minimind
V1

จีน |. อังกฤษ
โครงการโอเพ่นซอร์สนี้มีเป้าหมายที่จะเริ่มต้นใหม่ทั้งหมดภายในเวลาเพียง 3 ชั่วโมง! คุณสามารถฝึก MiniMind ซึ่ง เป็นโมเดลภาษาจิ๋วที่มีขนาดเพียง 26.88M
MiniMind มีน้ำหนักเบามากและเวอร์ชันที่เล็กที่สุดจะมีขนาดประมาณ GPT3
MiniMind เปิดตัวโครงสร้างมินิมอลโมเดลขนาดใหญ่ การทำความสะอาดชุดข้อมูลและการประมวลผลล่วงหน้า การฝึกล่วงหน้าแบบมีผู้ดูแล (Pretrain) การปรับแต่งคำสั่งแบบละเอียดแบบมีผู้ดูแล (SFT) การปรับแบบละเอียดแบบละเอียดระดับต่ำ (LoRA) และการเรียนรู้การเสริมแรงแบบไร้รางวัล การจัดตำแหน่งการตั้งค่าโดยตรง ( อ.ส.ค.) โค้ดแบบเต็มขั้นตอนยังรวมถึงส่วนขยายของแบบจำลองกระจัดกระจายของผู้เชี่ยวชาญไฮบริดที่ใช้ร่วมกัน (MoE) การขยาย VLM หลายรูปแบบด้วยภาพ: MiniMind-V
นี่ไม่ใช่แค่การนำโมเดลโอเพ่นซอร์สไปใช้เท่านั้น แต่ยังเป็นบทช่วยสอนสำหรับการเริ่มต้นใช้งานโมเดลภาษาขนาดใหญ่ (LLM)
เราหวังว่าโครงการนี้สามารถให้ตัวอย่างเบื้องต้นแก่นักวิจัยเพื่อช่วยให้ทุกคนเริ่มต้นได้อย่างรวดเร็ว และสร้างการสำรวจและนวัตกรรมเพิ่มเติมในสาขา LLM
เพื่อป้องกันความเข้าใจผิด "สูงสุด 3 ชั่วโมง" หมายความว่าคุณต้องมีเครื่องที่มี >การกำหนดค่าฮาร์ดแวร์ของฉันเอง รายละเอียดของข้อกำหนดเฉพาะจะมีระบุไว้ด้านล่าง

การทดสอบออนไลน์ของ ModelScope | ลิงก์วิดีโอ Bilibili
ในด้านโมเดลภาษาขนาดใหญ่ (LLM) เช่น GPT, LLaMA, GLM เป็นต้น แม้ว่าเอฟเฟกต์จะน่าทึ่ง แต่พารามิเตอร์โมเดลขนาดใหญ่ 10 พันล้านและหน่วยความจำของอุปกรณ์ส่วนบุคคลยังไม่เพียงพอสำหรับการฝึกอบรมและแม้แต่ การอนุมานเป็นเรื่องยาก เกือบทุกคนไม่พอใจกับการปรับแต่งโมเดลขนาดใหญ่โดยใช้โปรแกรมเช่น Lora เพื่อเรียนรู้คำสั่งใหม่ ๆ ซึ่งก็เหมือนกับการสอนนิวตันให้เล่นกับสมาร์ทโฟนแห่งศตวรรษที่ 21 อย่างไรก็ตาม สิ่งนี้ยังห่างไกลจากการเรียนรู้ความลึกลับของ ฟิสิกส์นั่นเอง นอกจากนี้ บัญชีการตลาดที่ขายหลักสูตรการสมัครสมาชิกแบบชำระเงินยังเต็มไปด้วยช่องโหว่และบทช่วยสอนที่อธิบาย AI ด้วยความรู้เพียงครึ่งเดียว ซึ่งทำให้การเข้าใจเนื้อหาคุณภาพสูงของ LLM ยากยิ่งขึ้นและเป็นอุปสรรคต่อผู้เรียนอย่างจริงจัง
ดังนั้น เป้าหมายของโปรเจ็กต์นี้คือการลดเกณฑ์ในการเริ่มต้นกับ LLM อย่างไม่สิ้นสุด และฝึกฝนโมเดลภาษาที่ใช้งานง่ายมากตั้งแต่เริ่มต้นโดยตรง
เคล็ดลับ
(ณ วันที่ 17-9-2567) ซีรีส์ MiniMind เสร็จสิ้นการฝึกอบรมล่วงหน้าสำหรับโมเดล 3 รุ่นแล้ว จำนวนขั้นต่ำที่ต้องการเพียง 26M (0.02B) เพื่อให้มีความสามารถในการสนทนาที่ราบรื่น!
| รุ่น (ขนาด) | ความยาวโทเค็น | การใช้เหตุผล | ปล่อย | คะแนนส่วนตัว (/100) |
|---|---|---|---|---|
| minimind-v1-เล็ก (26M) | 6400 | 0.5 กิกะไบต์ | 2024.08.28 | 50' |
| minimind-v1-โม (4×26M) | 6400 | 1.0 กิกะไบต์ | 2024.09.17 | 55' |
| มินิมายด์-v1 (108M) | 6400 | 1.0 กิกะไบต์ | 2024.09.01 | 60' |
การวิเคราะห์ดำเนินการบน GPU 2×RTX 3090 พร้อม Torch 2.1.2, CUDA 12.2 และ Flash Attention 2
โครงการประกอบด้วย:
transformers , accelerate , trl , peft ฯลฯฉันหวังว่าโครงการโอเพ่นซอร์สนี้จะช่วยให้ผู้เริ่มต้น LLM เริ่มต้นได้อย่างรวดเร็ว!
ขยายความสามารถหลายรูปแบบของ MiniMind - วิสัยทัศน์
ย้ายไปที่โครงการแฝด minimind-v เพื่อดูรายละเอียด!
