข่าว), - 04/01- Flexidreamer: รุ่นเดียวถึง 3D กับ Flexicubes
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/01 - Evalverse: ห้องสมุดที่เป็นเอกภาพและเข้าถึงได้สำหรับการประเมินแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01 - การเพิ่มประสิทธิภาพการตั้งค่าโดยตรงของวิดีโอโมเดลหลายรูปแบบขนาดใหญ่จากรางวัลรูปแบบภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 04/01 - DBRX, การเตรียมการอย่างต่อเนื่อง, รางวัล Bench, การอนุมานเร็วขึ้นและอื่น ๆ
(บล็อก),, - 04/01- Cosmicman: โมเดลพื้นฐานแบบข้อความถึงภาพสำหรับมนุษย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/01 - เครือข่ายประสาทที่รับรู้สภาพสำหรับการสร้างภาพควบคุม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/01 - ใหญ่กว่านั้นไม่ดีกว่าเสมอไป: คุณสมบัติการปรับขนาดของแบบจำลองการแพร่กระจายแฝง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 04/01 - นักเคมี Superhuman รุ่นใหญ่หรือไม่?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/31 - Wavllm: ไปสู่การพูดที่แข็งแกร่งและปรับตัวได้แบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/31 - เหนื่อยกับปลั๊กอิน? แบบจำลองภาษาขนาดใหญ่สามารถเป็นผู้แนะนำแบบครบวงจร
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/30 - สำรวจการเรียนรู้การเสริมแรงแบบจำลองภาษาขนาดใหญ่: แนวคิดอนุกรมวิธานและวิธีการ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/30 - ST -LLM: แบบจำลองภาษาขนาดใหญ่เป็นผู้เรียนทางโลกที่มีประสิทธิภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (SS) - 03/30- การฝึกฝนเสียงรบกวนจากรูปแบบภาษาที่รับรู้
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/30 - Magritte: การรับรู้ 3 มิติและการกำเนิดจากภาพ, topview และข้อความ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (SS) - 03/30- Aurora-M: โมเดลภาษาโอเพนซอร์สหลายภาษาชุดแรกตามคำสั่งผู้บริหารของสหรัฐอเมริกา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - การตรวจจับปัญหาที่ไม่สามารถแก้ไขได้: การประเมินความน่าเชื่อถือของแบบจำลองภาษาการมองเห็น
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29- Transformer-Lite: การปรับใช้ประสิทธิภาพสูงของรุ่นภาษาขนาดใหญ่บน GPU โทรศัพท์มือถือ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29- snap-it, tap-it, splat-it: tactile-informed 3D gaussian splatting สำหรับการสร้างพื้นผิวที่ท้าทาย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - Realm: ความละเอียดอ้างอิงเป็นการสร้างแบบจำลองภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - NVIDIA H200 GPUS CRUSH MLPERF LLM การอนุมาน LLM ของ MLPERF
(ข่าว), - 03/29 - Mambamixer: แบบจำลองพื้นที่สถานะการเลือกที่มีประสิทธิภาพพร้อมโทเค็นคู่และการเลือกแชนเนล
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - LLAVA -GEMMA: การเร่งรูปแบบพื้นฐานหลายรูปแบบด้วยรูปแบบภาษาขนาดกะทัดรัด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29- Instantsplat: การสปิตติ้งแบบเกาส์ที่ไม่มีเบาบาง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - Gecko: การฝังข้อความอเนกประสงค์กลั่นจากรุ่นภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - Dijiang: แบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพผ่านเคอร์เนลขนาดกะทัดรัด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/29- DeepMind พัฒนาแอพที่ใช้ AI ซึ่งสามารถตรวจสอบ LLMS ได้จริง
