โดย ปูเฉียน เจิ้ง(buqianz) และ หยงคัง ฮวง(yongkan1)
โปสเตอร์
เราใช้ Corgy ซึ่งเป็นเฟรมเวิร์กการเรียนรู้เชิงลึกใน Swift และ Metal Corgy สามารถฝังลงในแอปพลิเคชัน macOS และ iOS และใช้เพื่อสร้างเครือข่ายประสาทเทียมที่ได้รับการฝึกอบรมและประเมินได้อย่างง่ายดาย เราเร่งความเร็วได้มากกว่า 60 เท่าบนอุปกรณ์ต่าง ๆ ที่มี GPU ต่างกัน

เฟรมเวิร์ก Metal 2 เป็นอินเทอร์เฟซที่ Apple มอบให้ซึ่งให้การเข้าถึงหน่วยประมวลผลกราฟิก (GPU) แบบเกือบจะโดยตรงบน iPhone/iPad และ Mac นอกจากกราฟิกแล้ว Metal 2 ยังรวมไลบรารีจำนวนมากที่ให้การสนับสนุนการทำงานแบบขนานที่ยอดเยี่ยมกับการดำเนินการพีชคณิตเชิงเส้นที่จำเป็นและฟังก์ชันการประมวลผลสัญญาณที่สามารถทำงานในอุปกรณ์ Apple ประเภทต่างๆ ไลบรารีเหล่านี้ทำให้เราสามารถสร้างโมเดลการเรียนรู้เชิงลึกที่เร่งด้วย GPU ที่ใช้งานได้ดีบนอุปกรณ์ iOS โดยอิงตามโมเดลที่ได้รับการฝึกซึ่งกำหนดโดยเฟรมเวิร์กอื่นๆ 1
โดยทั่วไปแล้ว ขั้นตอน การอนุมาน ของโครงข่ายประสาทเทียมที่ได้รับการฝึกนั้นมีการประมวลผลที่เข้มข้นมาก โดยเฉพาะอย่างยิ่งสำหรับโมเดลที่มีเลเยอร์จำนวนมากหรือนำไปใช้ในสถานการณ์ที่จำเป็นในการประมวลผลภาพที่มีความละเอียดสูง เป็นที่น่าสังเกตว่ามี การคำนวณเมทริกซ์จำนวนมหาศาล (เช่น เลเยอร์แบบหมุนวน) ซึ่งเหมาะสมที่จะใช้การดำเนินการแบบขนานเพื่อเพิ่มประสิทธิภาพการทำงาน
ความท้าทายแรกที่เราเผชิญคือการออกแบบอินเทอร์เฟซการเขียนโปรแกรมแอปพลิเคชันที่เป็นนามธรรมที่ดีซึ่งแสดงออกและใช้งานง่ายโดยมีช่วงการเรียนรู้ต่ำซึ่งใช้งานง่ายสำหรับผู้ใช้ของเรา
ในระหว่างกระบวนการพัฒนาทั้งหมด เราพยายามอย่างเต็มที่เพื่อให้ API สาธารณะเรียบง่ายที่สุดเท่าที่จะเป็นไปได้ ขณะเดียวกันก็มีคุณสมบัติที่จำเป็นทั้งหมดเพื่อสร้างทุกส่วนประกอบที่ต้องการโดยการใช้ประโยชน์จากกลไกการเขียนโปรแกรมเชิงฟังก์ชันที่ Swift มอบให้ นอกจากนี้เรายังจงใจซ่อนฮาร์ดแวร์ที่ไม่จำเป็นที่ Metal มอบให้เพื่อทำให้เส้นโค้งการเรียนรู้ราบรื่น
แม้ว่าโมเดลที่ผ่านการฝึกอบรมของเครือข่ายต่างๆ นั้นหาได้ง่ายบนอินเทอร์เน็ต แต่ความแตกต่างระหว่างเครือข่ายเหล่านั้นที่เกิดจากการนำไปใช้งานที่แตกต่างกันโดยใช้เครื่องมือประเภทต่างๆ ทำให้เกิดงานสร้างผู้นำเข้าโมเดลสากล