09-27 อัปเดตวิธีการประมวลผลล่วงหน้าของชุดข้อมูลฝึกล่วงหน้า เพื่อให้มั่นใจในความสมบูรณ์ของข้อความ การประมวลผลล่วงหน้าจึงถูกยกเลิกและแปลงเป็นการฝึก .bin (ทำให้ความเร็วในการฝึกลดลงเล็กน้อย)
ไฟล์ปัจจุบันหลังการประมวลผล pretrain มีชื่อว่า: pretrain_data.csv
ลบโค้ดที่ซ้ำซ้อนบางส่วนออก
อัพเดตโมเดล minimind-v1-moe
เพื่อป้องกันความกำกวม Mistral_tokenizer จะไม่ถูกใช้เป็นการแบ่งส่วนคำอีกต่อไป และ minimind_tokenizer ที่กำหนดเองทั้งหมดจะถูกนำมาใช้เป็นการแบ่งส่วนคำ
อัปเดตโมเดล minimind-v1 (108M) โดยใช้ minimind_tokenizer รอบก่อนการฝึก 3 + SFT รอบ 10 ได้รับการฝึกอย่างเต็มที่มากขึ้น และประสิทธิภาพที่แข็งแกร่งยิ่งขึ้น
โปรเจ็กต์ได้รับการปรับใช้ในพื้นที่สร้าง ModelScope แล้วและสามารถสัมผัสประสบการณ์ได้บนเว็บไซต์นี้:
?ประสบการณ์ออนไลน์ของ ModelScope?
นี่เป็นเพียงการกำหนดค่าสภาพแวดล้อมซอฟต์แวร์และฮาร์ดแวร์ส่วนบุคคลของฉัน โปรดเปลี่ยนตามดุลยพินิจของคุณเอง:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练MiniMind (กอดใบหน้า)
MiniMind (โมเดลสโคป)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.pyหรือเริ่ม streamlit และเริ่มอินเทอร์เฟซการแชทผ่านเว็บ
"หมายเหตุ" ต้องใช้ python>=3.10 ติดตั้ง
pip install streamlit==1.27.2
# or step 3, use streamlit
streamlit run fast_inference.py0. รหัสโครงการโคลน
git clone https://github.com/jingyaogong/minimind.git
cd minimind1. การติดตั้งสภาพแวดล้อม
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
หากไม่มี โปรดไปที่ torch_stable เพื่อดาวน์โหลดไฟล์ whl และติดตั้งด้วยตนเอง ลิงค์อ้างอิง
2. หากคุณต้องการฝึกฝนตัวเอง
2.1 ดาวน์โหลดที่อยู่ดาวน์โหลดชุดข้อมูลและวางลงในไดเร็กทอรี ./dataset
2.2 python data_process.py ประมวลผลชุดข้อมูล ตัวอย่างเช่น ข้อมูล pretrain มีการเข้ารหัสโทเค็นล่วงหน้า และชุดข้อมูล sft จะถูกแยกจากไฟล์ qa ถึง csv
2.3 ปรับการกำหนดค่าพารามิเตอร์โมเดลใน ./model/LMConfig.py
ที่นี่คุณเพียงแค่ต้องปรับพารามิเตอร์ dim, n_layers และ use_moe ซึ่งก็คือ
(512+8)หรือ(768+16)ตามลำดับ ซึ่งสอดคล้องกับminimind-v1-smallและminimind-v1
2.4 python 1-pretrain.py ดำเนินการฝึกอบรมล่วงหน้าและรับ pretrain_*.pth เป็นน้ำหนักเอาท์พุตของการฝึกอบรมล่วงหน้า
2.5 python 3-full_sft.py ดำเนินการปรับแต่งคำสั่งอย่างละเอียดและรับ full_sft_*.pth เป็นน้ำหนักเอาต์พุตของการปรับแต่งคำสั่งอย่างละเอียด
2.6 python 4-lora_sft.py ทำการปรับแต่ง lora แบบละเอียด (ไม่จำเป็น)
2.7 python 5-dpo_train.py ดำเนินการจัดตำแหน่งการเรียนรู้การเสริมความต้องการของมนุษย์ของ DPO (ไม่บังคับ)
3. ทดสอบผลการใช้เหตุผลของโมเดล
*.pth ที่จำเป็นต้องใช้และการฝึกที่เสร็จสิ้นนั้นอยู่ในไดเร็กทอรี ./out/ /*.pth ที่ผ่านการฝึกอบรมของฉัน minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py ทดสอบเอฟเฟกต์เล่นไพ่คนเดียวของโมเดลที่ได้รับการฝึกล่วงหน้าpython 2-eval.py ทดสอบเอฟเฟกต์บทสนทนาของโมเดล 
"เคล็ดลับ" การฝึกล่วงหน้าและการปรับพารามิเตอร์อย่างละเอียดทั้ง pretrain และ full_sft รองรับการเร่งความเร็วหลายการ์ด
สมมติว่าอุปกรณ์ของคุณมีการ์ดกราฟิกเพียงตัวเดียว เพียงใช้ Native Python เพื่อเริ่มการฝึก:
python 1-pretrain.py
# and
python 3-full_sft.pyสมมติว่าอุปกรณ์ของคุณมีการ์ดกราฟิก N (N>1):
การฝึกอบรมการเริ่มต้น N การ์ดแบบสแตนด์อโลน (DDP)
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.pyการฝึกอบรมการเริ่มต้นใช้งานการ์ด N แบบสแตนด์อโลน (DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.pyเปิดใช้งานไม้กายสิทธิ์เพื่อบันทึกกระบวนการฝึกอบรม (ไม่บังคับ)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb ด้วยการเพิ่มพารามิเตอร์ --use_wandb กระบวนการฝึกอบรมสามารถบันทึกได้ หลังจากการฝึกอบรมเสร็จสิ้น สามารถดูกระบวนการฝึกอบรมได้บนเว็บไซต์ wandb ด้วยการแก้ไขพารามิเตอร์ wandb_project และ wandb_run_name คุณสามารถระบุชื่อโปรเจ็กต์และชื่อรันได้
