imagen pytorch
2.1.0
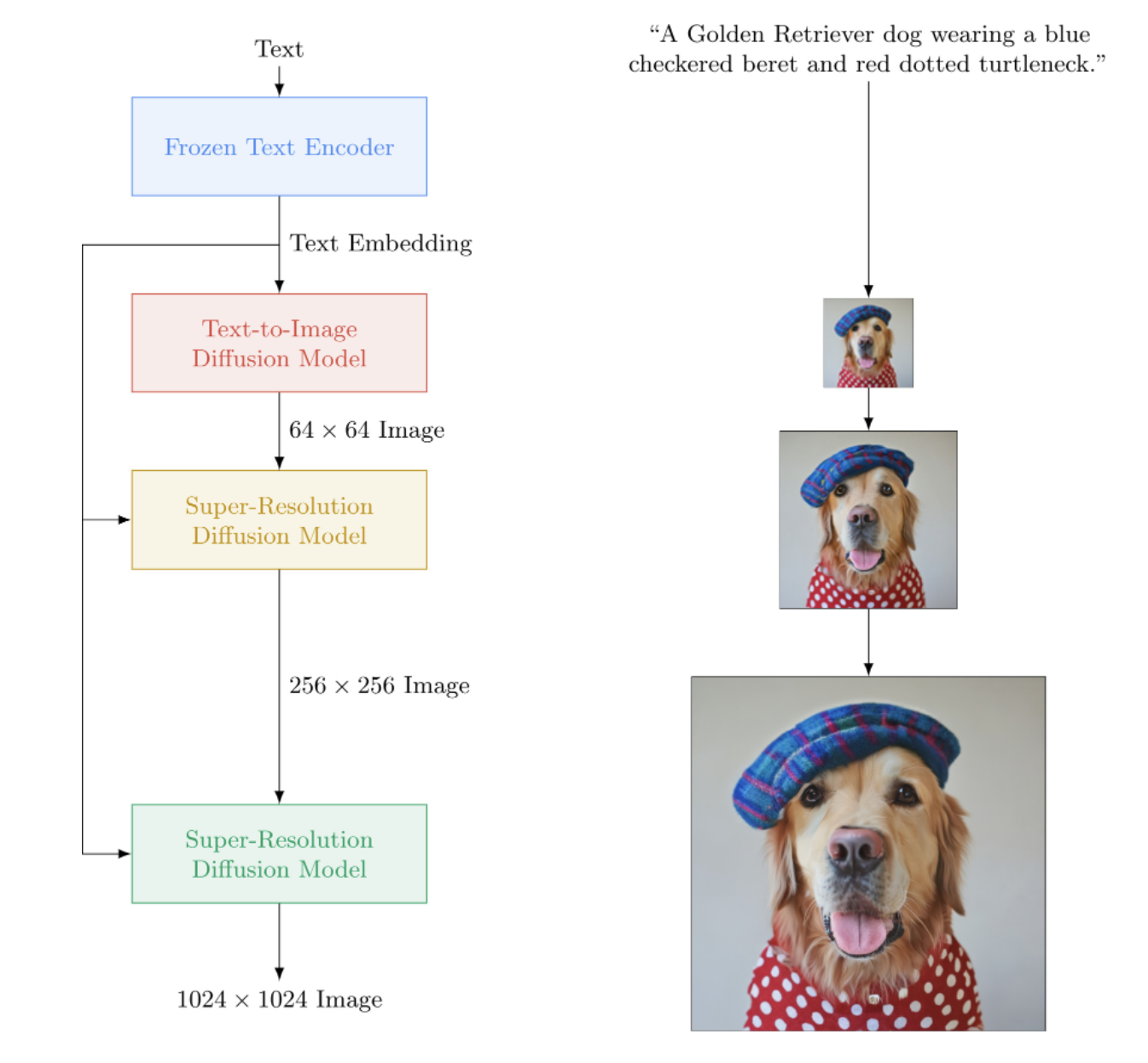
การใช้งาน Imagen ซึ่งเป็นเครือข่ายประสาทเทียมแปลงข้อความเป็นรูปภาพของ Google ที่เอาชนะ DALL-E2 ใน Pytorch เป็น SOTA ใหม่สำหรับการสังเคราะห์ข้อความเป็นรูปภาพ
ในทางสถาปัตยกรรมแล้ว จริงๆ แล้วง่ายกว่า DALL-E2 มาก ประกอบด้วย DDPM แบบเรียงซ้อนที่มีเงื่อนไขกับการฝังข้อความจากโมเดล T5 ที่ได้รับการฝึกล่วงหน้าขนาดใหญ่ (เครือข่ายความสนใจ) นอกจากนี้ยังมีการตัดภาพแบบไดนามิกสำหรับคำแนะนำแบบไม่มีตัวแยกประเภทที่ได้รับการปรับปรุง การปรับระดับเสียง และการออกแบบ Unet ที่มีประสิทธิภาพของหน่วยความจำ
ดูเหมือนว่าไม่จำเป็นต้องใช้ CLIP หรือเครือข่ายก่อนหน้าเลย ดังนั้นการวิจัยจึงดำเนินต่อไป
AI Coffee Break กับเลติเทีย | การประกอบ AI | ยานนิค คิลเชอร์
โปรดเข้าร่วมหากคุณสนใจที่จะช่วยเหลือในการจำลองแบบกับชุมชน LAION
StabilityAI สำหรับผู้สนับสนุนที่มีน้ำใจ เช่นเดียวกับผู้สนับสนุนคนอื่นๆ ของฉัน
- Huggingface สำหรับห้องสมุดหม้อแปลงที่น่าทึ่ง ส่วนตัวเข้ารหัสข้อความได้รับการดูแลเป็นอย่างดีเพราะส่วนนี้
Jonathan Ho นำเสนอการปฏิวัติปัญญาประดิษฐ์เชิงสร้างสรรค์ผ่านบทความวิจัยของเขา
Sylvain และ Zachary สำหรับห้องสมุด Accelerate ซึ่งพื้นที่เก็บข้อมูลนี้ใช้สำหรับการฝึกอบรมแบบกระจาย
Alex สำหรับ einops เครื่องมือที่ขาดไม่ได้สำหรับการจัดการเทนเซอร์
