Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ได้ไหม?Browser หัวขาดการขูดเว็บเว็บไซต์ส่วนใหญ่อาจจะค่อนข้างง่าย หัวข้อนี้มีเนื้อหาครอบคลุมอยู่แล้วในบทช่วยสอนนี้ อย่างไรก็ตาม มีหลายไซต์ที่ไม่สามารถคัดลอกด้วยวิธีเดียวกันได้ เหตุผลก็คือไซต์เหล่านี้โหลดเนื้อหาแบบไดนามิกโดยใช้ JavaScript
เทคนิคนี้เรียกอีกอย่างว่า AJAX (Asynchronous JavaScript และ XML) ในอดีต มาตรฐานนี้รวมไว้ด้วยการสร้างออบเจ็กต์ XMLHttpRequest เพื่อดึง XML จากเว็บเซิร์ฟเวอร์โดยไม่ต้องโหลดทั้งหน้าซ้ำ ปัจจุบันวัตถุนี้ไม่ค่อยได้ใช้โดยตรง โดยปกติแล้ว wrapper เช่น jQuery ใช้เพื่อดึงเนื้อหาเช่น JSON, HTML บางส่วน หรือแม้แต่รูปภาพ
หากต้องการคัดลอกหน้าเว็บปกติ จำเป็นต้องมีไลบรารีอย่างน้อยสองไลบรารี ไลบรารี requests ดาวน์โหลดหน้า เมื่อหน้านี้พร้อมใช้งานเป็นสตริง HTML ขั้นตอนต่อไปคือการแยกวิเคราะห์เป็นออบเจ็กต์ BeautifulSoup ออบเจ็กต์ BeautifulSoup นี้สามารถใช้เพื่อค้นหาข้อมูลเฉพาะได้
นี่คือตัวอย่างสคริปต์ง่ายๆ ที่พิมพ์ข้อความภายในองค์ประกอบ h1 โดยมี id ตั้งค่าเป็น firstHeading