? Tokenizer: Tokenizer ใน nlp นั้นคล้ายคลึงกับพจนานุกรม โดยจับคู่คำจากภาษาธรรมชาติกับตัวเลข เช่น 0, 1 และ 36 ผ่าน "พจนานุกรม" สามารถเข้าใจได้ว่าตัวเลขนี้แสดงถึงหมายเลขหน้าของคำนั้น "พจนานุกรม" มีสองวิธีในการสร้างโทเค็น LLM: วิธีหนึ่งคือการสร้างรายการคำด้วยตัวคุณเองเพื่อฝึกโทเค็น คุณสามารถดูโค้ดได้ train_tokenizer.py อีกวิธีคือเลือกโทเค็นไนเซอร์ที่ฝึกฝนโดยโมเดลโอเพ่นซอร์ส แน่นอนคุณสามารถเลือก Xinhua Dictionary หรือ Oxford Dictionary สำหรับ "พจนานุกรม" ได้โดยตรง ข้อดีคืออัตราการบีบอัดโทเค็นนั้นดีมาก แต่ข้อเสียคือรายการคำศัพท์ยาวเกินไปและมีวลีคำศัพท์นับแสน คุณยังสามารถใช้ตัวแบ่งคำที่ผ่านการฝึกอบรมมาเองได้ ข้อดีคือ สามารถควบคุมรายการคำได้ตามต้องการ ข้อเสียคืออัตราการบีบอัดไม่เหมาะเพียงพอ และไม่ง่ายที่จะครอบคลุมคำที่หายากทั้งหมด แน่นอนว่าการเลือก "พจนานุกรม" เป็นสิ่งสำคัญ ผลลัพธ์ของ LLM เป็นปัญหาการจำแนกคำหลายคำจาก SoftMax ไปยังพจนานุกรม จากนั้นจึงถอดรหัสเป็นภาษาธรรมชาติผ่าน "พจนานุกรม" เนื่องจาก LLM มีขนาดเล็กมาก เพื่อหลีกเลี่ยงโมเดลที่มีน้ำหนักมาก (อัตราส่วนของพารามิเตอร์เลเยอร์การฝังคำต่อ LLM ทั้งหมดสูงเกินไป) ความยาวของคำศัพท์จึงต้องเลือกให้ค่อนข้างเล็ก โมเดลโอเพ่นซอร์สที่ทรงพลัง เช่น 01 Wanwu, Qianwen, chatglm, Mistral, Llama3 ฯลฯ มีความยาวคำศัพท์โทเค็นไนเซอร์ดังต่อไปนี้:
| โมเดลโทเค็นไนเซอร์ | ขนาดคำศัพท์ | แหล่งที่มา |
|---|---|---|
| yi tokenizer | 64,000 | 01 ทุกอย่าง (จีน) |
| โทเค็น qwen2 | 151,643 | อาลีบาบา คลาวด์ (จีน) |
| โทเค็น GLM | 151,329 | ภูมิปัญญา AI (จีน) |
| โทเค็นมิสทรัล | 32,000 | มิสทรัล เอไอ (ฝรั่งเศส) |
| โทเค็นไลเซอร์ llama3 | 128,000 | เมตา (สหรัฐอเมริกา) |
| tokenizer ย่อเล็กสุด | 6,400 | ปรับแต่ง |
อัปเดต 17-09-2024: เพื่อป้องกันความคลุมเครือและควบคุมระดับเสียงในเวอร์ชันที่ผ่านมา โมเดล minimind ทั้งหมดใช้การแบ่งส่วนคำ minimind_tokenizer และเวอร์ชัน Mistral_tokenizer ทั้งหมดจะถูกยกเลิก
แม้ว่าความยาวของ minimind_tokenizer จะสั้นมาก แต่ประสิทธิภาพในการเข้ารหัสและถอดรหัสยังด้อยกว่าโทเค็นที่เป็นมิตรกับจีน เช่น qwen2 และ glm อย่างไรก็ตาม โมเดล minimind เลือก minimind_tokenizer ที่ได้รับการฝึกมาเป็นตัวแบ่งส่วนคำ เพื่อรักษาพารามิเตอร์โดยรวมให้มีน้ำหนักเบา และหลีกเลี่ยงความไม่สมดุลในสัดส่วนของเลเยอร์การเขียนโค้ดและเลเยอร์การคำนวณ ซึ่งมีน้ำหนักมากอันดับต้นๆ เนื่องจากขนาดคำศัพท์ของ minimind เป็นเพียง 6400. นอกจากนี้ minimind ไม่เคยล้มเหลวในการถอดรหัสคำที่หายากในการทดสอบจริง และผลลัพธ์ก็ดี เนื่องจากรายการคำที่กำหนดเองถูกบีบอัดเป็น 6400 คำ ขนาดพารามิเตอร์รวมของ LLM จึงต่ำเพียง 26M
?[เตรียมข้อมูลล่วงหน้า]: ชุดข้อมูลข้อความสากล Seq-Monkey/ดิสก์เครือข่าย Seq-Monkey Baidu ได้รับการรวบรวมและล้างจากแหล่งข้อมูลสาธารณะที่หลากหลาย (เช่น หน้าเว็บ สารานุกรม บล็อก รหัสโอเพ่นซอร์ส หนังสือ ฯลฯ) . ได้รับการจัดระเบียบเป็นรูปแบบ JSONL แบบครบวงจร และผ่านการคัดกรองและการขจัดข้อมูลซ้ำซ้อนอย่างเข้มงวด เพื่อให้มั่นใจในความครอบคลุม ขนาด ความน่าเชื่อถือ และคุณภาพของข้อมูล จำนวนรวมประมาณ 10B โทเค็น ซึ่งเหมาะสำหรับการฝึกอบรมโมเดลภาษาจีนขนาดใหญ่ล่วงหน้า
ตัวเลือกที่ 2: ส่วนที่สาธารณชนเข้าถึงได้ของชุดข้อมูล SkyPile-150B มีหน้าเว็บที่ไม่ซ้ำกันประมาณ 233 ล้านหน้า แต่ละหน้ามีตัวอักษรจีนโดยเฉลี่ยมากกว่า 1,000 ตัว ชุดข้อมูลประกอบด้วยโทเค็นประมาณ 150 พันล้านโทเค็นและข้อมูลข้อความธรรมดาขนาด 620GB หากคุณรีบ คุณสามารถลองเลือกเฉพาะบางส่วนของการดาวน์โหลด jsonl ของ SkyPile-150B (และสร้างไฟล์ *.csv สำหรับโทเค็นข้อความใน ./data_process.py) เพื่อให้ดำเนินการผ่านกระบวนการก่อนการฝึกอบรมได้อย่างรวดเร็ว .
