disclosure backend static
1.0.0
repo disclosure-backend-static คือแบ็กเอนด์ที่ขับเคลื่อน Open Disclosure California
มันถูกสร้างขึ้นอย่างเร่งรีบจนถึงการเลือกตั้งปี 2559 และได้รับการออกแบบตามปรัชญา "ลงมือทำ" ในเวลานั้น เราได้ออกแบบ API และสร้างส่วนหน้า (ส่วนใหญ่) แล้ว repo นี้ถูกสร้างขึ้นเพื่อดำเนินการเหล่านั้นโดยเร็วที่สุด
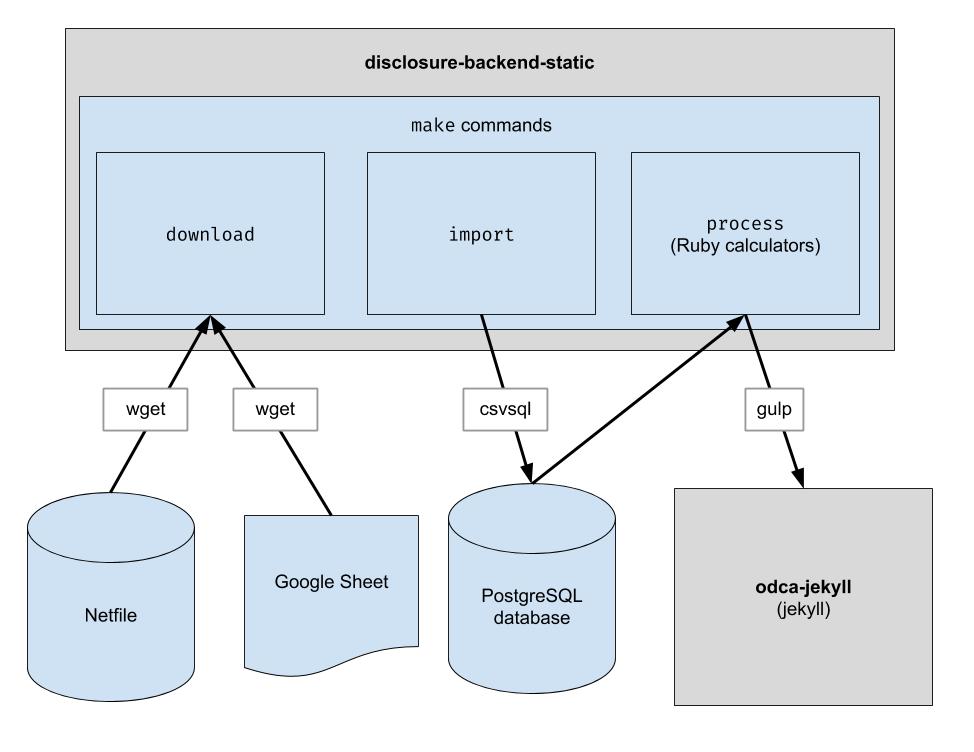
โปรเจ็กต์นี้ใช้ไปป์ไลน์ ETL พื้นฐานเพื่อดาวน์โหลดข้อมูล Netfile ของ Oakland ดาวน์โหลดข้อมูลที่ดูแลจัดการโดยมนุษย์ในรูปแบบ CSV สำหรับ Oakland และรวมทั้งสองเข้าด้วยกัน เอาต์พุตคือไดเร็กทอรีของไฟล์ JSON ซึ่งเลียนแบบโครงสร้าง API ที่มีอยู่ ดังนั้นจึงไม่จำเป็นต้องเปลี่ยนแปลงโค้ดไคลเอ็นต์
.ruby-version ) หมายเหตุ: คุณไม่จำเป็นต้องเรียกใช้คำสั่งเหล่านี้เพื่อพัฒนาบนส่วนหน้า สิ่งที่คุณต้องทำคือโคลนพื้นที่เก็บข้อมูลที่อยู่ติดกับ repo ส่วนหน้า
หากคุณวางแผนที่จะแก้ไขโค้ดแบ็กเอนด์ ให้ทำตามขั้นตอนเหล่านี้เพื่อตั้งค่าการพึ่งพาการพัฒนาที่จำเป็นทั้งหมด รวมถึงฐานข้อมูล PostgreSQL และ Python 3 ใหม่:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip แทน pip เพื่อให้แน่ใจว่ามีการใช้ Python 3: python3 -m pip install ...