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert Einsteinโปรดทราบว่าเรากำลังทำงานร่วมกับไลบรารี Beautiful Soup เวอร์ชัน 4 เวอร์ชันก่อนหน้านี้ถูกยกเลิก คุณอาจเห็นว่า Beautiful Soup 4 เขียนว่า Beautiful Soup, BeautifulSoup หรือแม้แต่ bs4 พวกเขาทั้งหมดอ้างถึงห้องสมุดซุป 4 ที่สวยงามเหมือนกัน
รหัสเดียวกันจะไม่ทำงานหากไซต์เป็นแบบไดนามิก ตัวอย่างเช่น ไซต์เดียวกันมีเวอร์ชันไดนามิกที่ https://quotes.toscrape.com/js/ (หมายเหตุ js ที่ส่วนท้ายของ URL นี้)
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output เหตุผลก็คือไซต์ที่สองเป็นแบบไดนามิกซึ่งมีการสร้างข้อมูลโดยใช้ JavaScript
มีสองวิธีในการจัดการไซต์เช่นนี้
แนวทางทั้งสองนี้มีเนื้อหาครอบคลุมอยู่ในบทช่วยสอนนี้
อย่างไรก็ตาม อันดับแรก เราต้องเข้าใจวิธีพิจารณาว่าไซต์นั้นเป็นแบบไดนามิกหรือไม่
นี่เป็นวิธีที่ง่ายที่สุดในการพิจารณาว่าเว็บไซต์เป็นแบบไดนามิกโดยใช้ Chrome หรือ Edge (เบราว์เซอร์ทั้งสองนี้ใช้ Chromium ภายใต้ประทุน)
เปิดเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์โดยกดปุ่ม F12 ตรวจสอบให้แน่ใจว่าโฟกัสอยู่ที่เครื่องมือสำหรับนักพัฒนาซอฟต์แวร์แล้วกดคีย์ผสม CTRL+SHIFT+P เพื่อเปิดเมนูคำสั่ง
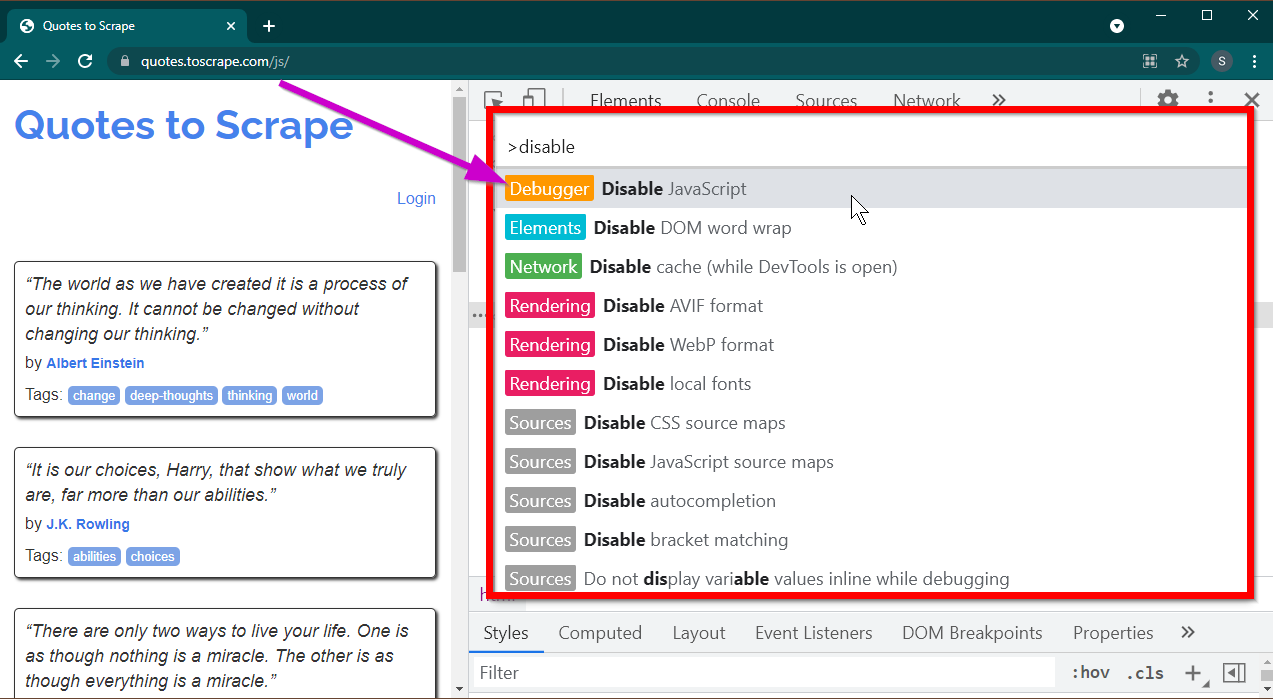