Jorge Gomes สำหรับการช่วยเหลือเกี่ยวกับโค้ดโหลด T5 และคำแนะนำเกี่ยวกับเวอร์ชัน T5 ที่ถูกต้อง
แคเธอรีน โครว์สัน สำหรับโค้ดที่สวยงามของเธอ ซึ่งช่วยให้ฉันเข้าใจการแพร่แบบเกาส์เซียนเวอร์ชันเวลาต่อเนื่อง
Marunine และ Netruk44 สำหรับตรวจสอบโค้ด แบ่งปันผลการทดลอง และช่วยในการแก้ไขจุดบกพร่อง
Marunine สำหรับการจัดหาวิธีแก้ปัญหาที่เป็นไปได้สำหรับปัญหาการเปลี่ยนสีใน u-nets ที่มีประสิทธิภาพของหน่วยความจำ ขอขอบคุณ Jacob สำหรับการแบ่งปันการเปรียบเทียบการทดลองระหว่างฐานและยูเน็ตที่มีประสิทธิภาพหน่วยความจำ
Marunine สำหรับการค้นหาจุดบกพร่องจำนวนมาก การแก้ไขปัญหาด้วยการปรับขนาดให้ถูกต้อง และสำหรับการแบ่งปันการกำหนดค่าและผลลัพธ์การทดลองของเขา
MalumaDev สำหรับการเสนอการใช้ pixel shuffle upsampler เพื่อแก้ไขสิ่งประดิษฐ์ของกระดานหมากรุก
Valentin เพื่อชี้ให้เห็นการเชื่อมต่อข้ามที่ไม่เพียงพอใน Unet ตลอดจนวิธีการเฉพาะในการปรับความสนใจใน Base-unet ในภาคผนวก
BIGJUN สำหรับการตรวจจับจุดบกพร่องขนาดใหญ่ด้วยการปรับระดับเสียงการแพร่แบบเกาส์เซียนแบบต่อเนื่องในเวลาอนุมาน
Bingbing สำหรับระบุจุดบกพร่องด้วยการสุ่มตัวอย่างและลำดับของการทำให้เป็นมาตรฐานและนอยซ์ด้วยการปรับสภาพภาพที่มีความละเอียดต่ำ
เคย์ที่สนับสนุนการฝึกคำสั่งบรรทัดเดียวของ Imagen!
