metal flash attention
v1.0.1
พื้นที่เก็บข้อมูลนี้พอร์ตการใช้งาน FlashAttention อย่างเป็นทางการกับ Apple Silicon เป็นชุดไฟล์ต้นฉบับขั้นต่ำที่สามารถบำรุงรักษาได้ซึ่งสร้างอัลกอริทึม FlashAttention ขึ้นมาใหม่
ความสนใจแบบหัวเดียวเท่านั้น เพื่อมุ่งเน้นไปที่คอขวดหลักของอัลกอริธึมความสนใจที่แตกต่างกัน (ความดันการลงทะเบียน ความขนาน) ด้วยอัลกอริธึมพื้นฐานที่ทำอย่างถูกต้อง การเพิ่มการปรับแต่ง เช่น การกระจัดกระจายของบล็อก ควรจะเป็นเรื่องเล็กน้อย
ทุกอย่างถูกคอมไพล์โดย JIT ณ รันไทม์ สิ่งนี้แตกต่างกับการใช้งานก่อนหน้านี้ซึ่งอาศัยไฟล์ปฏิบัติการที่ฝังอยู่ใน Xcode 14.2
การย้อนกลับใช้หน่วยความจำน้อยกว่า Dao-AILab/flash-attention การใช้งานอย่างเป็นทางการจะจัดสรรพื้นที่เริ่มต้นสำหรับอะตอมและผลรวมบางส่วน ฮาร์ดแวร์ของ Apple ขาดอะตอมมิก FP32 ดั้งเดิม (จำลอง metal::atomic<float> ) ในขณะที่พยายามหลีกเลี่ยงการขาดการสนับสนุนด้านฮาร์ดแวร์ ก็พบปัญหาคอขวดของแบนด์วิธและการทำขนานในเคอร์เนลย้อนหลัง FlashAttention-2 ทางเลือกย้อนกลับได้รับการออกแบบให้มีต้นทุนการประมวลผลที่สูงขึ้น (7 GEMM แทนที่จะเป็น 5 GEMM) โดยให้ประสิทธิภาพการขนาน 100% ทั่วทั้งมิติแถวและคอลัมน์ของเมทริกซ์ความสนใจ สิ่งสำคัญที่สุดคือเขียนโค้ดและบำรุงรักษาได้ง่ายกว่า
มีการทำสิ่งบ้าๆ มากมายเพื่อเอาชนะปัญหาคอขวดของแรงกดดันในการลงทะเบียน ที่ส่วนหัวขนาดใหญ่ (เช่น 256) ไม่มีบล็อกเมทริกซ์ใดที่สามารถใส่ลงในรีจิสเตอร์ได้ แม้แต่ตัวสะสมก็ไม่สามารถ ดังนั้น การลงทะเบียนการรั่วไหลโดยเจตนาจึงเสร็จสิ้น แต่ด้วยวิธีที่เหมาะสมที่สุด มิติบล็อกที่สามถูกเพิ่มเข้าไปในอัลกอริธึมความสนใจ ซึ่งจะบล็อกตาม D อัตราส่วนภาพของบล็อกเมทริกซ์ความสนใจถูกบิดเบี้ยวอย่างมาก