จะแสดงคำสั่งต่างๆ มากมาย เริ่มพิมพ์ disable และคำสั่งจะถูกกรองเพื่อแสดง Disable JavaScript เลือกตัวเลือกนี้เพื่อปิดการใช้งาน JavaScript
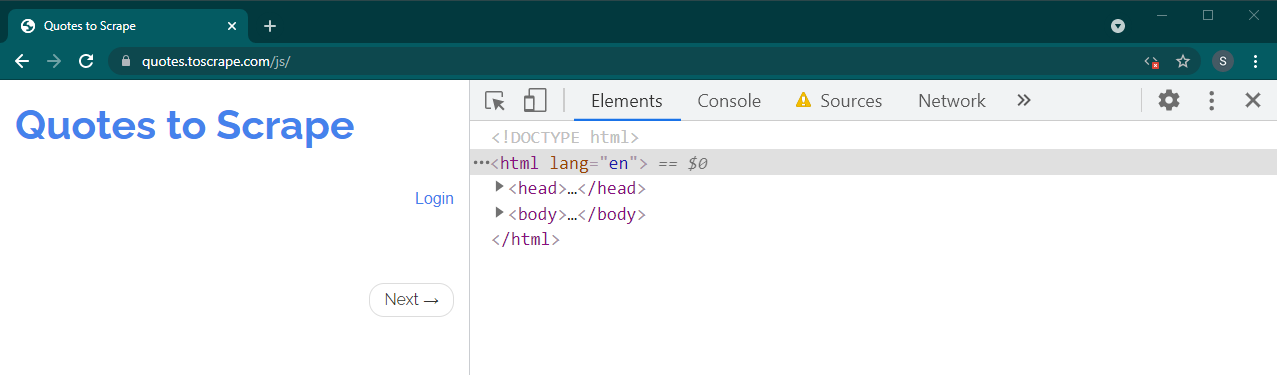
ตอนนี้โหลดหน้านี้ใหม่โดยกด Ctrl+R หรือ F5 เพจจะโหลดซ้ำ
หากนี่คือไซต์แบบไดนามิก เนื้อหาจำนวนมากจะหายไป:
ในบางกรณี ไซต์จะยังคงแสดงข้อมูล แต่จะกลับไปใช้ฟังก์ชันพื้นฐาน ตัวอย่างเช่น ไซต์นี้มีการเลื่อนที่ไม่มีที่สิ้นสุด หากปิดการใช้งาน JavaScript มันจะแสดงการแบ่งหน้าปกติ
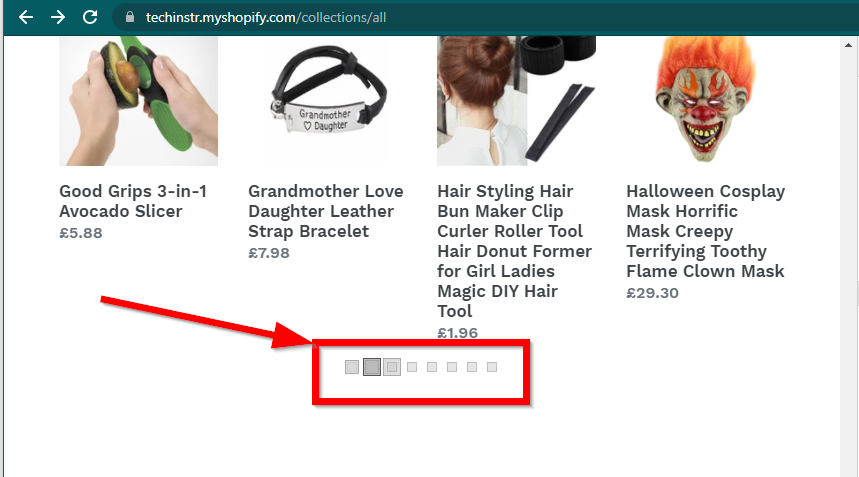 | 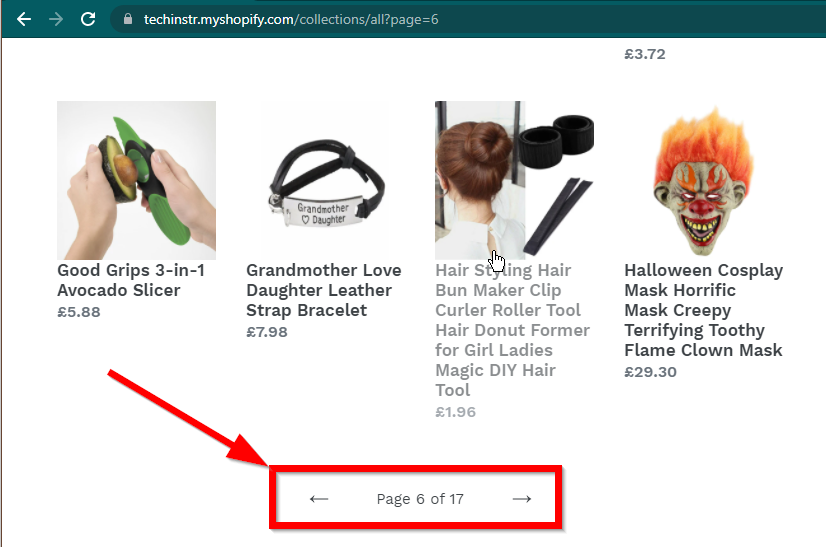 |
|---|---|
| เปิดใช้งานจาวาสคริปต์แล้ว | ปิดการใช้งานจาวาสคริปต์ |
คำถามต่อไปที่ต้องตอบคือความสามารถของ BeautifulSoup
JavaScript ได้ไหม?คำตอบสั้น ๆ คือไม่
สิ่งสำคัญคือต้องเข้าใจคำศัพท์ต่างๆ เช่น การแยกวิเคราะห์และการแสดงผล การแยกวิเคราะห์เป็นเพียงการแปลงการแสดงสตริงของวัตถุ Python ให้เป็นวัตถุจริง
แล้วการเรนเดอร์คืออะไร? การเรนเดอร์คือการตีความ HTML, JavaScript, CSS และรูปภาพให้เป็นสิ่งที่เราเห็นในเบราว์เซอร์
