make a video pytorch
0.4.0
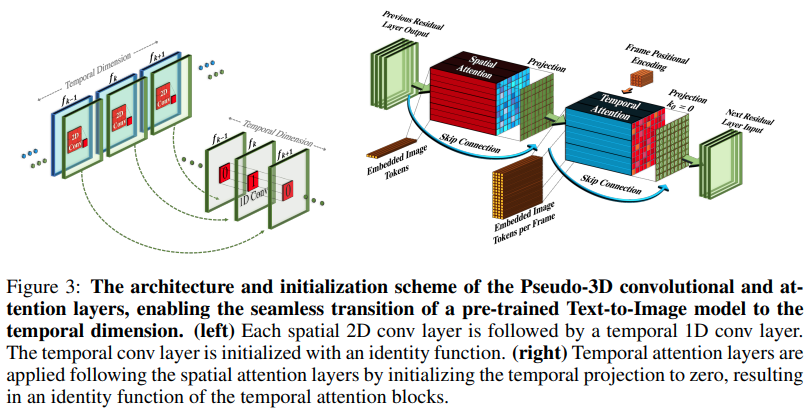
การใช้งาน Make-A-Video ซึ่งเป็นโปรแกรมสร้างข้อความ SOTA ใหม่เป็นวิดีโอจาก Meta AI ใน Pytorch พวกมันรวมการโน้มน้าวใจแบบหลอกสามมิติ (การโน้มน้าวตามแนวแกน) และความสนใจชั่วขณะ และแสดงฟิวชั่นชั่วขณะที่ดีกว่ามาก
การโน้มน้าวใจหลอก 3 มิติไม่ใช่แนวคิดใหม่ มีการสำรวจก่อนหน้านี้ในบริบทอื่น เช่น สำหรับการทำนายการสัมผัสโปรตีนว่าเป็น "เครือข่ายที่เหลือแบบลูกผสมมิติ"
สาระสำคัญของบทความนี้คือ ใช้โมเดลข้อความเป็นรูปภาพ SOTA (ในที่นี้ใช้ DALL-E2 แต่ประเด็นการเรียนรู้เดียวกันนี้สามารถนำไปใช้กับ Imagen ได้อย่างง่ายดาย) ทำการปรับเปลี่ยนเล็กน้อยเพื่อให้ความสนใจข้ามเวลาและวิธีอื่นๆ เพื่อลดค่าใช้จ่ายในการประมวลผล ทำการประมาณค่าเฟรมอย่างถูกต้อง และผลิตโมเดลวิดีโอที่ยอดเยี่ยมออกมา
คำอธิบาย AI Coffee Break
Stability.ai สำหรับการสนับสนุนอย่างมีน้ำใจในการทำงานวิจัยปัญญาประดิษฐ์ที่ล้ำหน้า
Jonathan Ho นำเสนอการปฏิวัติปัญญาประดิษฐ์เชิงสร้างสรรค์ผ่านบทความวิจัยของเขา
Alex สำหรับ einops ซึ่งเป็นนามธรรมที่เป็นอัจฉริยะ ไม่มีคำอื่นสำหรับมัน
$ pip install make-a-video-pytorchผ่านคุณสมบัติวิดีโอ
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)การส่งผ่านรูปภาพ (หากต้องฝึกล่วงหน้ากับรูปภาพก่อน) ทั้งการขมับและความสนใจจะถูกข้ามไปโดยอัตโนมัติ กล่าวอีกนัยหนึ่ง คุณสามารถใช้สิ่งนี้ได้อย่างตรงไปตรงมาใน 2d Unet ของคุณ จากนั้นจึงย้ายไปยัง 3d Unet เมื่อขั้นตอนของการฝึกอบรมเสร็จสิ้น โมดูลชั่วคราวได้รับการเตรียมใช้งานเพื่อระบุตัวตนของเอาท์พุตเหมือนกับกระดาษที่ทำเสร็จแล้ว
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)คุณยังสามารถควบคุมทั้งสองโมดูลได้ ดังนั้นเมื่อป้อนคุณสมบัติ 3 มิติ มันจะทำการฝึกเฉพาะเชิงพื้นที่เท่านั้น
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) Full SpaceTimeUnet ที่ไม่เชื่อเรื่องรูปภาพหรือการฝึกอบรมวิดีโอ และแม้ว่าวิดีโอจะถูกส่งผ่านก็ตาม ก็สามารถเพิกเฉยต่อเวลาได้
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )ให้ความสนใจกับการวิจัยการฝังตำแหน่งที่ดีที่สุดที่มีให้
ดึงดูดความสนใจ
เพิ่มความสนใจแบบแฟลช
ตรวจสอบให้แน่ใจว่า dalle2-pytorch สามารถยอมรับ SpaceTimeUnet สำหรับการฝึกอบรมได้
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