(ข่าว), - 03/29 - CTRL -SIM: ตัวแทนขับเคลื่อนแบบตอบโต้และควบคุมได้พร้อมการเรียนรู้เสริมแรงแบบออฟไลน์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/29 - เรากำลังใช้วิธีที่ถูกต้องสำหรับการประเมินโมเดลภาษาวิสัยทัศน์ขนาดใหญ่หรือไม่?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/28 - SDPO: อย่าใช้ข้อมูลของคุณทั้งหมดในครั้งเดียว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/28 - MESH2NERF: การกำกับดูแลโดยตรงของตาข่ายสำหรับการเป็นตัวแทนสนามประสาทและการสร้าง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/28 - การท่องจำย่อหน้าภาษาท้องถิ่นในรูปแบบภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/28 - Jamba: โมเดลภาษา Transformer -Mamba ไฮบริด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/28 - Gaussiancube: โครงสร้างแบบเกาส์เซียนโดยใช้การขนส่งที่ดีที่สุดสำหรับการสร้างแบบจำลองการกำเนิด 3 มิติ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/28 - Claude 3 แซง GPT -4 ในการต่อสู้ของบอท AI นี่คือวิธีการดำเนินการในการดำเนินการ
(ข่าว), - 03/28 - ประกาศ Grok -1.5
(บล็อก), (สาธิต),, - 03/27 - เส้นทางสู่ความเป็นอิสระทางกฎหมาย: วิธีการที่สามารถอธิบายได้และอธิบายได้ในการแยกการแปลงการโหลดและการคำนวณข้อมูลทางกฎหมายโดยใช้แบบจำลองภาษาขนาดใหญ่ระบบผู้เชี่ยวชาญและเครือข่ายแบบเบย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27 - Vitar: Vision Transformer ด้วยความละเอียดใด ๆ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27- สู่รูปแบบภาษาภาษาอังกฤษโลกสำหรับผู้ช่วยเสมือนจริงในอุปกรณ์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27 - TextCraftor: ตัวเข้ารหัสข้อความของคุณสามารถเป็นตัวควบคุมคุณภาพของภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27 - ObjectDrop: bootstrapping counterfactuals สำหรับการกำจัดและการแทรกวัตถุ photorealistic
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27- Mini-Gemini: การขุดศักยภาพของแบบจำลองภาษาการมองเห็นแบบหลายรูปแบบ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/27 - ข้อเท็จจริงแบบยาวในรูปแบบภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/27 - Lita: ภาษาที่ได้รับคำแนะนำจากผู้ช่วยการแปลชั่วคราว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/27 - Garment3dgen: การสร้างสไตล์และการสร้างพื้นผิว 3 มิติ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27 - Gamba: แต่งงานกับ Gaussian Splatting กับ Mamba สำหรับการสร้างภาพ 3 มิติเดี่ยว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27- FlexEdit: การแก้ไขภาพวัตถุที่มีความยืดหยุ่นและควบคุมได้
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/27 - Biomedlm: โมเดลภาษาพารามิเตอร์ 2.7B ที่ผ่านการฝึกอบรมเกี่ยวกับข้อความชีวการแพทย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/26- MAGIS: กรอบการทำงานหลายตัวแทน LLM สำหรับการแก้ไขปัญหาปัญหา GitHub
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/26 - ความไร้ประสิทธิภาพที่ไม่มีเหตุผลของชั้นลึก
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/26- TC4D: การสร้างข้อความที่มีการปรับสภาพเป็นแบบ To-4D
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/26- Octree-GS: ไปสู่การแสดงผลแบบเรียลไทม์ที่สอดคล้องกับ 3D Gaussians โครงสร้าง LOD
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/26- แนะนำ DBRX: LLM เปิดล้ำสมัยใหม่
(บล็อก),, - 03/26 - รายงานทางเทคนิค internlm2
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/26- การปรับปรุงความสอดคล้องของข้อความเป็นภาพผ่านการเพิ่มประสิทธิภาพโดยอัตโนมัติ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/26- Perceptrons หลายชั้นที่หลอมเต็มรูปแบบบน GPUs ศูนย์ข้อมูล Intel
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/26 - Egolifter: การแบ่งส่วน 3D แบบเปิด - โลกสำหรับการรับรู้ egocentric
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/26 - aniportrait: การสังเคราะห์เสียงของภาพเคลื่อนไหวภาพบุคคล
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/26 - 2d Gaussian Splatting สำหรับสนามรังสีที่แม่นยำทางเรขาคณิต
