Megatron LM
NVIDIA Megatron Core 0.9.0
พื้นที่เก็บข้อมูลนี้ประกอบด้วยองค์ประกอบที่สำคัญสองส่วน: Megatron-LM และ Megatron-Core Megatron-LM ทำหน้าที่เป็นกรอบการทำงานที่มุ่งเน้นการวิจัยซึ่งใช้ประโยชน์จาก Megatron-Core สำหรับการฝึกอบรมโมเดลภาษาขนาดใหญ่ (LLM) ในทางกลับกัน Megatron-Core คือคลังเทคนิคการฝึกอบรมที่ปรับให้เหมาะสมกับ GPU ที่มาพร้อมกับการสนับสนุนผลิตภัณฑ์อย่างเป็นทางการ รวมถึง API เวอร์ชันและเวอร์ชันปกติ คุณสามารถใช้ Megatron-Core ควบคู่ไปกับ Megatron-LM หรือ Nvidia NeMo Framework สำหรับโซลูชันแบบครบวงจรและแบบเนทีฟบนคลาวด์ หรือคุณสามารถรวม Building Block ของ Megatron-Core เข้ากับกรอบการฝึกอบรมที่คุณต้องการได้
Megatron (1, 2 และ 3) เปิดตัวครั้งแรกในปี 2019 จุดประกายกระแสนวัตกรรมในชุมชน AI ซึ่งช่วยให้นักวิจัยและนักพัฒนาสามารถใช้รากฐานของห้องสมุดนี้เพื่อพัฒนา LLM ต่อไป ในปัจจุบัน เฟรมเวิร์กนักพัฒนา LLM ที่ได้รับความนิยมสูงสุดจำนวนมากได้รับแรงบันดาลใจและสร้างโดยใช้ประโยชน์จากไลบรารีโอเพ่นซอร์ส Megatron-LM โดยตรง ซึ่งกระตุ้นให้เกิดโมเดลพื้นฐานและสตาร์ทอัพด้าน AI มากมาย เฟรมเวิร์ก LLM ที่ได้รับความนิยมสูงสุดบางส่วนที่สร้างขึ้นจาก Megatron-LM ได้แก่ Colossal-AI, HuggingFace Accelerate และ NVIDIA NeMo Framework รายชื่อโครงการที่ใช้ Megatron โดยตรงสามารถดูได้ที่นี่
Megatron-Core เป็นไลบรารีที่ใช้ PyTorch แบบโอเพ่นซอร์สซึ่งมีเทคนิคที่ปรับให้เหมาะสมกับ GPU และการเพิ่มประสิทธิภาพระดับระบบที่ล้ำสมัย โดยสรุปพวกมันออกเป็น API แบบแยกส่วนและแบบแยกส่วนได้ ช่วยให้นักพัฒนาและนักวิจัยโมเดลมีความยืดหยุ่นอย่างเต็มที่ในการฝึกหม้อแปลงแบบกำหนดเองในขนาดต่างๆ บนโครงสร้างพื้นฐานการประมวลผลที่เร่งความเร็วของ NVIDIA ไลบรารีนี้เข้ากันได้กับ NVIDIA Tensor Core GPU ทั้งหมด รวมถึงการรองรับการเร่งความเร็ว FP8 สำหรับสถาปัตยกรรม NVIDIA Hopper
Megatron-Core นำเสนอองค์ประกอบหลัก เช่น กลไกความสนใจ บล็อกและเลเยอร์ของหม้อแปลง เลเยอร์การทำให้เป็นมาตรฐาน และเทคนิคการฝัง ฟังก์ชันเพิ่มเติม เช่น การคำนวณการเปิดใช้งานใหม่ จุดตรวจสอบแบบกระจายก็มีอยู่ในไลบรารีเช่นกัน โครงสร้างและฟังก์ชันการทำงานทั้งหมดได้รับการปรับให้เหมาะสมสำหรับ GPU และสามารถสร้างได้ด้วยกลยุทธ์การขนานขั้นสูงเพื่อความเร็วและความเสถียรในการฝึกอบรมที่เหมาะสมที่สุดบนโครงสร้างพื้นฐานคอมพิวเตอร์ NVIDIA Accelerated องค์ประกอบสำคัญอีกประการหนึ่งของไลบรารี Megatron-Core รวมถึงเทคนิคการจำลองความเท่าเทียมของแบบจำลองขั้นสูง (เทนเซอร์ ลำดับ ไปป์ไลน์ บริบท และความเท่าเทียมของผู้เชี่ยวชาญ MoE)
Megatron-Core สามารถใช้ได้กับ NVIDIA NeMo ซึ่งเป็นแพลตฟอร์ม AI ระดับองค์กร หรือคุณสามารถสำรวจ Megatron-Core ด้วยลูปการฝึกอบรม PyTorch ดั้งเดิมได้ที่นี่ ไปที่เอกสารประกอบของ Megatron-Core เพื่อเรียนรู้เพิ่มเติม
โค้ดเบสของเราสามารถฝึกอบรมโมเดลภาษาขนาดใหญ่ได้อย่างมีประสิทธิภาพ (เช่น โมเดลที่มีพารามิเตอร์นับแสนล้าน) โดยมีทั้งโมเดลและข้อมูลที่มีความขนานกัน เพื่อสาธิตวิธีที่ซอฟต์แวร์ของเราปรับขนาดด้วย GPU หลายตัวและขนาดโมเดลต่างๆ เราจะพิจารณาโมเดล GPT ที่มีพารามิเตอร์ตั้งแต่ 2 พันล้านพารามิเตอร์ไปจนถึง 462 พันล้านพารามิเตอร์ โมเดลทั้งหมดใช้ขนาดคำศัพท์ 131,072 และความยาวลำดับ 4,096 เราเปลี่ยนแปลงขนาดที่ซ่อนอยู่ จำนวนส่วนหัวของความสนใจ และจำนวนเลเยอร์เพื่อให้ได้ขนาดโมเดลที่เฉพาะเจาะจง เมื่อขนาดโมเดลเพิ่มขึ้น เราก็เพิ่มขนาดแบทช์เล็กน้อยเช่นกัน การทดลองของเราใช้ GPU มากถึง 6144 H100 เราทำการทับซ้อนกันอย่างละเอียดของ data-parallel ( --overlap-grad-reduce --overlap-param-gather ), tensor-parallel ( --tp-comm-overlap ) และการสื่อสารไปป์ไลน์-ขนาน (เปิดใช้งานโดยค่าเริ่มต้น) ด้วย การคำนวณเพื่อปรับปรุงความสามารถในการปรับขนาด ปริมาณการประมวลผลที่รายงานได้รับการวัดสำหรับการฝึกอบรมแบบ end-to-end และรวมถึงการดำเนินการทั้งหมด รวมถึงการโหลดข้อมูล ขั้นตอนเครื่องมือเพิ่มประสิทธิภาพ การสื่อสาร และแม้กระทั่งการบันทึก โปรดทราบว่าเราไม่ได้ฝึกโมเดลเหล่านี้ให้มาบรรจบกัน
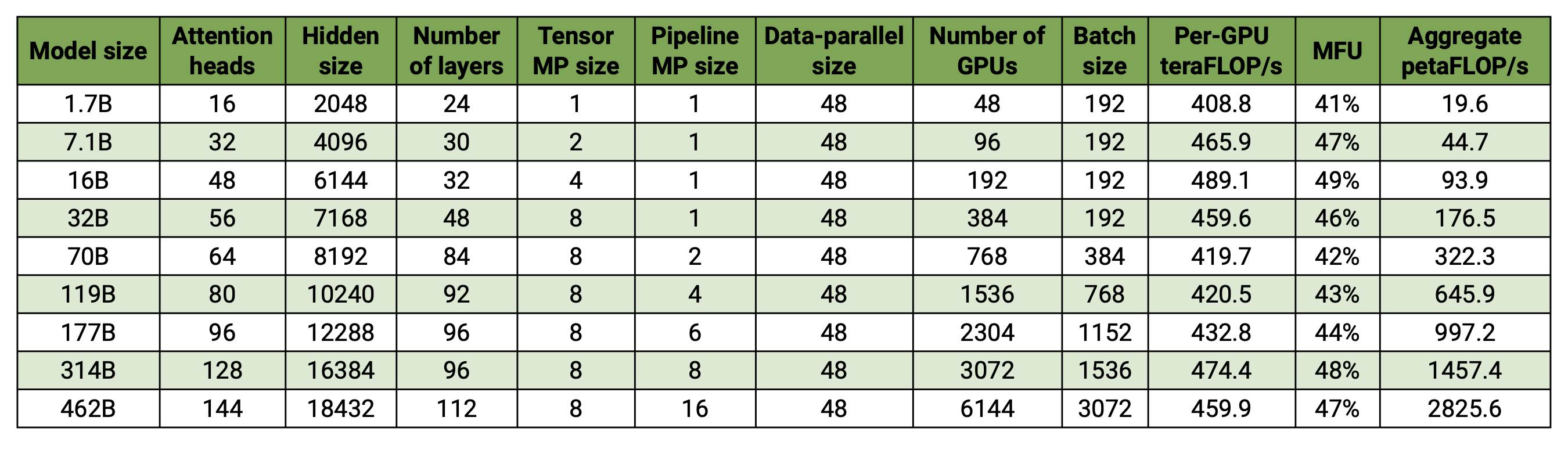
ผลลัพธ์ที่มาตราส่วนอ่อนแอของเราแสดงมาตราส่วนเชิงเส้นตรง (MFU เพิ่มขึ้นจาก 41% สำหรับรุ่นที่เล็กที่สุด คิดเป็น 47-48% สำหรับรุ่นที่ใหญ่ที่สุด) เนื่องจาก GEMM ที่ใหญ่กว่ามีความเข้มข้นทางคณิตศาสตร์ที่สูงกว่า และส่งผลให้ดำเนินการได้อย่างมีประสิทธิภาพมากกว่า