Beautiful Soup เป็นไลบรารี Python สำหรับดึงข้อมูลออกจากไฟล์ HTML สิ่งนี้เกี่ยวข้องกับการแยกวิเคราะห์สตริง HTML ลงในวัตถุ BeautifulSoup สำหรับการแยกวิเคราะห์ ขั้นแรกเราจำเป็นต้องมี HTML เป็นสตริงเพื่อเริ่มต้น เว็บไซต์ไดนามิกไม่มีข้อมูลในรูปแบบ HTML โดยตรง หมายความว่า BeautifulSoup ไม่สามารถทำงานกับเว็บไซต์ไดนามิกได้
ไลบรารี Selenium สามารถโหลดและเรนเดอร์เว็บไซต์ในเบราว์เซอร์เช่น Chrome หรือ Firefox ได้โดยอัตโนมัติ แม้ว่า Selenium จะรองรับการดึงข้อมูลออกจาก HTML แต่ก็เป็นไปได้ที่จะแยก HTML ที่สมบูรณ์และใช้ Beautiful Soup แทนเพื่อแยกข้อมูล
มาเริ่มต้นการขูดเว็บแบบไดนามิกด้วย Python โดยใช้ Selenium ก่อน
การติดตั้ง Selenium เกี่ยวข้องกับการติดตั้งสามสิ่ง:
เบราว์เซอร์ที่คุณเลือก (ซึ่งคุณมีอยู่แล้ว):
ไดรเวอร์สำหรับเบราว์เซอร์ของคุณ:
แพ็คเกจ Python Selenium:
pip install seleniumconda-forge conda install -c conda-forge selenium โครงสร้างพื้นฐานของสคริปต์ Python ในการเปิดใช้เบราว์เซอร์ โหลดเพจ จากนั้นปิดเบราว์เซอร์นั้นง่ายดาย:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()ตอนนี้เราสามารถโหลดเพจในเบราว์เซอร์ได้แล้ว มาดูการแยกองค์ประกอบเฉพาะกัน มีสองวิธีในการแยกองค์ประกอบ ได้แก่ ซีลีเนียมและซุปสวย