การคำนวณบางอย่างสามารถเข้าใจได้ง่ายจากแนวคิด แต่ต้องใช้การคิดอย่างรอบคอบ เมื่อคุณต้องการสร้างการใช้งานที่มีประสิทธิภาพโดยการสรุปออกมา Convolution เป็นตัวอย่างที่เป็นตัวแทน
คุณสมบัติที่แท้จริงของการดำเนินการ Convolution ไม่มีตำแหน่งที่ดี การใช้งานวานิลลานั้นยากที่จะเข้าใจ และไม่มีประสิทธิผลเมื่อมีความซับซ้อนสำหรับลูป นอกจากนี้ เราต้องพิจารณาสิ่งที่เป็นนามธรรมจาก Metal 2 และสร้างวิธีที่สะดวกในการแบ่งปันข้อมูลและโครงสร้างข้อมูลที่จำเป็นระหว่างโฮสต์และอุปกรณ์ด้วยการพิจารณาการแสดงข้อมูลและเค้าโครงหน่วยความจำอย่างรอบคอบ
ในระหว่างขั้นตอนการพัฒนา เรามีสติสัมปชัญญะเมื่อต้องรับมือกับความสามารถของโค้ดของเราที่ทำงานตามปกติบน macOS และ iOS โดยไม่มีการลดทอนประสิทธิภาพการทำงานบนทั้งสองแพลตฟอร์ม เราพยายามอย่างเต็มที่เพื่อรักษาโค้ดไลบรารี่ที่สามารถคอมไพล์และรันได้ในทั้งสองแพลตฟอร์ม เราระมัดระวังในการเพิ่มโค้ดที่ใช้ร่วมกันระหว่างเป้าหมายที่แตกต่างกันและนำโค้ดกลับมาใช้ใหม่ให้มากที่สุด
เนื่องจากส่วนประกอบที่นำมาใช้อย่างสมบูรณ์ของเลเยอร์โครงข่ายประสาทเทียมควรให้การสนับสนุนด้วยพารามิเตอร์ในปริมาณที่เหมาะสมซึ่งทำให้ส่วนประกอบนั้นใช้งานได้เพียงพอ ความซับซ้อนของส่วนประกอบจึงค่อนข้างน่าประทับใจจริงๆ ตัวอย่างเช่น เลเยอร์ convolutional ควรสนับสนุนพารามิเตอร์ที่รวมเอา padding, dilation stride ฯลฯ และทั้งหมดควรได้รับการพิจารณาอย่างระมัดระวังเมื่อทำการขนานเพื่อให้ได้ประสิทธิภาพที่สมเหตุสมผล เราสร้างเครือข่ายง่ายๆ เพื่อทำการทดสอบการถดถอย กรณีทดสอบจะถูกสร้างขึ้นในเฟรมเวิร์กอื่น (หลักคือ PyTorch และ Keras) เพื่อให้แน่ใจว่าการใช้งานทั้งหมดทำงานได้อย่างถูกต้อง
Swift ได้รับการพัฒนาครั้งแรกในเดือนกรกฎาคม 2010 และเผยแพร่และโอเพ่นซอร์สในปี 2014 แม้ว่าจะผ่านมาเกือบ 4 ปีแล้วนับตั้งแต่เผยแพร่ แต่การขาดไลบรารีที่มีประสิทธิภาพก็ยังคงเป็นปัญหาที่ไม่อาจมองข้ามได้ สาเหตุบางประการทำให้เกิดสถานการณ์เช่นนี้ บทบาทที่โดดเด่นของ Apple และการทำซ้ำอย่างรวดเร็วของ Swift อาจเป็นสาเหตุของปรากฏการณ์นี้ ห้องสมุดบางแห่งที่สำคัญสำหรับเราอาจไม่มีประสิทธิภาพหรือใช้งานได้เพียงพอกับความต้องการของเรา หรือไม่ได้รับการดูแลอย่างดีจากนักพัฒนาแต่ละรายที่คิดค้นไลบรารีเหล่านั้น เราใช้เวลาค่อนข้างมากในการปรับใช้ Variable เทนเซอร์คลาสที่มีฟังก์ชันดีเพื่อตอบสนองความต้องการของเรา