ดาวน์โหลดไปยังไดเร็กทอรี ./dataset/
| ชุดข้อมูลการฝึก MiniMind | ดาวน์โหลดที่อยู่ |
|---|---|
| [ชุดการฝึกโทเคนไนเซอร์] | HuggingFace / Baidu Netdisk |
| 【ข้อมูลฝึกล่วงหน้า】 | อย่างเป็นทางการของ Seq-Monkey/ดิสก์เครือข่าย Baidu/HuggingFace |
| 【ข้อมูล SFT】 | ชุดข้อมูล SFT โมเดลขนาดใหญ่ของ Jiangshu |
| 【ข้อมูลอ.ส.ค.】 | กอดหน้า |
MiniMind-Dense (เหมือนกับ Llama3.1) ใช้โครงสร้าง Decoder-Only ของ Transformer ความแตกต่างจาก GPT-3 คือ:
โมเดล MiniMind-MoE โครงสร้างอิงตาม Llama3 และโมดูลผู้เชี่ยวชาญไฮบริด MixFFN ใน Deepseek-V2
โครงสร้างโดยรวมของ MiniMind จะเหมือนกัน ยกเว้นการปรับเปลี่ยนเล็กน้อยในโค้ดของการคำนวณ RoPE ฟังก์ชันการอนุมาน และเลเยอร์ FFN โครงสร้างมีดังนี้ (ฉบับวาดใหม่):
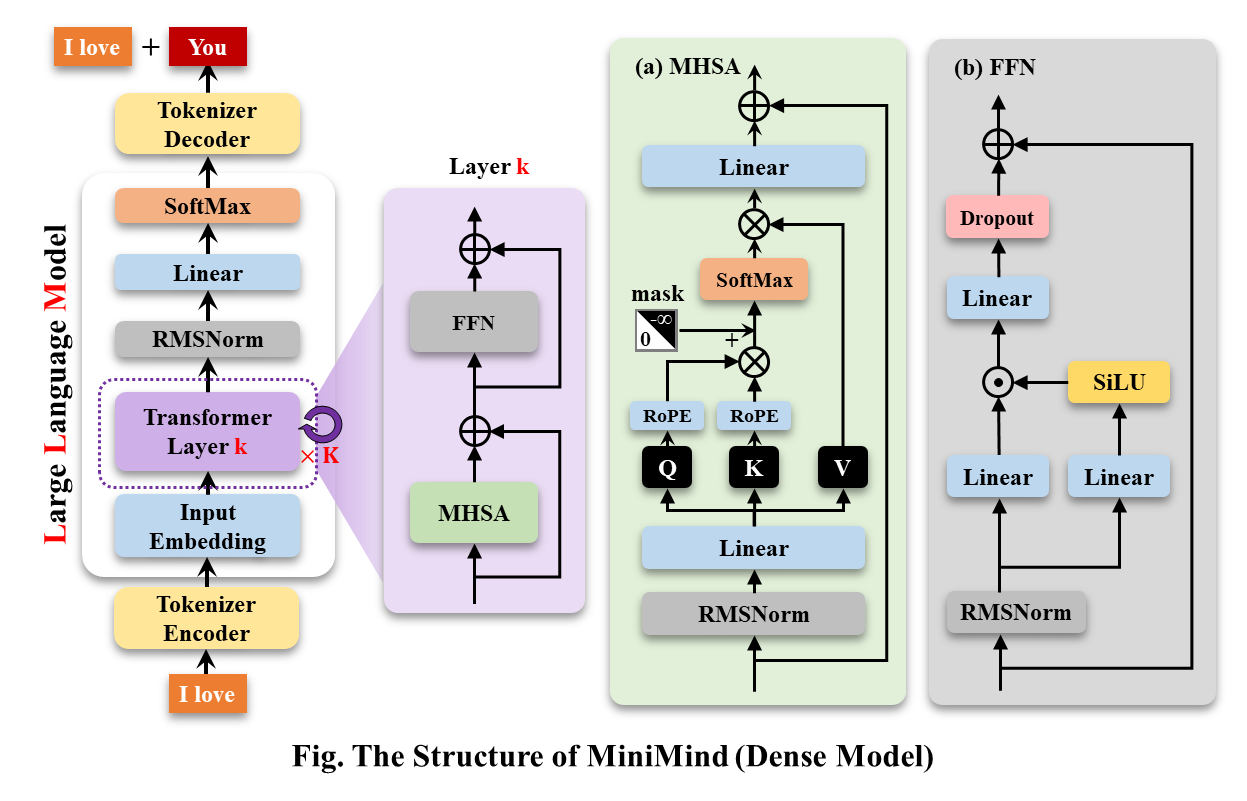
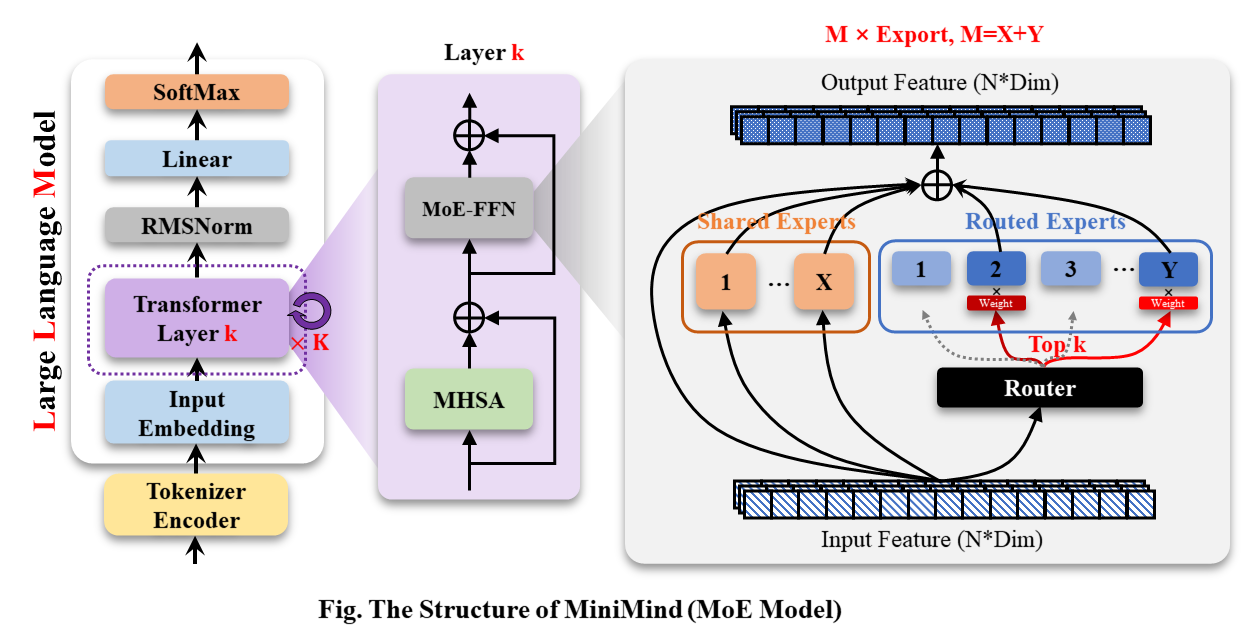
หากต้องการแก้ไขการกำหนดค่าโมเดล โปรดดูที่ ./model/LMConfig.py เวอร์ชันของโมเดลที่ได้รับการฝึกโดย minimind จะแสดงอยู่ในตารางด้านล่าง:
| ชื่อรุ่น | พารามิเตอร์ | len_vocab | n_ชั้น | d_model | kv_heads | q_heads | แบ่งปัน+เส้นทาง | ท็อปเค |
|---|---|---|---|---|---|---|---|---|
| minimind-v1-เล็ก | 26ม | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimind-v1-moe | 4×26ม | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| มินิมายด์-v1 | 108ม | 6400 | 16 | 768 | 8 | 16 | - | - |
| ชื่อรุ่น | พารามิเตอร์ | len_vocab | ชุด_ขนาด | pretrain_time | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-เล็ก | 26ม | 6400 | 64 | มีความยาว 2 ชั่วโมง (1 ยุค) | มีความยาว 2 ชั่วโมง (1 ยุค) | มีความยาว 0.5 ชั่วโมง (1 ยุค) |
| minimind-v1-moe | 4×26ม | 6400 | 40 | มีความยาว 6 ชั่วโมง (1 ยุค) | มีความยาว 5 ชั่วโมง (1 ยุค) | มีความยาว 1 ชั่วโมง (1 ยุค) |
| minimind-v1 | 108ม | 6400 | 16 | มีความยาว 6 ชั่วโมง (1 ยุค) | มีความยาว 4 ชั่วโมง (1 ยุค) | มีความยาว 1 ชั่วโมง (1 ยุค) |
การฝึกอบรมล่วงหน้า (ข้อความเป็นข้อความ) :
อัตราการเรียนรู้ของการฝึกล่วงหน้าถูกกำหนดเป็นอัตราการเรียนรู้แบบไดนามิกตั้งแต่ 1e-4 ถึง 1e-5 และจำนวนยุคของการฝึกล่วงหน้าถูกกำหนดไว้ที่ 5
torchrun --nproc_per_node 2 1-pretrain.pyกล่องโต้ตอบเดียว
ด้วยการปรับค่าความแตกต่างเชิงเส้นของ RoPE ในระหว่างการอนุมาน จะสะดวกในการคาดการณ์ความยาวเป็น 1024 หรือ 2048 ขึ้นไป อัตราการเรียนรู้ถูกกำหนดเป็นอัตราการเรียนรู้แบบไดนามิกตั้งแต่ 1e-5 ถึง 1e-6 และจำนวนยุคที่ปรับแต่งอย่างละเอียดคือ 6
