obfuscated gradients
v1.0.0
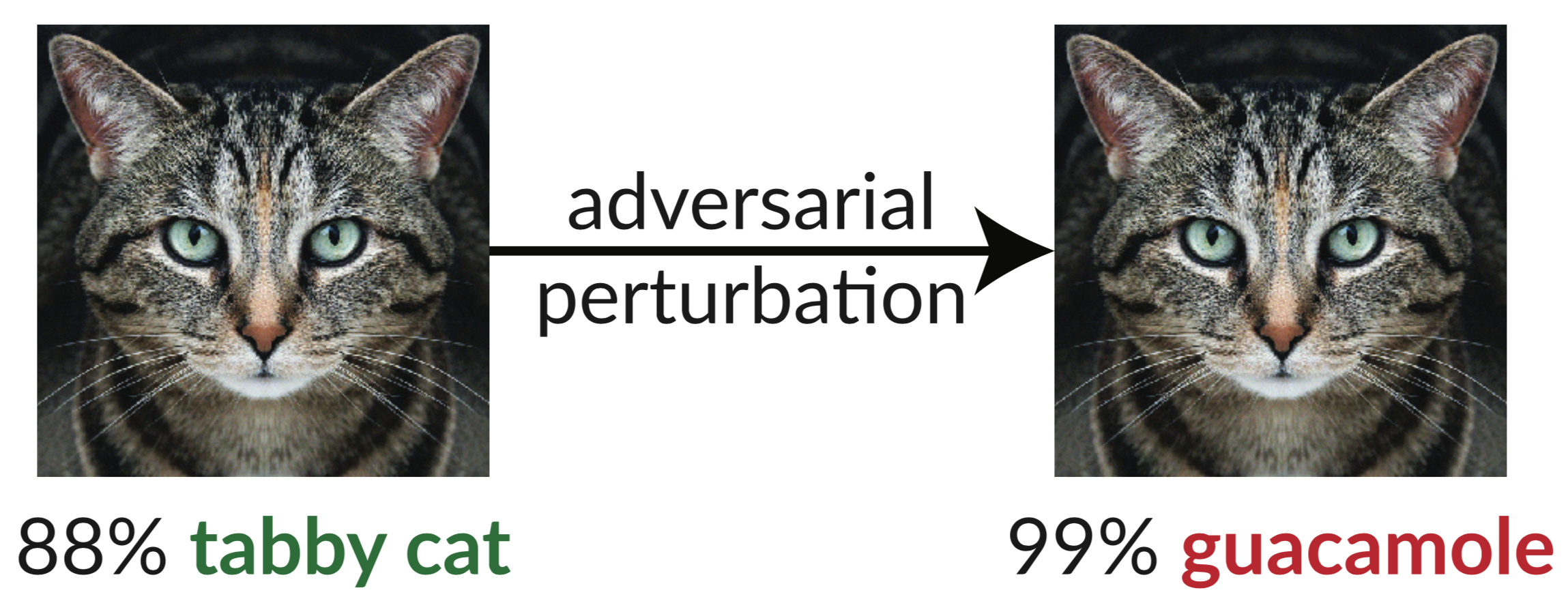
ข้างต้นเป็นตัวอย่างของฝ่ายตรงข้าม: ภาพแมวที่ถูกรบกวนเล็กน้อยทำให้ตัวแยกประเภท InceptionV3 จำแนกว่าเป็น "guacamole" "ภาพหลอกลวง" ดังกล่าวสามารถสังเคราะห์ได้ง่ายโดยใช้การไล่ระดับสีแบบไล่ระดับ (Szegedy et al. 2013)
ในรายงานล่าสุดของเรา เราประเมินความแข็งแกร่งของเอกสารเก้าฉบับที่ยอมรับใน ICLR 2018 ว่าเป็นการป้องกันแบบ white-box-secure ที่ไม่ผ่านการรับรองสำหรับตัวอย่างของฝ่ายตรงข้าม เราพบว่าการป้องกันเจ็ดในเก้าประการช่วยเพิ่มความทนทานได้อย่างจำกัด และสามารถถูกทำลายได้ด้วยเทคนิคการโจมตีที่ได้รับการปรับปรุงที่เราพัฒนาขึ้น
ด้านล่างนี้คือตารางที่ 1 จากรายงานของเรา ซึ่งเราแสดงให้เห็นความแข็งแกร่งของการป้องกันแต่ละอันที่ยอมรับกับตัวอย่างฝ่ายตรงข้ามที่เราสามารถสร้างได้:
| กลาโหม | ชุดข้อมูล | ระยะทาง | ความแม่นยำ |
|---|---|---|---|
| บัคแมน และคณะ (2018) | ซีฟาร์ | 0.031 (ลินฟ) | 0%* |
| แม่และคณะ (2018) | ซีฟาร์ | 0.031 (ลินฟ) | 5% |
| กัว และคณะ (2018) | อิมเมจเน็ต | 0.05 (ลิตร2) | 0%* |
| ดิลลอน และคณะ (2018) | ซีฟาร์ | 0.031 (ลินฟ) | 0% |
| Xie และคณะ (2018) | อิมเมจเน็ต | 0.031 (ลินฟ) | 0%* |
| เพลงและคณะ (2018) | ซีฟาร์ | 0.031 (ลินฟ) | 9%* |
| ซามังโกเออิ และคณะ (2018) | มินนิสต์ | 0.005 (ลิตร2) | 55%** |
| แมดรี และคณะ (2018) | ซีฟาร์ | 0.031 (ลินฟ) | 47% |
| นา และคณะ (2018) | ซีฟาร์ | 0.015 (ลินฟ์) | 15% |