เพื่อลดต้นทุนแบนด์วิธของการรั่วไหลของการลงทะเบียน ตัวอย่างเช่น 16-32 ตามมิติการขนาน และ 80-128 ตามมิติการเคลื่อนที่ มีไฟล์พารามิเตอร์ขนาดใหญ่ที่ใช้มิติ D และกำหนดว่าตัวถูกดำเนินการใดที่สามารถใส่ลงในรีจิสเตอร์ได้ จากนั้นจะกำหนดขนาดบล็อกที่จะรักษาสมดุลของปัญหาคอขวดที่แข่งขันกันมากมาย
ผลลัพธ์ที่ได้คือคำแนะนำ 4400 กิกะบิตต่อวินาทีที่สอดคล้องกันบน M1 Max (การใช้ ALU 83%) ที่ความยาวลำดับไม่สิ้นสุดและขนาดส่วนหัวไม่สิ้นสุด การจำลอง BF16 ที่มีให้นั้นถูกนำมาใช้เพื่อความแม่นยำแบบผสม ( bfloat ของ Metal มีการปัดเศษที่สอดคล้องกับมาตรฐาน IEEE ซึ่งเป็นค่าใช้จ่ายหลักสำหรับชิปรุ่นเก่าที่ไม่มีฮาร์ดแวร์ BF16)
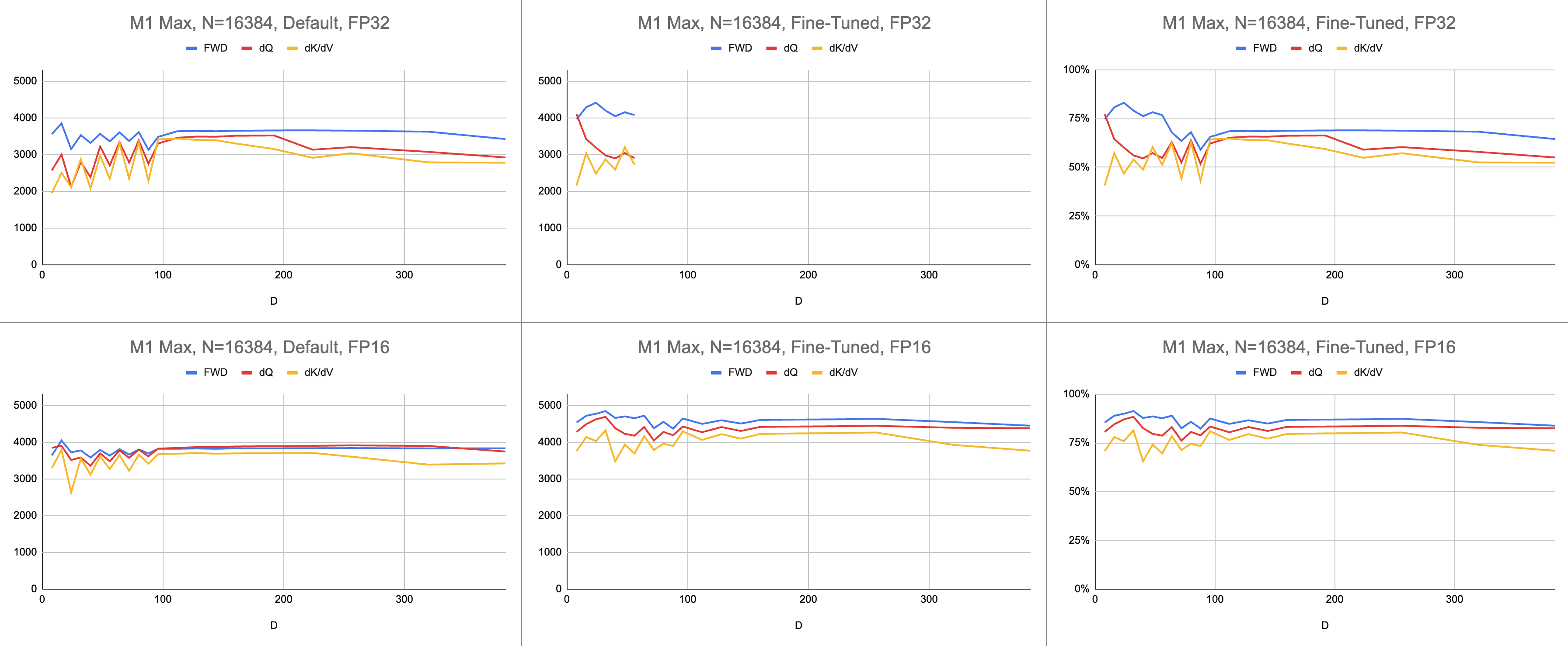
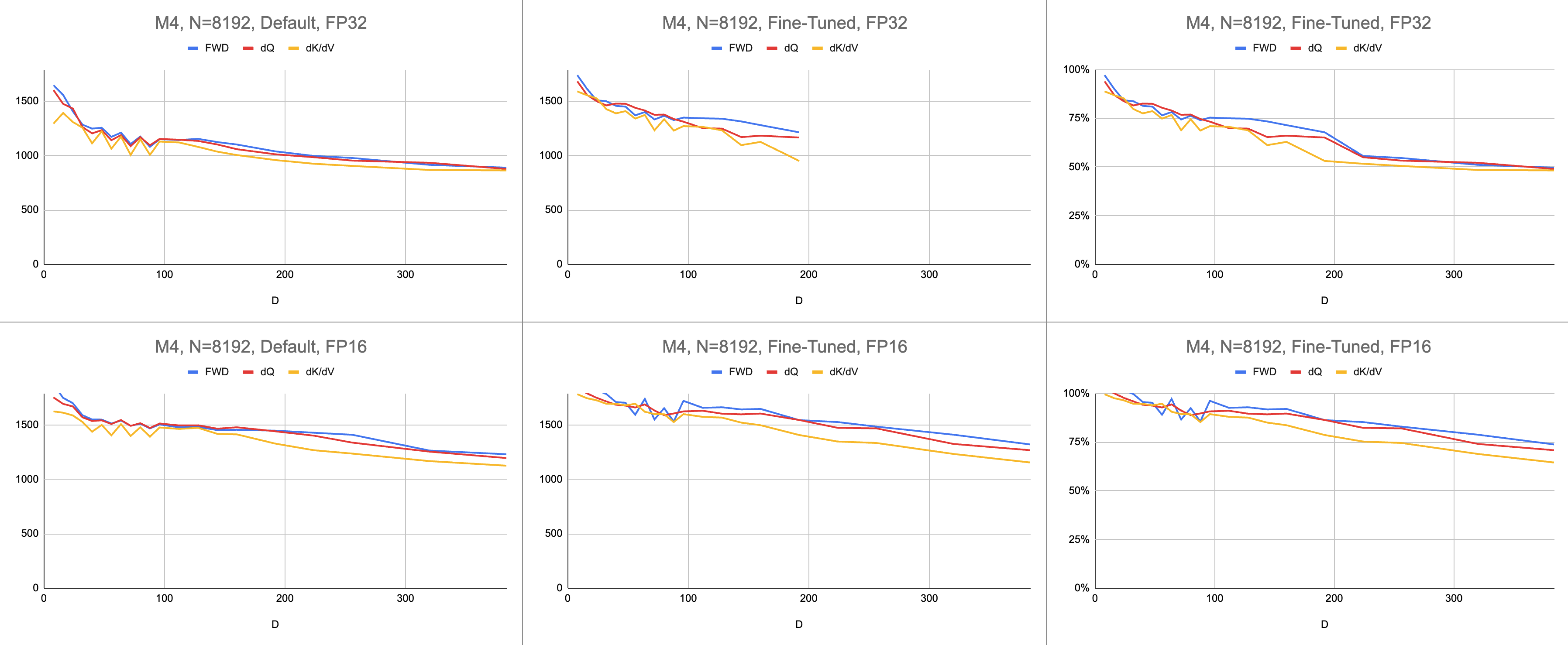
ข้อมูลดิบ: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
ในด้าน AI ประสิทธิภาพมักถูกรายงานเป็นการดำเนินการจุดลอยตัวขนาดกิกะต่อวินาที (GFLOPS) ตัวชี้วัดนี้สะท้อนถึงโมเดลประสิทธิภาพที่เรียบง่าย ซึ่งทุกคำสั่งเกิดขึ้นใน GEMM เนื่องจากฮาร์ดแวร์มีความก้าวหน้าตั้งแต่ FPU รุ่นแรกๆ ไปจนถึงโปรเซสเซอร์เวกเตอร์สมัยใหม่ การดำเนินการจุดลอยตัวที่พบบ่อยที่สุดจึงถูกหลอมรวมเป็นคำสั่งเดียว ผสมคูณ-บวก (FMA) เมื่อคูณเมทริกซ์ 100x100 สองตัว จะได้รับคำสั่ง FMA 1 ล้านคำสั่ง เหตุใดเราจึงต้องปฏิบัติต่อ FMA นี้เสมือนเป็นคำสั่งสองข้อที่แยกจากกัน
คำถามนี้เกี่ยวข้องกับความสนใจ โดยที่การดำเนินการจุดลอยตัวไม่ได้ถูกสร้างขึ้นเท่ากันทั้งหมด การยกกำลังระหว่างซอฟต์แม็กซ์จะเกิดขึ้นในรอบสัญญาณนาฬิกาเดียว โดยที่คำสั่งอื่นๆ ส่วนใหญ่จะไปที่หน่วย FMA การคูณและเพิ่มบางส่วนระหว่าง softmax ไม่สามารถผสมกับการบวกหรือคูณใกล้เคียงได้ เราควรปฏิบัติต่อสิ่งเหล่านี้เช่นเดียวกับ FMA และแสร้งทำเป็นว่าฮาร์ดแวร์กำลังดำเนินการ FMA ช้าลงสองเท่าหรือไม่ ยังไม่ชัดเจนว่าโมเดลประสิทธิภาพของ GEMM สามารถอธิบายได้อย่างไรว่าเชเดอร์ของฉันใช้ฮาร์ดแวร์ ALU อย่างมีประสิทธิภาพหรือไม่