pip ของระบบของคุณชี้ไปที่ Python 3 คุณสามารถใช้ pip ได้โดยตรง: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
พื้นที่เก็บข้อมูลนี้ได้รับการตั้งค่าให้ทำงานในคอนเทนเนอร์ภายใต้ Codespaces กล่าวอีกนัยหนึ่ง คุณสามารถเริ่มต้นสภาพแวดล้อมที่ตั้งค่าไว้แล้วโดยไม่ต้องทำตามขั้นตอนการติดตั้งใดๆ ที่จำเป็นในการตั้งค่าสภาพแวดล้อมภายในเครื่อง ซึ่งสามารถใช้เป็นวิธีการแก้ไขปัญหาโค้ดก่อนที่จะส่งไปยังไปป์ไลน์การผลิต ข้อมูลต่อไปนี้อาจเป็นประโยชน์ในการเริ่มต้นใช้งาน Codespaces:
Code แล้วคลิกแท็บ Codespaces ในเมนูแบบเลื่อนลง/workspace จะถูกนำเสนอในหน้าเว็บ ซึ่งจะดูคุ้นเคยหากคุณเคยทำงานกับ VS Code มาก่อนmake downloadpsql ในเทอร์มินัลเพื่อเชื่อมต่อกับเซิร์ฟเวอร์make import จะเติมฐานข้อมูล Postgresgit pushพื้นที่เก็บข้อมูลนี้ได้รับการกำหนดค่าให้ทำงานภายในคอนเทนเนอร์ Docker ด้วย สิ่งนี้คล้ายกับ Codespaces ยกเว้นว่าคุณสามารถใช้ IDE และการตั้งค่าในเครื่องใดก็ได้ที่คุณต้องการ ต่อไปนี้เป็นวิธีเริ่มต้นใช้งาน Docker กับ VSCode:
ดาวน์โหลดไฟล์ข้อมูลดิบ คุณจะต้องดำเนินการนี้เป็นครั้งคราวเพื่อรับข้อมูลล่าสุด
$ make download
นำเข้าข้อมูลเข้าสู่ฐานข้อมูลเพื่อการประมวลผลที่ง่ายขึ้น คุณจะต้องเรียกใช้สิ่งนี้หลังจากที่คุณดาวน์โหลดข้อมูลใหม่แล้วเท่านั้น
$ make import
เรียกใช้เครื่องคิดเลข ทุกอย่างจะถูกส่งออกไปยังโฟลเดอร์ "build"
$ make process
ทางเลือก จัดทำดัชนีเอาต์พุตบิลด์ใหม่ลงใน Algolia (การจัดทำดัชนีใหม่ต้องใช้ตัวแปรสภาพแวดล้อม ALGOLIASEARCH_APPLICATION_ID และ ALGOLIASEARCH_API_KEY)
$ make reindex
หากคุณต้องการให้บริการไฟล์ JSON แบบคงที่ผ่านเว็บเซิร์ฟเวอร์ในเครื่อง ให้ทำดังนี้
$ make run
เมื่อรัน make import ตาราง postgres จำนวนหนึ่งจะถูกสร้างขึ้นเพื่อนำเข้าข้อมูลที่ดาวน์โหลด สคีมาของตารางเหล่านี้ถูกกำหนดไว้อย่างชัดเจนในไดเร็กทอรี dbschema และอาจต้องได้รับการอัปเดตในอนาคตเพื่อรองรับข้อมูลในอนาคต คอลัมน์ที่เก็บข้อมูลสตริงอาจมีขนาดไม่ใหญ่พอสำหรับข้อมูลในอนาคต ตัวอย่างเช่น หากคอลัมน์ชื่อยอมรับชื่อที่มีความยาวไม่เกิน 20 อักขระ และในอนาคต เรามีข้อมูลที่ชื่อมีความยาว 21 อักขระ การนำเข้าข้อมูลจะล้มเหลว เมื่อสิ่งนี้เกิดขึ้น เราจะต้องอัปเดตไฟล์สคีมาที่เกี่ยวข้องใน dbschema เพื่อรองรับอักขระเพิ่มเติม เพียงทำการเปลี่ยนแปลงและเรียกใช้ make import อีกครั้งเพื่อตรวจสอบว่าสำเร็จหรือไม่
