segment anything
1.0.0
โปรดตรวจสอบการเปิดตัวใหม่ของเราใน Segment Anything Model 2 (SAM 2)
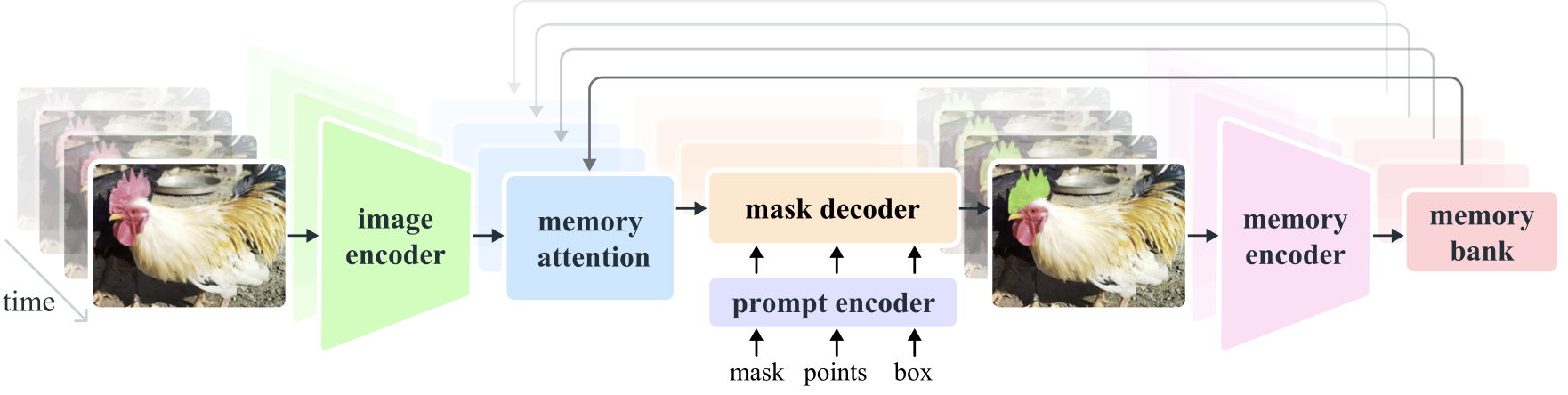
Segment Anything Model 2 (SAM 2) เป็นรูปแบบพื้นฐานในการแก้ปัญหาการแบ่งส่วนภาพที่รวดเร็วในรูปภาพและวิดีโอ เราขยาย SAM ไปยังวิดีโอโดยพิจารณารูปภาพเป็นวิดีโอที่มีเฟรมเดียว การออกแบบโมเดลเป็นสถาปัตยกรรมหม้อแปลงแบบธรรมดาพร้อมหน่วยความจำแบบสตรีมสำหรับการประมวลผลวิดีโอแบบเรียลไทม์ เราสร้างกลไกข้อมูล model-in-the-loop ซึ่งปรับปรุงโมเดลและข้อมูลผ่านการโต้ตอบของผู้ใช้ เพื่อรวบรวม ชุดข้อมูล SA-V ซึ่งเป็นชุดข้อมูลการแบ่งส่วนวิดีโอที่ใหญ่ที่สุดในปัจจุบัน SAM 2 ที่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลของเราให้ประสิทธิภาพที่ยอดเยี่ยมในงานและโดเมนภาพที่หลากหลาย
การวิจัย Meta AI ยุติธรรม
อเล็กซานเดอร์ คิริลลอฟ, เอริค มินตุน, นิคิลา ราวี, ฮันซี เหมา, โคลอี โรลแลนด์, ลอร่า กุสตาฟสัน, เตเต้ เซียว, สเปนเซอร์ ไวท์เฮด, อเล็กซ์ เบิร์ก, วาน-เยน โล, พิโอเตอร์ ดอลลาร์, รอสส์ เกอร์ชิค
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
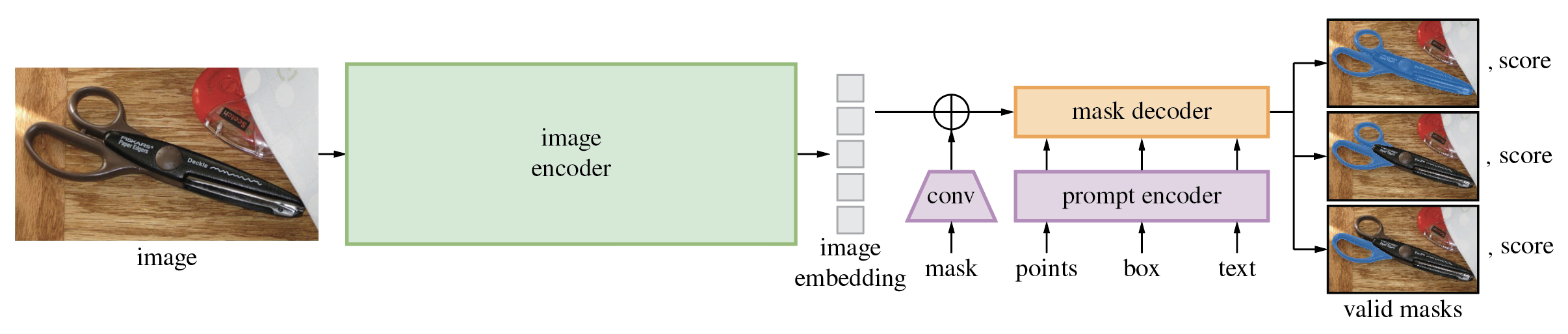
Segment Anything Model (SAM) จะสร้างมาสก์วัตถุคุณภาพสูงจากพร้อมท์อินพุต เช่น จุดหรือกล่อง และสามารถใช้เพื่อสร้างมาสก์สำหรับวัตถุทั้งหมดในรูปภาพได้ ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูล 11 ล้านภาพและมาสก์ 1.1 พันล้านชิ้น และมีประสิทธิภาพการทำงานเป็นศูนย์ช็อตที่แข็งแกร่งในงานการแบ่งส่วนที่หลากหลาย


รหัสต้องใช้ python>=3.8 เช่นเดียวกับ pytorch>=1.7 และ torchvision>=0.8 โปรดปฏิบัติตามคำแนะนำที่นี่เพื่อติดตั้งทั้งการพึ่งพา PyTorch และ TorchVision ขอแนะนำอย่างยิ่งให้ติดตั้งทั้ง PyTorch และ TorchVision พร้อมการรองรับ CUDA