Hadrien Reynaud สำหรับการทดสอบการแปลงข้อความเป็นวิดีโอบนชุดข้อมูลทางการแพทย์ แบ่งปันผลลัพธ์ของเขา และระบุปัญหา!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)เพื่อการฝึกที่ง่ายขึ้น คุณสามารถใส่สตริงข้อความได้โดยตรง แทนการเข้ารหัสข้อความที่คำนวณล่วงหน้า (แม้ว่าเพื่อวัตถุประสงค์ในการปรับขนาด คุณจะต้องคำนวณการฝังข้อความ + มาสก์ล่วงหน้าอย่างแน่นอน)
จำนวนคำบรรยายต้องตรงกับขนาดชุดของรูปภาพหากคุณใช้เส้นทางนี้
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () ด้วยคลาส wrapper ImagenTrainer ค่าเฉลี่ยเคลื่อนที่แบบเอ็กซ์โปเนนเชียลสำหรับ U-net ทั้งหมดใน DDPM แบบเรียงซ้อนจะได้รับการดูแลโดยอัตโนมัติเมื่อเรียกใช้ update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)คุณยังสามารถฝึก Imagen โดยไม่มีข้อความ (การสร้างภาพแบบไม่มีเงื่อนไข) ได้ดังต่อไปนี้
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)หรือฝึกเฉพาะ unets ที่มีความละเอียดมากเท่านั้น
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) คุณสามารถบันทึกและโหลดเทรนเนอร์และสถานะที่เกี่ยวข้องทั้งหมดได้ตลอดเวลาด้วยวิธี save และ load ขอแนะนำให้คุณใช้วิธีการเหล่านี้แทนการบันทึกด้วยตนเองด้วยการเรียก state_dict เนื่องจากมีการจัดการหน่วยความจำอุปกรณ์บางอย่างภายใต้ประทุนภายในเทรนเนอร์
อดีต.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 คุณยังสามารถไว้วางใจ ImagenTrainer เพื่อฝึกฝนอินสแตนซ์ DataLoader ได้โดยอัตโนมัติ คุณเพียงแค่ต้องสร้าง DataLoader ของคุณเพื่อส่งคืน images (สำหรับกรณีที่ไม่มีเงื่อนไข) หรือของ ('images', 'text_embeds') สำหรับการสร้างข้อความที่แนะนำ
อดีต. การฝึกอบรมแบบไม่มีเงื่อนไข
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )ขอบคุณ? เร่งความเร็ว คุณสามารถฝึก GPU หลายตัวได้อย่างง่ายดายด้วยสองขั้นตอน
ก่อนอื่นคุณต้องเรียกใช้การกำหนด accelerate config ในไดเร็กทอรีเดียวกันกับสคริปต์การฝึกอบรมของคุณ (เช่นชื่อ train.py )
$ accelerate config ถัดไป แทนที่จะเรียก python train.py เหมือนกับที่คุณเรียกกับ GPU ตัวเดียว คุณจะใช้ Accelerator CLI เช่นนั้น
$ accelerate launch train.pyแค่นั้นแหละ!
Imagen สามารถใช้ผ่าน CLI ได้โดยตรง
อดีต.