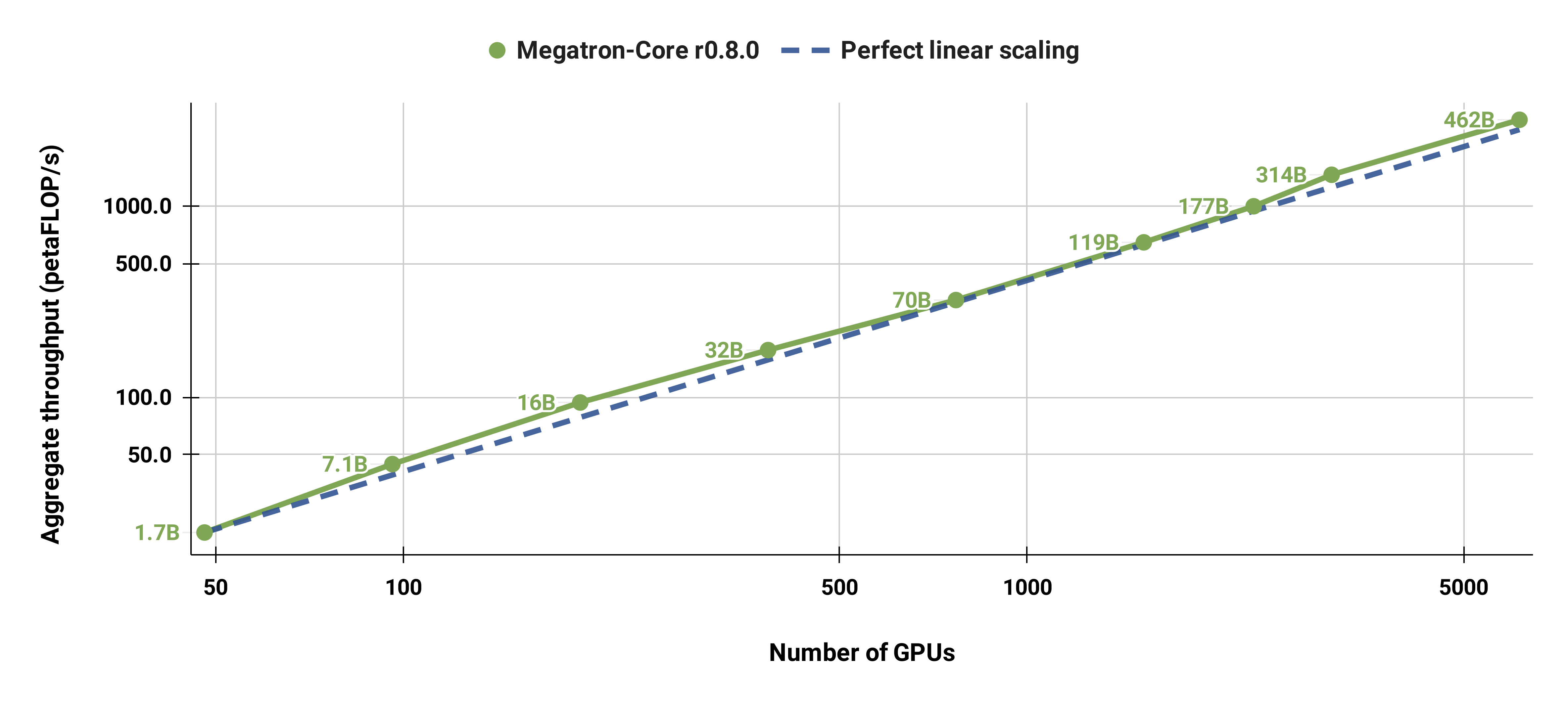
นอกจากนี้เรายังปรับขนาดโมเดล GPT-3 มาตรฐานที่แข็งแกร่ง (เวอร์ชันของเรามีพารามิเตอร์มากกว่า 175 พันล้านพารามิเตอร์เล็กน้อยเนื่องจากขนาดคำศัพท์ที่ใหญ่กว่า) จาก 96 H100 GPU เป็น 4608 GPU โดยใช้ขนาดแบตช์เดียวกันคือ 1152 ลำดับตลอด การสื่อสารจะถูกเปิดเผยมากขึ้นในขนาดที่ใหญ่ขึ้น ซึ่งส่งผลให้ MFU ลดลงจาก 47% เป็น 42%
เราขอแนะนำอย่างยิ่งให้ใช้คอนเทนเนอร์ PyTorch ของ NGC รุ่นล่าสุดที่มีโหนด DGX หากคุณไม่สามารถใช้สิ่งนี้ได้ด้วยเหตุผลบางประการ ให้ใช้ pytorch, cuda, nccl และ NVIDIA APEX รุ่นล่าสุด การประมวลผลข้อมูลล่วงหน้าต้องใช้ NLTK แม้ว่าจะไม่จำเป็นสำหรับการฝึกอบรม การประเมิน หรืองานดาวน์สตรีมก็ตาม
คุณสามารถเปิดใช้งานอินสแตนซ์ของคอนเทนเนอร์ PyTorch และติดตั้ง Megatron ชุดข้อมูลของคุณ และจุดตรวจสอบด้วยคำสั่ง Docker ต่อไปนี้:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
เราได้จัดเตรียมจุดตรวจสอบ BERT-345M และ GPT-345M ที่ได้รับการฝึกอบรมไว้แล้วเพื่อประเมินหรือปรับแต่งงานปลายน้ำ หากต้องการเข้าถึงจุดตรวจสอบเหล่านี้ ก่อนอื่นให้สมัครและตั้งค่า CLI Registry ของ NVIDIA GPU Cloud (NGC) เอกสารเพิ่มเติมสำหรับการดาวน์โหลดโมเดลสามารถดูได้ในเอกสารประกอบของ NGC
หรือคุณสามารถดาวน์โหลดจุดตรวจได้โดยตรงโดยใช้:
BERT-345M-uncased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
โมเดลต้องใช้ไฟล์คำศัพท์ในการรัน ไฟล์คำศัพท์ BERT Word Piece สามารถแยกได้จากโมเดล BERT ที่ได้รับการฝึกล่วงหน้าของ Google: แบบไม่มีกล่อง, แบบใส่กล่อง คุณสามารถดาวน์โหลดไฟล์คำศัพท์ GPT และตารางผสานได้โดยตรง
หลังการติดตั้ง จะมีขั้นตอนการทำงานที่เป็นไปได้หลายประการ ที่ครอบคลุมที่สุดคือ:
อย่างไรก็ตาม คุณสามารถแทนที่ขั้นตอนที่ 1 และ 2 ได้โดยใช้หนึ่งในโมเดลที่ได้รับการฝึกอบรมตามที่กล่าวข้างต้น
เราได้จัดเตรียมสคริปต์หลายตัวสำหรับการฝึกล่วงหน้าทั้ง BERT และ GPT ในไดเร็กทอรี examples รวมถึงสคริปต์สำหรับงานดาวน์สตรีมทั้งแบบ Zero-shot และแบบละเอียด รวมถึงการประเมิน MNLI, RACE, WikiText103 และ LAMBADA นอกจากนี้ยังมีสคริปต์สำหรับการสร้างข้อความโต้ตอบ GPT
ข้อมูลการฝึกอบรมต้องมีการประมวลผลล่วงหน้า ขั้นแรก วางข้อมูลการฝึกของคุณในรูปแบบ json แบบหลวมๆ โดยหนึ่ง json จะมีตัวอย่างข้อความต่อบรรทัด ตัวอย่างเช่น:
{"src": "www.nvidia.com", "text": "The Quick Brown Fox", "type": "Eng", "id": "0", "title": "First Part"}
{"src": "อินเทอร์เน็ต", "text": "กระโดดข้ามสุนัขขี้เกียจ", "type": "อังกฤษ", "id": "42", "title": "ส่วนที่สอง"}
ชื่อของฟิลด์ text ของ json สามารถเปลี่ยนแปลงได้โดยใช้แฟล็ก --json-key ใน preprocess_data.py ข้อมูลเมตาอื่น ๆ เป็นทางเลือกและไม่ได้ใช้ในการฝึกอบรม
จากนั้น json แบบหลวมๆ จะถูกประมวลผลเป็นรูปแบบไบนารี่สำหรับการฝึก หากต้องการแปลง json เป็นรูปแบบ mmap ให้ใช้ preprocess_data.py สคริปต์ตัวอย่างในการเตรียมข้อมูลสำหรับการฝึกอบรม BERT คือ:
เครื่องมือหลาม/preprocess_data.py
--input my-corpus.json
--เอาท์พุทคำนำหน้า my-bert
--vocab-ไฟล์ bert-vocab.txt
--tokenizer ประเภท BertWord PieceLowerCase
--แยกประโยค
เอาต์พุตจะเป็นสองไฟล์ที่มีชื่อ ในกรณีนี้ คือ my-bert_text_sentence.bin และ my-bert_text_sentence.idx --data-path ที่ระบุในการฝึกอบรม BERT ในภายหลังคือเส้นทางแบบเต็มและชื่อไฟล์ใหม่ แต่ไม่มีนามสกุลไฟล์
สำหรับ T5 ให้ใช้การประมวลผลล่วงหน้าแบบเดียวกับ BERT ซึ่งอาจเปลี่ยนชื่อเป็น:
--เอาท์พุทคำนำหน้า my-t5
จำเป็นต้องมีการแก้ไขเล็กน้อยสำหรับการประมวลผลข้อมูล GPT ล่วงหน้า กล่าวคือ การเพิ่มตารางผสาน โทเค็นท้ายเอกสาร การนำการแยกประโยคออก และการเปลี่ยนแปลงประเภทโทเค็น
เครื่องมือหลาม/preprocess_data.py
--input my-corpus.json
--เอาท์พุทคำนำหน้า my-gpt2
--vocab-ไฟล์ gpt2-vocab.json
--tokenizer ชนิด GPT2BPETokenizer
--ผสานไฟล์ gpt2-merges.txt
--ผนวก-eod
ที่นี่ไฟล์เอาต์พุตมีชื่อว่า my-gpt2_text_document.bin และ my-gpt2_text_document.idx เช่นเคย ในการฝึกอบรม GPT ให้ใช้ชื่อที่ยาวขึ้นโดยไม่มีส่วนขยายเป็น --data-path
อาร์กิวเมนต์บรรทัดคำสั่งเพิ่มเติมอธิบายไว้ในไฟล์ต้นฉบับ preprocess_data.py
