phenaki pytorch
0.5.0
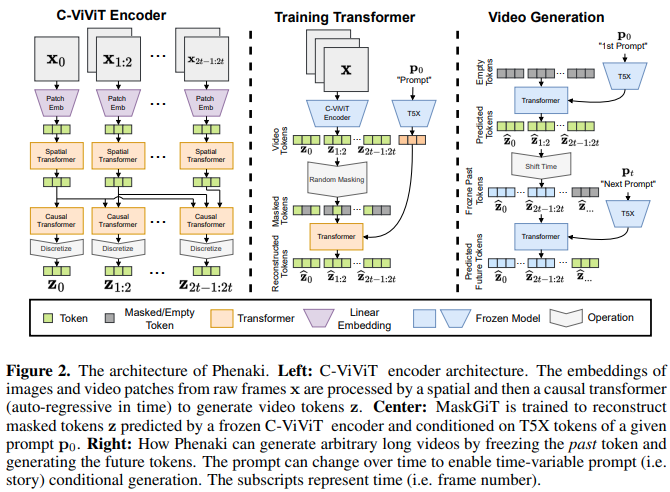
การใช้งาน Phenaki Video ซึ่งใช้ Mask GIT เพื่อสร้างวิดีโอแนะนำด้วยข้อความที่มีความยาวสูงสุด 2 นาทีใน Pytorch นอกจากนี้ยังจะรวมเทคนิคอื่นที่เกี่ยวข้องกับการวิจารณ์โทเค็นเพื่อคนรุ่นที่ดีกว่าอีกด้วย
กรุณาเข้าร่วมหากคุณสนใจที่จะทำซ้ำงานนี้ในที่สาธารณะ
คำอธิบาย AI Coffeebreak
Stability.ai สำหรับการสนับสนุนอย่างมีน้ำใจในการทำงานวิจัยปัญญาประดิษฐ์ที่ล้ำหน้า
- กอดกันเพื่อหม้อแปลงที่น่าทึ่งและเร่งห้องสมุด
Guillem สำหรับการสนับสนุนอย่างต่อเนื่องของเขา
คุณ? หากคุณเป็นวิศวกรแมชชีนเลิร์นนิงและ/หรือนักวิจัยที่ยอดเยี่ยม อย่าลังเลที่จะมีส่วนร่วมในขอบเขตของ AI แบบโอเพ่นซอร์ส
$ pip install phenaki-pytorchC-ViViT
import torch
from phenaki_pytorch import CViViT , CViViTTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
). cuda ()
trainer = CViViTTrainer (
cvivit ,
folder = '/path/to/images/or/videos' ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = False , # you can train on images first, before fine tuning on video, for sample efficiency
use_ema = False , # recommended to be turned on (keeps exponential moving averaged cvivit) unless if you don't have enough resources
num_train_steps = 10000
)
trainer . train () # reconstructions and checkpoints will be saved periodically to ./resultsฟีนากิ
import torch
from phenaki_pytorch import CViViT , MaskGit , Phenaki
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = ( 256 , 128 ), # video with rectangular screen allowed
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
videos = torch . randn ( 3 , 3 , 17 , 256 , 128 ). cuda () # (batch, channels, frames, height, width)
mask = torch . ones (( 3 , 17 )). bool (). cuda () # [optional] (batch, frames) - allows for co-training videos of different lengths as well as video and images in the same batch
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = phenaki ( videos , texts = texts , video_frame_mask = mask )
loss . backward ()
# do the above for many steps, then ...
video = phenaki . sample ( texts = 'a squirrel examines an acorn' , num_frames = 17 , cond_scale = 5. ) # (1, 3, 17, 256, 128)
# so in the paper, they do not really achieve 2 minutes of coherent video
# at each new scene with new text conditioning, they condition on the previous K frames
# you can easily achieve this with this framework as so
video_prime = video [:, :, - 3 :] # (1, 3, 3, 256, 128) # say K = 3
video_next = phenaki . sample ( texts = 'a cat watches the squirrel from afar' , prime_frames = video_prime , num_frames = 14 ) # (1, 3, 14, 256, 128)
# the total video
entire_video = torch . cat (( video , video_next ), dim = 2 ) # (1, 3, 17 + 14, 256, 128)
# and so on... หรือเพียงแค่นำเข้าฟังก์ชัน make_video
# ... above code
from phenaki_pytorch import make_video
entire_video , scenes = make_video ( phenaki , texts = [
'a squirrel examines an acorn buried in the snow' ,
'a cat watches the squirrel from a frosted window sill' ,
'zoom out to show the entire living room, with the cat residing by the window sill'
], num_frames = ( 17 , 14 , 14 ), prime_lengths = ( 5 , 5 ))
entire_video . shape # (1, 3, 17 + 14 + 14 = 45, 256, 256)