ติดตั้งเซ็กเมนต์อะไรก็ได้:
pip install git+https://github.com/facebookresearch/segment-anything.git
หรือโคลนที่เก็บในเครื่องและติดตั้งด้วย
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
การขึ้นต่อกันเพิ่มเติมต่อไปนี้จำเป็นสำหรับการประมวลผลมาสก์ภายหลัง การบันทึกมาสก์ในรูปแบบ COCO สมุดบันทึกตัวอย่าง และการส่งออกโมเดลในรูปแบบ ONNX jupyter จำเป็นต้องเรียกใช้สมุดบันทึกตัวอย่างด้วย
pip install opencv-python pycocotools matplotlib onnxruntime onnx
ขั้นแรกให้ดาวน์โหลดจุดตรวจสอบโมเดล จากนั้นโมเดลจะสามารถใช้ได้เพียงไม่กี่บรรทัดเพื่อรับมาสก์จากพรอมต์ที่กำหนด:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
หรือสร้างมาสก์สำหรับรูปภาพทั้งหมด:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
นอกจากนี้ คุณสามารถสร้างมาสก์สำหรับรูปภาพจากบรรทัดคำสั่งได้:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
ดูสมุดบันทึกตัวอย่างเกี่ยวกับการใช้ SAM พร้อมข้อความแจ้งและสร้างมาสก์โดยอัตโนมัติเพื่อดูรายละเอียดเพิ่มเติม


ตัวถอดรหัสมาสก์น้ำหนักเบาของ SAM สามารถส่งออกเป็นรูปแบบ ONNX เพื่อให้สามารถรันในสภาพแวดล้อมใดๆ ที่รองรับรันไทม์ ONNX เช่น ในเบราว์เซอร์ดังที่แสดงในการสาธิต ส่งออกโมเดลด้วย
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
ดูสมุดบันทึกตัวอย่างสำหรับรายละเอียดเกี่ยวกับวิธีการรวมการประมวลผลภาพล่วงหน้าผ่านแกนหลักของ SAM กับการทำนายมาสก์โดยใช้โมเดล ONNX ขอแนะนำให้ใช้ PyTorch เวอร์ชันเสถียรล่าสุดสำหรับการส่งออก ONNX
โฟลเดอร์ demo/ มีแอป React หน้าเดียวที่เรียบง่ายซึ่งแสดงวิธีเรียกใช้การทำนายมาสก์ด้วยโมเดล ONNX ที่ส่งออกในเว็บเบราว์เซอร์ที่มีมัลติเธรด โปรดดู demo/README.md สำหรับรายละเอียดเพิ่มเติม