สคริปต์ examples/bert/train_bert_340m_distributed.sh รันพารามิเตอร์ GPU 345M เดี่ยว BERT pretraining การดีบักเป็นการใช้งานหลักสำหรับการฝึก GPU เดี่ยว เนื่องจากฐานโค้ดและอาร์กิวเมนต์บรรทัดคำสั่งได้รับการปรับให้เหมาะสมสำหรับการฝึกที่มีการกระจายอย่างมาก ข้อโต้แย้งส่วนใหญ่ค่อนข้างอธิบายได้ในตัว ตามค่าเริ่มต้น อัตราการเรียนรู้จะลดลงเป็นเส้นตรงกับการวนซ้ำของการฝึกเริ่มต้นที่ --lr จนถึงค่าต่ำสุดที่กำหนดโดย --min-lr มากกว่า --lr-decay-iters การวนซ้ำ เศษส่วนของการวนซ้ำการฝึกที่ใช้สำหรับการวอร์มอัพถูกกำหนดโดย --lr-warmup-fraction แม้ว่านี่จะเป็นการฝึก GPU เดี่ยว ขนาดแบตช์ที่ระบุโดย --micro-batch-size จะเป็นขนาดแบตช์เส้นทางไปข้างหน้า-ข้างหลังเดียว และโค้ดจะดำเนินการขั้นตอนการสะสมแบบไล่ระดับจนกว่าจะถึงขนาด global-batch-size ซึ่งเป็นขนาดแบตช์ ต่อการวนซ้ำ ข้อมูลจะถูกแบ่งพาร์ติชันเป็นอัตราส่วน 949:50:1 สำหรับชุดการฝึกอบรม/การตรวจสอบ/การทดสอบ (ค่าเริ่มต้นคือ 969:30:1) การแบ่งพาร์ติชันนี้เกิดขึ้นได้ทันที แต่มีความสอดคล้องกันระหว่างการรันด้วยเมล็ดสุ่มเดียวกัน (1234 โดยค่าเริ่มต้น หรือระบุด้วยตนเองด้วย --seed ) เราใช้ train-iters เป็นการทำซ้ำการฝึกอบรมที่ร้องขอ อีกทางหนึ่ง เราสามารถจัดเตรียม --train-samples ซึ่งเป็นจำนวนตัวอย่างทั้งหมดที่จะฝึก หากมีตัวเลือกนี้ แทนที่จะจัดเตรียม --lr-decay-iters เราจะต้องจัดเตรียม --lr-decay-samples
มีการระบุตัวเลือกการบันทึก การบันทึกจุดตรวจ และช่วงเวลาการประเมิน โปรดทราบว่าตอนนี้ --data-path มีส่วนต่อท้าย _text_sentence เพิ่มเติมที่เพิ่มในการประมวลผลล่วงหน้า แต่จะไม่รวมนามสกุลไฟล์
อาร์กิวเมนต์บรรทัดคำสั่งเพิ่มเติมอธิบายไว้ในไฟล์ต้นฉบับ arguments.py
หากต้องการรัน train_bert_340m_distributed.sh ให้ทำการแก้ไขตามต้องการ รวมถึงการตั้งค่าตัวแปรสภาพแวดล้อมสำหรับ CHECKPOINT_PATH , VOCAB_FILE และ DATA_PATH ตรวจสอบให้แน่ใจว่าได้ตั้งค่าตัวแปรเหล่านี้เป็นเส้นทางในคอนเทนเนอร์ จากนั้นเปิดคอนเทนเนอร์โดยติดตั้ง Megatron และเส้นทางที่จำเป็น (ตามที่อธิบายไว้ในการตั้งค่า) และเรียกใช้สคริปต์ตัวอย่าง
สคริปต์ examples/gpt3/train_gpt3_175b_distributed.sh รันการฝึกอบรมล่วงหน้า GPT พารามิเตอร์ GPU 345M เดี่ยว ดังที่กล่าวไว้ข้างต้น การฝึกอบรม GPU เดี่ยวมีจุดประสงค์เพื่อการแก้ไขจุดบกพร่องเป็นหลัก เนื่องจากโค้ดได้รับการปรับให้เหมาะสมสำหรับการฝึกอบรมแบบกระจาย
ส่วนใหญ่เป็นไปตามรูปแบบเดียวกันกับสคริปต์ BERT ก่อนหน้าโดยมีความแตกต่างที่น่าสังเกตบางประการ: รูปแบบโทเค็นที่ใช้คือ BPE (ซึ่งต้องใช้ตารางผสานและไฟล์คำศัพท์ json ) แทนที่จะเป็น Word Piece สถาปัตยกรรมแบบจำลองอนุญาตให้มีลำดับที่ยาวขึ้น (โปรดทราบว่า การฝังตำแหน่งสูงสุดต้องมากกว่าหรือเท่ากับความยาวลำดับสูงสุด) และ --lr-decay-style ถูกตั้งค่าเป็นการสลายตัวของโคไซน์ โปรดทราบว่าตอนนี้ --data-path มีส่วนต่อท้าย _text_document เพิ่มเติมที่เพิ่มในการประมวลผลล่วงหน้า แต่ไม่รวมนามสกุลไฟล์
อาร์กิวเมนต์บรรทัดคำสั่งเพิ่มเติมอธิบายไว้ในไฟล์ต้นฉบับ arguments.py
train_gpt3_175b_distributed.sh สามารถเปิดได้ในลักษณะเดียวกับที่อธิบายไว้สำหรับ BERT ตั้งค่า env vars และทำการแก้ไขอื่นๆ เปิดใช้คอนเทนเนอร์ด้วยการเมาต์ที่เหมาะสม และรันสคริปต์ รายละเอียดเพิ่มเติมใน examples/gpt3/README.md
คล้ายกับ BERT และ GPT มาก สคริปต์ examples/t5/train_t5_220m_distributed.sh รัน GPU "ฐาน" เดี่ยว (พารามิเตอร์ ~ 220M) T5 การฝึกล่วงหน้า ความแตกต่างหลักจาก BERT และ GPT คือการเพิ่มอาร์กิวเมนต์ต่อไปนี้เพื่อรองรับสถาปัตยกรรม T5:
--kv-channels กำหนดมิติภายในของเมทริกซ์ "คีย์" และ "ค่า" ของกลไกความสนใจทั้งหมดในโมเดล สำหรับ BERT และ GPT จะมีค่าเริ่มต้นเป็นขนาดที่ซ่อนอยู่หารด้วยจำนวนส่วนหัวของความสนใจ แต่สามารถกำหนดค่าสำหรับ T5 ได้
--ffn-hidden-size กำหนดขนาดที่ซ่อนอยู่ในเครือข่ายฟีดส่งต่อภายในเลเยอร์หม้อแปลง สำหรับ BERT และ GPT จะมีค่าเริ่มต้นเป็น 4 เท่าของขนาดที่ซ่อนอยู่ของหม้อแปลง แต่สามารถกำหนดค่าสำหรับ T5 ได้
--encoder-seq-length และ --decoder-seq-length ตั้งค่าความยาวลำดับสำหรับตัวเข้ารหัสและตัวถอดรหัสแยกกัน
ข้อโต้แย้งอื่นๆ ทั้งหมดยังคงเหมือนเดิมสำหรับการฝึกอบรมล่วงหน้าของ BERT และ GPT รันตัวอย่างนี้ด้วยขั้นตอนเดียวกับที่อธิบายไว้ข้างต้นสำหรับสคริปต์อื่นๆ
รายละเอียดเพิ่มเติมใน examples/t5/README.md