# scenes - List[Tensor[3]] - video segment of each sceneแค่นั้นแหละ!
บทความใหม่ชี้ให้เห็นว่าแทนที่จะอาศัยความน่าจะเป็นที่คาดการณ์ไว้ของแต่ละโทเค็นเพื่อวัดความมั่นใจ เราสามารถฝึกอบรมนักวิจารณ์เพิ่มเติมเพื่อตัดสินใจว่าจะปกปิดอะไรซ้ำๆ ในระหว่างการสุ่มตัวอย่าง คุณสามารถเลือกฝึกอบรมนักวิจารณ์นี้เพื่อคนรุ่นต่อไปที่อาจดีกว่าได้ดังที่แสดงด้านล่าง
import torch
from phenaki_pytorch import CViViT , MaskGit , TokenCritic , Phenaki
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = ( 256 , 128 ),
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
maskgit = MaskGit (
num_tokens = 65536 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
)
# (1) define the critic
critic = TokenCritic (
num_tokens = 65536 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
has_cross_attn = True
)
trainer = Phenaki (
maskgit = maskgit ,
cvivit = cvivit ,
critic = critic # and then (2) pass it into Phenaki
). cuda ()
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
videos = torch . randn ( 3 , 3 , 3 , 256 , 128 ). cuda () # (batch, channels, frames, height, width)
loss = trainer ( videos = videos , texts = texts )
loss . backward () หรือง่ายกว่านั้น เพียงใช้ MaskGit ซ้ำอีกครั้งในฐานะ Self Critic (Nijkamp et al) โดยการตั้งค่า self_token_critic = True ในการเริ่มต้นของ Phenaki
phenaki = Phenaki (
...,
self_token_critic = True # set this to True
)บัดนี้เชื้อสายของคุณควรได้รับการปรับปรุงอย่างมาก!
พื้นที่เก็บข้อมูลนี้จะพยายามให้ผู้วิจัยสามารถฝึกอบรมการแปลงข้อความเป็นรูปภาพและแปลงข้อความเป็นวิดีโอได้ ในทำนองเดียวกัน สำหรับการฝึกอบรมแบบไม่มีเงื่อนไข ผู้วิจัยควรสามารถฝึกอบรมเกี่ยวกับรูปภาพก่อนแล้วค่อยปรับแต่งวิดีโอ ด้านล่างนี้เป็นตัวอย่างสำหรับข้อความเป็นวิดีโอ
import torch
from torch . utils . data import Dataset
from phenaki_pytorch import CViViT , MaskGit , Phenaki , PhenakiTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
unconditional = False
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
# mock text video dataset
# you will have to extend your own, and return the (<video tensor>, <caption>) tuple
class MockTextVideoDataset ( Dataset ):
def __init__ (
self ,
length = 100 ,
image_size = 256 ,
num_frames = 17
):
super (). __init__ ()
self . num_frames = num_frames
self . image_size = image_size
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
video = torch . randn ( 3 , self . num_frames , self . image_size , self . image_size )
caption = 'video caption'
return video , caption
dataset = MockTextVideoDataset ()
# pass in the dataset
trainer = PhenakiTrainer (
phenaki = phenaki ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = False , # if your mock dataset above return (images, caption) pairs, set this to True
dataset = dataset , # pass in your dataset here
sample_texts_file_path = '/path/to/captions.txt' # each caption should be on a new line, during sampling, will be randomly drawn
)
trainer . train ()แบบไม่มีเงื่อนไขมีดังนี้
อดีต. การฝึกอบรมภาพและวิดีโอแบบไม่มีเงื่อนไข
import torch
from phenaki_pytorch import CViViT , MaskGit , Phenaki , PhenakiTrainer
cvivit = CViViT (
dim = 512 ,
codebook_size = 65536 ,
image_size = 256 ,
patch_size = 32 ,
temporal_patch_size = 2 ,
spatial_depth = 4 ,
temporal_depth = 4 ,
dim_head = 64 ,
heads = 8
)
cvivit . load ( '/path/to/trained/cvivit.pt' )
maskgit = MaskGit (
num_tokens = 5000 ,
max_seq_len = 1024 ,
dim = 512 ,