แทนที่จะใช้ gigaflops ฉันใช้ gigainstructions เพื่อทำความเข้าใจว่าเชเดอร์ทำงานได้ดีเพียงใด มันแมปเข้ากับอัลกอริธึมโดยตรงมากขึ้น ตัวอย่างเช่น GEMM หนึ่งคำสั่งคือคำสั่ง N^3 FMA ความสนใจไปข้างหน้าดำเนินการคูณเมทริกซ์สองครั้งหรือคำสั่ง FMA 2 * D * N^2 ความสนใจย้อนกลับ (โดยการใช้ Dao-AILab/flash-attention) คือคำสั่ง 5 * D * N^2 FMA ลองเปรียบเทียบตารางนี้กับรุ่นหลังคาในเอกสาร Flash1, Flash2 หรือ Flash3
| การดำเนินการ | งาน |
|---|---|
| สแควร์เจมม์ | N^3 |
| ส่งต่อความสนใจ | (2D + 5) * N^2 |
| ความสนใจแบบไร้เดียงสาย้อนหลัง | 4D * N^2 |
| ถอยหลังแฟลชความสนใจ | (5D + 5) * N^2 |
| FWD + BWD รวม | (7D + 10) * N^2 |
เนื่องจากความซับซ้อนของอะตอมมิก FP32 MFA จึงใช้วิธีการอื่นในการส่งผ่านย้อนกลับ อันนี้มีต้นทุนการประมวลผลที่สูงกว่า มันแยกการย้อนกลับออกเป็นสองเคอร์เนลแยกกัน: dQ และ dK/dV เมนูแบบเลื่อนลงจะแสดงรหัสเทียม เปรียบเทียบสิ่งนี้กับหนึ่งในอัลกอริธึมในเอกสาร Flash1, Flash2 หรือ Flash3
| การดำเนินการ | งาน |
|---|---|
| ซึ่งไปข้างหน้า | (2D + 5) * N^2 |
| ดีคิวย้อนหลัง | (3D + 5) * N^2 |
| ย้อนกลับ dK/dV | (4D + 5) * N^2 |
| FWD + BWD รวม | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }ประสิทธิภาพวัดโดยการคำนวณปริมาณงานประมวลผล จากนั้นหารด้วยวินาที ผลลัพธ์ที่ได้คือ "gigainstructions ต่อวินาที" ต่อไปเราต้องมีโมเดลไลน์หลังคา ตารางด้านล่างแสดงเส้นหลังคาสำหรับ GINSTRS ซึ่งคำนวณเป็นครึ่งหนึ่งของ GFLOPS การใช้งาน ALU คือ (กิกะอินสตรัคชั่นจริงต่อวินาที) / (กิกะอินสตรัคชั่นที่คาดหวังต่อวินาที) ตัวอย่างเช่น M1 Max โดยทั่วไปจะใช้ ALU ได้ 80% ด้วยความแม่นยำแบบผสม