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25 - ไปสู่การประเมินอัตโนมัติสำหรับความสามารถทางคลินิกของ LLMS: ตัวชี้วัดข้อมูลและอัลกอริทึม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25 - ซ่อมแซม: ตัวแทนอิสระที่ใช้ LLM สำหรับการซ่อมแซมโปรแกรม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25- RL สำหรับโมเดลที่สอดคล้องกัน: การสร้างข้อความเป็นคำแนะนำที่เร็วกว่า
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/25- VP3D: ปลดปล่อยพรอมต์ภาพ 2D สำหรับการสร้างข้อความถึง 3D
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25- การเดินทาง: การเรียนรู้ที่เหลืออยู่ชั่วคราวด้วยเสียงรบกวนภาพก่อนสำหรับโมเดลการแพร่ภาพกับภาพผ่านวิดีโอ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25- SDXS: แบบจำลองการแพร่กระจายแบบเรียลไทม์แบบเรียลไทม์พร้อมเงื่อนไขภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/25 - ระบบปฏิบัติการเอเจนต์ LLM
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/25 - Flashface: การทำให้เป็นส่วนตัวของภาพมนุษย์ด้วยการเก็บรักษาตัวตนที่มีความเที่ยงตรงสูง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25- Dreampolisher: ไปสู่การสร้างข้อความที่มีคุณภาพสูงถึง 3D ผ่านการแพร่กระจายทางเรขาคณิต
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/25- เป็นตัวของตัวเอง: ความสนใจที่ จำกัด สำหรับการสร้างข้อความหลายเรื่องกับภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/23 - เมื่อการสร้างรหัสที่ใช้ LLM เป็นไปตามกระบวนการพัฒนาซอฟต์แวร์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/22 - TheSestation: การสร้างสินทรัพย์ 3 มิติที่รับรู้ธีมจากแบบอย่างไม่กี่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/22 - Simba: สถาปัตยกรรมที่ใช้ Mamba แบบง่ายสำหรับการมองเห็นและอนุกรมเวลาหลายตัวแปร
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/22 - LLM2LLM: เพิ่ม LLMS ด้วยการปรับปรุงข้อมูลซ้ำใหม่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/22- Latte3d: การสังเคราะห์ข้อความขนาดใหญ่ที่ตัดต่อการปรับปรุง 3D 3D
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/22 - InternVideo2: ปรับขนาดโมเดลวิดีโอพื้นฐานสำหรับการทำความเข้าใจวิดีโอหลายรูปแบบ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/22 - ผู้ติดตาม: การประเมินและการสอนแบบจำลองการดึงข้อมูลเพื่อทำตามคำแนะนำ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/22 - Dragapart: การเรียนรู้การเคลื่อนไหวระดับส่วนก่อนสำหรับวัตถุที่เปล่งออกมา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/22 - โมเดลภาษาขนาดใหญ่สามารถสำรวจในบริบทได้หรือไม่?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/22 - Allhands: ถามอะไรก็ได้เกี่ยวกับคำติชมคำกริยาขนาดใหญ่ผ่านแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (SS) - 03/21 - PEERGPT: การตรวจสอบบทบาทของตัวแทนเพียร์ที่ใช้ LLM ในฐานะผู้ดูแลทีมและผู้เข้าร่วมในการเรียนรู้ร่วมกันของเด็ก
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - Stylecinegan: Landscape Cinemagraph รุ่นโดยใช้ Stylegan ที่ผ่านการฝึกอบรมมาก่อน
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/21 - สตรีมมิ่ง T2V: การสร้างวิดีโอที่สอดคล้องกันแบบไดนามิกและขยายได้จากข้อความ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/21 - Renoise: การผกผันของภาพจริงผ่าน Noising ซ้ำ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - การขอความช่วยเหลือสำหรับการบุกเบิก: การแชทกับแบบจำลองภาษากำเนิด
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - Rakutenai -7b: ขยายรูปแบบภาษาขนาดใหญ่สำหรับภาษาญี่ปุ่น
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - MYVLM: ปรับแต่ง VLMS สำหรับแบบสอบถามเฉพาะผู้ใช้
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - Mathverse: LLM แบบหลายโหมดของคุณเห็นไดอะแกรมในปัญหาคณิตศาสตร์ภาพอย่างแท้จริงหรือไม่?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - GRM: แบบจำลองการสร้างใหม่แบบเกาส์เซียนขนาดใหญ่สำหรับการสร้างใหม่และสร้างใหม่ที่มีประสิทธิภาพและการสร้าง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/21 - สมัชชาใหญ่
(ข่าว), - 03/21 - Gaussian Frosting: Field Radiance Fields ที่ซับซ้อนได้พร้อมการเรนเดอร์แบบเรียลไทม์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - สำรวจระหว่างเวลาและพื้นที่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21- โมเดลการแพร่กระจายวิดีโอที่มีประสิทธิภาพผ่านการสลายตัวของเนื้อหาเฟรม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21- DreamReward: Text-to-3D รุ่นที่มีความชอบของมนุษย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/21 - งูเห่า: ขยาย Mamba ไปยังแบบจำลองภาษาขนาดใหญ่หลายรูปแบบเพื่อการอนุมานที่มีประสิทธิภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/21 - แชมป์: ภาพเคลื่อนไหวภาพมนุษย์ที่ควบคุมได้และสอดคล้องกันพร้อมคำแนะนำแบบพารามิเตอร์ 3 มิติ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/21- Anyv2v: เฟรมเวิร์กแบบปลั๊กและเล่นสำหรับงานแก้ไขวิดีโอกับวิดีโอใด ๆ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - การทำแผนที่ภูมิทัศน์ความปลอดภัย LLM: ข้อเสนอการประเมินความเสี่ยงของผู้มีส่วนได้ส่วนเสียที่ครอบคลุม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - ซิกม่า: รูปแบบการแพร่กระจายซิกแซก Mamba
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/20 - VSTAR: การพยาบาลชั่วคราวสำหรับการสังเคราะห์วิดีโอแบบไดนามิกที่ยาวนานขึ้น
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - รางวัล Bench: การประเมินแบบจำลองรางวัลสำหรับการสร้างแบบจำลองภาษา
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/20 - การฝึกอบรมย้อนกลับเพื่อพยาบาลคำสาปกลับรายการ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/25
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - Mora: การเปิดใช้งานการสร้างวิดีโอทั่วไปผ่านเฟรมเวิร์กหลายตัวแทน
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/20 - Llamafactory: การปรับแต่งแบบครบวงจรของแบบจำลองภาษา 100+ แบบรวม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/20- Idadapter: การเรียนรู้คุณสมบัติผสมสำหรับการปรับแต่งแบบจำลองการปรับแต่งแบบจำลองข้อความเป็นภาพต่อภาพ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - Hyperllava: การปรับแต่งผู้เชี่ยวชาญด้านภาพและภาษาแบบไดนามิกสำหรับแบบจำลองภาษาขนาดใหญ่หลายรูปแบบ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/20 - ประเมินโมเดลชายแดนสำหรับความสามารถที่เป็นอันตราย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - DEPTHFM: การประมาณค่าความลึกตาข้างเดียวอย่างรวดเร็วด้วยการจับคู่การไหล
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20 - compress3d: พื้นที่แฝงที่ถูกบีบอัดสำหรับรุ่น 3D จากภาพเดียว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/20- เป็นของคุณ outpainter: การเรียนรู้วิดีโอมากกว่าการปรับตัวเฉพาะอินพุต
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19 - เมื่อไหร่ที่เราไม่ต้องการแบบจำลองการมองเห็นขนาดใหญ่ขึ้น?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19- VID2Robot: การเรียนรู้นโยบายแบบครบวงจรกับการเรียนรู้ด้วยวิดีโอด้วยการควบคุมข้ามความสนใจ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19 - ไปสู่รูปแบบพื้นฐานที่มีวัตถุประสงค์ทั่วไปสำหรับพยาธิสภาพการคำนวณ
- - 03/19- TexDreamer: ไปสู่การสร้างพื้นผิวมนุษย์ 3 มิติที่มีความเที่ยงตรงสูง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19 - Scenescript: การสร้างฉากใหม่ด้วยโมเดลภาษาที่มีโครงสร้างแบบอัตโนมัติ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19- MPLUG-DOCOWL 1.5: การเรียนรู้โครงสร้างแบบครบวงจรสำหรับการทำความเข้าใจเอกสารฟรี OCR
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19 - Magic Fixup: การแก้ไขรูปภาพที่คล่องตัวโดยการดูวิดีโอแบบไดนามิก