มีโมเดลให้เลือกสามเวอร์ชันโดยมีขนาดแกนหลักที่แตกต่างกัน โมเดลเหล่านี้สามารถสร้างอินสแตนซ์ได้ด้วยการรัน
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
คลิกลิงก์ด้านล่างเพื่อดาวน์โหลดจุดตรวจสอบสำหรับประเภทรุ่นที่เกี่ยวข้อง
default หรือ vit_h : รุ่น ViT-H SAMvit_l : รุ่น ViT-L SAMvit_b : รุ่น ViT-B SAM ดูที่นี่สำหรับภาพรวมของชุดข้อมูล สามารถดาวน์โหลดชุดข้อมูลได้ที่นี่ การดาวน์โหลดชุดข้อมูลแสดงว่าคุณได้อ่านและยอมรับข้อกำหนดของใบอนุญาตการวิจัยชุดข้อมูล SA-1B แล้ว
เราบันทึกมาสก์ต่อรูปภาพเป็นไฟล์ json สามารถโหลดเป็นพจนานุกรมใน python ได้ในรูปแบบด้านล่าง
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}รหัสรูปภาพสามารถพบได้ใน sa_images_ids.txt ซึ่งสามารถดาวน์โหลดได้โดยใช้ลิงก์ด้านบนเช่นกัน
หากต้องการถอดรหัสมาสก์ในรูปแบบ COCO RLE เป็นไบนารี:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
ดูคำแนะนำเพิ่มเติมในการจัดการมาสก์ที่จัดเก็บในรูปแบบ RLE ที่นี่
โมเดลนี้ได้รับอนุญาตภายใต้ลิขสิทธิ์ Apache 2.0
ดูการบริจาคและจรรยาบรรณ
โครงการ Segment Anything เกิดขึ้นได้ด้วยความช่วยเหลือจากผู้ร่วมให้ข้อมูลจำนวนมาก (เรียงตามตัวอักษร):
อารอน แอดค็อก, ไวบาฟ อัคการ์วาล, มอร์เตซา เบห์รูซ, เฉิงหยาง ฟู่, แอชลีย์ กาเบรียล, อาฮูวา โกลด์สแตนด์, อัลเลน กู๊ดแมน, ซูแมนธ์ เกอร์แรม, เจียโบ หู, สมยา เจน, เดวานช์ คูเครจา, โรเบิร์ต คูโอ, โจชัว เลน, หยางห่าว ลี, ลิเลียน ลือง, จิเทนดรา มาลิก, มัลลิกา มัลโหตรา, วิลเลียม เงิน, ออมการ์ ปาร์กี, นิคิล ไรนา, เดิร์ค โรว์, นีล เซจัวร์, วาเนสซา สตาร์ก, บาลา วาราดาราจัน, แบรม วัสตี, แซคารี วินสตรอม
หากคุณใช้ SAM หรือ SA-1B ในการวิจัยของคุณ โปรดใช้รายการ BibTeX ต่อไปนี้
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