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.pyการปรับหลายกล่องโต้ตอบแบบละเอียด :
อัตราการเรียนรู้ถูกกำหนดเป็นอัตราการเรียนรู้แบบไดนามิกตั้งแต่ 1e-5 ถึง 1e-6 และจำนวนยุคที่ปรับแต่งอย่างละเอียดคือ 5
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.pyการเรียนรู้การเสริมแรงตอบรับของมนุษย์ (RLHF) - การเพิ่มประสิทธิภาพการตั้งค่าโดยตรง (DPO) :
ชุดข้อมูลแฝดประเภทที่เคลื่อนย้ายได้ (q, เลือก, ปฏิเสธ) อัตราการเรียนรู้ le-5, half-precision fp16 รวม 1 epoch และใช้เวลา 1 ชั่วโมง
python 5-dpo_train.py ? เกี่ยวกับการกำหนดค่าพารามิเตอร์ของ LLM มีรายงาน MobileLLM ที่น่าสนใจมากซึ่งทำการวิจัยและทดลองโดยละเอียด กฎหมายมาตราส่วนมีกฎเฉพาะของตัวเองในโมเดลขนาดเล็ก พารามิเตอร์ที่ทำให้พารามิเตอร์ Transformer ปรับขนาดขึ้นอยู่กับ d_model และ n_layers เกือบทั้งหมด
d_model ↑+ n_layers ↓->ฮัมป์ตี้ ดัมพ์ตี้d_model ↓+ n_layers ↑->ผอมและสูง บทความที่เสนอกฎมาตราส่วนในปี 2020 เชื่อว่าจำนวนข้อมูลการฝึก จำนวนพารามิเตอร์ และจำนวนการฝึกซ้ำเป็นปัจจัยสำคัญที่กำหนดประสิทธิภาพ และแทบจะมองข้ามผลกระทบของสถาปัตยกรรมแบบจำลองไปได้เลย อย่างไรก็ตาม ดูเหมือนว่ากฎหมายฉบับนี้จะใช้ไม่ได้กับรุ่นขนาดเล็กทั้งหมด MobileLLM เสนอว่าความลึกของสถาปัตยกรรมมีความสำคัญมากกว่าความกว้าง โมเดล "ลึกและแคบ" "เรียว" สามารถเรียนรู้แนวคิดที่เป็นนามธรรมได้มากกว่าโมเดล "กว้างและตื้น" ตัวอย่างเช่น เมื่อพารามิเตอร์โมเดลถูกกำหนดไว้ที่ 125M หรือ 350M โมเดล "แคบ" ที่มี 30 ถึง 42 เลเยอร์จะมีประสิทธิภาพที่ดีกว่าโมเดล "เตี้ยและอ้วน" ที่มีประมาณ 12 เลเยอร์อย่างมาก ในการทดสอบเกณฑ์มาตรฐาน 8 ครั้ง เช่น การใช้เหตุผลสามัญสำนึก คำถามและคำตอบและการอ่านเพื่อความเข้าใจก็มีแนวโน้มคล้ายกัน นี่เป็นการค้นพบที่น่าสนใจมากจริงๆ เพราะในอดีต เมื่อออกแบบสถาปัตยกรรมสำหรับโมเดลขนาดเล็กประมาณ 100M แทบไม่มีใครพยายามซ้อนกันเกิน 12 ชั้น ซึ่งสอดคล้องกับผลที่สังเกตได้จากการทดลองของ MiniMind โดยปรับพารามิเตอร์โมเดลระหว่าง d_model และ n_layers ในระหว่างกระบวนการฝึกอบรม อย่างไรก็ตาม "แคบ" ของ "ลึกและแคบ" ก็มีขีดจำกัดมิติเช่นกัน เมื่อ d_model<512 ข้อเสียของการยุบมิติการฝังคำนั้นชัดเจนมาก เลเยอร์ที่เพิ่มเข้ามาไม่สามารถชดเชยข้อเสียของ d_head ที่ไม่เพียงพอที่เกิดจากการฝังคำได้ ใน q_head คงที่ เมื่อ d_model>1536 การเพิ่มเลเยอร์ดูเหมือนจะมีลำดับความสำคัญสูงกว่า d_model และสามารถนำพารามิเตอร์ "คุ้มต้นทุน" มาใช้ -> เอฟเฟกต์ที่ได้รับมากขึ้น ดังนั้น MiniMind จึงตั้งค่า d_model=512 และ n_layers=8 ของโมเดลขนาดเล็กเพื่อให้ได้ความสมดุลของ "ปริมาณที่น้อยมาก <-> เอฟเฟกต์ที่ดีกว่า" ตั้งค่า d_model=768, n_layers=16 เพื่อให้ได้รับประโยชน์มากขึ้นจากเอฟเฟกต์ ซึ่งสอดคล้องกับเส้นโค้งที่เปลี่ยนแปลงของกฎมาตราส่วนของโมเดลขนาดเล็ก