$ imagen configหรือ
$ imagen config --path ./configs/config.jsonในการกำหนดค่า คุณสามารถเปลี่ยนการตั้งค่าสำหรับเทรนเนอร์ ชุดข้อมูล และการกำหนดค่าอิมเมจได้
พารามิเตอร์การกำหนดค่า Imagen สามารถพบได้ที่นี่
สามารถดูพารามิเตอร์การกำหนดค่า Elucidated Imagen ได้ที่นี่
คุณสามารถดูพารามิเตอร์การกำหนดค่า Imagen Trainer ได้ที่นี่
สำหรับพารามิเตอร์ชุดข้อมูล สามารถใช้พารามิเตอร์ dataloader ทั้งหมดได้
คำสั่งนี้ช่วยให้คุณสามารถฝึกหรือฝึกโมเดลของคุณต่อได้
อดีต.
$ imagen trainหรือ
$ imagen train --unet 2 --epoches 10คุณสามารถส่งผ่านอาร์กิวเมนต์ต่อไปนี้ไปยังคำสั่งการฝึกอบรมได้
--config ระบุไฟล์กำหนดค่าที่จะใช้สำหรับการฝึกอบรม [ค่าเริ่มต้น: ./imagen_config.json]--unet ดัชนีของ unet เพื่อฝึก [ค่าเริ่มต้น: 1]--epoches จำนวนยุคที่จะฝึกสำหรับ [ค่าเริ่มต้น: 50]ควรระวังเมื่อสุ่มตัวอย่างจุดตรวจสอบของคุณควรฝึกยูเน็ตทั้งหมดเพื่อให้ได้ผลลัพธ์ที่ใช้งานได้
อดีต.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngคุณสามารถส่งผ่านอาร์กิวเมนต์ต่อไปนี้ไปยังคำสั่งตัวอย่างได้
--model ระบุไฟล์โมเดลที่จะใช้สำหรับการสุ่มตัวอย่าง--cond_scale สเกลการปรับสภาพ (คำแนะนำแบบไม่มีลักษณนาม) ในตัวถอดรหัส--load_ema โหลดเวอร์ชัน EMA ของ unets หากมี หากต้องการใช้จุดตรวจสอบที่บันทึกไว้กับคุณสมบัตินี้ คุณจะต้องสร้างอินสแตนซ์ Imagen ของคุณโดยใช้คลาสการกำหนดค่า ImagenConfig และ ElucidatedImagenConfig หรือสร้างจุดตรวจสอบผ่าน CLI โดยตรง
เพื่อการฝึกอบรมที่เหมาะสม คุณอาจต้องตั้งค่าการฝึกอบรมที่ขับเคลื่อนด้วยการกำหนดค่าอยู่แล้ว
อดีต.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalมันควรจะง่ายแบบนั้นจริงๆ
คุณยังสามารถส่งไฟล์จุดตรวจสอบนี้ไปได้ และใครๆ ก็สามารถปรับแต่งข้อมูลของตนเองต่อไปได้
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning การลงสีเป็นไปตามสูตรที่กำหนดไว้ในกระดาษ Repaint ล่าสุด เพียงส่ง inpaint_images และ inpaint_masks ไปยังฟังก์ชัน sample บน Imagen หรือ ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) สำหรับวิดีโอ ให้ส่งวิดีโอของคุณไปยังคีย์เวิร์ด inpaint_videos บน .sample ในทำนองเดียวกัน มาสก์ในการวาดภาพสามารถเหมือนกันในทุกเฟรม (batch, height, width) หรือต่างกัน (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Tero Karras แห่งชื่อเสียงของ StyleGAN ได้เขียนรายงานฉบับใหม่พร้อมผลลัพธ์ที่ได้รับการยืนยันโดยนักวิจัยอิสระจำนวนหนึ่งรวมถึงในเครื่องของฉันเอง ฉันได้ตัดสินใจสร้างเวอร์ชันของ Imagen ซึ่งเป็น ElucidatedImagen เพื่อให้สามารถใช้ DDPM ที่มีการอธิบายใหม่สำหรับการสร้าง cascading ที่ใช้ข้อความนำทาง
เพียงนำเข้า ElucidatedImagen แล้วสร้างอินสแตนซ์เหมือนที่คุณเคยทำมาก่อน ไฮเปอร์พารามิเตอร์แตกต่างจากพารามิเตอร์ปกติสำหรับการแพร่แบบเกาส์เซียนแบบไม่ต่อเนื่องและต่อเนื่อง และสามารถกำหนดค่าเป็นรายบุคคลสำหรับแต่ละยูเน็ตในคาสเคดได้
อดีต.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above พื้นที่เก็บข้อมูลนี้จะเริ่มรวบรวมงานวิจัยใหม่เกี่ยวกับการสังเคราะห์วิดีโอที่มีข้อความแนะนำ สำหรับผู้เริ่มต้น จะใช้สถาปัตยกรรม 3d unet ที่อธิบายโดย Jonathan Ho ใน Video Diffusion Models
อัปเดต: ตรวจสอบการทำงานโดย Hadrien Reynaud!