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19- LLMLINGUA-2: การกลั่นข้อมูลเพื่อการบีบอัดพร้อมการบีบอัดที่มีประสิทธิภาพและซื่อสัตย์
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19- GVGEN: Text-to-3D Generation พร้อมการแสดงปริมาตร
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19 - Gaussianflow: Splatting Gaussian Dynamics สำหรับการสร้างเนื้อหา 4D
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19- Fresco: การติดต่อทางอวกาศ-อวกาศสำหรับการแปลวิดีโอแบบศูนย์-ช็อต
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19- Fouriscale: มุมมองความถี่เกี่ยวกับการสังเคราะห์ภาพความละเอียดสูงที่ปราศจากการฝึกอบรม
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19 - การเพิ่มประสิทธิภาพเชิงวิวัฒนาการของสูตรการผสานแบบจำลอง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), ([: octocat:] (https : //github.com/ sakanaai/evolutionary-model-merge)! [github repo stars] (https://img.shields.io/github/stars/ sakanaai/evolutionary-model-merge? style = social)))) - 03/19 - Comboverse: การสร้างสินทรัพย์ 3D องค์ประกอบโดยใช้คำแนะนำการแพร่กระจายเชิงพื้นที่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19 - การใช้เหตุผลตามแผนภูมิ: การถ่ายโอนความสามารถจาก LLMS ไปยัง VLMS
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19 - MM1 ของ Apple: โมเดลภาษาขนาดใหญ่หลายรูปแบบที่สามารถตีความทั้งภาพและข้อมูลข้อความ
(ข่าว), - 03/19- ภาพเคลื่อนไหว-แสง: การกลั่นการแพร่กระจายข้ามโมเดล
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/19 - Agent -Flan: การออกแบบข้อมูลและวิธีการปรับจูนเอเจนต์ที่มีประสิทธิภาพสำหรับแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/19 - รูปแบบพื้นฐานภาษาภาพสำหรับพยาธิวิทยาการคำนวณ
() , () - 03/19 - ตัวแทน AI ลักษณะผ่านแบบจำลองภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), (! https://img.shields.io/github/stars/nuaa-nlp/character100? style = social))) - 03/18 - เราอยู่ไกลแค่ไหนในการตัดสินใจของ LLMS? การประเมินความสามารถในการเล่นเกมของ LLMS ในสภาพแวดล้อมที่หลากหลาย
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/18 - VideHeragent: ตัวแทนหลายหน่วยความจำสำหรับการทำความเข้าใจวิดีโอ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18 - VFusion3d: การเรียนรู้แบบจำลอง 3D ที่ปรับขนาดได้จากโมเดลการแพร่กระจายวิดีโอ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18 - tnt -llm: การขุดข้อความในระดับที่มีรูปแบบภาษาขนาดใหญ่
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18 - SV3D: การสังเคราะห์หลายมุมมองนวนิยายและการสร้าง 3D จากภาพเดียวโดยใช้การแพร่กระจายวิดีโอแฝง
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18 - Routerbench: มาตรฐานสำหรับระบบการกำหนดเส้นทาง Multi -LLM
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), (ss) - 03/18- Meta-Prompting สำหรับการจดจำภาพศูนย์โดยอัตโนมัติด้วย LLMS
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/18 - LN3DIFF: การแพร่กระจายของระบบประสาทแฝงที่ปรับขนาดได้สำหรับรุ่น 3D ที่รวดเร็ว
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18- llava-uhd: LMM รับรู้อัตราส่วนภาพและภาพความละเอียดสูงใด ๆ
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳), () - 03/18 - Larimar: รุ่นภาษาขนาดใหญ่ที่มีการควบคุมหน่วยความจำฉาก
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18- Infinite-Id: การตั้งค่าส่วนบุคคลที่ได้รับการอนุรักษ์ไว้
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳) - 03/18 - GPT -4 ในฐานะผู้ประเมินผล: การประเมินแบบจำลองภาษาขนาดใหญ่เกี่ยวกับการจัดการศัตรูพืชในการเกษตร
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (twitter,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