โมเดลนี้มีข้อจำกัด มันแตกสลายไปพร้อมกับรุ่น M3 ที่ขนาดหัวเล็ก หน่วยประมวลผลที่แตกต่างกันอาจถูกนำมาใช้พร้อมกัน ทำให้มีการใช้งานที่ชัดเจนมากกว่า 100% โดยส่วนใหญ่ เกณฑ์มาตรฐานจะให้แบบจำลองที่แม่นยำของประสิทธิภาพที่เหลืออยู่บนโต๊ะ
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| ฮาร์ดแวร์ | GFLOPS | GINSTRS |
|---|---|---|
| M1 สูงสุด | 10616 | 5308 |
| ม4 | 3580 | พ.ศ. 2333 |
พอร์ต Metal เปรียบเทียบกับพื้นที่เก็บข้อมูล FlashAttention อย่างเป็นทางการได้ดีเพียงใด ลองนึกภาพฉันใช้อัลกอริธึม "atomic dQ" และบรรลุประสิทธิภาพ 100% จากนั้นจึงเปลี่ยนไปใช้ MFA repo จริงและพบว่าการฝึกโมเดลช้าลง 4 เท่า นั่นจะเป็น 25% ของแนวหลังคาจากพื้นที่เก็บข้อมูลอย่างเป็นทางการ หากต้องการรับเปอร์เซ็นต์นี้ ให้คูณการใช้งาน ALU เฉลี่ยของเคอร์เนลทั้งสามด้วย 7 / 9 มีการใช้แบบจำลองที่เหมาะสมยิ่งขึ้นสำหรับสถิติเกี่ยวกับฮาร์ดแวร์ของ Apple แต่นี่คือส่วนสำคัญของโมเดล
ในการคำนวณการใช้งานฮาร์ดแวร์ของ Nvidia ฉันใช้ GFLOPS สำหรับ FP16/BF16 ALU ฉันแบ่ง GFLOPS สูงสุดจากแต่ละกราฟในบทความนี้ด้วย 312000 (A100 SXM), 989000 (H100 SXM) โปรดสังเกตว่าสำหรับขนาดส่วนหัวที่ใหญ่ขึ้นและเมล็ดที่มีการลงทะเบียนอย่างเข้มข้น (ผ่านย้อนกลับ) จะไม่มีการรายงานการวัดประสิทธิภาพ ฉันยืนยันว่าพวกเขาไม่ได้แก้ปัญหาความดันรีจิสเตอร์ที่ขนาดหัวที่ไม่มีที่สิ้นสุด ตัวอย่างเช่น ตัวสะสมจะถูกเก็บไว้ในการลงทะเบียนเสมอ ในขณะที่เขียน ฉันไม่เคยเห็นหลักฐานที่เป็นรูปธรรมของการไล่ระดับสีย้อนหลัง D=256 ที่ดำเนินการด้วยผลลัพธ์ที่ถูกต้อง