อดีต.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) คุณยังสามารถฝึกจับคู่ข้อความ - รูปภาพก่อนได้ Unet3D จะแปลงเป็นวิดีโอที่มีเฟรมเดียวโดยอัตโนมัติ และเรียนรู้โดยไม่มีองค์ประกอบชั่วคราว (โดยการตั้งค่า ignore_time = True โดยอัตโนมัติ) ไม่ว่าจะเป็นการบิด 1d หรือความสนใจเชิงสาเหตุในช่วงเวลาหนึ่ง
นี่เป็นแนวทางปัจจุบันที่ห้องปฏิบัติการปัญญาประดิษฐ์ขนาดใหญ่ทุกแห่ง (Brain, MetaAI, Bytedance)
Imagen ใช้อัลกอริทึมที่เรียกว่า Classifier Free Guidance เมื่อสุ่มตัวอย่าง คุณจะต้องใช้มาตราส่วนกับการปรับสภาพ (ข้อความในกรณีนี้) ที่มากกว่า 1.0
นักวิจัย Netruk44 รายงานว่า 5-10 เป็นค่าที่เหมาะสม แต่มีอะไรที่มากกว่า 10 ที่จะพัง
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageยังไม่ใช่ในขณะนี้ แต่มีแนวโน้มว่าจะมีผู้ได้รับการฝึกอบรมและโอเพ่นซอร์สภายในปีนี้ หากไม่ช้าก็เร็ว หากคุณต้องการเข้าร่วม คุณสามารถเข้าร่วมชุมชนผู้ฝึกสอนโครงข่ายประสาทเทียมที่ Laion (ลิงก์ความไม่ลงรอยกันอยู่ใน Readme ด้านบน) และเริ่มการทำงานร่วมกัน
เหตุผลที่คุณควรเริ่มฝึกฝนโมเดลของคุณเอง เริ่มตั้งแต่วันนี้! สิ่งสุดท้ายที่เราต้องการก็คือเทคโนโลยีนี้อยู่ในมือของคนชั้นสูงเพียงไม่กี่คน หวังว่าพื้นที่เก็บข้อมูลนี้จะลดงานลงเหลือเพียงการค้นหาการคำนวณที่จำเป็น และเสริมด้วยชุดข้อมูลที่ดูแลจัดการของคุณเอง
อะไรก็ตาม! มันเป็นลิขสิทธิ์ของ MIT กล่าวอีกนัยหนึ่ง คุณสามารถคัดลอก/วางสำหรับการค้นคว้าของคุณเองได้อย่างอิสระ โดยรีมิกซ์ตามรูปแบบใดๆ ก็ตามที่คุณนึกออก ไปฝึกโมเดลที่น่าทึ่งเพื่อผลกำไร ทางวิทยาศาสตร์ หรือเพียงเพื่อความพึงพอใจส่วนตัวของคุณด้วยการได้เห็นบางสิ่งที่ศักดิ์สิทธิ์คลี่คลายต่อหน้าคุณ
การสังเคราะห์คลื่นไฟฟ้าหัวใจ [รหัส]
การสังเคราะห์เมทริกซ์สัมผัส SOTA Hi-C [รหัส]
การสร้างแผนผังชั้น
สไลด์จุลพยาธิวิทยาความละเอียดสูงพิเศษ
ภาพส่องกล้องสังเคราะห์
การออกแบบ MetaMaterial
การกระจายเสียงจาก Flavio Schneider
มินิอิมเมจจาก Ryan O. | การเขียน AssemblyAI
ใช้หม้อแปลง Huggingface สำหรับการฝังข้อความ T5 ขนาดเล็ก
เพิ่มเกณฑ์ขั้นต่ำแบบไดนามิก
