meena chatbot
1.0.0
นี่คือความพยายามของฉันในการสร้าง Meena ซึ่งเป็นแชทบอทล้ำสมัยที่พัฒนาโดย Google Research และอธิบายไว้ในรายงานเรื่อง Towards a Human-like Open-Domain Chatbot
สำหรับการนำไปใช้นี้ ฉันใช้ไลบรารีการเรียนรู้เชิงลึกของ tensor2tensor โดยใช้โมเดลหม้อแปลงที่พัฒนาแล้วตามที่อธิบายไว้ในรายงาน
ชุดการฝึกอบรมที่ใช้คือคลังข้อมูล OpenSubtitles ในภาษาอิตาลี มีภาษาอื่นๆ อีกมากมายที่นี่
เช่นเดียวกับงานที่ทำในรายงาน แบบจำลองนี้ประกอบด้วยบล็อกตัวเข้ารหัส 1 บล็อกและบล็อกตัวถอดรหัส 12 บล็อก รวมเป็นพารามิเตอร์ 108M เครื่องมือเพิ่มประสิทธิภาพที่ใช้คือ Adafactor ซึ่งมีตารางอัตราการฝึกอบรมเดียวกันกับที่อธิบายไว้ในรายงาน
นี่คือผลลัพธ์หลังจากการฝึกโมเดลกับประโยค 40 ล้านประโยคของชุดข้อมูล OpenSubtitles ในภาษาอิตาลี อัตราการเรียนรู้เริ่มต้นที่ 0.01 และคงที่เป็นเวลา 10,000 ก้าว จากนั้นสลายตัวด้วยรากที่สองผกผันของจำนวนก้าว
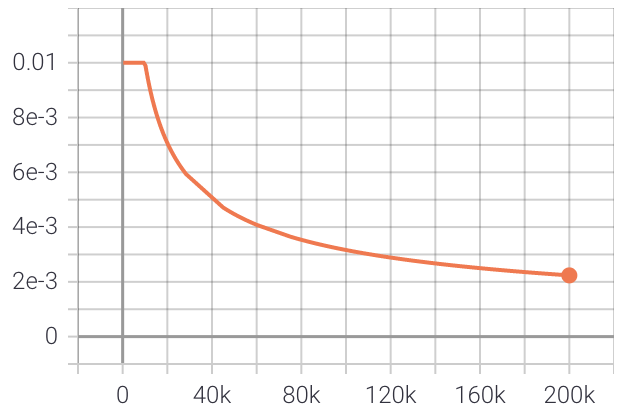
นี่คือโครงเรื่องของการสูญเสียการประเมินระหว่างการฝึกอบรม 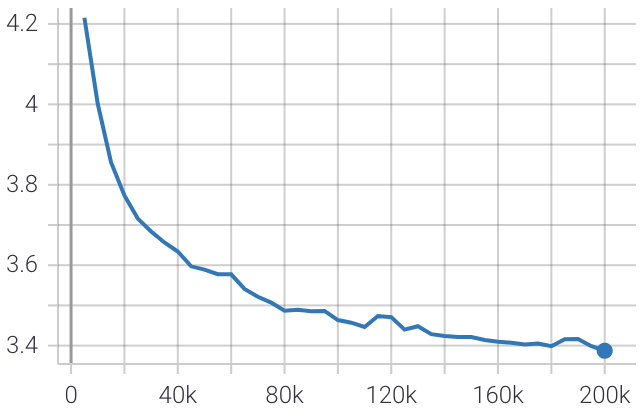
คะแนนความฉงนสนเท่ห์สุดท้ายคือ 10.4 ซึ่งใกล้เคียงกับคะแนนความฉงนสนเท่ห์ที่ได้รับจาก meena chatbot 10.2 ของ Google
บทความนี้แสดงความสัมพันธ์ระหว่างคะแนนความฉงนสนเท่ห์และค่าเฉลี่ยความรู้สึกและความจำเพาะซึ่งมีความสัมพันธ์กับ "ความเหมือนมนุษย์" ของแชทบอต คะแนนความฉงนสนเท่ห์ของเราแสดงให้เห็นว่าบอทของเราดีกว่าแชทบอทอื่น ๆ เช่น Cleverbot และ DialoGPT: 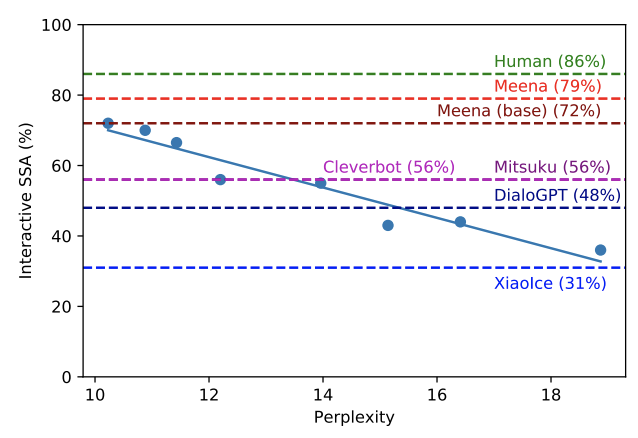
อย่างไรก็ตาม ชุดข้อมูลที่ใช้ไม่ได้แสดงถึงการสนทนาตามปกติระหว่างมนุษย์ อย่างไรก็ตาม Opensubtitles มีชุดข้อมูลขนาดใหญ่มากในหลายภาษา
เพียงเรียกใช้งาน notebook meena_chatbot_inference.ipynb
มิฉะนั้นให้ดาวน์โหลดโมเดลต่อไปนี้และแตกไฟล์ออก ตั้งค่า MODEL_DIR และ CHECKPOINT_NAME ที่เหมาะสมใน predict.py และเรียกใช้ main.py
สำหรับการฝึกอบรม เพียงเรียกใช้สมุดบันทึก ipython บน Google Colab โมเดลจะถูกบันทึกไว้ใน Google Drive เมื่อสิ้นสุดการดำเนินการ คุณสามารถโต้ตอบกับแชทบอทได้
โมเดลสามารถส่งออกได้โดยการคัดลอกไฟล์ต่อไปนี้ลงในโฟลเดอร์:
และรัน main.py หลังจากตั้งค่าไดเร็กทอรีโมเดลที่เหมาะสม
server.py มี HTTP API อย่างง่ายสำหรับให้บริการแชทบอท