นอกจากนี้ นี่เป็นอีกเหตุผลหนึ่งที่ขัดขวางการพัฒนาตัวแยกวิเคราะห์โมเดลสากลที่ฟังก์ชันการจัดการไฟล์และสตริงมีความสามารถที่จำกัดมาก
นอกจากนี้ เครื่องมือการพัฒนาและแก้ไขจุดบกพร่องโดยพื้นฐานแล้วจำกัดอยู่ที่ Xcode แม้ว่าจะมีตัวเลือกอื่นๆ ที่เป็นเรื่องทั่วไปสำหรับเรา แต่ Xcode ยังคงเป็นเครื่องมือมาตรฐานสำหรับการพัฒนาของเรา
สำหรับการปรับแต่งประสิทธิภาพของอุปกรณ์เคลื่อนที่ Apple ไม่ได้ให้รายละเอียดข้อกำหนดฮาร์ดแวร์สำหรับ SoC สื่อใช้ชื่อทางการตลาดกันอย่างแพร่หลาย และเป็นการยากที่จะอนุมานว่าคุณลักษณะฮาร์ดแวร์เฉพาะเจาะจงมีผลกระทบที่แน่นอนอย่างไร และปรับแต่งประสิทธิภาพของการใช้งานอย่างละเอียด .
เรากำลังใช้ภาษาการเขียนโปรแกรม Swift โดยเฉพาะ Swift 4.2 ซึ่งเป็นรุ่นล่าสุด เฟรมเวิร์ก Metal 2 และฟังก์ชันไลบรารีบางส่วนที่จัดทำโดย Metal Performance Shader (ฟังก์ชันพีชคณิตเชิงเส้นพื้นฐาน) แม้ว่า Apple จะเปิดตัว CoreML SDK ในฤดูใบไม้ผลิปี 2017 ซึ่งรวมการสนับสนุนเครือข่ายประสาทเทียมแบบหมุนวนไว้ด้วย แต่เราไม่ได้ใช้พวกมันใน Corgy เพื่อรับประสบการณ์อันล้ำค่าในการพัฒนาการใช้งานเลเยอร์เครือข่ายแบบขนาน และมอบ API ที่กระชับและใช้งานง่ายพร้อมการใช้งานที่ดีและเส้นโค้งการเรียนรู้ที่ราบรื่น เพื่อให้ผู้ใช้สามารถย้ายโมเดลจากเฟรมเวิร์กอื่นได้อย่างง่ายดาย
เครื่องเป้าหมายของเราคืออุปกรณ์ทั้งหมดที่ใช้ macOS และ iOS เช่น iMac, MacBook, iPhone และ iPad โดยเฉพาะอุปกรณ์ที่มีแพลตฟอร์มที่รองรับไลบรารีพีชคณิตเชิงเส้น MPS (เช่น หลัง iOS 10.0 และ macOS 10.13) ซึ่งหมายความว่า iPhone เปิดตัวหลัง iPhone 5, iPad เปิดตัวหลัง iPad (รุ่นที่ 4) และ iPod Touch (รุ่นที่ 6) ได้รับการรองรับเป็นแพลตฟอร์ม iOS กลุ่มผลิตภัณฑ์ Mac ได้รับการครอบคลุมมากขึ้น รวมถึง iMac ที่ผลิตหลังปลายปี 2009 หรือใหม่กว่า, MacBook Series ทั้งหมดที่เปิดตัวหลังกลางปี 2010 และ iMac Pro