เพิ่ม Thrilling Thresholding DALLE2 และพื้นที่เก็บข้อมูล video-diffusion ด้วยเช่นกัน
อนุญาตให้ตั้งค่า T5-large (และบางทีอาจเป็นวิธีโรงงานขนาดเล็กที่จะใช้หม้อแปลงไฟฟ้ากอด)
เพิ่มระดับเสียงรบกวนต่ำด้วยรหัสเทียมในภาคผนวก และหาคำตอบว่าพวกเขาทำอะไรในเวลาอนุมาน
พอร์ตผ่านโค้ดการฝึกอบรมบางส่วนจาก DAALLE2
จำเป็นต้องใช้กำหนดเวลาสัญญาณรบกวนที่แตกต่างกันต่อหนึ่งยูเน็ต (ใช้โคไซน์เป็นฐาน แต่เป็นเส้นตรงสำหรับ SR)
เพียงสร้าง Unet ที่กำหนดค่าหลักได้หนึ่งรายการ
บล็อก resnet ที่สมบูรณ์ (ได้รับแรงบันดาลใจจาก biggan แต่ด้วย groupnorm) - เอาใจใส่ตนเองอย่างเต็มที่
บล็อกการฝังการปรับสภาพที่สมบูรณ์ (และทำให้สามารถกำหนดค่าได้อย่างสมบูรณ์ ไม่ว่าจะเป็นความสนใจ ฟิล์ม ฯลฯ)
พิจารณาใช้ allowancer-resampler จาก https://github.com/lucidrains/flamingo-pytorch แทนการรวมความสนใจ
เพิ่มตัวเลือกการรวมความสนใจ นอกเหนือจากการข้ามความสนใจและภาพยนตร์
เพิ่มตารางการสลายตัวของโคไซน์เพิ่มเติมพร้อมการวอร์มอัพสำหรับแต่ละยูเน็ตให้กับเทรนเนอร์
สลับไปใช้การจับเวลาแบบต่อเนื่องแทนที่จะแยกออกจากกันเนื่องจากดูเหมือนว่าเป็นสิ่งที่ใช้สำหรับทุกขั้นตอน - ก่อนอื่นให้หากรณีกำหนดเวลาสัญญาณรบกวนเชิงเส้นจากเอกสาร ddpm ที่หลากหลาย https://openreview.net/forum?id=2LdBqxc1Yv
หาบันทึก (snr) สำหรับกำหนดเวลาสัญญาณรบกวนอัลฟาโคไซน์
ระงับคำเตือนของหม้อแปลงเนื่องจากใช้เฉพาะ T5encoder เท่านั้น
อนุญาตให้ตั้งค่าสำหรับการใช้ความสนใจเชิงเส้นบนเลเยอร์ที่ไม่สามารถใช้ความสนใจแบบเต็มได้
บังคับให้ unets ในกรณีเวลาต่อเนื่องเพื่อใช้เงื่อนไขที่ไม่ใช่ฟูริเยร์ (เพียงส่งบันทึก (snr) ผ่าน MLP พร้อมด้วยเลเยอร์มาตรฐานที่เป็นทางเลือก) เนื่องจากนั่นคือสิ่งที่ฉันได้ทำงานในพื้นที่
ลบความแปรปรวนที่เรียนรู้ออก
เพิ่มการถ่วงน้ำหนักการสูญเสีย p2 เป็นเวลาต่อเนื่องกัน
ตรวจสอบให้แน่ใจว่าสามารถฝึก ddpm แบบเรียงซ้อนได้โดยไม่มีเงื่อนไขข้อความ และตรวจสอบให้แน่ใจว่าการแพร่กระจายแบบเกาส์เซียนทั้งแบบต่อเนื่องและไม่ต่อเนื่องนั้นทำงาน