วัตถุประสงค์ของเราในตัวอย่างนี้คือการค้นหาองค์ประกอบผู้เขียน
โหลดไซต์ https://quotes.toscrape.com/js/ ใน Chrome คลิกขวาที่ชื่อผู้เขียน แล้วคลิก Inspect สิ่งนี้ควรโหลดเครื่องมือสำหรับนักพัฒนาโดยมีองค์ประกอบผู้เขียนที่ไฮไลต์ดังนี้:
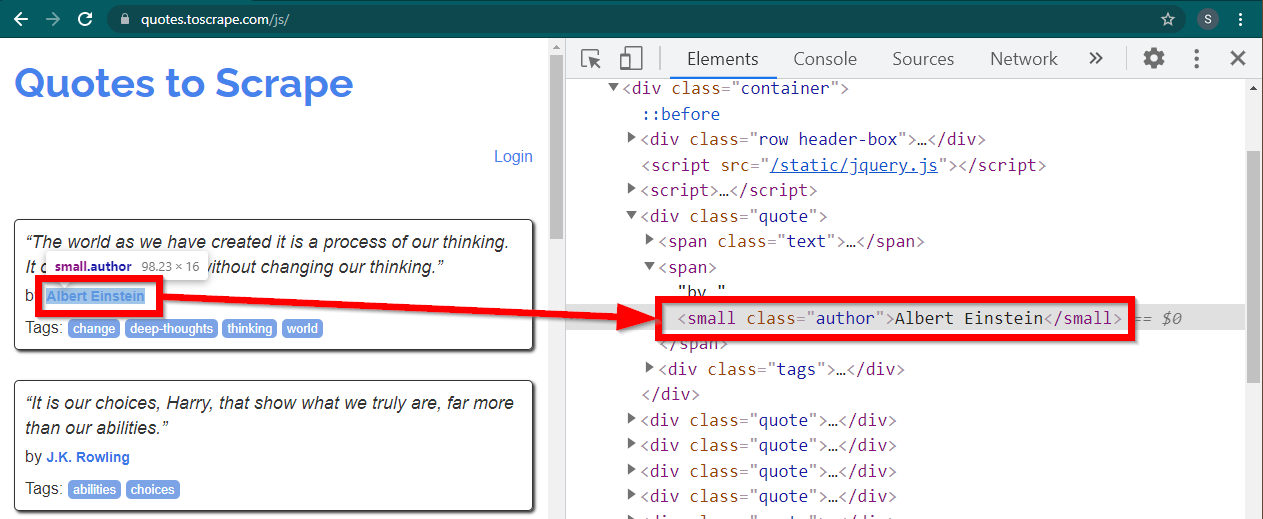
นี่เป็นองค์ประกอบ small ที่มีแอตทริบิวต์ class ตั้งค่าเป็น author
< small class =" author " > Albert Einstein </ small >ซีลีเนียมอนุญาตให้มีวิธีการต่างๆ ในการค้นหาองค์ประกอบ HTML วิธีการเหล่านี้เป็นส่วนหนึ่งของวัตถุโปรแกรมควบคุม วิธีการบางอย่างที่อาจเป็นประโยชน์มีดังนี้:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )มีวิธีอื่นอีกสองสามวิธี ซึ่งอาจเป็นประโยชน์สำหรับสถานการณ์อื่น วิธีการเหล่านี้มีดังนี้:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) บางทีวิธีการที่มีประโยชน์ที่สุดอาจเป็น find_element(By.CSS_SELECTOR) และ find_element(By.XPATH) วิธีใดวิธีหนึ่งในสองวิธีนี้ควรสามารถเลือกสถานการณ์ส่วนใหญ่ได้
มาแก้ไขโค้ดเพื่อให้สามารถพิมพ์ผู้เขียนคนแรกได้
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()จะทำอย่างไรถ้าคุณต้องการพิมพ์ผู้แต่งทั้งหมด?