| A100, แฟลช2, FP16 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 192000 | 223000 | 0 |
| ถอยหลัง | 170000 | 196000 | 0 |
| เดินหน้า+ถอยหลัง | 176000 | 203000 | 0 |
| H100, แฟลช3, FP16 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 497000 | 648000 | 756000 |
| ถอยหลัง | 474000 | 561000 | 0 |
| เดินหน้า+ถอยหลัง | 480000 | 585000 | 0 |
| H100, แฟลช3, FP8 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 613000 | 1008000 | 1171000 |
| ถอยหลัง | 0 | 0 | 0 |
| เดินหน้า+ถอยหลัง | 0 | 0 | 0 |
| A100, แฟลช2, FP16 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 62% | 71% | 0% |
| เดินหน้า+ถอยหลัง | 56% | 65% | 0% |
| H100, แฟลช3, FP16 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 50% | 66% | 76% |
| เดินหน้า+ถอยหลัง | 48% | 59% | 0% |
| สถาปัตยกรรม M1, FP16 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 86% | 85% | 86% |
| เดินหน้า+ถอยหลัง | 62% | 63% | 64% |
| สถาปัตยกรรม M3, FP16 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| ซึ่งไปข้างหน้า | 94% | 91% | 82% |
| เดินหน้า+ถอยหลัง | 71% | 69% | 61% |
| ฮาร์ดแวร์ที่ผลิตในปี 2020 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| สถาปัตยกรรม M1—M2 | 62% | 63% | 64% |
| ฮาร์ดแวร์ที่ผลิตในปี 2023 | ด = 64 | ด = 128 | ด = 256 |
|---|---|---|---|
| H100 (ใช้ FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (ใช้ FP16 GFLOPS) | 48% | 59% | 0% |
| สถาปัตยกรรม M3—M4 | 71% | 69% | 61% |