ใช้ Convs ในเชิงลึกของไพรเมอร์ในการฉายภาพ qkv ในความสนใจเชิงเส้น (หรือใช้การเปลี่ยนโทเค็นก่อนการฉายภาพ) - ใช้การออกกลางคันใหม่ที่เสนอโดย bayesformer เนื่องจากดูเหมือนว่าจะทำงานได้ดีกับความสนใจเชิงเส้น
สำรวจการกระตุ้นการข้ามเลเยอร์ในตัวถอดรหัส Unet
เร่งบูรณาการ
สร้างเครื่องมือ CLI และการสร้างรูปภาพหนึ่งบรรทัด
ขจัดทุกปัญหาที่เกิดจากการเร่งความเร็ว
เพิ่มความสามารถในการวาดภาพโดยใช้ resampler จากกระดาษทาสีใหม่ https://arxiv.org/abs/2201.09865
สร้างระบบจุดตรวจอย่างง่าย ซึ่งได้รับการสนับสนุนโดยโฟลเดอร์
เพิ่มการเชื่อมต่อข้ามจากเอาต์พุตของบล็อก upsample ทั้งหมด ใช้ในกระดาษ unet squared และงาน unet ก่อนหน้าบางส่วน
เพิ่ม fsspec แนะนำโดย Romain @ rom1504 สำหรับระบบไฟล์คลาวด์ / โลคัลที่ไม่เชื่อเรื่องจุดตรวจ
ทดสอบความคงอยู่ของ gcs ด้วย https://github.com/fsspec/gcsfs
ขยายไปสู่การสร้างวิดีโอ โดยใช้เวลาตามแกน เช่นเดียวกับในเอกสาร ddpm ของวิดีโอของ Ho
อนุญาตให้อิมเมจที่อธิบายชัดเจนสามารถสรุปเป็นรูปร่างใดก็ได้
อนุญาตให้อิมเมเจนสรุปรูปร่างใดก็ได้
เพิ่มอคติตำแหน่งแบบไดนามิกสำหรับการประมาณค่าความยาวที่ดีที่สุดในช่วงเวลาของวิดีโอ
ย้ายเฟรมวิดีโอไปที่ฟังก์ชันตัวอย่าง เนื่องจากเราจะพยายามประมาณค่าเวลา
ความโน้มเอียงความสนใจต่อคีย์ / ค่าว่างควรเป็นสเกลาร์ที่เรียนรู้ของมิติส่วนหัว
เพิ่มการปรับสภาพตัวเองจากกระดาษกระจายบิตซึ่งเขียนโค้ดไว้แล้วที่ ddpm-pytorch
เพิ่ม v-parameterization (https://arxiv.org/abs/2202.00512) จากกระดาษวิดีโอ imagen สิ่งเดียวที่ใหม่
รวมการเรียนรู้ทั้งหมดจาก make-a-video (https://makeavideo.studio/)
สร้างเครื่องมือ CLI สำหรับการฝึกอบรม และดำเนินการฝึกอบรมต่อจากไฟล์ปรับแต่ง
อนุญาตให้มีการแก้ไขชั่วคราวในขั้นตอนเฉพาะ
ตรวจสอบให้แน่ใจว่าการแก้ไขชั่วคราวใช้งานได้กับการวาดภาพ
ตรวจสอบให้แน่ใจว่าสามารถปรับแต่งโหมดการแก้ไขทั้งหมดได้ (นักวิจัยบางคนกำลังค้นหาผลลัพธ์ที่ดีกว่าด้วยไตรลิเนียร์)
imagen-video : อนุญาตให้มีการปรับเงื่อนไขในเฟรมวิดีโอก่อนหน้า (และในอนาคต) ไม่ควรอนุญาตให้ละเลยเวลาในสถานการณ์นั้น