พื้นที่เก็บข้อมูลนี้ใช้เพื่อสร้างไฟล์ข้อมูลที่เว็บไซต์ใช้ หลังจากรัน make process แล้ว ไดเร็กทอรี build จะถูกสร้างขึ้นโดยมีไฟล์ข้อมูล ไดเร็กทอรีนี้ถูกเช็คอินในพื้นที่เก็บข้อมูล และเช็คเอาท์ในภายหลังเมื่อสร้างเว็บไซต์ หลังจากทำการเปลี่ยนแปลงโค้ด สิ่งสำคัญคือต้องเปรียบเทียบไดเร็กทอรี build ที่สร้างขึ้นกับไดเร็กทอรี build ที่สร้างขึ้นก่อนการเปลี่ยนแปลงโค้ด และตรวจสอบว่าการเปลี่ยนแปลงจากการเปลี่ยนแปลงโค้ดเป็นไปตามที่คาดไว้
เนื่องจากการเปรียบเทียบเนื้อหาทั้งหมดของไดเร็กทอรี build อย่างเข้มงวดจะรวมการเปลี่ยนแปลงที่เกิดขึ้นโดยไม่ขึ้นกับการเปลี่ยนแปลงโค้ดใดๆ เสมอ นักพัฒนาทุกคนจึงต้องทราบเกี่ยวกับการเปลี่ยนแปลงที่คาดหวังเหล่านี้เพื่อดำเนินการตรวจสอบนี้ หากต้องการลบความจำเป็นนี้ ไฟล์เฉพาะ bin/create-digests.py จะสร้างไดเจสต์สำหรับข้อมูล JSON ในไดเร็กทอรี build หลังจากยกเว้นการเปลี่ยนแปลงที่คาดไว้เหล่านี้ หากต้องการค้นหาการเปลี่ยนแปลงที่ไม่รวมการเปลี่ยนแปลงที่คาดหวังเหล่านี้ เพียงมองหาการเปลี่ยนแปลงในไฟล์ build/digests.json
ในปัจจุบัน การเปลี่ยนแปลงที่คาดหวังเหล่านี้เกิดขึ้นโดยไม่ขึ้นกับการเปลี่ยนแปลงรหัสใดๆ:
การเปลี่ยนแปลงที่คาดไว้จะถูกแยกออกก่อนที่จะสร้างไดเจสต์สำหรับข้อมูลในไดเร็กทอรี build ตรรกะสำหรับสิ่งนี้สามารถพบได้ในฟังก์ชัน clean_data ที่พบในไฟล์ bin/create-digests.py หลังจากที่โค้ดได้รับการแก้ไขจนไม่มีการเปลี่ยนแปลงที่คาดหวังอีกต่อไปแล้ว การแยกการเปลี่ยนแปลงนั้นสามารถลบออกจาก clean_data ได้ ตัวอย่างเช่น การปัดเศษของการลอยไม่เหมือนกันในแต่ละครั้งที่รัน make process เนื่องจากความแตกต่างในสภาพแวดล้อม เมื่อโค้ดได้รับการแก้ไขเพื่อให้การปัดเศษของ float เท่ากันตราบใดที่ข้อมูลไม่มีการเปลี่ยนแปลง การเรียก round_float ใน clean_data ก็สามารถลบออกได้
มีการสร้างสคริปต์เพิ่มเติมเพื่อสร้างรายงานที่ช่วยให้สามารถเปรียบเทียบผลรวมของผู้สมัครได้ สคริปต์คือ bin/report-candidates.py และสร้าง build/candidates.csv และ build/candidates.xlsx รายงานประกอบด้วยรายชื่อผู้สมัครทั้งหมดและผลรวมที่คำนวณได้หลายวิธีที่ควรรวมกันเป็นตัวเลขเดียวกัน