นามธรรมแบบขนานของ Metal 2 นั้นเหมือนกันมาก CUDA: เมื่อส่งคอมพิวเตอร์ผ่านไปยัง GPU โปรแกรมเมอร์จะเขียนฟังก์ชันเคอร์เนลที่จะดำเนินการโดยแต่ละเธรดก่อน จากนั้นระบุจำนวนกลุ่มเธรด (aka. block ใน CUDA) ในตารางและ จำนวนเธรดในแต่ละกลุ่มเธรด Metal จะดำเนินการเคอร์เนลบนกริดนี้ เคอร์เนลถูกนำไปใช้ในภาษาถิ่น C++14 ชื่อภาษาการแรเงาโลหะ ภายในกลุ่มเธรดแต่ละกลุ่ม จะมีหน่วยเล็กๆ ที่เรียกว่ากลุ่ม SIMD ซึ่งหมายถึงกลุ่มเธรดที่ใช้คำสั่ง SIMD เดียวกัน แต่ภายใต้การดำเนินการของเรา ไม่จำเป็นต้องพิจารณาเรื่องนี้
Metal จัดเตรียม API ชื่อ MTLCommandBuffer ซึ่งจัดเก็บคำสั่งที่เข้ารหัสที่คอมมิตและดำเนินการโดย GPU แต่ละครั้งที่เราต้องการเริ่มงานที่ GPU จะดำเนินการ ฟังก์ชันเคอร์เนลที่คอมไพล์แล้วจะถูกเข้ารหัสเป็นคำสั่งของ GPU ซึ่งฝังอยู่ในไปป์ไลน์การแรเงา Metal และถูกส่งไปยัง MTLCommandBuffer บัฟเฟอร์โลหะที่ใช้ในการจัดเก็บพารามิเตอร์การคำนวณที่ต้องส่งผ่านไปยังอุปกรณ์จะได้รับการตั้งค่าในขั้นตอนนี้ด้วย จากนั้น ด้วยจำนวนกลุ่มเธรดและเธรดต่อกลุ่มที่ระบุ คำสั่งที่จัดการโดยบัฟเฟอร์คำสั่งจะถูกเข้ารหัสอย่างสมบูรณ์ และทั้งหมดจะถูกตั้งค่าให้ส่งไปยังอุปกรณ์ GPU จะกำหนดเวลางานและแจ้งเตือนเธรด CPU ที่ส่งงานหลังจากการดำเนินการเสร็จสิ้น
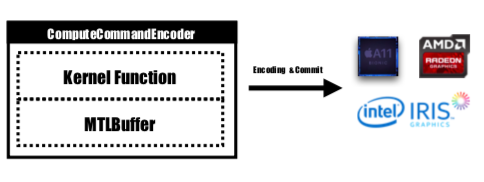
ฟังก์ชันเคอร์เนลจะถูกเข้ารหัสโดย MTLComputeCommandEncoder และงานจะถูกสร้างขึ้นสำหรับแพลตฟอร์มที่รองรับทั้งหมด
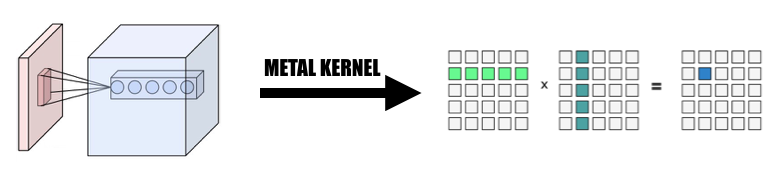
ในการนำไปใช้งานของเรา เราใช้วิธีที่ใช้งานง่ายอย่างกว้างขวางในการแมปองค์ประกอบเข้ากับเธรด GPU: แมปแต่ละองค์ประกอบในเทนเซอร์เอาต์พุตของเลเยอร์ปัจจุบันกับเธรด GPU หนึ่งเธรด: แต่ละเธรดคำนวณและอัปเดตองค์ประกอบเดียวของเอาต์พุตอย่างแน่นอน และอินพุตจะเป็น อ่านอย่างเดียว ดังนั้นเราจึงไม่จำเป็นต้องกังวลเกี่ยวกับการซิงโครไนซ์ระหว่างเธรด ภายใต้การแมปนี้ เธรดที่มี id ต่อเนื่องอาจอ่านข้อมูลอินพุตจากตำแหน่งหน่วยความจำที่แตกต่างกัน แต่จะเขียนไปยังตำแหน่งหน่วยความจำต่อเนื่องเสมอ ดังนั้นจะไม่มีการดำเนินการกระจายเมื่อกลุ่ม SIMD เขียนลงในหน่วยความจำ