แม้จะมีการคำนวณมากขึ้น แต่ฮาร์ดแวร์ของ Apple ก็ฝึกฝนหม้อแปลง ให้เร็วกว่าฮาร์ดแวร์ของ Nvidia ที่ทำงานเหมือนกัน การทำให้เป็นมาตรฐานสำหรับความแตกต่างขนาดระหว่าง GPU ที่แตกต่างกัน เพียงเน้นไปที่การใช้ GPU อย่างมีประสิทธิภาพ
บางทีพื้นที่เก็บข้อมูลหลักควรลองใช้อัลกอริธึมที่หลีกเลี่ยงอะตอมมิกของ FP32 และจงใจปล่อยรีจิสเตอร์เมื่อไม่สามารถใส่ลงในแกน GPU ได้ ดูเหมือนว่าไม่น่าเป็นไปได้ เนื่องจากมีการสนับสนุนแบบฮาร์ดโค้ดสำหรับชุดย่อยเล็กๆ ของขนาดปัญหาที่เป็นไปได้ แรงจูงใจดูเหมือนจะสนับสนุนโมเดลทั่วไป โดยที่ D คือกำลัง 2 และน้อยกว่า 128 สำหรับสิ่งอื่นใด ผู้ใช้จำเป็นต้องพึ่งพาการใช้งานทางเลือกอื่น (เช่น พื้นที่เก็บข้อมูล MFA) ซึ่งอาจใช้ข้อมูลพื้นฐานที่แตกต่างไปจากเดิมอย่างสิ้นเชิง อัลกอริทึม
บน macOS ให้ดาวน์โหลดแพ็คเกจ Swift และคอมไพล์ด้วย -Xswiftc -Ounchecked ตัวเลือกคอมไพเลอร์นี้จำเป็นสำหรับโค้ด CPU ที่ไวต่อประสิทธิภาพ ไม่สามารถใช้โหมด Release ได้เนื่องจากจะบังคับให้คอมไพล์โค้ดเบสทั้งหมดใหม่ตั้งแต่ต้น ทุกครั้งที่มีการเปลี่ยนแปลงเพียงครั้งเดียว ไปที่ Git repo ใน Finder แล้วดับเบิลคลิก Package.swift หน้าต่าง Xcode ควรปรากฏขึ้น ทางด้านซ้ายควรมีลำดับชั้นของไฟล์ หากคุณไม่สามารถคลี่คลายลำดับชั้นได้ แสดงว่ามีสิ่งผิดปกติเกิดขึ้น
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
หรือสร้างโปรเจ็กต์ Xcode ใหม่ด้วยเทมเพลต SwiftUI แทนที่ข้อความ "Hello, world!" string พร้อมการเรียกฟังก์ชันที่ส่งคืน String ฟังก์ชั่นนี้จะรันสคริปต์ที่คุณเลือก จากนั้นเรียก exit(0) ดังนั้นแอปจึงหยุดทำงานก่อนที่จะเรนเดอร์สิ่งใดๆ ลงบนหน้าจอ คุณจะใช้เอาต์พุตในคอนโซล Xcode เป็นคำติชมเกี่ยวกับโค้ดของคุณ ขั้นตอนการทำงานนี้เข้ากันได้กับทั้ง macOS และ iOS