เมธอด find_element ทั้งหมดมีคู่กัน - find_elements สังเกตพหูพจน์ หากต้องการค้นหาผู้เขียนทั้งหมด เพียงเปลี่ยนหนึ่งบรรทัด:
elements = driver . find_elements ( By . CLASS_NAME , "author" )สิ่งนี้จะส่งคืนรายการองค์ประกอบ เราสามารถรันลูปเพื่อพิมพ์ผู้เขียนทั้งหมดได้:
for element in elements :
print ( element . text )หมายเหตุ: รหัสที่สมบูรณ์อยู่ในไฟล์รหัส selenium_example.py
อย่างไรก็ตาม หากคุณคุ้นเคยกับ BeautifulSoup อยู่แล้ว คุณสามารถสร้างวัตถุ Beautiful Soup ได้
ดังที่เราเห็นในตัวอย่างแรก ออบเจ็กต์ Beautiful Soup ต้องการ HTML สำหรับการขูดไซต์แบบคงที่ของเว็บ สามารถดึงข้อมูล HTML ได้โดยใช้ไลบรารี requests ขั้นตอนต่อไปคือการแยกวิเคราะห์สตริง HTML นี้ลงในวัตถุ BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )มาดูวิธีขูดเว็บไซต์ไดนามิกด้วย BeautifulSoup กันดีกว่า
ส่วนต่อไปนี้ยังคงไม่เปลี่ยนแปลงจากตัวอย่างก่อนหน้านี้
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) HTML ที่แสดงผลของเพจมีอยู่ในแอ็ตทริบิวต์ page_source
soup = BeautifulSoup ( driver . page_source , "lxml" )เมื่อวัตถุซุปพร้อมแล้ว วิธี Beautiful Soup ทั้งหมดก็สามารถใช้ได้ตามปกติ
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )หมายเหตุ: ซอร์สโค้ดที่สมบูรณ์อยู่ใน selenium_bs4.py
Browser หัวขาดเมื่อสคริปต์พร้อมแล้ว ก็ไม่จำเป็นต้องแสดงเบราว์เซอร์เมื่อสคริปต์กำลังทำงาน สามารถซ่อนเบราว์เซอร์ได้ และสคริปต์จะยังคงทำงานได้ดี ลักษณะการทำงานของเบราว์เซอร์นี้เรียกอีกอย่างว่าเบราว์เซอร์ที่ไม่มีส่วนหัว
หากต้องการทำให้เบราว์เซอร์ไม่มีหัว ให้นำเข้า ChromeOptions สำหรับเบราว์เซอร์อื่นๆ จะมีคลาสตัวเลือกของตัวเองให้เลือกใช้
