PaLM rlhf pytorch
0.3.9
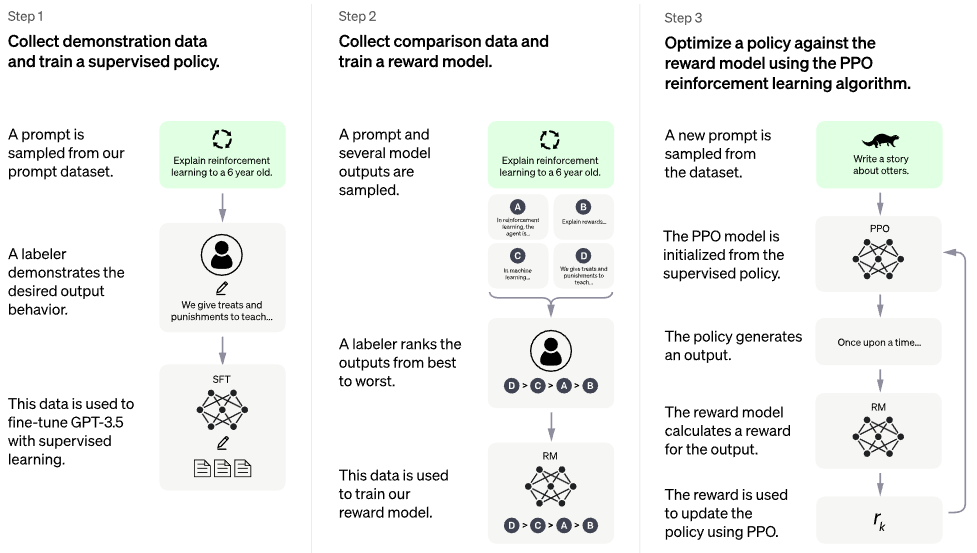
บล็อกโพสต์ chatgpt อย่างเป็นทางการ
การใช้งาน RLHF (การเรียนรู้แบบเสริมแรงด้วยผลตอบรับของมนุษย์) บนสถาปัตยกรรม PaLM บางทีฉันอาจจะเพิ่มฟังก์ชันการดึงข้อมูลด้วย à la RETRO
หากคุณสนใจที่จะทำซ้ำบางอย่างเช่น ChatGPT ในที่สาธารณะ โปรดพิจารณาเข้าร่วม Laion
ผู้สืบทอดที่มีศักยภาพ: การเพิ่มประสิทธิภาพการตั้งค่าโดยตรง - โค้ดทั้งหมดใน repo นี้กลายเป็น ~ การสูญเสียเอนโทรปีข้ามไบนารี < 5 loc มากสำหรับโมเดลรางวัลและ PPO
ไม่มีโมเดลที่ผ่านการฝึกอบรม นี่เป็นเพียงเรือและแผนที่โดยรวมเท่านั้น เรายังต้องการข้อมูลประมวลผล + มูลค่าหลายล้านดอลลาร์เพื่อแล่นไปยังจุดที่ถูกต้องในพื้นที่พารามิเตอร์มิติสูง ถึงอย่างนั้น คุณจำเป็นต้องมีกะลาสีเรือมืออาชีพ (เช่น Robin Rombach จาก Stable Diffusion) เพื่อนำทางเรือผ่านช่วงเวลาที่วุ่นวายจนถึงจุดนั้น
CarperAI ทำงานบนเฟรมเวิร์ก RLHF สำหรับโมเดลภาษาขนาดใหญ่เป็นเวลาหลายเดือนก่อนที่จะมีการเปิดตัว ChatGPT
Yannic Kilcher กำลังดำเนินการใช้งานแบบโอเพ่นซอร์สเช่นกัน
AI Coffeebreak กับ เลติเทีย | โค้ดเอ็มโพเรียม | โค้ด เอ็มโพเรี่ยม ตอนที่ 2
Stability.ai สำหรับการสนับสนุนอย่างมีน้ำใจในการทำงานวิจัยปัญญาประดิษฐ์ที่ล้ำหน้า
- Hugging Face และ CarperAI สำหรับการเขียนบล็อกโพสต์ Illustrating Reinforcement Learning from Human Feedback (RLHF) และก่อนหน้านี้สำหรับห้องสมุดเร่งความเร็วของพวกเขาด้วย
@kisseternity และ @ taynoel84 สำหรับการตรวจสอบโค้ดและค้นหาข้อบกพร่อง
Enrico สำหรับการรวม Flash Attention จาก Pytorch 2.0
$ pip install palm-rlhf-pytorch ขั้นแรกฝึก PaLM เช่นเดียวกับหม้อแปลงแบบออโตรีเกรสซีฟอื่นๆ
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) จากนั้นฝึกฝนโมเดลการให้รางวัลของคุณด้วยคำติชมจากมนุษย์ที่ได้รับการดูแลจัดการ ในรายงานต้นฉบับ พวกเขาไม่สามารถรับแบบจำลองรางวัลสำหรับการปรับแต่งอย่างละเอียดจากหม้อแปลงที่ผ่านการฝึกอบรมโดยไม่ต้องมีการติดตั้งมากเกินไป แต่ฉันให้ตัวเลือกในการปรับแต่งด้วย LoRA ต่อไป เนื่องจากยังคงเป็นการวิจัยแบบเปิด
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) จากนั้นคุณจะส่งต่อหม้อแปลงและโมเดลรางวัลให้กับ RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) หม้อแปลงฐานโคลนพร้อม Lora แยกต่างหากสำหรับนักวิจารณ์
ยังอนุญาตให้มีการปรับแต่งแบบละเอียดที่ไม่ใช่ LoRA
ทำซ้ำการทำให้เป็นมาตรฐานเพื่อให้สามารถมีเวอร์ชันที่มาสก์ได้ ไม่แน่ใจว่าจะมีใครใช้รางวัล / มูลค่าต่อโทเค็นหรือไม่ แต่เป็นแนวปฏิบัติที่ดีในการนำไปใช้
ให้ความเอาใจใส่อย่างดีที่สุด
เพิ่มการเร่งความเร็ว Hugging Face และทดสอบเครื่องมือไม้กายสิทธิ์
ค้นหาวรรณกรรมเพื่อดูว่า SOTA ล่าสุดสำหรับ PPO คืออะไร โดยสมมติว่าฟิลด์ RL ยังคงมีความคืบหน้า
ทดสอบระบบโดยใช้เครือข่ายความรู้สึกที่ได้รับการฝึกไว้ล่วงหน้าเป็นรูปแบบการให้รางวัล
เขียนหน่วยความจำใน PPO ไปยังไฟล์ memmapped numpy
รับการสุ่มตัวอย่างด้วยข้อความแจ้งที่มีความยาวผันแปรได้ แม้ว่าจะไม่จำเป็นก็ตาม เนื่องจากปัญหาคอขวดนั้นเป็นความคิดเห็นของมนุษย์
อนุญาตให้มีการปรับแต่งเลเยอร์ N สุดท้ายสุดท้ายเฉพาะในนักแสดงหรือนักวิจารณ์เท่านั้น โดยสมมติว่าได้รับการฝึกฝนมาก่อน
รวมประเด็นการเรียนรู้จาก Sparrow จากวิดีโอของเลติเทีย
เว็บอินเตอร์เฟสที่เรียบง่ายพร้อม django + htmx สำหรับการรวบรวมความคิดเห็นของมนุษย์
พิจารณา RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