เราออกแบบ Variable คลาสเทนเซอร์ให้เป็นรากฐานของการนำไปใช้งานทั้งหมด เราใช้และห่อหุ้มการดำเนินการพีชคณิตเชิงเส้นไว้ในคลาส Variable แทนที่จะเขียนเคอร์เนลเพิ่มเติมเพื่อเจาะลึกในการดำเนินการที่ไม่ใช่จุดสนใจหลักของเราเพื่อลดความซับซ้อนของการนำไปใช้งาน และประหยัดเวลาของเราในการมุ่งเน้นไปที่การเร่งเลเยอร์เครือข่าย
1. เปลี่ยนการบิดเป็นการคูณเมทริกซ์ขนาดยักษ์
เรารวบรวมข้อมูลจากอินพุตในลักษณะขนานเพื่อสร้างเมทริกซ์ขนาดยักษ์ของทั้งตัวแปรอินพุตและน้ำหนัก เราแคชน้ำหนักของแต่ละเลเยอร์การบิดเบี้ยวเพื่อหลีกเลี่ยงการคำนวณใหม่ การเสริมของเลเยอร์ Convolutional จะถูกสร้างขึ้นระหว่างการแปลงแบบขนานในระหว่างการคำนวณ จากนั้นเราจะเรียกใช้ MPSMatrixMultiply ไปยังเมทริกซ์ขนาดยักษ์ และแปลงข้อมูลจากเมทริกซ์ขนาดยักษ์กลับเป็นคลาสเทนเซอร์ปกติที่เราสร้างขึ้น วิธีการอธิบายไว้ในสไลด์ของชั้นเรียน
2. การออกแบบและการใช้งานคลาสตัวแปร
คลาสตัวแปรเป็นรากฐานของการดำเนินการของเราในฐานะตัวแทนเทนเซอร์ เราห่อหุ้ม MPSMatrixMultiplication สำหรับตัวแปร (กำหนดเครื่องหมายคูณ Unicode (×) เป็นตัวดำเนินการมัดเพื่อนำเสนออย่างหรูหรา :-))
โครงสร้างข้อมูลพื้นฐานของตัวแปรคือ UnsafemutableBufferPointer ที่ชี้ไปยังประเภทข้อมูล เราเลือก Float 32 บิตเพื่อความเรียบง่าย คลาส Variable รักษาขนาดข้อมูลไว้สองขนาด count เป็นหมายเลของค์ประกอบที่เก็บไว้จริง actualCount คือขนาดขององค์ประกอบทั้งหมดที่ปัดเศษขึ้นเป็นขนาดหน้าของแพลตฟอร์มที่ได้รับโดยใช้ getpagesize()
เรารักษาค่าทั้งสองนี้ไว้เพื่อให้แน่ใจว่า makeBuffer(bytesNoCopy:) เพื่อสร้างบัฟเฟอร์โดยตรงบนขอบเขต VM ที่ระบุ และหลีกเลี่ยงการจัดสรรใหม่ซ้ำซ้อนซึ่งจะช่วยลดค่าใช้จ่าย หากหน่วยความจำที่จะส่งผ่านไปยัง Metal ไม่ได้จัดแนวหน้า Metal จะไม่สามารถใช้หน่วยความจำนี้เป็นบัฟเฟอร์อินพุตหรือเอาท์พุตได้ เราจะต้องใช้เมธอด makeBuffer(bytes:) ซึ่งจะสร้างบัฟเฟอร์ใหม่และคัดลอกข้อมูลจากตำแหน่งหน่วยความจำอินพุต ดังนั้นเราจึงจำเป็นต้องจัดสรรหน่วยความจำมากกว่าที่จำเป็นเสมอเพื่อให้แน่ใจว่าความทรงจำทั้งหมดใน Variable นั้นอยู่ในแนวเดียวกัน ดังนั้นเราจึงต้องการสองค่าเพื่อติดตามว่าหน่วยความจำก้อนนี้มีขนาดใหญ่เพียงใด และเราควรใช้ค่าขนาดใหญ่เพียงใด