เพื่อให้แน่ใจว่าการเปลี่ยนแปลงสคีมาฐานข้อมูลสามารถมองเห็นได้ในคำขอดึง สคีมา postgres ที่สมบูรณ์จะถูกบันทึกลงในไฟล์ schema.sql ในไดเร็กทอรี build ด้วย เนื่องจากไดเร็กทอรี build ถูกสร้างขึ้นใหม่โดยอัตโนมัติสำหรับแต่ละสาขาใน PR และคอมมิตกับพื้นที่เก็บข้อมูล การเปลี่ยนแปลงใดๆ ในสคีมาที่เกิดจากการเปลี่ยนแปลงโค้ดจะแสดงความแตกต่างในไฟล์ schema.sql เมื่อตรวจสอบ PR
แต่ละตัวชี้วัดเกี่ยวกับผู้สมัครจะได้รับการคำนวณอย่างแยกจากกัน ตัวชี้วัดอาจเป็น "เงินสนับสนุนทั้งหมดที่ได้รับ" หรืออะไรที่ซับซ้อนกว่านั้น เช่น "เปอร์เซ็นต์ของเงินสนับสนุนที่น้อยกว่า 100 ดอลลาร์"
เมื่อเพิ่มการคำนวณใหม่ จุดเริ่มต้นที่ดีคือแบบฟอร์ม 460 อย่างเป็นทางการ คุณกำลังมองหาข้อมูลที่ถูกรายงานในแบบฟอร์มนั้นหรือไม่ หากเป็นเช่นนั้น คุณจะพบข้อมูลดังกล่าวในฐานข้อมูลของคุณหลังจากขั้นตอนการนำเข้า นอกจากนี้ยังมีแบบฟอร์มอื่นๆ อีกสองสามรูปแบบที่เรานำเข้า เช่น แบบฟอร์ม 496 (นี่คือชื่อของไฟล์ในไดเร็กทอรี input ตรวจสอบสิ่งเหล่านั้น)
แต่ละกำหนดการของแต่ละแบบฟอร์มจะถูกนำเข้าไปยังตาราง postgres ที่แยกจากกัน ตัวอย่างเช่น ตาราง A ของแบบฟอร์ม 460 จะถูกนำเข้าไปยังตาราง A-Contributions
เมื่อคุณมีวิธีในการสืบค้นข้อมูลแล้ว คุณควรสร้างแบบสอบถาม SQL ที่คำนวณค่าที่คุณกำลังพยายามรับ เมื่อคุณแสดงการคำนวณเป็น SQL แล้ว ให้ใส่ไว้ในไฟล์เครื่องคิดเลขดังนี้:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_IDcandidate.save_calculation วิธีการนั้นจะทำให้อาร์กิวเมนต์ที่สองเป็นอนุกรมเป็น JSON เพื่อให้สามารถจัดเก็บข้อมูลประเภทใดก็ได้candidate.calculation(:your_thing) คุณจะต้องเพิ่มสิ่งนี้ลงในการตอบกลับ API ในไฟล์ process.rb นี่คือวิธีที่ข้อมูลไหลผ่านส่วนหลัง ข้อมูลทางการเงินถูกดึงมาจาก Netfile ซึ่งเสริมด้วยรหัสไฟล์ของไฟล์การแมป Google ชีตกับข้อมูลบัตรลงคะแนน เช่น ชื่อผู้สมัคร สำนักงาน มาตรการลงคะแนนเสียง ฯลฯ เมื่อกรอง รวบรวม และแปลงข้อมูลแล้ว ส่วนหน้าจะใช้ข้อมูลดังกล่าวและสร้าง HTML แบบคงที่ ส่วนหน้า
ระหว่างการติดตั้ง Bundle
error: use of undeclared identifier 'LZMA_OK'
พยายาม:
brew unlink xz
bundle install
brew link xz
ระหว่าง make download
wget: command not found
วิ่ง brew install wget
ระหว่าง make import
ดูเหมือนว่ามีปัญหากับระบบ Macintosh ที่ใช้ชิป Apple
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
ลองดังต่อไปนี้:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