ตรวจสอบให้แน่ใจว่าได้ดูแลการลดเวลา/อัปแซมปลิงชั่วคราวสำหรับการปรับสภาพเฟรมวิดีโอโดยอัตโนมัติ แต่อนุญาตให้มีตัวเลือกในการปิด
ตรวจสอบให้แน่ใจว่า inpainting ใช้งานได้กับวิดีโอ
ตรวจสอบให้แน่ใจว่า inpainting mask สำหรับวิดีโอสามารถปรับแต่งต่อเฟรมได้
เพิ่มความสนใจแบบแฟลช
อ่าน cogvideo อีกครั้งและดูว่าจะใช้การปรับอัตราเฟรมได้อย่างไร
นำความเชี่ยวชาญด้านความสนใจมาสู่ชั้นความสนใจในตนเองใน Unet3d
ลองดึงความสนใจแบบสามมิติของ NUWA เข้ามา
พิจารณาความทรงจำของ Transformer-xl ในบล็อกความสนใจชั่วคราว
พิจารณาวิธีรับรู้ถึงการคำนึงถึงเวลาในอดีต
เฟรมหลุดระหว่างความสนใจเพื่อให้ได้ผลทั้งการทำให้สม่ำเสมอและระยะเวลาการฝึกอบรมที่สั้นลง
ตรวจสอบการอ้างสิทธิ์ของ Frank Wood https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch และเพิ่มเทคนิคการสุ่มตัวอย่างแบบลำดับชั้น หรือแจ้งให้ผู้คนทราบเกี่ยวกับข้อบกพร่องของมัน
นำเสนอการเคลื่อนไหวที่ท้าทาย (พร้อมวัตถุรบกวน) เป็นบรรทัดฐานที่สามารถฝึกได้บรรทัดเดียวสำหรับนักวิจัยในการแยกย่อยจากข้อความเป็นวิดีโอ
การเข้ารหัสข้อความล่วงหน้าเพื่อฝัง memmapped
สามารถสร้างตัววนซ้ำของ dataloader ตามสไตล์ยุคเก่า รวมถึงกำหนดค่าการสับเปลี่ยน ฯลฯ
สามารถส่งผ่านข้อโต้แย้งได้ (แทนที่จะต้องส่งต่อเป็น args คำหลักทั้งหมดในโมเดล)
นำบล็อกแบบพลิกกลับได้จาก revnets สำหรับ 3d unet เพื่อลดภาระหน่วยความจำ
เพิ่มความสามารถในการฝึกฝนเฉพาะเครือข่ายที่มีความละเอียดสูงเท่านั้น
อ่าน dpm-solver ดูว่าใช้ได้กับการกระจายแบบเกาส์เซียนแบบต่อเนื่องหรือไม่
อนุญาตให้ปรับเฟรมวิดีโอด้วยเวลาที่แน่นอนโดยพลการ (คำนวณ RPE ในระหว่างความสนใจชั่วขณะ)
รองรับการปรับแต่งบูธในฝัน
เพิ่มการผกผันข้อความ
การปรับสภาพตนเองในการล้างข้อมูลจะถูกแยกออกมาที่การสร้างอินสแตนซ์ของอิมเมเจน
ตรวจสอบให้แน่ใจว่า Dreambooth ในที่สุดใช้งานได้กับ imagen-video
เพิ่มการปรับสภาพเฟรมเรตสำหรับการกระจายวิดีโอ
ตรวจสอบให้แน่ใจว่าสามารถกำหนดเงื่อนไขบนเฟรมวิดีโอพร้อมกันได้ เช่นเดียวกับการปรับสภาพรูปภาพในทุกเฟรม
ทดสอบและเพิ่มเทคนิคการกลั่นจากแบบจำลองความสม่ำเสมอ
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