เพิ่มตัวเลือก -Xswiftc -Ounchecked ผ่าน Project > ชื่อโครงการของคุณ > Build Settings > Swift Compiler - Code Generation > Optimization Level คอลัมน์ที่สองของตารางจะแสดงชื่อโครงการของคุณ คลิก อื่นๆ ในเมนูแบบเลื่อนลงและพิมพ์ -Ounchecked ในแผงที่ปรากฏขึ้น ถัดไป เพิ่มพื้นที่เก็บข้อมูลนี้เป็นการพึ่งพาแพ็คเกจ Swift ดูการทดสอบบางส่วนภายใต้ Tests/FlashAttention คัดลอกซอร์สโค้ดดิบสำหรับการทดสอบอย่างใดอย่างหนึ่งเหล่านี้ลงในโปรเจ็กต์ของคุณ เรียกใช้การทดสอบจากฟังก์ชันในย่อหน้าก่อนหน้า ตรวจสอบสิ่งที่แสดงบนคอนโซล
หากต้องการแก้ไขการสร้างโค้ดโลหะ (เช่น เพิ่มการรองรับหลายหัวหรือมาสก์) ให้คัดลอกโค้ด Swift แบบดิบลงในโปรเจ็กต์ Xcode ของคุณ ใช้ git clone ในโฟลเดอร์แยกต่างหาก หรือดาวน์โหลดไฟล์ raw บน GitHub เป็น ZIP นอกจากนี้ยังมีวิธีลิงก์ไปยังทางแยกของ metal-flash-attention และบันทึกการเปลี่ยนแปลงของคุณไปยังคลาวด์โดยอัตโนมัติ แต่การตั้งค่านี้ทำได้ยากกว่า ลบการพึ่งพาแพ็คเกจ Swift ออกจากย่อหน้าก่อนหน้า ทำการทดสอบที่คุณเลือกอีกครั้ง มันคอมไพล์และแสดงบางอย่างในคอนโซลหรือไม่?
ค้นหาหนึ่งในตัวอักษรสตริงหลายบรรทัดในโฟลเดอร์ใดโฟลเดอร์หนึ่งเหล่านี้:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
เพิ่มข้อความแบบสุ่มให้กับหนึ่งในนั้น คอมไพล์และรันโปรเจ็กต์อีกครั้ง มีบางอย่างผิดพลาดร้ายแรง ตัวอย่างเช่น คอมไพเลอร์ Metal อาจมีข้อผิดพลาดเกิดขึ้น หากไม่เกิดขึ้น ให้ลองสร้างโค้ดบรรทัดอื่นที่อื่น หากการทดสอบยังคงผ่าน แสดงว่า Xcode ไม่ได้บันทึกการเปลี่ยนแปลงของคุณ
ดำเนินการเขียนโค้ดต่อบล็อกกระจัดกระจายหรืออะไรสักอย่าง รับคำติชมว่าโค้ดใช้งานได้จริงหรือไม่ ทำงานเร็วหรือไม่ ทำงานได้เร็วในทุกขนาดปัญหาหรือไม่ รวมซอร์สโค้ดดิบเข้ากับแอปของคุณ หรือแปลเป็นภาษาโปรแกรมอื่น