from selenium . webdriver import ChromeOptions ตอนนี้ สร้างวัตถุของคลาสนี้ และตั้งค่าแอตทริบิวต์ headless เป็น True
options = ChromeOptions ()
options . headless = Trueสุดท้าย ให้ส่งออบเจ็กต์นี้ขณะสร้างอินสแตนซ์ Chrome
driver = Chrome ( ChromeDriverManager (). install (), options = options )ตอนนี้เมื่อคุณเรียกใช้สคริปต์ เบราว์เซอร์จะไม่สามารถมองเห็นได้ ดูไฟล์ selenium_bs4_headless.py สำหรับการใช้งานที่สมบูรณ์
การโหลดเบราว์เซอร์มีราคาแพง เนื่องจากต้องใช้ CPU, RAM และแบนด์วิธซึ่งไม่จำเป็นจริงๆ เมื่อเว็บไซต์ถูกคัดลอก ข้อมูลนั้นมีความสำคัญ CSS รูปภาพ และการเรนเดอร์ทั้งหมดนั้นไม่จำเป็นจริงๆ
วิธีที่เร็วและมีประสิทธิภาพมากที่สุดในการคัดลอกหน้าเว็บแบบไดนามิกด้วย Python คือการค้นหาตำแหน่งจริงที่มีข้อมูลอยู่
มีสองที่ที่สามารถระบุข้อมูลนี้ได้:
<script>ลองดูตัวอย่างบางส่วน
เปิด https://quotes.toscrape.com/js ใน Chrome เมื่อโหลดเพจแล้ว ให้กด Ctrl+U เพื่อดูแหล่งที่มา กด Ctrl+F เพื่อเปิดช่องค้นหา ค้นหา Albert
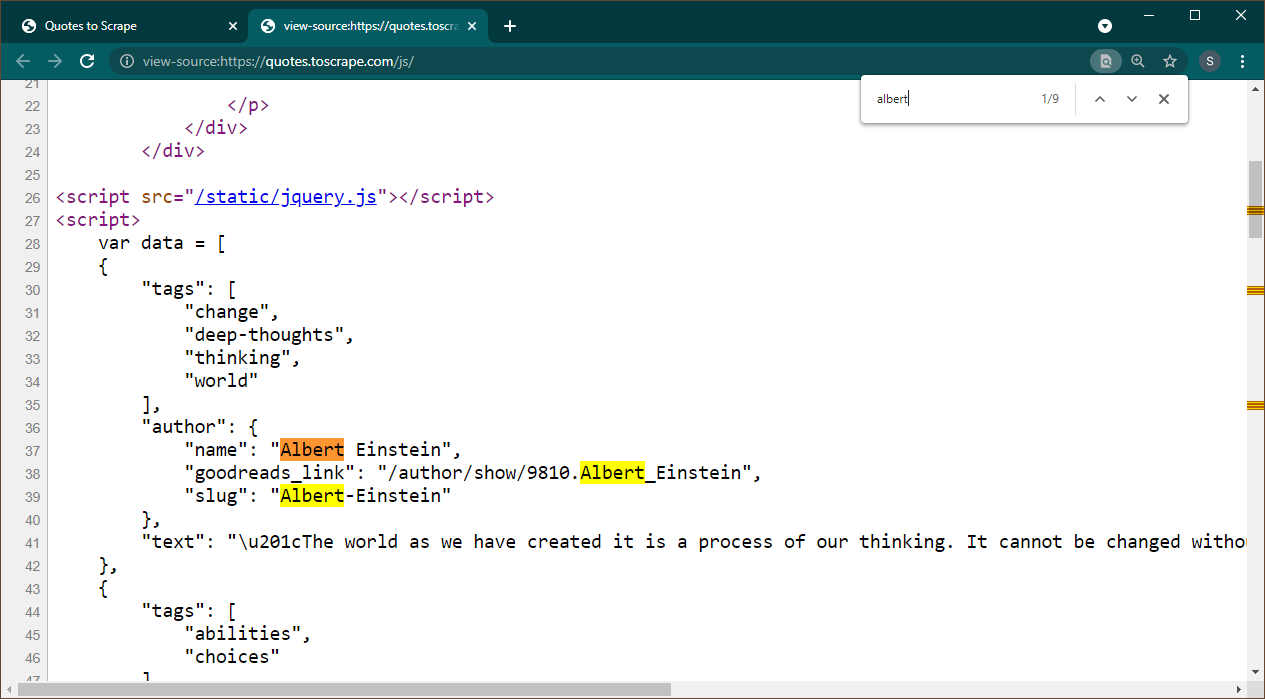
เราจะเห็นได้ทันทีว่าข้อมูลถูกฝังเป็นออบเจ็กต์ JSON บนเพจ นอกจากนี้ โปรดทราบว่านี่เป็นส่วนหนึ่งของสคริปต์ที่ข้อมูลนี้ถูกกำหนดให้กับ data ตัวแปร
ในกรณีนี้ เราสามารถใช้ไลบรารี Requests เพื่อรับเพจและใช้ Beautiful Soup เพื่อแยกวิเคราะห์เพจและรับองค์ประกอบสคริปต์
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) โปรดทราบว่ามีองค์ประกอบ <script> หลายรายการ อันที่มีข้อมูลที่เราต้องการไม่มีแอตทริบิวต์ src ลองใช้สิ่งนี้เพื่อแยกองค์ประกอบสคริปต์