3. จำนวนองค์ประกอบที่ประมวลผลโดยเธรดเดียว
เราพยายามแมปหนึ่งเธรดกับองค์ประกอบหลายรายการ ตั้งแต่ 2 ถึง 16 องค์ประกอบต่อเธรด ประสิทธิภาพเกือบจะเท่ากัน แต่มีการเพิ่มความซับซ้อนอย่างมากให้กับโปรเจ็กต์ของเรา ดังนั้นเราจึงละทิ้งแนวทางนี้
CPU เวอร์ชันทั้งหมดที่กล่าวถึงด้านล่างนี้เป็นโค้ด CPU แบบเธรดเดี่ยวที่ไร้เดียงสา โดยไม่มีการเพิ่มประสิทธิภาพ SIMD การเพิ่มประสิทธิภาพคอมไพเลอร์ในระดับ -Ofast ถูกนำไปใช้
ประสิทธิภาพการดำเนินงานของเราดีไม่ดีพอ
เราใช้ iPhone 6s และ MacBook Pro รุ่น 15 นิ้วเป็นแพลตฟอร์มการวัดประสิทธิภาพ ฮาร์ดแวร์มีการระบุด้านล่าง:
MacBook Pro (Retina 15 นิ้ว กลางปี 2015)
ไอโฟน 6เอส
เมื่อเปรียบเทียบกับการใช้งาน CPU เวอร์ชันไร้เดียงสาโดยไม่มีการทำงานแบบขนาน เวอร์ชัน GPU ของเรา เร็วกว่ามากกว่า 60 เท่า
เนื่องจากโมเดล MNIST มีขนาดเล็กเกินไป ผลลัพธ์จึงอาจไม่สะท้อนถึงการเร่งความเร็วที่แม่นยำ และเราไม่มีเวอร์ชันเธรดเดียวที่ใช้งานได้ดี เราไม่สามารถให้หมายเลขการเร่งความเร็วที่แม่นยำได้ เนื่องจากเวอร์ชัน CPU ช้าเกินไป การเร่งความเร็วของ Tiny YOLO จึงใหญ่เกินกว่าจะเชื่อได้
แอตทริบิวต์เครือข่ายการทดสอบ:
มินนิสต์:
โยโล:
ผลการวัด:
| ไอโฟน 6s | มินนิสต์ | โยโล ตัวเล็ก |
|---|---|---|
| ซีพียู | 1500ms | 753ส |
| จีพียู | 0.025 วินาที | 0.5 วินาที |
| เร่งความเร็ว | ~60x | ~1500x |
| แมคบุ๊คโปร | มินนิสต์ | โยโล ตัวเล็ก |
|---|---|---|
| ซีพียู | 650ms | 729 |
| จีพียู | 10ms | 0.028 วินาที |
| เร่งความเร็ว | ~65x | ~26000x |
จากเกณฑ์มาตรฐานข้างต้น เราจะเห็นได้ว่าเมื่อขนาดของปัญหาเพิ่มขึ้น
ทำไมเราถึงบอกว่าการเร่งความเร็วของเราไม่ดีพอ? เนื่องจากเมื่อเปรียบเทียบกับการใช้งาน MPSCNNConvolution อย่างเป็นทางการของ Apple เรามีความเร็วเพียงประมาณหนึ่งในสามเท่านั้น ซึ่งหมายความว่ายังมีพื้นที่เพิ่มประสิทธิภาพอีกมาก การเปรียบเทียบนี้อิงตามการใช้งาน YOLO แบบโอเพ่นซอร์สบน iPhone โดยใช้ MPSCNNConvolution อย่างเป็นทางการ ซึ่งสามารถจดจำ ~5 ภาพต่อวินาที ในขณะที่การใช้งานของเราสามารถทำได้เพียง ~2 ภาพต่อวินาที