สคริปต์ pretrain_{bert,gpt,t5}_distributed.sh ใช้ PyTorch ตัวเรียกใช้งานแบบกระจายสำหรับการฝึกอบรมแบบกระจาย ด้วยเหตุนี้ การฝึกอบรมแบบหลายโหนดจึงสามารถทำได้โดยการตั้งค่าตัวแปรสภาพแวดล้อมอย่างเหมาะสม ดูเอกสารประกอบ PyTorch อย่างเป็นทางการสำหรับคำอธิบายเพิ่มเติมเกี่ยวกับตัวแปรสภาพแวดล้อมเหล่านี้ ตามค่าเริ่มต้น การฝึกแบบหลายโหนดจะใช้แบ็กเอนด์แบบกระจายของ nccl ชุดอาร์กิวเมนต์เพิ่มเติมแบบง่ายๆ และการใช้โมดูลแบบกระจายของ PyTorch กับตัวเรียกใช้แบบยืดหยุ่น torchrun (เทียบเท่ากับ python -m torch.distributed.run ) เป็นข้อกำหนดเพิ่มเติมเพียงอย่างเดียวในการนำการฝึกอบรมแบบกระจายมาใช้ ดู pretrain_{bert,gpt,t5}_distributed.sh ใด ๆ สำหรับรายละเอียดเพิ่มเติม
เราใช้ความเท่าเทียมสองประเภท: ข้อมูลและความเท่าเทียมของแบบจำลอง การใช้งานข้อมูลแบบขนานของเรานั้นมีหน่วยเป็น megatron/core/distributed และรองรับการทับซ้อนกันของการลดความลาดชันด้วยการย้อนกลับเมื่อใช้ตัวเลือกบรรทัดคำสั่ง --overlap-grad-reduce
ประการที่สอง เราได้พัฒนาแนวทางแบบจำลองสองมิติแบบขนานที่เรียบง่ายและมีประสิทธิภาพ หากต้องการใช้มิติแรก ความเท่าเทียมของโมเดลเทนเซอร์ (การแยกการทำงานของโมดูลหม้อแปลงเดี่ยวบน GPU หลายตัว ดูส่วนที่ 3 ของรายงานของเรา) ให้เพิ่มแฟล็ก --tensor-model-parallel-size เพื่อระบุจำนวน GPU ที่ต้องการ แยกโมเดลพร้อมกับข้อโต้แย้งที่ส่งไปยังตัวเรียกใช้งานแบบกระจายตามที่กล่าวไว้ข้างต้น หากต้องการใช้มิติที่สอง ซึ่งก็คือ Sequence Parallelism ให้ระบุ --sequence-parallel ซึ่งจำเป็นต้องเปิดใช้งาน Tensor Model Parallelism ด้วยเช่นกัน เนื่องจากแยกข้าม GPU เดียวกัน (รายละเอียดเพิ่มเติมในส่วน 4.2.2 ของรายงานของเรา)
หากต้องการใช้โมเดลไปป์ไลน์แบบขนาน (การแบ่งโมดูลหม้อแปลงออกเป็นขั้นตอนโดยมีจำนวนโมดูลหม้อแปลงเท่ากันในแต่ละขั้นตอน จากนั้นดำเนินการไปป์ไลน์โดยการแบ่งแบทช์ออกเป็นไมโครแบทช์ที่มีขนาดเล็กลง ดูส่วนที่ 2.2 ของรายงานของเรา) ให้ใช้ --pipeline-model-parallel-size - แฟล็ก --pipeline-model-parallel-size เพื่อระบุจำนวนขั้นตอนที่จะแยกโมเดลออกเป็น (เช่น การแยกโมเดลที่มีชั้นหม้อแปลง 24 ชั้นเป็น 4 ขั้นตอนจะหมายความว่าแต่ละขั้นตอนจะได้รับชั้นหม้อแปลง 6 ชั้นในแต่ละชั้น)
เรามีตัวอย่างวิธีใช้โมเดลความเท่าเทียมสองรูปแบบที่แตกต่างกันนี้ โดยสคริปต์ตัวอย่างที่ลงท้ายด้วย distributed_with_mp.sh
นอกเหนือจากการเปลี่ยนแปลงเล็กๆ น้อยๆ เหล่านี้ การฝึกแบบกระจายจะเหมือนกับการฝึกบน GPU ตัวเดียว
กำหนดการการวางท่อแบบแทรกสลับ (รายละเอียดเพิ่มเติมในส่วน 2.2.2 ของรายงานของเรา) สามารถเปิดใช้งานได้โดยใช้อาร์กิวเมนต์ --num-layers-per-virtual-pipeline-stage ซึ่งควบคุมจำนวนชั้นของหม้อแปลงในขั้นตอนเสมือน (โดยค่าเริ่มต้น ด้วยกำหนดการที่ไม่มีการสลับกัน GPU แต่ละตัวจะดำเนินการขั้นตอนเสมือนเดียวด้วยเลเยอร์หม้อแปลง NUM_LAYERS / PIPELINE_MP_SIZE ) จำนวนเลเยอร์ทั้งหมดในโมเดลหม้อแปลงควรหารด้วยค่าอาร์กิวเมนต์นี้ นอกจากนี้ จำนวนไมโครแบทช์ในไปป์ไลน์ (คำนวณเป็น GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) ควรหารด้วย PIPELINE_MP_SIZE เมื่อใช้กำหนดการนี้ (เงื่อนไขนี้จะถูกตรวจสอบในการยืนยันในโค้ด) ไม่รองรับกำหนดการแบบแทรกสลับสำหรับไปป์ไลน์ที่มี 2 ระยะ ( PIPELINE_MP_SIZE=2 )
เพื่อลดการใช้หน่วยความจำ GPU เมื่อฝึกโมเดลขนาดใหญ่ เราสนับสนุนจุดตรวจสอบการเปิดใช้งานและการคำนวณใหม่ในรูปแบบต่างๆ แทนที่จะให้การเปิดใช้งานทั้งหมดถูกจัดเก็บไว้ในหน่วยความจำเพื่อใช้ระหว่าง backprop ดังเช่นในกรณีทั่วไปของโมเดลการเรียนรู้เชิงลึก เฉพาะการเปิดใช้งานที่ "จุดตรวจสอบ" บางอย่างในโมเดลเท่านั้นที่จะคงไว้ (หรือจัดเก็บ) ไว้ในหน่วยความจำ และการเปิดใช้งานอื่นๆ จะถูกคำนวณใหม่ -the-fly เมื่อจำเป็นสำหรับ backprop โปรดทราบว่าจุดตรวจสอบประเภทนี้ การเปิดใช้งาน จุดตรวจสอบ แตกต่างอย่างมากจากจุดตรวจสอบของพารามิเตอร์โมเดลและสถานะเครื่องมือเพิ่มประสิทธิภาพ ซึ่งถูกกล่าวถึงในที่อื่น
เรารองรับรายละเอียดการคำนวณซ้ำสองระดับ: selective และ full การคำนวณใหม่แบบเลือกเป็นค่าเริ่มต้น และแนะนำให้ใช้ในเกือบทุกกรณี โหมดนี้จะเก็บการเปิดใช้งานที่ใช้พื้นที่จัดเก็บหน่วยความจำน้อยลงในหน่วยความจำ และมีราคาแพงกว่าในการคำนวณใหม่และคำนวณการเปิดใช้งานที่ใช้พื้นที่จัดเก็บหน่วยความจำมากขึ้น แต่มีราคาไม่แพงนักในการคำนวณใหม่ ดูเอกสารของเราสำหรับรายละเอียด คุณควรพบว่าโหมดนี้เพิ่มประสิทธิภาพสูงสุดในขณะที่ลดหน่วยความจำที่จำเป็นในการจัดเก็บการเปิดใช้งาน หากต้องการเปิดใช้งานการคำนวณการเปิดใช้งานแบบเลือกใหม่ เพียงใช้ --recompute-activations