เพื่อเป็นข้อมูลอ้างอิง การตั้งค่าพารามิเตอร์ของ GPT3 จะแสดงอยู่ในตารางด้านล่าง:
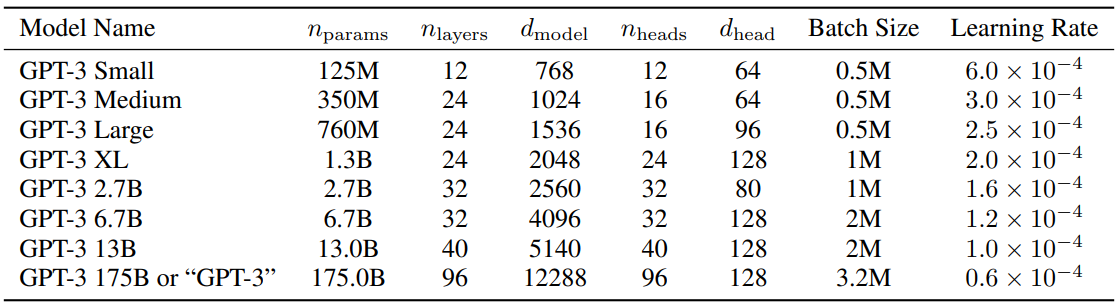
?ไป่ตู้เน็ตดิสก์
| ชื่อรุ่น | พารามิเตอร์ | การกำหนดค่า | pretrain_model | single_sft_model | multi_sft_model | rl_model |
|---|---|---|---|---|---|---|
| minimind-v1-เล็ก | 26ม | d_model=512 n_เลเยอร์=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| minimind-v1-moe | 4×26ม | d_model=512 n_เลเยอร์=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| มินิมายด์-v1 | 108ม | d_model=768 n_ชั้น=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
เคล็ดลับ
ทดสอบการเปรียบเทียบโมเดล minimind ตาม "บทสนทนารอบเดียว full_sft" และ "การจัดตำแหน่งการเรียนรู้การเสริมกำลัง DPO"
ไฟล์โมเดล Baidu Netdisk โดยที่ rl_<dim>.pth คือน้ำหนักโมเดลขั้นต่ำหลัง "การจัดตำแหน่งการเรียนรู้การเสริมกำลัง DPO"
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
เคล็ดลับ
การทดสอบต่อไปนี้เสร็จสิ้นในวันที่ 2024-09-17 รุ่นใหม่ที่ออกหลังจากวันที่นี้จะไม่รวมอยู่ในการทดสอบ เว้นแต่จะมีความต้องการพิเศษ ทดสอบโมเดล minimind ตามบทสนทนารอบเดียว full_sft (โดยไม่มีการปรับแต่งแบบละเอียดแบบหลายรอบและการเรียนรู้แบบเสริมแบบเสริม)
[A] มินิมายด์-v1-เล็ก(0.02B)
[B] มินิมายด์-v1-โม(0.1B)
[C] มินิมายด์-v1(0.1B)
[D] baby-llama2-chinese(0.2B)
[E] chatlm-มินิ-จีน(0.2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
บันทึก
?♂️ ส่งคำตอบของโมเดลข้างต้นไปที่ GPT-4o โดยตรงแล้วปล่อยให้มันช่วยให้คะแนน:
รุ่นเอ :
รุ่น บี :
รุ่นซี :
รุ่น D :
รุ่น อี :
| แบบอย่าง | ค | อี | บี | ก | ดี |
|---|---|---|---|---|---|
| เศษส่วน | 75 | 70 | 65 | 60 | 50 |
การเรียงลำดับซีรีส์ minimind (ABC) เป็นไปตามสัญชาตญาณ และ minimind-v1 (0.1B) มีคะแนนสูงสุด คำตอบสำหรับคำถามสามัญสำนึกโดยพื้นฐานแล้วไม่มีข้อผิดพลาดและภาพลวงตา
epochs SFT ของ minimind-v1 (0.1B) น้อยกว่า 2 ฉันขี้เกียจเกินไปที่จะฆ่าล่วงหน้าเพื่อเพิ่มทรัพยากรสำหรับรุ่นขนาดเล็ก 0.1B ยังคงได้รับประสิทธิภาพที่แข็งแกร่งที่สุดแม้ว่าจะยังไม่สมบูรณ์ก็ตาม ฝึกฝนแล้ว ในความเป็นจริงมันยังสูงกว่าระดับก่อนหน้าหนึ่งคำตอบของโมเดล E ดูดีมากด้วยตาเปล่า แม้ว่าจะมีภาพหลอนและการปลอมแปลงอยู่บ้างก็ตาม อย่างไรก็ตาม การให้คะแนนของทั้ง GPT-4o และ Deepseek เห็นพ้องกันว่ามี "ข้อมูลที่ยาวเกินไป เนื้อหาซ้ำ และภาพลวงตา" จริงๆ แล้วการประเมินแบบนี้ค่อนข้างเข้มงวด แม้ว่า 10 คำจากทั้งหมด 100 คำจะเป็นภาพหลอน แต่ก็ให้คะแนนต่ำได้ง่ายๆ เนื่องจากข้อความก่อนการฝึกอบรมของโมเดล E ยาวกว่าและชุดข้อมูลมีขนาดใหญ่กว่ามาก คำตอบจึงดูเหมือนเสร็จสมบูรณ์ ในกรณีของการประมาณปริมาณ ทั้งปริมาณข้อมูลและคุณภาพมีความสำคัญ
?♂️การประเมินแบบอัตนัยส่วนบุคคล: E>C>BหยาบคายA>D
? ระดับ GPT-4o: C>E>B>A>D
กฎการปรับขนาด: ยิ่งพารามิเตอร์โมเดลมีขนาดใหญ่และข้อมูลการฝึกมากขึ้น ประสิทธิภาพของโมเดลก็จะยิ่งแข็งแกร่งขึ้นเท่านั้น
ดูโค้ดประเมินผล C-Eval: ./eval_ceval.py เพื่อหลีกเลี่ยงปัญหาในการแก้ไขรูปแบบการตอบกลับ การประเมินแบบจำลองขนาดเล็กมักจะกำหนดความน่าจะเป็นในการทำนายของโทเค็นที่สอดคล้องกับตัวอักษรสี่ตัว A , B , C โดยตรง และ D และเอาคำตอบที่ใหญ่ที่สุดมาคำนวณและคำนวณอัตราความแม่นยำด้วยคำตอบมาตรฐาน โมเดล minimind ไม่ได้ใช้ชุดข้อมูลขนาดใหญ่ในการฝึกอบรม และไม่ได้ปรับแต่งคำแนะนำในการตอบคำถามแบบปรนัยอย่างละเอียด
ตัวอย่างเช่น รายละเอียดผลลัพธ์ของ minimind-small:
| พิมพ์ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ยี่สิบเอ็ด | ยี่สิบสอง | ยี่สิบสาม | ยี่สิบสี่ | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ข้อมูล | ความน่าจะเป็น_และ_สถิติ | กฎ | มัธยมต้น_ชีววิทยา | มัธยมปลาย_เคมี | มัธยมปลาย_ฟิสิกส์ | กฎหมาย_มืออาชีพ | มัธยมปลาย_จีน | มัธยมปลาย_ประวัติศาสตร์ | Tax_accountant | modern_chinese_history | มัธยมต้น_ฟิสิกส์ | มัธยมต้น_ประวัติศาสตร์ | basic_medicine | ระบบปฏิบัติการ | ตรรกะ | ช่างไฟฟ้า_วิศวกร | พลเรือน_ข้าราชการ | ภาษาจีน_ภาษา_และ_วรรณกรรม | วิทยาลัย_การเขียนโปรแกรม | นักบัญชี | พืช_การป้องกัน | มัธยมต้น_เคมี | มาตรวิทยา_วิศวกร | สัตวแพทยศาสตร์_การแพทย์ | ลัทธิมาร์กซิสม์ | ขั้นสูง_คณิตศาสตร์ | มัธยมปลาย_คณิตศาสตร์ | ธุรกิจ_การบริหาร | เหมา_เจ๋อตง_คิด | อุดมการณ์_และ_ศีลธรรม_การเพาะปลูก | วิทยาลัยเศรษฐศาสตร์ | professional_tour_guide | Environmental_impact_assessment_วิศวกร | คอมพิวเตอร์_สถาปัตยกรรม | urban_and_rural_planner | วิทยาลัยฟิสิกส์ | มัธยมต้น_คณิตศาสตร์ | มัธยมปลาย_การเมือง | แพทย์ | วิทยาลัย_เคมี | มัธยมปลาย_ชีววิทยา | มัธยมปลาย_ภูมิศาสตร์ | มัธยมต้น_การเมือง | ทางคลินิก_ยา | คอมพิวเตอร์_เครือข่าย | กีฬา_วิทยาศาสตร์ | ศิลปะ_การศึกษา | ครู_วุฒิการศึกษา | discrete_mathematics | การศึกษา_วิทยาศาสตร์ | fire_engineer | มัธยมต้น_ภูมิศาสตร์ |