(การป้องกันที่แสดงด้วย * ยังเสนอให้รวมการฝึกอบรมฝ่ายตรงข้าม เรารายงานที่นี่เกี่ยวกับการป้องกันเพียงอย่างเดียว ดูบทความของเรา ส่วนที่ 5 สำหรับตัวเลขทั้งหมด หลักการพื้นฐานเบื้องหลังการป้องกันที่แสดงด้วย ** มีความแม่นยำ 0% ในทางปฏิบัติ ข้อบกพร่องในการป้องกันทำให้เกิด การโจมตีที่เหมาะสมที่สุดที่จะล้มเหลว ดูหัวข้อ 5.4.2 สำหรับรายละเอียด)
การป้องกันเดียวที่เราสังเกตเห็นว่าเพิ่มความแข็งแกร่งอย่างมากให้กับตัวอย่างฝ่ายตรงข้ามภายในโมเดลภัยคุกคามที่เสนอคือ "สู่โมเดลการเรียนรู้เชิงลึกที่ทนต่อการโจมตีของฝ่ายตรงข้าม" (Madry et al. 2018) และเราไม่สามารถเอาชนะการป้องกันนี้โดยไม่ก้าวออกจากโมเดลภัยคุกคาม . ถึงกระนั้น เทคนิคนี้ก็แสดงให้เห็นว่ายากที่จะปรับขนาดเป็น ImageNet-scale (Kurakin et al. 2016) เอกสารส่วนที่เหลือ (นอกเหนือจากรายงานของ Na et al. ซึ่งให้ความทนทานที่จำกัด) อาศัยสิ่งที่เราเรียกว่า การไล่ระดับสีที่สับสน โดยไม่ตั้งใจหรือโดยเจตนา การโจมตีแบบมาตรฐานจะใช้การไล่ระดับเพื่อเพิ่มการสูญเสียเครือข่ายบนรูปภาพที่กำหนด เพื่อสร้างตัวอย่างฝ่ายตรงข้ามบนโครงข่ายประสาทเทียม วิธีการปรับให้เหมาะสมดังกล่าวต้องการสัญญาณการไล่ระดับสีที่เป็นประโยชน์จึงจะประสบความสำเร็จ เมื่อการป้องกันทำให้การไล่ระดับสีสับสน มันจะทำลายสัญญาณการไล่ระดับสีนี้ และทำให้วิธีการเพิ่มประสิทธิภาพล้มเหลว
เราระบุสามวิธีที่การป้องกันทำให้เกิดการไล่ระดับสีที่ซับซ้อน และสร้างการโจมตีเพื่อหลีกเลี่ยงแต่ละกรณีเหล่านี้ โดยทั่วไปการโจมตีของเราใช้ได้กับการป้องกันใดๆ ก็ตาม ซึ่งรวมถึงการดำเนินการที่ไม่สามารถสร้างความแตกต่างได้ ไม่ว่าจะโดยตั้งใจหรือไม่ตั้งใจ หรือขัดขวางไม่ให้สัญญาณเกรเดียนต์ไหลผ่านเครือข่าย เราหวังว่างานในอนาคตจะสามารถใช้วิธีการของเราในการประเมินความปลอดภัยที่ละเอียดยิ่งขึ้น
เชิงนามธรรม:
เราระบุการไล่ระดับสีแบบคลุมเครือ ซึ่งเป็นการปกปิดการไล่ระดับสีแบบหนึ่ง เป็นปรากฏการณ์ที่นำไปสู่ความรู้สึกผิด ๆ เกี่ยวกับความปลอดภัยในการป้องกันตัวอย่างที่เป็นปฏิปักษ์ แม้ว่าการป้องกันที่ทำให้เกิดการไล่ระดับสีที่สับสนดูเหมือนจะเอาชนะการโจมตีที่เน้นการปรับให้เหมาะสมแบบวนซ้ำ แต่เราพบว่าการป้องกันที่อาศัยเอฟเฟกต์นี้สามารถหลีกเลี่ยงได้ เราอธิบายพฤติกรรมลักษณะเฉพาะของการป้องกันที่แสดงผล และสำหรับการไล่ระดับสีที่ซับซ้อนทั้งสามประเภทที่เราค้นพบ เราจะพัฒนาเทคนิคการโจมตีเพื่อเอาชนะมัน ในกรณีศึกษา ซึ่งตรวจสอบการป้องกันแบบ white-box-secure ที่ไม่ผ่านการรับรองที่ ICLR 2018 เราพบว่าการไล่ระดับสีแบบ obfuscated เป็นเรื่องปกติ โดยการป้องกัน 7 จาก 9 แบบอาศัยการไล่ระดับสีแบบ obfuscated การโจมตีครั้งใหม่ของเราประสบความสำเร็จในการหลีกเลี่ยง 6 ครั้งอย่างสมบูรณ์ และ 1 ครั้งในบางส่วน ในรูปแบบภัยคุกคามดั้งเดิมที่แต่ละรายงานพิจารณา
สำหรับรายละเอียด โปรดอ่านบทความของเรา
พื้นที่เก็บข้อมูลนี้ประกอบด้วยอินสแตนซ์ของเทคนิคการโจมตีทั่วไปที่อธิบายไว้ในรายงานของเรา ซึ่งทำลายการป้องกัน 7 รายการของ ICLR 2018 การป้องกันบางส่วนไม่ได้เผยแพร่ซอร์สโค้ด (ในขณะที่เราทำงานนี้) ดังนั้นเราจึงต้องปรับใช้ใหม่อีกครั้ง
@inproceedings{obfuscated-gradients, author = {Anish Athalye และ Nicholas Carlini และ David Wagner}, title = {Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples}, booktitle = {การดำเนินการของการประชุมนานาชาติครั้งที่ 35 บนเครื่อง การเรียนรู้ {ICML} 2018} ปี = {2018} เดือน = ก.ค. URL = {https://arxiv.org/abs/1802.00420},
- 