script_tag = soup . find ( "script" , src = None )โปรดจำไว้ว่าสคริปต์นี้มีโค้ด JavaScript อื่นนอกเหนือจากข้อมูลที่เราสนใจ ด้วยเหตุนี้ เราจะใช้นิพจน์ทั่วไปเพื่อดึงข้อมูลนี้
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )ตัวแปรข้อมูลคือรายการที่มีหนึ่งรายการ ตอนนี้เราสามารถใช้ไลบรารี JSON เพื่อแปลงข้อมูลสตริงนี้เป็นวัตถุหลามได้
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )ผลลัพธ์จะเป็นวัตถุหลาม:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................รายการนี้ไม่สามารถแปลงเป็นรูปแบบใดๆ ได้ตามต้องการ นอกจากนี้ โปรดทราบว่าแต่ละรายการมีลิงก์ไปยังหน้าผู้เขียน หมายความว่าคุณสามารถอ่านลิงก์เหล่านี้และสร้างสไปเดอร์เพื่อรับข้อมูลจากหน้าเหล่านี้ทั้งหมดได้
รหัสที่สมบูรณ์นี้รวมอยู่ใน data_in_same_page.py
ไซต์แบบไดนามิกที่ขูดเว็บสามารถติดตามเส้นทางที่แตกต่างไปจากเดิมอย่างสิ้นเชิง บางครั้งข้อมูลจะถูกโหลดในหน้าแยกกันโดยสิ้นเชิง ตัวอย่างหนึ่งคือ Librivox
เปิดเครื่องมือสำหรับนักพัฒนา ไปที่แท็บเครือข่ายแล้วกรองตาม XHR ตอนนี้เปิดลิงก์นี้หรือค้นหาหนังสือเล่มใดก็ได้ คุณจะเห็นว่าข้อมูลนั้นเป็น HTML ที่ฝังอยู่ใน JSON
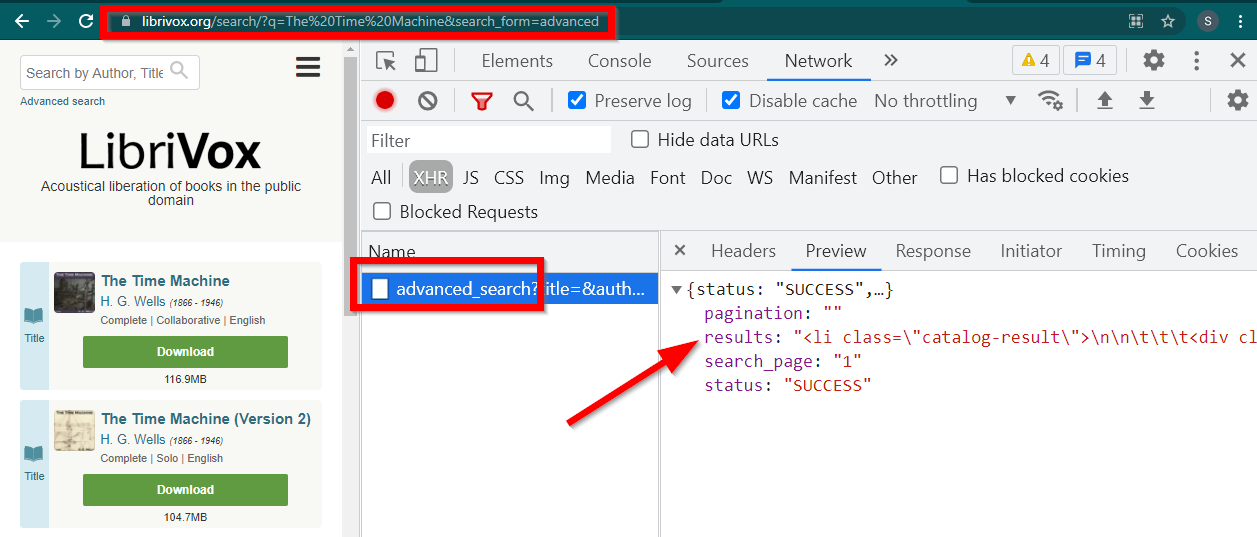
โปรดทราบบางสิ่ง:
URL ที่แสดงโดยเบราว์เซอร์คือ https://librivox.org/search/?q=...
ข้อมูลอยู่ใน https://librivox.org/advanced_search?....
หากคุณดูที่ส่วนหัว คุณจะพบว่าหน้า Advanced_search ถูกส่งส่วนหัวพิเศษ X-Requested-With: XMLHttpRequest
นี่คือตัวอย่างเพื่อแยกข้อมูลนี้:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )รหัสที่สมบูรณ์จะรวมอยู่ในไฟล์ librivox.py