สำหรับกรณีที่หน่วยความจำมีจำกัดมาก การคำนวณ full จะบันทึกเฉพาะอินพุตไปยังเลเยอร์ Transformer หรือกลุ่มหรือบล็อกของเลเยอร์ Transformer และคำนวณทุกอย่างใหม่อีกครั้ง หากต้องการเปิดใช้งานการเปิดใช้งานเต็มรูปแบบให้ใช้การคำนวณใหม่ --recompute-granularity full เมื่อใช้การคำนวณการเปิดใช้งานเต็มรูป full มีสองวิธี: uniform และ block เลือกโดยใช้อาร์กิวเมนต์ --recompute-method
วิธีการ uniform จะแบ่งเลเยอร์ของหม้อแปลงออกเป็นกลุ่มของเลเยอร์ต่างๆ อย่างสม่ำเสมอ (แต่ละกลุ่มของขนาด --recompute-num-layers ) และจัดเก็บการเปิดใช้งานอินพุตของแต่ละกลุ่มไว้ในหน่วยความจำ ขนาดกลุ่มพื้นฐานคือ 1 และในกรณีนี้ การเปิดใช้งานอินพุตของเลเยอร์หม้อแปลงแต่ละชั้นจะถูกจัดเก็บไว้ เมื่อหน่วยความจำ GPU ไม่เพียงพอ การเพิ่มจำนวนเลเยอร์ต่อกลุ่มจะลดการใช้หน่วยความจำ ทำให้สามารถฝึกอบรมโมเดลที่ใหญ่ขึ้นได้ ตัวอย่างเช่น เมื่อตั้งค่า --recompute-num-layers เป็น 4 ระบบจะจัดเก็บเฉพาะการเปิดใช้งานอินพุตของแต่ละกลุ่มที่มีชั้นหม้อแปลง 4 ชั้นเท่านั้น
วิธี block จะคำนวณการเปิดใช้งานอินพุตของหมายเลขเฉพาะ (กำหนดโดย --recompute-num-layers ) ของชั้นหม้อแปลงแต่ละชั้นต่อระยะไปป์ไลน์ และจัดเก็บการเปิดใช้งานอินพุตของเลเยอร์ที่เหลือในระยะไปป์ไลน์ การลด --recompute-num-layers ส่งผลให้มีการจัดเก็บการเปิดใช้งานอินพุตไปยังชั้นหม้อแปลงมากขึ้น ซึ่งจะช่วยลดการคำนวณการเปิดใช้งานใหม่ที่จำเป็นใน backprop จึงช่วยปรับปรุงประสิทธิภาพการฝึกอบรมในขณะที่เพิ่มการใช้หน่วยความจำ ตัวอย่างเช่น เมื่อเราระบุ 5 เลเยอร์เพื่อคำนวณใหม่ 8 เลเยอร์ต่อระยะไปป์ไลน์ การเปิดใช้งานอินพุตของเลเยอร์หม้อแปลง 5 เลเยอร์แรกเท่านั้นจะถูกคำนวณใหม่ในขั้นตอน backprop ในขณะที่การเปิดใช้งานอินพุตสำหรับ 3 เลเยอร์สุดท้ายจะถูกเก็บไว้ --recompute-num-layers สามารถเพิ่มขึ้นได้จนกว่าจำนวนพื้นที่หน่วยความจำที่ต้องการจะน้อยพอที่จะใส่ในหน่วยความจำที่มีอยู่ได้ ดังนั้นจึงใช้หน่วยความจำให้เกิดประโยชน์สูงสุดและเพิ่มประสิทธิภาพสูงสุด
การใช้งาน: --use-distributed-optimizer ใช้งานได้กับทุกรุ่นและทุกประเภทข้อมูล
เครื่องมือเพิ่มประสิทธิภาพแบบกระจายเป็นเทคนิคการประหยัดหน่วยความจำ โดยที่สถานะของเครื่องมือเพิ่มประสิทธิภาพจะถูกกระจายเท่าๆ กันในอันดับคู่ขนานของข้อมูล (เทียบกับวิธีการดั้งเดิมในการจำลองสถานะเครื่องมือเพิ่มประสิทธิภาพข้ามอันดับคู่ขนานของข้อมูล) ตามที่อธิบายไว้ใน ZeRO: การเพิ่มประสิทธิภาพหน่วยความจำสู่การฝึกอบรมโมเดลพารามิเตอร์ล้านล้าน การใช้งานของเราจะกระจายสถานะตัวเพิ่มประสิทธิภาพทั้งหมดที่ไม่ทับซ้อนกับสถานะของโมเดล ตัวอย่างเช่น เมื่อใช้พารามิเตอร์โมเดล fp16 เครื่องมือเพิ่มประสิทธิภาพแบบกระจายจะรักษาสำเนาพารามิเตอร์หลักและผู้สำเร็จการศึกษาของ fp32 แยกต่างหาก ซึ่งกระจายไปตามอันดับ DP อย่างไรก็ตาม เมื่อใช้พารามิเตอร์โมเดล bf16 การจบระดับหลักของ fp32 ของเครื่องมือเพิ่มประสิทธิภาพแบบกระจายจะเหมือนกับการจบระดับ fp32 ของโมเดล ดังนั้นการจบในกรณีนี้จะไม่ถูกกระจาย (แม้ว่าพารามิเตอร์หลักของ fp32 ยังคงกระจายอยู่ เนื่องจากแยกจาก bf16 พารามิเตอร์โมเดล)
การประหยัดหน่วยความจำตามทฤษฎีจะแตกต่างกันไปขึ้นอยู่กับการรวมกันของพารามิเตอร์ dtype และ grad dtype ของโมเดล ในการนำไปใช้งานของเรา จำนวนไบต์ตามทฤษฎีต่อพารามิเตอร์คือ (โดยที่ 'd' คือขนาดข้อมูลแบบขนาน):
| ออปติไมซ์แบบไม่กระจาย | การเพิ่มประสิทธิภาพแบบกระจาย | |
|---|---|---|
| พารามิเตอร์ fp16, ผู้สำเร็จการศึกษา fp16 | 20 | 4 + 16/วัน |
| พารามิเตอร์ bf16, ระดับ fp32 | 18 | 6 + 12/วัน |
| พารามิเตอร์ fp32, ระดับ fp32 | 16 | 8 + 8/วัน |
เช่นเดียวกับความเท่าเทียมของข้อมูลทั่วไป การทับซ้อนกันของการลดความลาดชัน (ในกรณีนี้คือการลดการกระจาย) กับการส่งผ่านย้อนกลับสามารถอำนวยความสะดวกได้โดยใช้แฟล็ก --overlap-grad-reduce นอกจากนี้ การทับซ้อนกันของพารามิเตอร์ all-gather สามารถซ้อนทับกับการส่งต่อโดยใช้ --overlap-param-gather
การใช้งาน: --use-flash-attn รองรับขนาดหัวความสนใจสูงสุด 128
FlashAttention เป็นอัลกอริธึมที่รวดเร็วและมีประสิทธิภาพหน่วยความจำในการคำนวณความสนใจที่แน่นอน ช่วยเพิ่มความเร็วในการฝึกโมเดลและลดความต้องการหน่วยความจำ
ในการติดตั้ง FlashAttention:
pip install flash-attn ใน examples/gpt3/train_gpt3_175b_distributed.sh เราได้ยกตัวอย่างวิธีกำหนดค่า Megatron เพื่อฝึก GPT-3 ด้วยพารามิเตอร์ 175 พันล้านพารามิเตอร์บน 1,024 GPU สคริปต์นี้ได้รับการออกแบบสำหรับ slurm ด้วยปลั๊กอิน pyxis แต่สามารถนำไปใช้กับตัวกำหนดเวลาอื่น ๆ ได้อย่างง่ายดาย มันใช้ความขนานของเทนเซอร์ 8 ทิศทางและความขนานของไปป์ไลน์ 16 ทิศทาง ด้วยตัวเลือก global-batch-size 1536 และ rampup-batch-size 16 16 5859375 การฝึกอบรมจะเริ่มต้นด้วยขนาดชุดงานทั่วโลก 16 และเพิ่มขนาดชุดงานทั่วโลกเชิงเส้นเป็น 1536 ในตัวอย่าง 5,859,375 ตัวอย่างโดยเพิ่มขั้นตอนที่ 16 ชุดข้อมูลการฝึกอบรมอาจเป็นได้ทั้ง ชุดข้อมูลชุดเดียวหรือหลายชุดรวมกับชุดน้ำหนัก
ด้วยขนาดแบทช์ทั่วโลกเต็มรูปแบบที่ 1536 บน A100 GPU จำนวน 1,024 ตัว การวนซ้ำแต่ละครั้งจะใช้เวลาประมาณ 32 วินาที ทำให้ได้ 138 teraFLOPs ต่อ GPU ซึ่งเป็น 44% ของ FLOP สูงสุดตามทฤษฎี
Retro (Borgeaud et al., 2022) คือโมเดลภาษาเฉพาะตัวถอดรหัสอัตโนมัติ (LM) ที่ได้รับการฝึกล่วงหน้าด้วยการดึงข้อมูลเสริม Retro มีความสามารถในการปรับขนาดได้จริงเพื่อรองรับการฝึกล่วงหน้าขนาดใหญ่ตั้งแต่เริ่มต้นโดยการดึงโทเค็นจากล้านล้านโทเค็น การฝึกอบรมล่วงหน้าพร้อมการดึงข้อมูลให้กลไกการจัดเก็บความรู้ข้อเท็จจริงที่มีประสิทธิภาพมากขึ้น เมื่อเปรียบเทียบกับการจัดเก็บความรู้ข้อเท็จจริงโดยปริยายภายในพารามิเตอร์ของเครือข่าย ดังนั้นจึงลดพารามิเตอร์แบบจำลองได้อย่างมากในขณะที่บรรลุความฉงนสนเท่ห์ต่ำกว่า GPT มาตรฐาน Retro ยังให้ความยืดหยุ่นในการอัปเดตความรู้ที่จัดเก็บไว้ใน LM (Wang et al., 2023a) โดยการอัพเดตฐานข้อมูลการดึงข้อมูลโดยไม่ต้องฝึกอบรม LM อีกครั้ง
InstructRetro (Wang et al., 2023b) ขยายขนาด Retro ให้เป็น 48B เพิ่มเติม โดยมี LLM ที่ใหญ่ที่สุดที่ได้รับการฝึกฝนล่วงหน้าพร้อมการดึงข้อมูล (ณ เดือนธันวาคม 2023) แบบจำลองรากฐานที่ได้รับ Retro 48B นั้นมีประสิทธิภาพเหนือกว่า GPT อย่างมากในแง่ของความฉงนสนเท่ห์ ด้วยการปรับแต่งคำสั่งบน Retro InstructRetro แสดงให้เห็นถึงการปรับปรุงที่สำคัญเหนือ GPT ที่ปรับแต่งคำสั่งในงานดาวน์สตรีมในการตั้งค่า Zero-shot โดยเฉพาะอย่างยิ่ง การปรับปรุงโดยเฉลี่ยของ InstructRetro คือ 7% เมื่อเทียบกับ GPT ในงาน QA แบบสั้น 8 งาน และ 10% เมื่อเทียบกับ GPT ในงาน QA แบบยาวที่ท้าทาย 4 งาน นอกจากนี้เรายังพบว่าเราสามารถลดตัวเข้ารหัสจากสถาปัตยกรรม InstructRetro และใช้แกนหลักของตัวถอดรหัส InstructRetro เป็น GPT ได้โดยตรง ในขณะที่ได้ผลลัพธ์ที่เทียบเคียงได้
ใน repo นี้ เรามีคำแนะนำในการทำซ้ำแบบ end-to-end เพื่อใช้งาน Retro และ InstructRetro ซึ่งครอบคลุม
ดู tools/retro/README.md สำหรับภาพรวมโดยละเอียด
ดูตัวอย่าง/mambaสำหรับรายละเอียด
เรามีอาร์กิวเมนต์บรรทัดคำสั่งหลายรายการ ซึ่งมีรายละเอียดอยู่ในสคริปต์ที่แสดงด้านล่าง เพื่อจัดการงานดาวน์สตรีมแบบ Zero-shot และแบบละเอียดต่างๆ อย่างไรก็ตาม คุณยังสามารถปรับแต่งโมเดลของคุณจากจุดตรวจสอบที่ได้รับการฝึกมาแล้วบนองค์กรอื่นๆ ได้ตามต้องการ ในการทำเช่นนั้น เพียงเพิ่มแฟล็ก --finetune และปรับไฟล์อินพุตและพารามิเตอร์การฝึกภายในสคริปต์การฝึกต้นฉบับ จำนวนการวนซ้ำจะถูกรีเซ็ตเป็นศูนย์ และตัวเพิ่มประสิทธิภาพและสถานะภายในจะถูกเริ่มต้นใหม่ หากการปรับแต่งแบบละเอียดถูกขัดจังหวะไม่ว่าด้วยเหตุผลใดก็ตาม อย่าลืมลบแฟล็ก --finetune ออกก่อนที่จะดำเนินการต่อ ไม่เช่นนั้นการฝึกจะเริ่มอีกครั้งตั้งแต่ต้น
เนื่องจากการประเมินต้องใช้หน่วยความจำน้อยกว่าการฝึกอย่างมาก จึงอาจเป็นประโยชน์ที่จะรวมโมเดลที่ได้รับการฝึกแบบขนานเพื่อใช้กับ GPU น้อยลงในงานดาวน์สตรีม สคริปต์ต่อไปนี้ทำให้สิ่งนี้สำเร็จ ตัวอย่างนี้อ่านในโมเดล GPT ที่มีเทนเซอร์ 4 ทิศทางและความขนานของโมเดลไปป์ไลน์ 4 ทิศทาง และเขียนแบบจำลองที่มีเทนเซอร์ 2 ทิศทางและความขนานของโมเดลไปป์ไลน์ 2 ทิศทาง
เครื่องมือหลาม/จุดตรวจสอบ/convert.py
--รุ่นประเภท GPT
--load-dir จุดตรวจ/gpt3_tp4_pp4
--save-dir ด่าน/gpt3_tp2_pp2
--เป้าหมาย-เทนเซอร์-ขนาดขนาน 2
--เป้าหมาย-ไปป์ไลน์-ขนาดขนาน 2
มีการอธิบายงานดาวน์สตรีมหลายงานสำหรับทั้งรุ่น GPT และ BERT ด้านล่างนี้ สามารถรันในโหมดกระจายและสร้างโมเดลแบบขนานโดยมีการเปลี่ยนแปลงแบบเดียวกับที่ใช้ในสคริปต์การฝึกอบรม