| พิมพ์ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ยี่สิบเอ็ด | ยี่สิบสอง | ยี่สิบสาม | ยี่สิบสี่ | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ที/เอ | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 31 ก.ค | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
| ความแม่นยำ | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| หมวดหมู่ | ถูกต้อง | คำถาม_นับ | ความแม่นยำ |
|---|---|---|---|
| minimind-v1-เล็ก | 344 | 1346 | 25.56% |
| มินิมายด์-v1 | 351 | 1346 | 26.08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
./export_model.py สามารถส่งออกโมเดลเป็นรูปแบบ Transformers และกดไปที่ Huggingface
ที่อยู่คอลเลกชันกอดของ MiniMind: MiniMind
my_openai_api.py ทำให้อินเทอร์เฟซการแชทของ openai_api สมบูรณ์ ทำให้ง่ายต่อการเชื่อมต่อโมเดลของคุณกับ UI ของบุคคลที่สาม เช่น fastgpt, OpenWebUI ฯลฯ
ดาวน์โหลดไฟล์น้ำหนักโมเดลจาก Huggingface
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
เริ่มเซิร์ฟเวอร์การสนทนา
python my_openai_api.pyทดสอบอินเทอร์เฟซบริการ
python chat_openai_api.pyตัวอย่างอินเทอร์เฟซ API เข้ากันได้กับรูปแบบ openai api
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
เคล็ดลับ
หากคุณรู้สึกว่า MiniMind เป็นประโยชน์กับคุณ คุณสามารถเพิ่มบทความใน GitHub ได้ ความยาวไม่มากและมีระดับจำกัด การละเลยเป็นสิ่งที่หลีกเลี่ยงไม่ได้ในการแลกเปลี่ยนปัญหาหรือส่งโครงการปรับปรุง PR แรงผลักดันในการปรับปรุงโครงการอย่างต่อเนื่อง
บันทึก
ทุกคนเติมเชื้อเพลิงให้กับเปลวไฟ หากคุณได้ลองฝึกโมเดล MiniMind ใหม่แล้ว คุณสามารถแบ่งปันน้ำหนักโมเดลของคุณในการสนทนาหรือประเด็นต่างๆ ได้ โดยอาจเป็นงานปลายน้ำเฉพาะหรือสาขาแนวตั้ง (เช่น การจดจำอารมณ์ การแพทย์ และจิตวิทยา) ,การเงิน,คำถามและคำตอบทางกฎหมาย ฯลฯ ) MiniMind เวอร์ชันใหม่ นอกจากนี้ยังอาจเป็นเวอร์ชัน MiniMind ใหม่หลังจากการฝึกอบรมแบบขยายเวลา (เช่น การสำรวจลำดับข้อความที่ยาวขึ้น ปริมาณที่มากขึ้น (0.1B+) หรือชุดข้อมูลที่ใหญ่กว่า) การแบ่งปันใด ๆ ถือว่าไม่เหมือนใคร และความพยายามทั้งหมดจะมีคุณค่าและได้รับการสนับสนุน ถูกค้นพบทันเวลาและจัดระเบียบในรายการรับทราบ ขอขอบคุณอีกครั้งสำหรับการสนับสนุนของคุณ!
@ipfgao : ?บันทึกขั้นตอนการฝึกอบรม
@chuanzhubin : ? โค้ดคอมเม้นต์ทีละบรรทัด
@WangRongsheng : ?การประมวลผลชุดข้อมูลขนาดใหญ่ล่วงหน้า
@pengqianhan : ?บทช่วยสอนที่กระชับ
@RyanSunn : ?บันทึกการเรียนรู้กระบวนการให้เหตุผล
ที่เก็บนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต Apache-2.0