และเนื่องจากระยะเวลาที่จำกัด เราไม่สามารถสร้างเวอร์ชันพื้นฐานที่ดีขึ้นและเวอร์ชันขนานของ CPU เพื่อทำการวัดประสิทธิภาพได้ ซึ่งทำให้ตัวเลขความเร็วเพิ่มขึ้นมากเกินไป
นอกจากนี้ ยังควรรายงานประสิทธิภาพที่เพิ่มขึ้นตามขนาดปัญหาที่แตกต่างกันด้วย ดังที่เราเห็น MNIST มีน้ำหนักเพียง 0.1 ล้านน้ำหนัก ในขณะที่ Tiny YOLO มีน้ำหนัก 17 ล้าน Tiny YOLO นั้นซับซ้อนกว่า MNIST มาก แต่เวลาทำงานของเวอร์ชัน GPU ไม่ได้ปรับขนาดมากนัก นั่นเป็นอีกครั้งเพราะกฎของอัมดาห์ล แต่ละงาน GPU จะถูกเปิดใช้งาน คำสั่ง GPU ที่เกี่ยวข้องจะต้องได้รับการเข้ารหัสลงในบัฟเฟอร์คำสั่ง กระบวนการนี้เป็นแบบอนุกรมโดยเนื้อแท้ เมื่อขนาดของปัญหามีขนาดเล็ก กระบวนการนี้มีส่วนช่วยอย่างมากต่อเวลาการทำงานทั้งหมด ดังนั้นการขนานขั้นตอนการอนุมานโครงข่ายประสาทเทียมใน MINST อาจไม่ได้รับความเร็วเพิ่มขึ้นเท่ากับใน Tiny YOLO ซึ่งค่าใช้จ่ายด้านเวลาในการทำงานนั้นสามารถละเลยได้
อะไรจำกัดความเร็วของคุณ?
if s และ for s ซึ่งอาจทำให้เกิดความแตกต่าง ส่งผลให้การใช้งาน SIMD ไม่ดีการวิเคราะห์เชิงลึก: แจกแจงเวลาดำเนินการของระยะต่างๆ
ยกตัวอย่าง Tiny YOLO ในการรันตัวอย่างโดยใช้เวลาทำงานทั้งหมด 227ms บน Macbook เลเยอร์แบบ Convolutional ใช้เวลา 207ms หรือ 92% ของเวลาทำงานทั้งหมด เลเยอร์ Pooling ใช้ 14ms (6%) และ ReLU ใช้ 6ms (2%) ตามกฎของอัมดาห์ล หากเราต้องการปรับปรุงประสิทธิภาพให้ดียิ่งขึ้น เราควรดำเนินการในระดับ Convolutional ต่อไปอย่างแน่นอน
โดยรวมแล้ว เราเชื่อว่าตัวเลือก Metal Framework ของเราในการเร่งความเร็ว Neural Network บนอุปกรณ์ iOS และ macOS นั้นฟังดูดี โดยเฉพาะสำหรับอุปกรณ์ iOS เนื่องจากมีคอร์น้อยกว่า แม้ว่าจะมีคำสั่ง SIMD ก็ตาม เวอร์ชัน CPU ที่ได้รับการปรับแต่งอย่างดีจึงมีโอกาสน้อยที่จะได้รับประสิทธิภาพที่ใกล้เคียงกับเวอร์ชัน GPU
สมาชิกในทีมทั้งสองทำงานอย่างเท่าเทียมกัน
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