เราได้รวมเซิร์ฟเวอร์ REST แบบธรรมดาเพื่อใช้สำหรับการสร้างข้อความไว้ใน tools/run_text_generation_server.py คุณดำเนินการเหมือนกับที่คุณเริ่มงานการฝึกอบรมล่วงหน้า โดยระบุจุดตรวจสอบที่ได้รับการฝึกอบรมไว้อย่างเหมาะสม นอกจากนี้ยังมีพารามิเตอร์ทางเลือกบางประการ: temperature , top-k และ top-p ดู --help หรือไฟล์ต้นฉบับสำหรับข้อมูลเพิ่มเติม ดูตัวอย่าง/การอนุมาน/run_text_generation_server_345M.sh สำหรับตัวอย่างวิธีรันเซิร์ฟเวอร์
เมื่อเซิร์ฟเวอร์กำลังทำงาน คุณสามารถใช้ tools/text_generation_cli.py เพื่อสืบค้นได้ โดยต้องใช้อาร์กิวเมนต์หนึ่งตัวซึ่งเป็นโฮสต์ที่เซิร์ฟเวอร์กำลังทำงานอยู่
เครื่องมือ/text_generation_cli.py localhost:5000
คุณยังสามารถใช้ CURL หรือเครื่องมืออื่นๆ เพื่อค้นหาเซิร์ฟเวอร์ได้โดยตรง:
curl 'http://localhost:5000/api' -X 'PUT' -H 'ประเภทเนื้อหา: application/json; charset=UTF-8' -d '{"พร้อมท์":["สวัสดีชาวโลก"], "tokens_to_generate":1}'
ดู megatron/inference/text_generation_server.py สำหรับตัวเลือก API เพิ่มเติม
เรารวมตัวอย่างไว้ใน examples/academic_paper_scripts/detxoify_lm/ เพื่อล้างพิษโมเดลภาษาโดยใช้ประโยชน์จากพลังกำเนิดของโมเดลภาษา
ดูตัวอย่าง/academic_paper_scripts/detxoify_lm/README.md สำหรับบทช่วยสอนทีละขั้นตอนเกี่ยวกับวิธีการฝึกอบรมแบบปรับใช้โดเมนและล้างพิษ LM โดยใช้คลังข้อมูลที่สร้างขึ้นเอง
เรารวมสคริปต์ตัวอย่างสำหรับการประเมิน GPT ในการประเมินความซับซ้อนของ WikiText และความแม่นยำของ LAMBADA Cloze
สำหรับการเปรียบเทียบกับงานก่อนหน้านี้ เราจะประเมินความฉงนสนเท่ห์ของชุดข้อมูลทดสอบ WikiText-103 ระดับคำ และคำนวณความงุนงงอย่างเหมาะสมเมื่อได้รับการเปลี่ยนแปลงในโทเค็นเมื่อใช้โทเค็นไนเซอร์คำย่อยของเรา
เราใช้คำสั่งต่อไปนี้เพื่อรันการประเมิน WikiText-103 บนโมเดลพารามิเตอร์ 345M
TASK="WIKITEXT103"
VALID_DATA=<เส้นทางข้อความวิกิ>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=จุดตรวจ/gpt2_345m
COMMON_TASK_ARGS="--จำนวนเลเยอร์ 24
--ซ่อนขนาด 1024
--จำนวนความสนใจหัว 16
--seq ยาว 1,024
--การฝังตำแหน่งสูงสุด 1,024
--fp16
--ไฟล์คำศัพท์ $VOCAB_FILE"
งานหลาม/main.py
--งาน $TASK
$COMMON_TASK_ARGS
--ข้อมูลที่ถูกต้อง $VALID_DATA
--tokenizer ชนิด GPT2BPETokenizer
--ผสานไฟล์ $MERGE_FILE
--โหลด $CHECKPOINT_PATH
--ไมโครแบทช์ขนาด 8
--บันทึกช่วง 10
--ไม่มี-โหลด-เพิ่มประสิทธิภาพ
--no-load-rng
ในการคำนวณความแม่นยำของการปิดล้อม LAMBADA (ความแม่นยำในการทำนายโทเค็นสุดท้ายจากโทเค็นก่อนหน้า) เราใช้ชุดข้อมูล LAMBADA เวอร์ชันที่ได้รับการประมวลผลแล้วและยกเลิกโทเค็นแล้ว
เราใช้คำสั่งต่อไปนี้เพื่อรันการประเมิน LAMBADA บนโมเดลพารามิเตอร์ 345M โปรดทราบว่าควรใช้แฟล็ก --strict-lambada เพื่อกำหนดให้มีการจับคู่คำทั้งหมด ตรวจสอบให้แน่ใจว่า lambada เป็นส่วนหนึ่งของเส้นทางไฟล์
TASK="แลมบาดา"
VALID_DATA=<เส้นทางแลมบาดา>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=จุดตรวจ/gpt2_345m
COMMON_TASK_ARGS=<เหมือนกับการประเมินความฉงนสนเท่ห์ของ WikiText ด้านบน>
งานหลาม/main.py
--งาน $TASK
$COMMON_TASK_ARGS
--ข้อมูลที่ถูกต้อง $VALID_DATA
--tokenizer ชนิด GPT2BPETokenizer
--เข้มงวดแลมบาดา
--ผสานไฟล์ $MERGE_FILE
--โหลด $CHECKPOINT_PATH
--ไมโครแบทช์ขนาด 8
--บันทึกช่วง 10
--ไม่มี-โหลด-เพิ่มประสิทธิภาพ
--no-load-rng
อาร์กิวเมนต์บรรทัดคำสั่งเพิ่มเติมอธิบายไว้ในไฟล์ต้นฉบับ main.py
สคริปต์ต่อไปนี้ปรับแต่งโมเดล BERT เพื่อประเมินชุดข้อมูล RACE ไดเร็กทอรี TRAIN_DATA และ VALID_DATA มีชุดข้อมูล RACE เป็นไฟล์ .txt แยกกัน โปรดทราบว่าสำหรับ RACE ขนาดแบทช์คือจำนวนแบบสอบถาม RACE ที่จะประเมิน เนื่องจากการสืบค้น RACE แต่ละรายการมีสี่ตัวอย่าง ขนาดชุดงานที่มีประสิทธิภาพที่ส่งผ่านแบบจำลองจะเป็นสี่เท่าของขนาดชุดงานที่ระบุในบรรทัดคำสั่ง
TRAIN_DATA = "ข้อมูล/การแข่งขัน/รถไฟ/กลาง"
VALID_DATA="ข้อมูล/การแข่งขัน/dev/middle
ข้อมูล/การแข่งขัน/dev/สูง"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=จุดตรวจ/bert_345m
CHECKPOINT_PATH=จุดตรวจ/bert_345m_race
COMMON_TASK_ARGS="--จำนวนเลเยอร์ 24
--ซ่อนขนาด 1024
--จำนวนความสนใจหัว 16
--seq ยาว 512
--ตำแหน่งสูงสุด-การฝัง 512
--fp16
--ไฟล์คำศัพท์ $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--ข้อมูลรถไฟ $TRAIN_DATA
--ข้อมูลที่ถูกต้อง $VALID_DATA
--จุดตรวจที่ผ่านการฝึกอบรมมาแล้ว $PRETRAINED_CHECKPOINT