dim_context = 768 ,
depth = 6 ,
unconditional = False
)
phenaki = Phenaki (
cvivit = cvivit ,
maskgit = maskgit
). cuda ()
# pass in the folder to images or video
trainer = PhenakiTrainer (
phenaki = phenaki ,
batch_size = 4 ,
grad_accum_every = 4 ,
train_on_images = True , # for sake of example, bottom is folder of images
dataset = '/path/to/images/or/video'
)
trainer . train ()ส่งผ่านความน่าจะเป็นของมาสก์ไปยังมาสก์กิตและมาสก์อัตโนมัติ และรับการสูญเสียเอนโทรปีข้าม
ข้ามความสนใจ + รับโค้ดการฝัง t5 จาก imagen-pytorch และรับคำแนะนำการแยกประเภทฟรีแบบต่อสาย
เชื่อมต่อ vqgan-vae แบบเต็มสำหรับ c-vivit เพียงใช้สิ่งที่อยู่ใน parti-pytorch แล้ว แต่ต้องแน่ใจว่าใช้ตัวแยกแยะ stylegan ตามที่กล่าวไว้ในกระดาษ
กรอกรหัสฝึกอบรมนักวิจารณ์โทเค็นให้สมบูรณ์
ดำเนินการสุ่มตัวอย่างตามกำหนดเวลาของ Maskgit + นักวิจารณ์โทเค็นผ่านครั้งแรก (เป็นทางเลือกหากผู้วิจัยไม่ต้องการฝึกอบรมเพิ่มเติม)
รหัสการอนุมานที่ช่วยให้เลื่อนเวลา + ปรับสภาพบน K เฟรมที่ผ่านมา
ข้อแก้ตัวเกี่ยวกับความลำเอียงสำหรับความสนใจชั่วคราว
ให้ความสนใจเชิงพื้นที่กับอคติตำแหน่งที่ทรงพลังที่สุด
ตรวจสอบให้แน่ใจว่าใช้ตัวแยกแยะ stylegan-esque
อคติตำแหน่งสัมพัทธ์ 3 มิติสำหรับมาสก์กิต
ตรวจสอบให้แน่ใจว่า Maskgit สามารถรองรับการฝึกอิมเมจได้ และตรวจสอบให้แน่ใจว่ามันทำงานบนเครื่องในเครื่อง
ยังสร้างตัวเลือกสำหรับนักวิจารณ์โทเค็นที่จะกำหนดเงื่อนไขด้วยข้อความ
ควรฝึกการสร้างข้อความเป็นรูปภาพก่อน
ตรวจสอบให้แน่ใจว่าผู้ฝึกสอนนักวิจารณ์สามารถรับ cvivit และส่งผ่านรูปร่างของแพตช์วิดีโอโดยอัตโนมัติสำหรับอคติด้านตำแหน่งสัมพัทธ์ - ตรวจสอบให้แน่ใจว่านักวิจารณ์ได้รับอคติด้านตำแหน่งสัมพัทธ์ที่เหมาะสมที่สุดด้วย
รหัสการฝึกอบรมสำหรับ cvivit
ย้าย cvivit ไปยังไฟล์ของตัวเอง
รุ่นที่ไม่มีเงื่อนไข (ทั้งวิดีโอและรูปภาพ)
วางสายเร่งความเร็วสำหรับการฝึก multi-gpu สำหรับทั้ง c-vivit และ maskgit
เพิ่ม deepwise-convs ให้กับ cvivit เพื่อสร้างตำแหน่ง
โค้ดการจัดการวิดีโอพื้นฐานบางส่วน อนุญาตให้บันทึกเทนเซอร์ตัวอย่างเป็น GIF ได้
รหัสการฝึกอบรมการวิจารณ์ขั้นพื้นฐาน
เพิ่มตำแหน่งที่สร้าง dsconv ให้กับ maskgit ด้วย
เครื่องแต่งกายบล็อกความสนใจตนเองที่ปรับแต่งได้เพื่อแยกแยะ stylegan
เพิ่มการวิจัยชั้นนำทั้งหมดสำหรับการฝึกอบรมเสถียรภาพของหม้อแปลงไฟฟ้า
รับโค้ดสุ่มตัวอย่างนักวิจารณ์ขั้นพื้นฐาน แสดงการเปรียบเทียบระหว่างมีและไม่มีนักวิจารณ์
นำการเปลี่ยนโทเค็นแบบต่อกัน (มิติชั่วคราว)
เพิ่ม DDPM upsampler ไม่ว่าจะเป็นพอร์ตจาก imagen-pytorch หรือเพียงแค่เขียนเวอร์ชันธรรมดาใหม่ที่นี่
ดูแลการมาสก์ในมาสก์กิต
ทดสอบ Maskgit + นักวิจารณ์เพียงลำพังในชุดข้อมูล Oxford Flowers
รองรับวิดีโอขนาดสี่เหลี่ยม
เพิ่มความสนใจแบบแฟลชเป็นตัวเลือกสำหรับหม้อแปลงทั้งหมดและอ้างอิง @tridao
@article { Villegas2022PhenakiVL ,
title = { Phenaki: Variable Length Video Generation From Open Domain Textual Description } ,
author = { Ruben Villegas and Mohammad Babaeizadeh and Pieter-Jan Kindermans and Hernan Moraldo and Han Zhang and Mohammad Taghi Saffar and Santiago Castro and Julius Kunze and D. Erhan } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02399 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { press2021ALiBi ,
title = { Train Short, Test Long: Attention with Linear Biases Enable Input Length Extrapolation } ,
author = { Ofir Press and Noah A. Smith and Mike Lewis } ,
year = { 2021 } ,
url = { https://ofir.io/train_short_test_long.pdf }
} @article { Liu2022SwinTV ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11999-12009 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