--บันทึกช่วง 10,000
--บันทึก $CHECKPOINT_PATH
--บันทึกช่วง 100
--eval-ช่วง 1,000
--eval-iters 10
--น้ำหนักสลาย 1.0e-1"
งานหลาม/main.py
--งานการแข่งขัน
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer ประเภท BertWord PieceLowerCase
--ยุค 3
--ไมโครแบทช์ขนาด 4
--lr 1.0e-5
--lr-วอร์มอัพ-เศษส่วน 0.06
สคริปต์ต่อไปนี้ปรับแต่งโมเดล BERT สำหรับการประเมินด้วยคลังข้อมูลคู่ประโยค MultiNLI เนื่องจากงานที่ตรงกันนั้นค่อนข้างคล้ายกันสคริปต์จึงสามารถปรับแต่งได้อย่างรวดเร็วเพื่อทำงานกับชุดข้อมูล Quora Question Pairs (QQP) เช่นกัน
train_data = "data/glue_data/mnli/train.tsv"
valid_data = "data/glue_data/mnli/dev_matched.tsv
data/glue_data/mnli/dev_mismatched.tsv "
pretrained_checkpoint = จุดตรวจ/bert_345m
vocab_file = bert-vocab.txt
จุดตรวจสอบ _path = จุดตรวจ/bert_345m_mnli
Common_task_args = <เหมือนกับในการประเมินผลการแข่งขันด้านบน>
Common_task_args_ext = <เหมือนกับในการประเมินผลการแข่งขันด้านบน>
งาน Python/main.py
-งาน mnli
$ Common_task_args
$ Common_task_args_ext
-BertwordPieCelowerCase ประเภท tokenizer
-EPOCHS 5
-Micro-batch-size 8
-lr 5.0e-5
-LR-Warmup-Fraction 0.065
ตระกูล LLAMA-2 แบบจำลองเป็นชุดโอเพนซอร์ซของรุ่นที่ได้รับการฝึกฝนและ Finetuned (สำหรับการแชท) ที่ได้ผลลัพธ์ที่แข็งแกร่งในชุดเกณฑ์มาตรฐานที่กว้าง ในช่วงเวลาของการเปิดตัวรุ่น LLAMA-2 ได้รับผลลัพธ์ที่ดีที่สุดสำหรับโมเดลโอเพ่นซอร์สและแข่งขันกับรุ่น GPT-3.5 ที่เป็นแหล่งปิด (ดู https://arxiv.org/pdf/2307.09288.pdf)
จุดตรวจ LLAMA-2 สามารถโหลดลงใน megatron เพื่อการอนุมานและ finetuning ดูเอกสารที่นี่
ตระกูล Megatron-Core (McOore) GPTModel สนับสนุนอัลกอริทึมการวัดปริมาณขั้นสูงและการอนุมานประสิทธิภาพสูงผ่าน Tensorrt-LLM
ดูการเพิ่มประสิทธิภาพโมเดล Megatron และการปรับใช้สำหรับตัวอย่าง llama2 และ nemotron3
เราไม่ได้โฮสต์ชุดข้อมูลใด ๆ สำหรับการฝึกอบรม GPT หรือ BERT เราให้รายละเอียดคอลเลกชันของพวกเขาเพื่อให้ผลลัพธ์ของเราอาจถูกทำซ้ำ
เราขอแนะนำให้ติดตามกระบวนการสกัดข้อมูล Wikipedia ที่ระบุโดย Google Research: "การประมวลผลล่วงหน้าที่แนะนำคือการดาวน์โหลดการถ่ายโอนข้อมูลล่าสุดแยกข้อความด้วย wikiextractor.py แล้วใช้การทำความสะอาดที่จำเป็นเพื่อแปลงเป็นข้อความธรรมดา"
เราขอแนะนำให้ใช้อาร์กิวเมนต์ --json เมื่อใช้ wikiextractor ซึ่งจะทิ้งข้อมูล Wikipedia ลงในรูปแบบ Loose JSON (วัตถุ JSON หนึ่งชิ้นต่อบรรทัด) ทำให้สามารถจัดการได้มากขึ้นในระบบไฟล์ เราขอแนะนำให้ประมวลผลชุดข้อมูล JSON นี้ล่วงหน้าด้วยมาตรฐานเครื่องหมายวรรคตอน NLTK สำหรับการฝึกอบรมเบิร์ตให้ใช้ --split-sentences เพื่อ preprocess_data.py ตามที่อธิบายไว้ข้างต้นเพื่อรวมการแบ่งประโยคในดัชนีที่ผลิต หากคุณต้องการใช้ข้อมูล Wikipedia สำหรับการฝึกอบรม GPT คุณควรทำความสะอาดด้วย NLTK/Spacy/FTFY แต่อย่าใช้ธง --split-sentences
เราใช้ห้องสมุด OpenWebText ที่เปิดเผยต่อสาธารณะจากงาน JCPeterson และ Eukaryote31 เพื่อดาวน์โหลด URL จากนั้นเรากรองทำความสะอาดและซ้ำซ้อนเนื้อหาที่ดาวน์โหลดทั้งหมดตามขั้นตอนที่อธิบายไว้ในไดเรกทอรี OpenWebText ของเรา สำหรับ URL Reddit ที่สอดคล้องกับเนื้อหาจนถึงเดือนตุลาคม 2018 เรามาถึงเนื้อหาประมาณ 37GB
การฝึกอบรม Megatron สามารถทำซ้ำได้ เพื่อเปิดใช้งานโหมดนี้ใช้ --deterministic-mode ซึ่งหมายความว่าการกำหนดค่าการฝึกอบรมเดียวกันทำงานสองครั้งในสภาพแวดล้อม HW และ SW เดียวกันควรสร้างจุดตรวจสอบแบบจำลองการสูญเสียและค่าตัวชี้วัดความแม่นยำ (ตัวชี้วัดเวลาวนซ้ำอาจแตกต่างกันไป)
ขณะนี้มีการเพิ่มประสิทธิภาพ megatron ที่รู้จักกันสามประการที่ทำลายการทำซ้ำในขณะที่ยังคงให้การฝึกอบรมที่เหมือนกันเกือบทั้งหมด:
NCCL_ALGO ) เป็นสิ่งสำคัญ เราได้ทดสอบสิ่งต่อไปนี้: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain รหัสยอมรับการใช้ ^NVLS ซึ่งอนุญาตให้ NCCL เลือกอัลกอริทึมที่ไม่ใช่ NVLS; ทางเลือกของมันดูเหมือนจะมีเสถียรภาพ--use-flash-attnNVTE_ALLOW_NONDETERMINISTIC_ALGO=0นอกจากนี้การตรวจสอบได้รับการตรวจสอบในคอนเทนเนอร์ NGC Pytorch จนถึงและใหม่กว่า 23.12 หากคุณสังเกตเห็นการไม่ใช้งานในการฝึกอบรม Megatron ภายใต้สถานการณ์อื่น ๆ โปรดเปิดปัญหา
ด้านล่างนี้เป็นโครงการที่เราใช้ Megatron โดยตรง:


